-
-
-
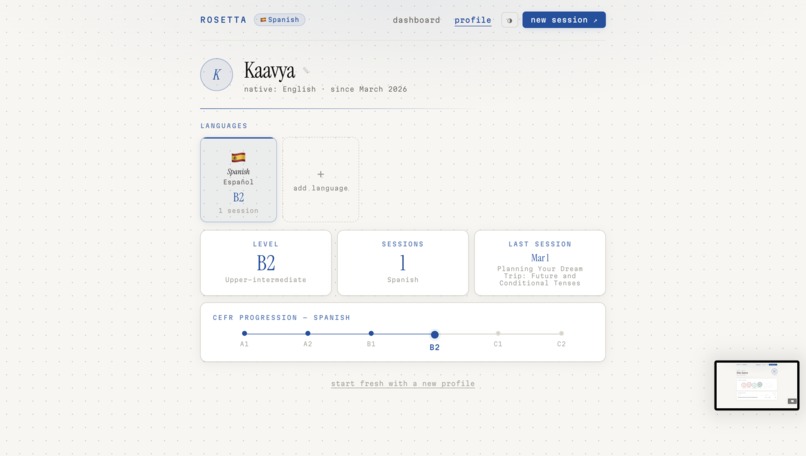
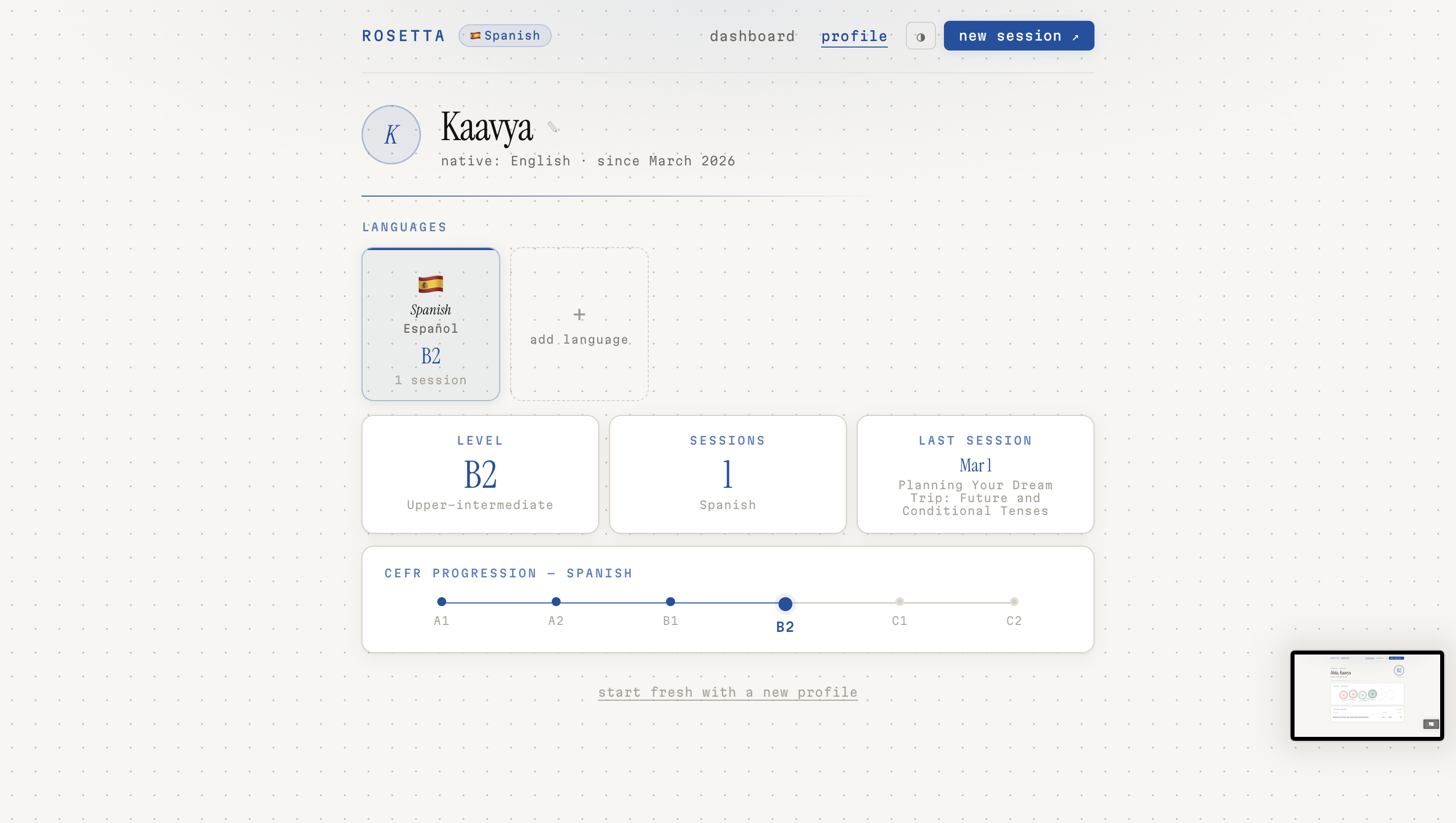
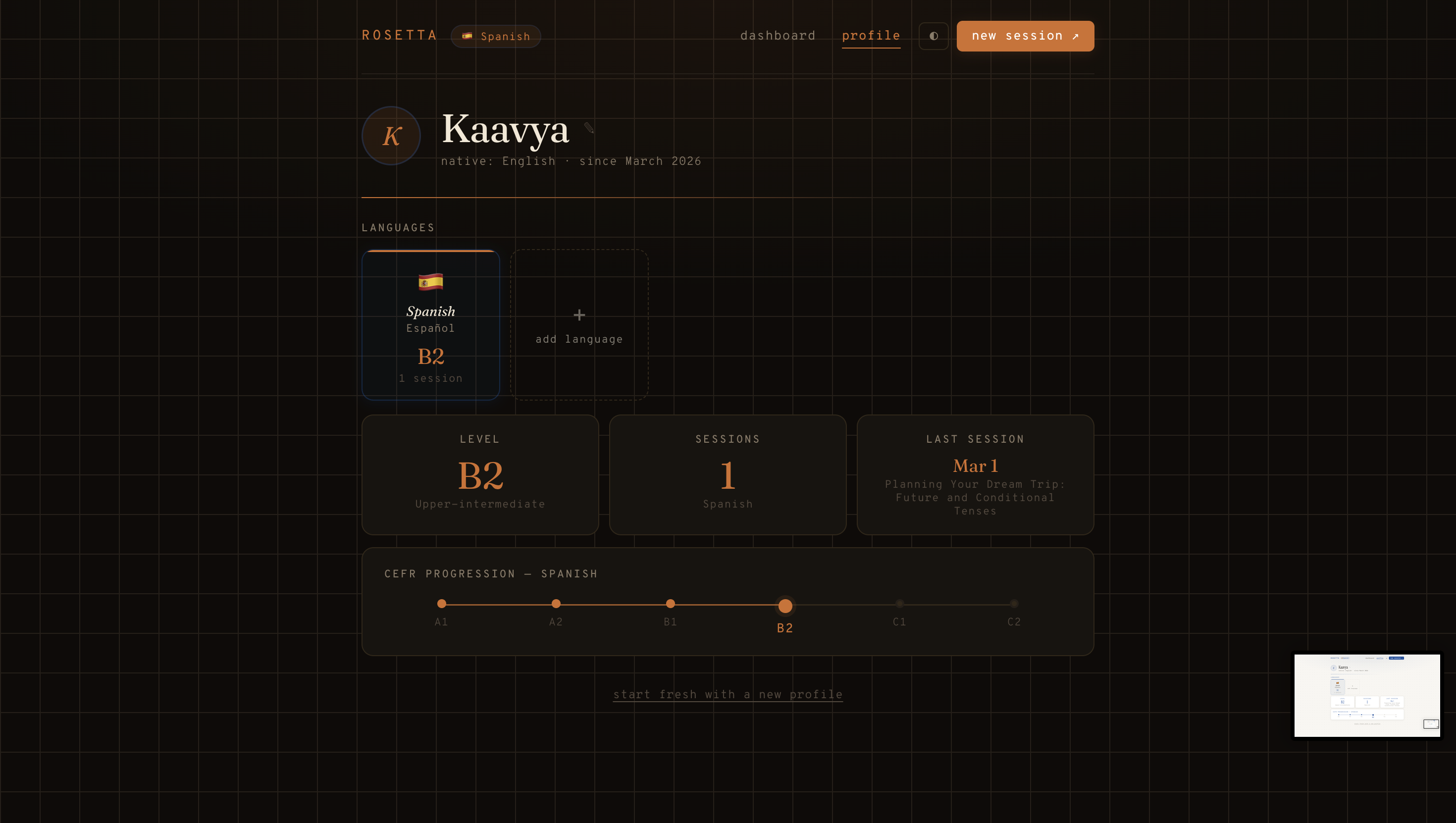
Profile
-
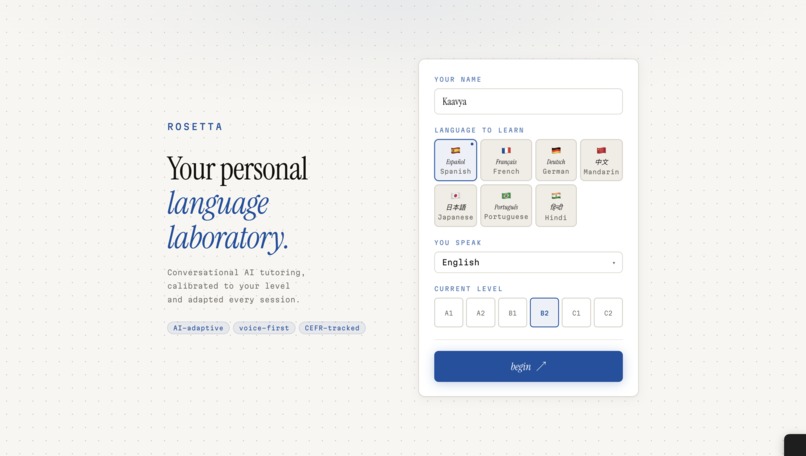
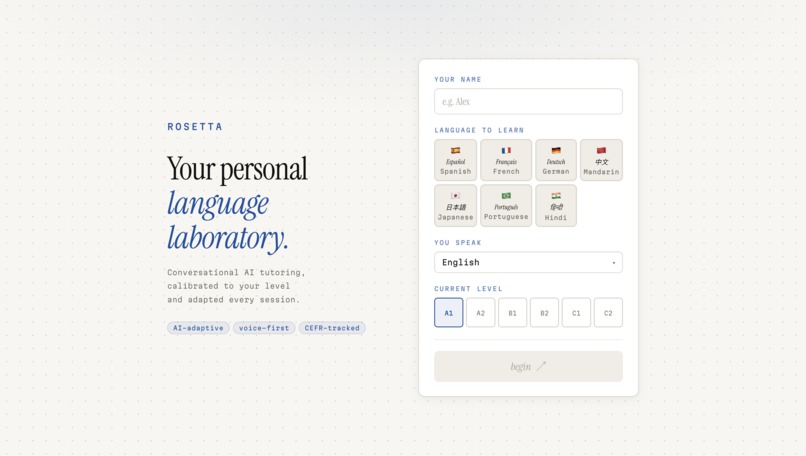
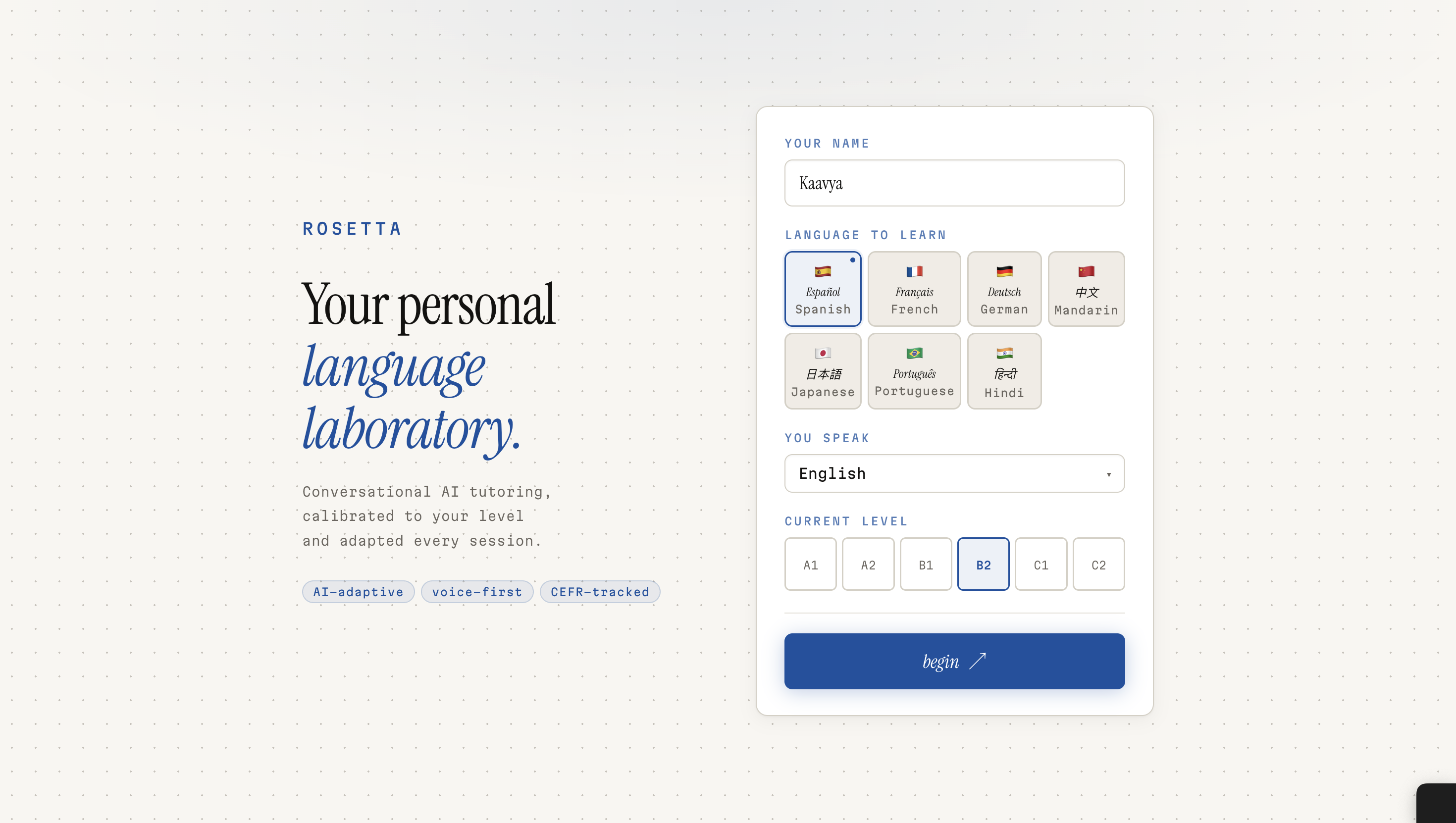
Onboarding
-
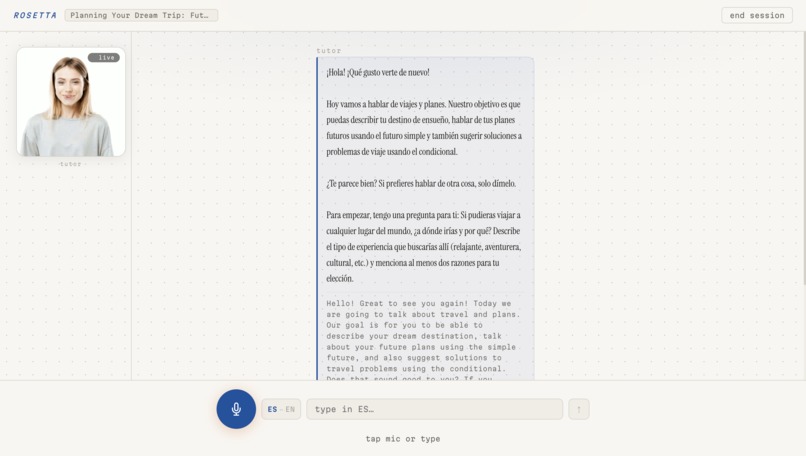
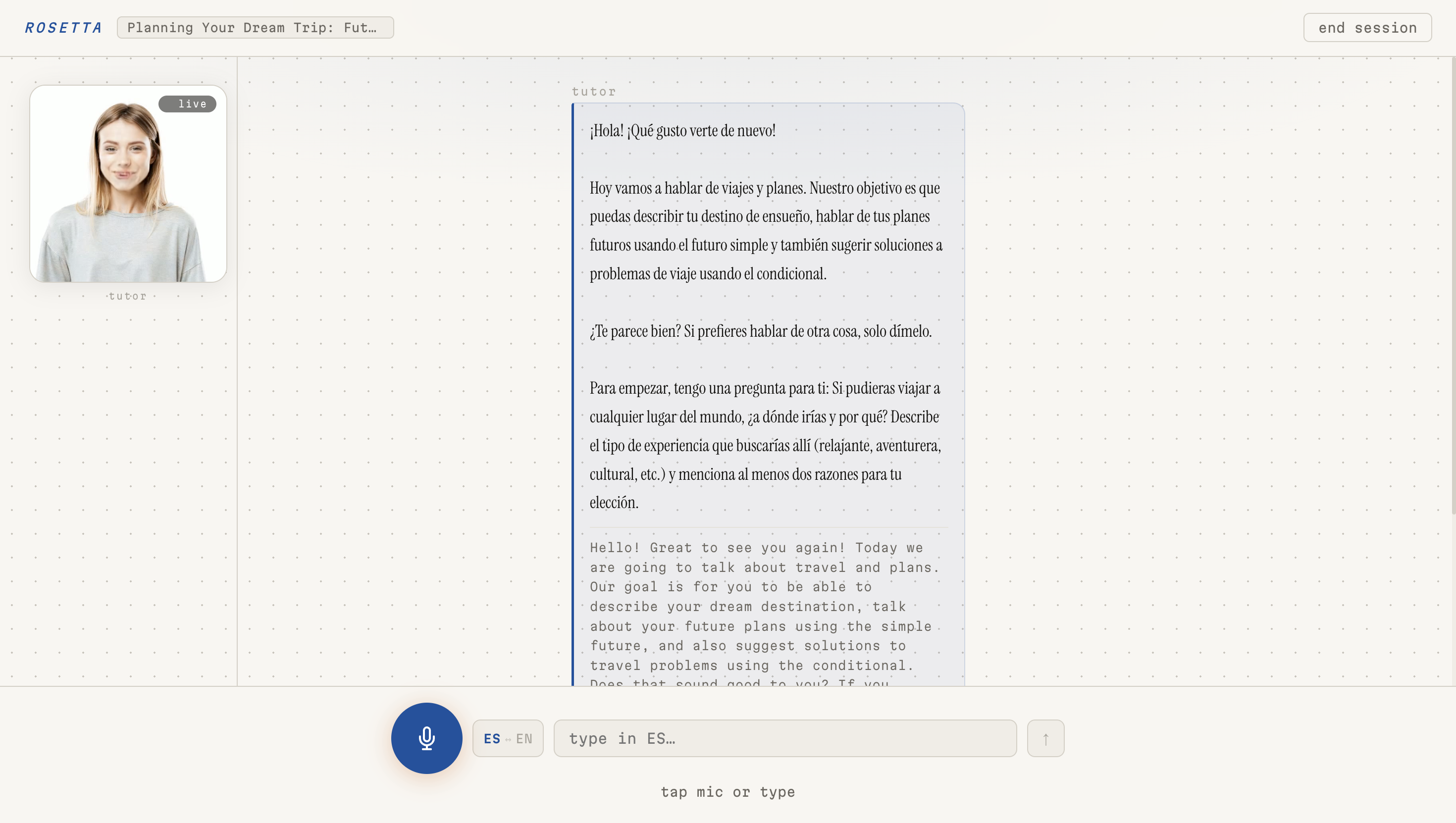
Session w/ Audio and Lip-Synced Tutor
-
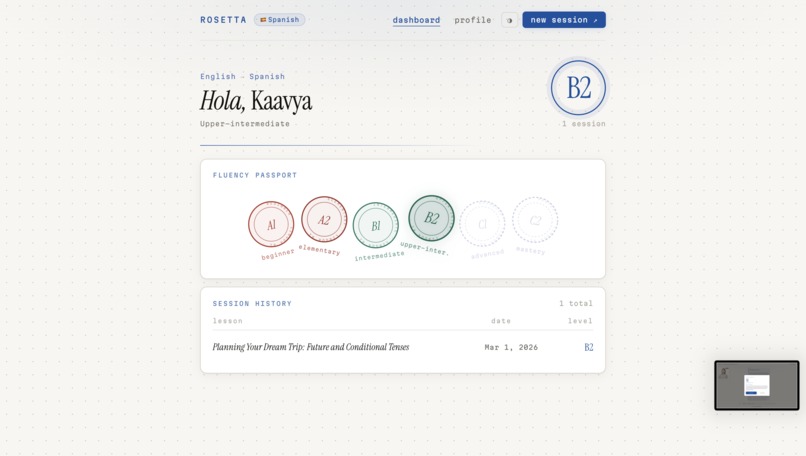
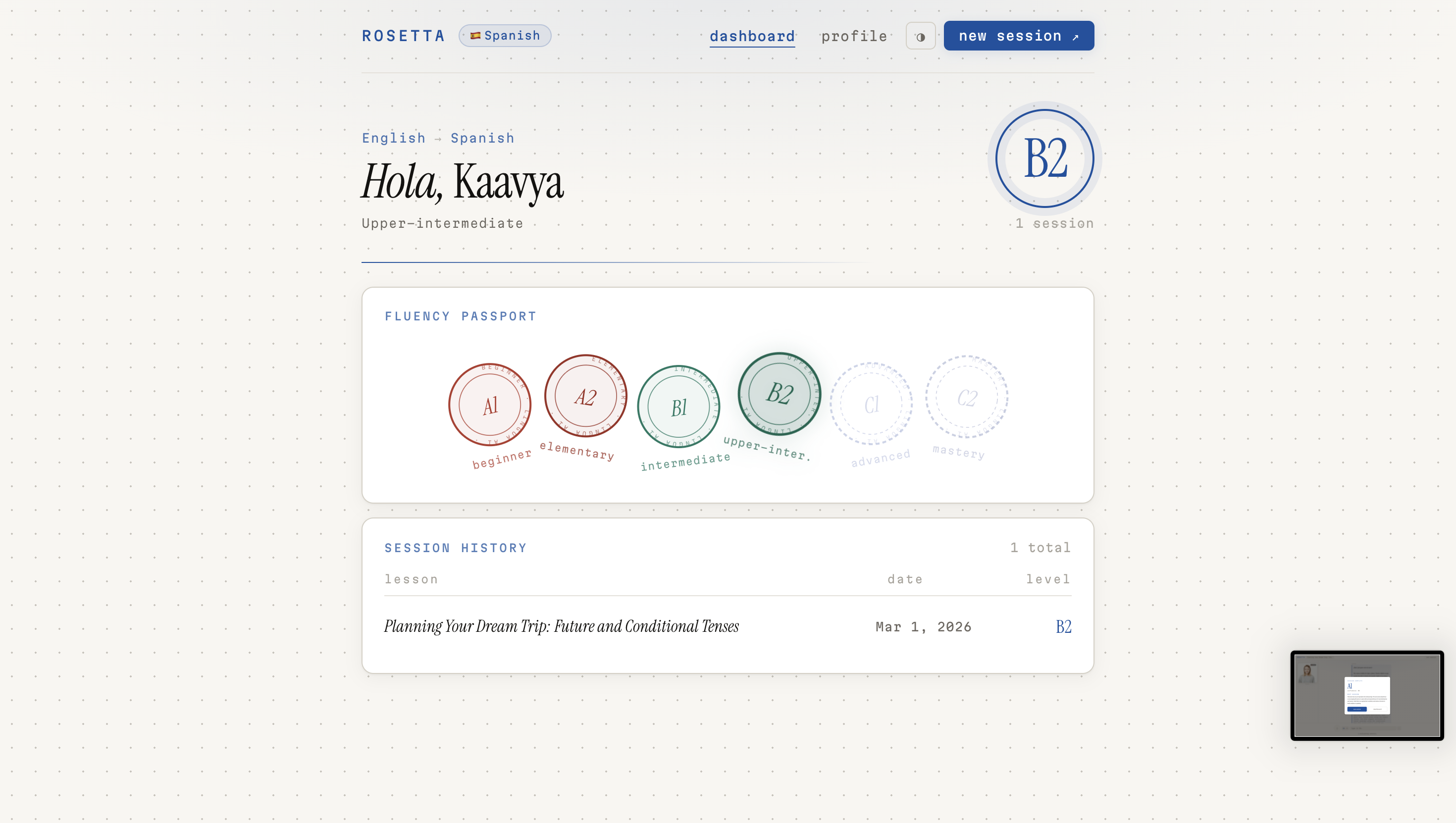
Dashboard
-
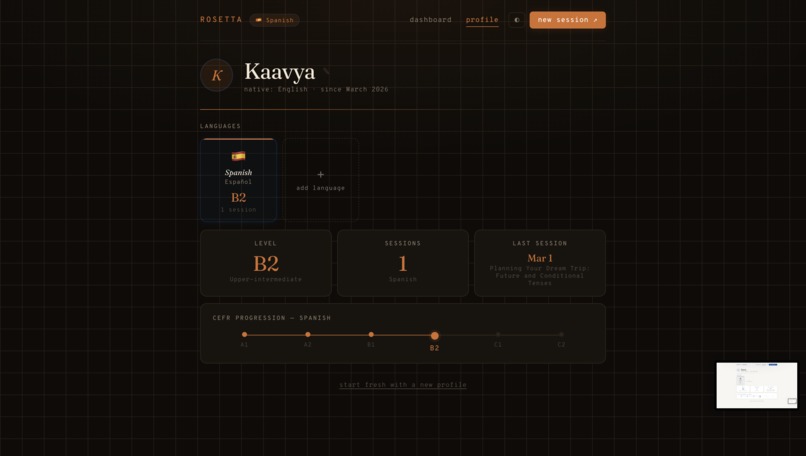
Dark Mode!
-
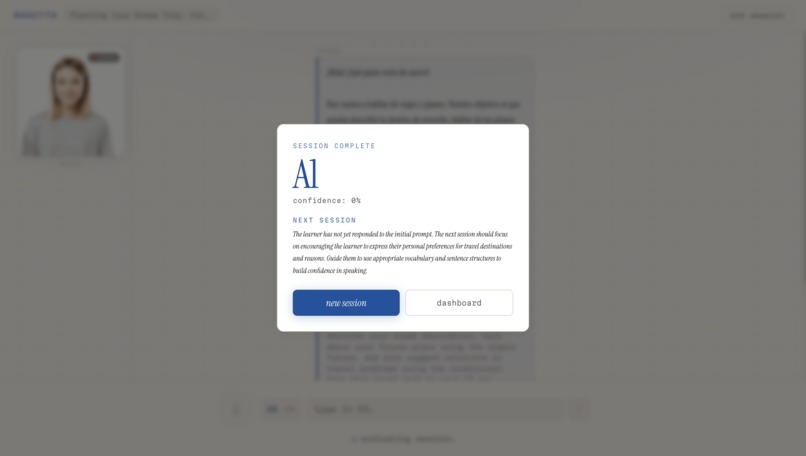
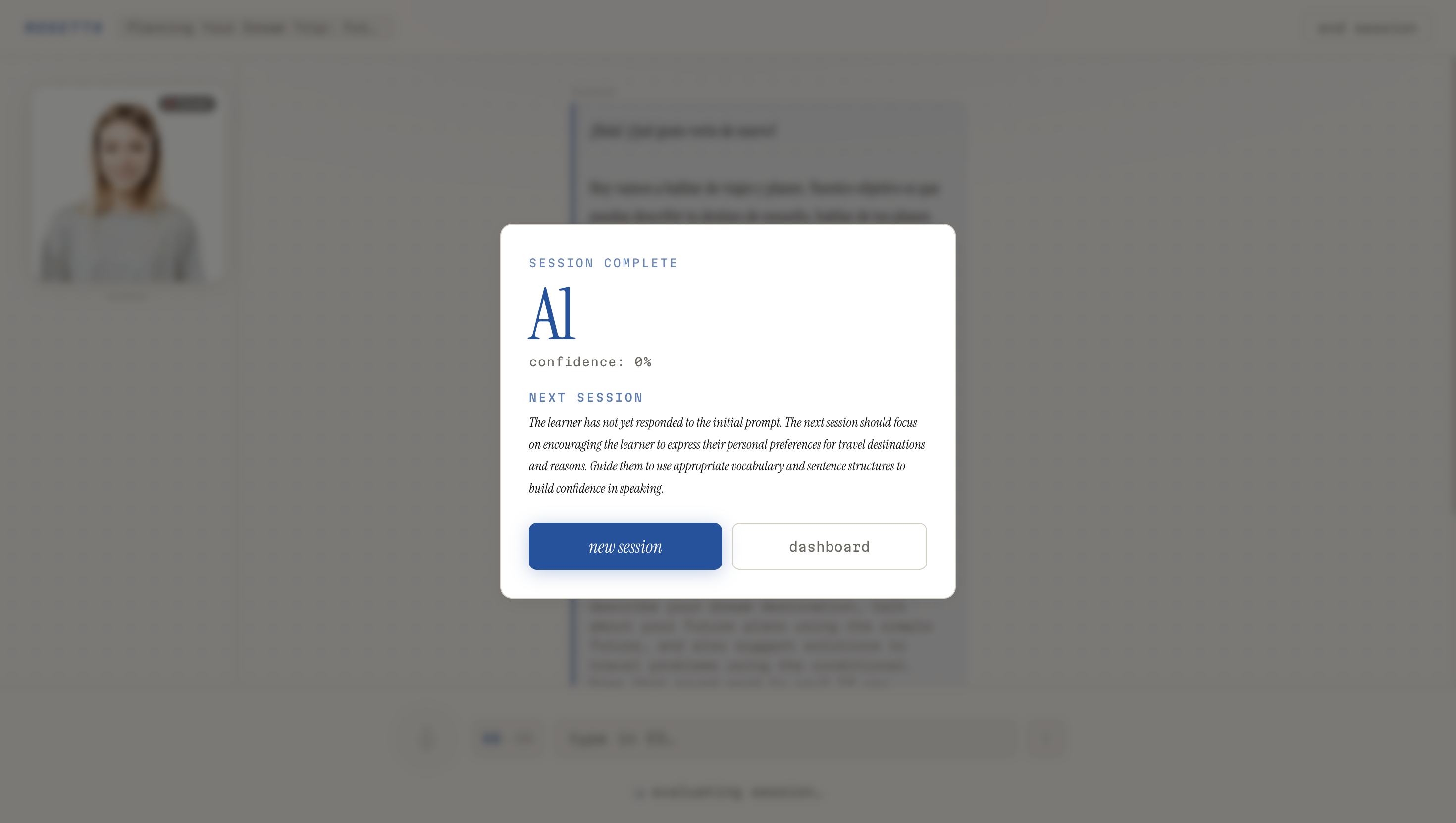
Session Feedback + Future Goals
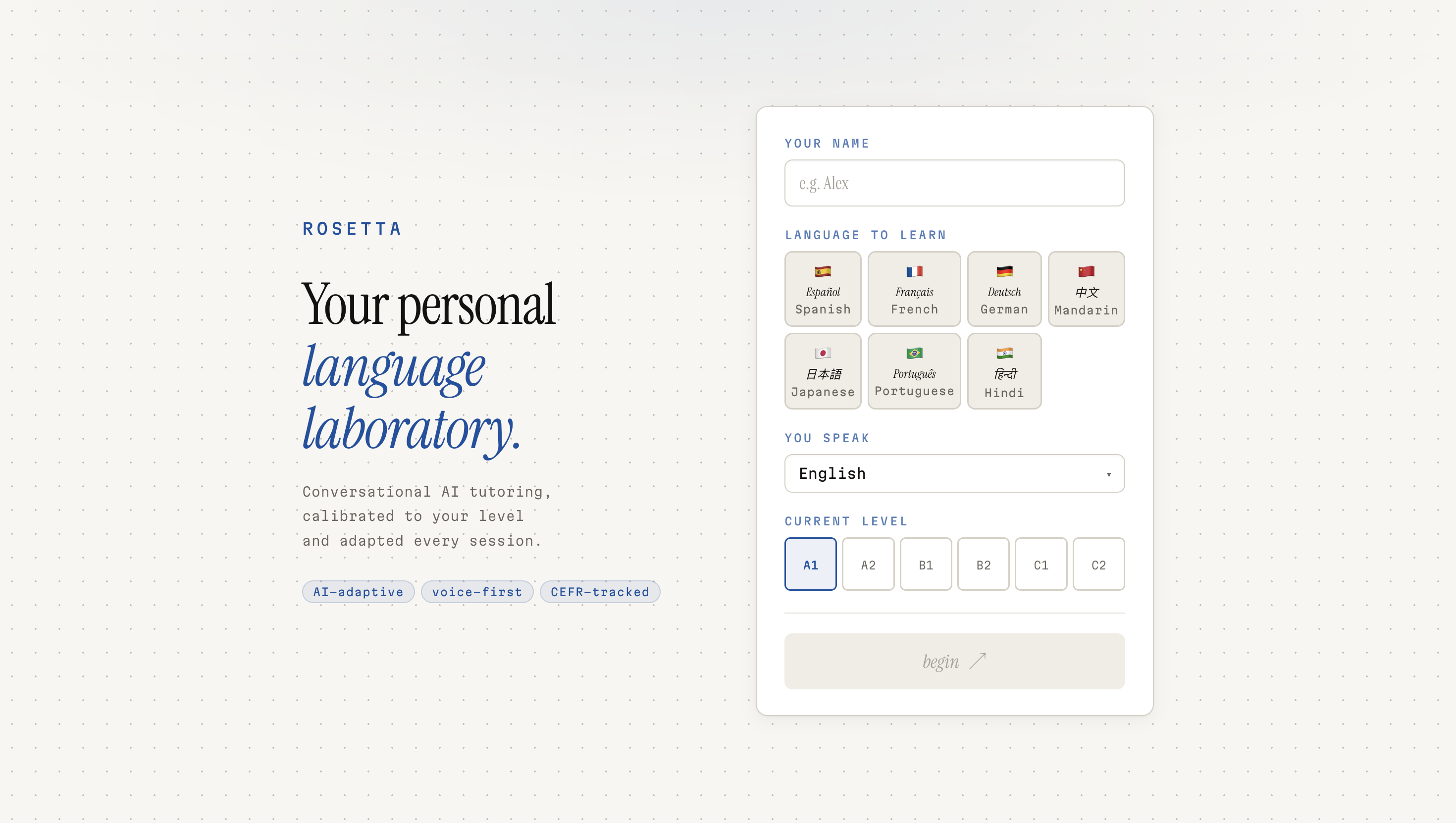
The Story Behind Rosetta
Inspiration
It started with Gujarati.
It's a language spoken by tens of millions of people — but if you go looking for it on the major language learning platforms, you'll find almost nothing. No structured courses, no audio practice, no conversational tools. For a language with that kind of reach, the gap felt almost absurd.
That was the seed. But the frustration went deeper than just which languages were supported. The dominant paradigm in language learning apps — the rigid, gamified, lesson-by-lesson drip of content — never sat right with us. Real language acquisition doesn't happen in neat little modules. It happens in conversation: messy, adaptive, contextual. And yet every tool on the market either locks you into a fixed curriculum or throws you into a raw chatbot with no pedagogical backbone whatsoever.
I wanted something in between. Something that understood how people actually learn languages — grounded in frameworks like CEFR, built around real conversational practice — but flexible enough to meet you where you are, not where the app decided you should be. A tutor, not a worksheet.
That's Rosetta.
What I Built
Rosetta is a full-stack AI language tutor with a live talking-head avatar, voice input and output, and an adaptive lesson engine that builds a personalized plan from the moment you arrive.
Here's how a session works: you tell Rosetta what language you want to learn, your native language, and a bit about your goals. It assesses your level, maps you to a CEFR band, and generates a structured lesson plan — not a generic one, but one tailored specifically to you. Then you talk. You speak into the mic, Rosetta listens, responds through a lip-synced animated tutor, and speaks back in your target language. At the end of each session, an evaluator scores your performance across multiple dimensions and feeds that back into your progression arc.
Under the hood, the stack is doing a lot of heavy lifting:
- Frontend: React + Vite, with a split-panel layout — animated avatar on the left, live conversation on the right
- Backend: FastAPI with server-sent events (SSE) for real-time streamed responses
- LLM: Gemini API, handling the planner, tutor, and evaluator roles with structured outputs
- Speech: Gemini's STT and TTS APIs — one model for speech-to-text, per-language VITS models for text-to-speech
- Talking head: Wav2Lip running on an A10G GPU via Modal, with a D-ID fallback for reliability
- Database: MongoDB Atlas, storing user profiles, lesson plans, transcripts, and evaluations
And about Gujarati specifically — because MMS supports over 1,100 languages natively, adding Gujarati support is genuinely a one-line config change. The architecture wasn't built around the languages we support — it was built so that the language list is almost beside the point.
How I Built It
A lot of Rosetta existed in our heads before a single line was written. The architecture — the three-agent LLM pattern, the audio pipeline, the streaming layout — was sketched out mentally before I touched the keyboard. Getting to watch it actually assemble into something real was one of the more satisfying parts of this process.
The build was a great experience. While the backend systems and AI integration came together on one side, the design and frontend experience were shaped by a keen desire for a specific experience as to how the product felt. And all our elements — the avatar panel, the session flow, the dashboard — were geared towards ensuring that Rosetta looked and behaved like something people would actually want to use, not just a technical demo.
What surprised us most was how composable everything was. Chaining together a GPU inference service, a streaming LLM, a speech pipeline, and a real-time frontend sounds like a months-long project on paper. In practice, with the right abstractions and infrastructure, it came together in a weekend. That's not because the problems are easy — they're not — it's because the tooling has quietly gotten extraordinary. The bottleneck is genuinely just: do you have the idea, and are you willing to put in the work?
Challenges
The audio pipeline was the first real wall I hit. Getting audio from the browser — recorded as WebM/Opus — into a format that the Gemini API could actually work with required normalization, resampling to 16kHz mono WAV, and careful handling of edge cases around silence and encoding. A lot of "why is the STT returning nothing" debugging lived here.
Cold starts on Modal were a recurring friction point. Spinning up a GPU-backed service from cold takes time, and in the context of a conversational app where latency is felt immediately, that gap is noticeable. I worked around it, but it's the kind of thing that would need warm pool management at scale.
Making the LLM pedagogically coherent was harder than expected. It's easy to get an LLM to have a conversation. It's much harder to get it to have a conversation that's calibrated to a specific CEFR level, stays in the target language at the right ratio, introduces vocabulary intentionally, and corrects errors without breaking flow. Getting the tutor prompt right went through a lot of iterations.
The talking head integration involved two different services (SadTalker and D-ID) with different APIs, different latencies, and different failure modes — building a clean fallback layer between them without the frontend ever knowing which was running took some care.
What I Learned
The clearest lesson was about the nature of modern AI development: the hard part is no longer access to capability. The hard part is clarity of thought — knowing precisely what you want the system to do, and being disciplined enough to build toward that rather than just seeing what the model produces. The infrastructure is there. The models are there. What matters is the idea, and the care with which you execute it.
I also came away with a deep appreciation for how underserved regional and minority languages are in the current edtech landscape — and how little technical justification there is for that gap anymore. Rosetta doesn't support Gujarati yet in its live demo, but it could, in minutes. That's the point.
Language learning shouldn't be a privilege of speakers of globally dominant languages. That's what Rosetta is trying to change.




Log in or sign up for Devpost to join the conversation.