Inspiration
Healthcare costs are on the rise - drugs are being promoted on national media, some doctors partner with companies to get commission in return for higher prescriptions rates. Many drugs have similar purposes, but vastly different side effects and costs, leaving patients wondering why their doctor prescribed a specific medicine over a cheaper or less adverse one. RU Okay? is here to fix that.
What it does
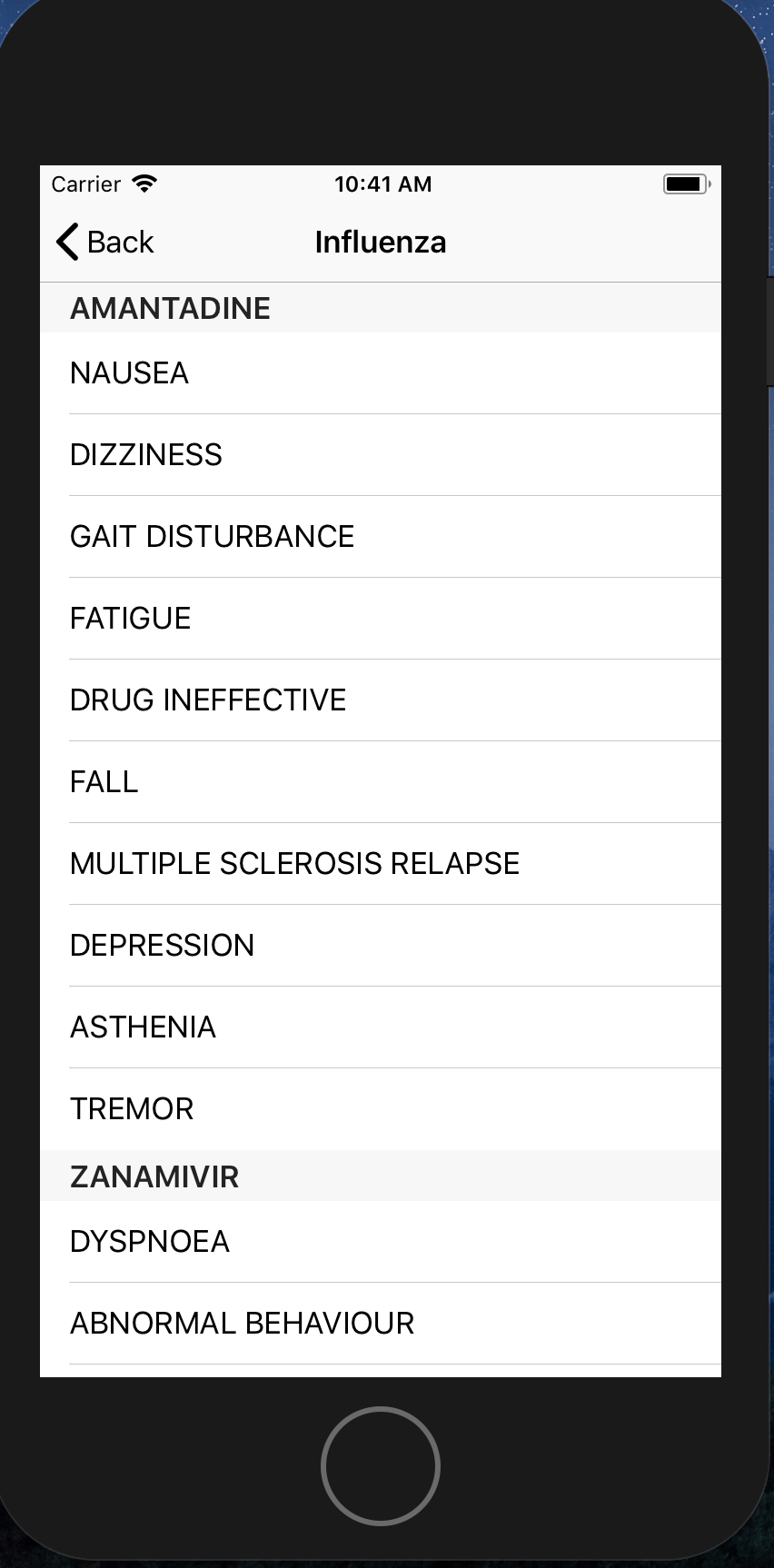
RU Okay? gives the power of medicinal data back to the patients. Cross referencing the large libraries of the National Institute Of Health, U.S Food and Drug Administrations, and Medicaid, our system provides a process to obtain and manipulate data. First, our system takes in a diagnosis (usually a disease or infection). It reaches into the libraries, and returns a list of active ingredients for treatments. The program provides all brands that contain it, adverse side effects (including the percent of users to experience them), and cost in dollar per unit. The most common unis is the price for one tablet.
Using this system, patients have the ability to overcome media bias, and focus on their needs. For example, a patient, with the fear of vomiting, may look through the list for a possible medication that minimizes that side effect. The ability to sort by cost allows the patient to easily look at medicine they can afford. This will help patients who have little or no health insurance to locate possible cost effective treatments.Using this information, the patient now can play an active role in deciding their treatment plan while communicating with their doctor.
How we built it
Medicinal data is notoriously fragmented and unregulated. Once the infection is inputted, it is searched in the NIH (National Institutes of Health) RxNav database for its NUI code. This database is used again to provide drugs (active ingredients) that could cure the infection, and their respective NUI codes. For each of these ingredients, another NIH database is queried to find brands that sell a drug containing this active ingredient. Each active ingredient is then looked up in the NIH NDF-RT dataset to find the RXCUI code, another identifier.
To find the side effects of each drug and their occurence rates, we look at the FDA's (Food and Drug Administration) Drug Adverse Events dataset, which is queried using the RXCUI code. The results are manipulated using Python Pandas to find the percentage occurrence of each side effect.
Finally, the Medicaid NADAC (National Average Drug Acquisition Cost) dataset is used to find the distributions of each drug, and its average cost of acquisition. This entire script is hosted on a server using Flask and ngrok, and made into the RESTful API, which takes in the type of disease and returns a JSON of all the data described.
The iOS app provides a basic interface for our dataset that can interact with the server. It displays the side effects and their occurrence percentages for each active ingredient by parsing the JSON. This is out example usecase.
The python script increases functionality to be able to sort drugs by cost, and provides graphics that let patients have a better idea of what they are being prescribed.
What's next for RU Okay?
By giving patients and doctors access to more drug data, we hope to push costs down for drugs and improve overall healthcare. Patients should be able to select drugs that are covered by their insurance plan, and minimize side effects they don't want. Doctors should be able to give their patients a better understanding of what they are prescribing.
The answer to RU Okay? should always by a resounding YES.


Log in or sign up for Devpost to join the conversation.