Inspiration
Screening calls are time-consuming, inconsistent, and hard to scale. Recruiters told us their biggest bottleneck is first-round signal, not sourcing. Candidates said the process feels subjective and repetitive. We set out to build a privacy-first, multimodal interviewer that feels human, scores transparently, and only forwards the most promising applicants—without storing raw video by default.
What it does
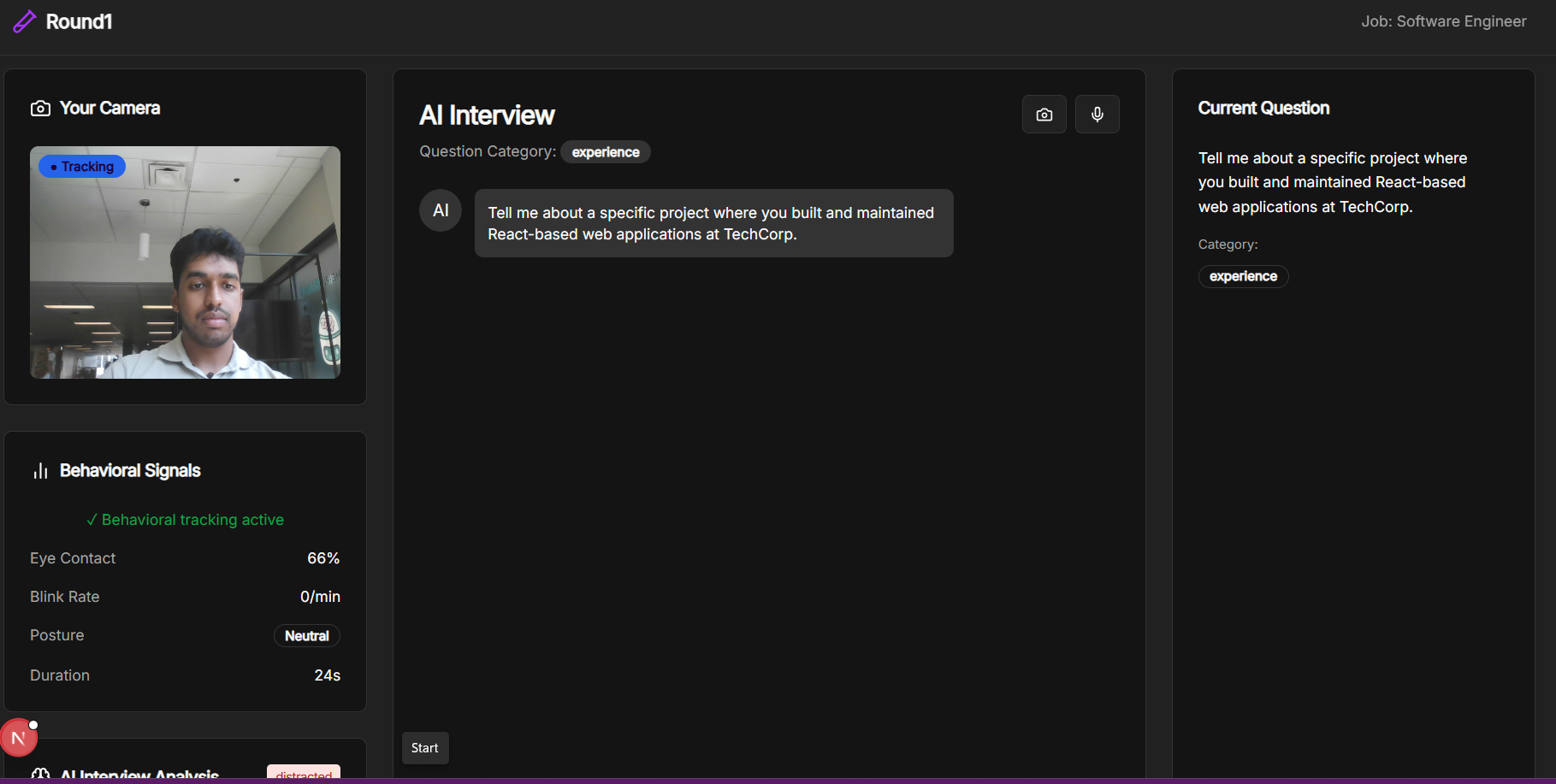
Simulated Interviewer: Role-aware questions (role fit, project deep-dive, behavioral, light technical), with targeted follow-ups.
Speech + CV signals (on-device):
Speech: clarity, relevance, completeness (via LLM on transcripts).
Computer vision: eye-contact %, blink rate, head stability, posture lean (MediaPipe).
Optional Roboflow snapshots: attentive / distracted / away / second-face flag.
Resume parsing: Extracts skills/experience to contextualize questions and scoring.
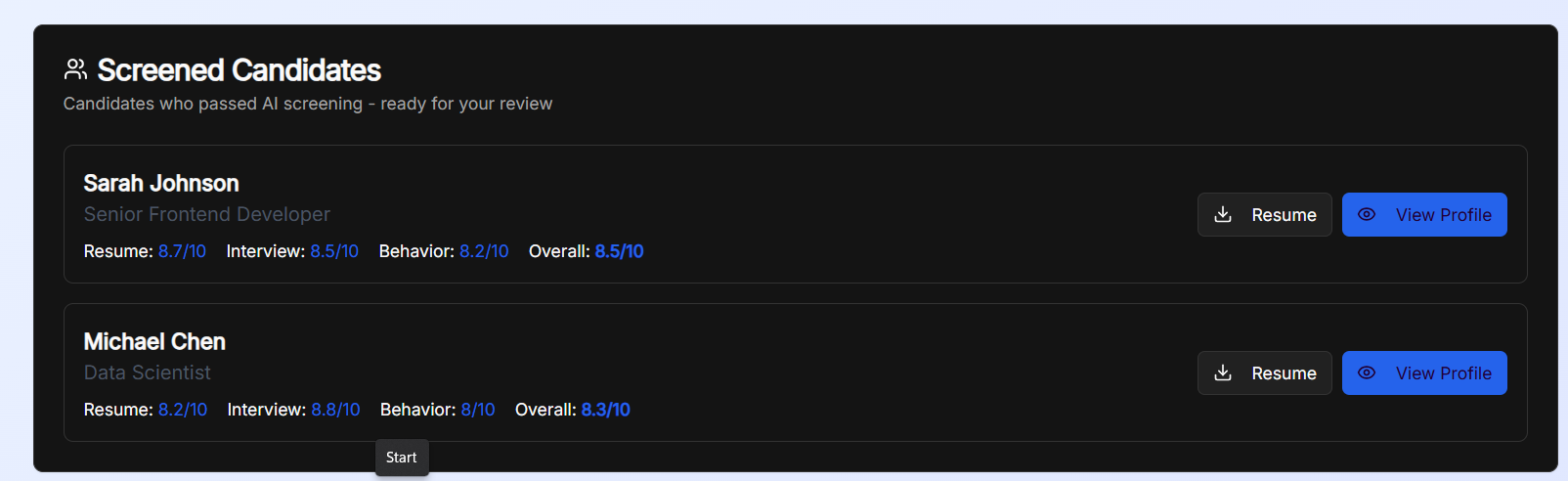
Scoring & Summary: Per-answer and final scores, concise candidate profile, pass/fail vs. job threshold.
Recruiter dashboard: Transcript, per-metric charts, flags, one-click Forward or Reject with feedback.
How we built it
Frontend: Next.js + Tailwind (single app with role-gated routes), getUserMedia for mic/cam, MediaRecorder per-answer.
On-device CV: MediaPipe Tasks (Face & Pose Landmarker) at ~10 FPS → feature aggregates only (no frames).
(Optional) Roboflow: Lightweight browser classification for environment check & engagement snapshots (1 FPS).
Speech-to-Text: Batch per answer (Whisper / Google STT) via Firebase Cloud Functions.
LLM: Interviewer follow-ups + rubric scoring (prompted to return strict JSON).
Backend: Firebase Auth, Firestore (interviews/messages/scores), Storage (optional raw audio), Functions for STT/LLM/scoring.
Charts: Chart.js for behavior/time series.
Privacy: Store transcripts + aggregates; raw media off by default with explicit toggle.
Challenges we ran into
Browser quirks: Autoplay/permissions, device differences, keeping stable FPS.
Latency budget: Balancing batch STT (simple) vs. user-perceived responsiveness.
Normalization: Head-stability varies by camera/FOV; added min–max and sanity gates.
Fairness: Avoiding demographic proxies; keeping only behavior aggregates and exposing the rubric.
Model hosting: Serving .task files locally to avoid CDN hiccups.
Accomplishments that we're proud of
Shipped a true multimodal pipeline in <24h end-to-end.
Privacy-first CV (features, not pixels) that still produces useful signals.
Transparent, math-backed scoring that recruiters can tune.
Clean, role-gated UX: candidate flow → recruiter dashboard with actionable summaries.
What we learned
Multimodal ≠ heavy: On-device landmarks + simple aggregates provide strong signal.
Prompting is product: JSON schemas + short, role-aware prompts keep LLM outputs reliable.
Latency > complexity: Batch STT per answer hits the sweet spot for an MVP.
Explainability builds trust: Showing how scores are computed reduces skepticism.
What’s next for Round1
Voice & flow: Streaming TTS for the interviewer; smarter follow-ups.
Fairness & calibration: Small human-rated set for scaling/offsets; bias audits & model cards.
Integrations: ATS export (Greenhouse/Lever), Slack/Email webhooks.
Signals: Gesture/nod detection, gaze stability, multilingual STT, better environment QA via Roboflow.
Enterprise: Admin controls, audit logs, data retention policies.

Log in or sign up for Devpost to join the conversation.