
Inspiration
Motivated by the economic opportunities presented by generative AIs and Large Language Models (LLMs), as highlighted in the McKinsey research, we recognize the challenges businesses face in managing vast volumes of text and voice data resulting from customer interactions. Effectively addressing these challenges requires leveraging advanced technologies such as LLMs to gain deeper insights into customer needs and elevate their overall experiences.
Despite the evident advantages of employing LLMs, concerns related to computational infrastructure, data privacy, and security often act as barriers for enterprises looking to integrate these technologies into their operations. Fortunately, the DataBricks platform emerges as a comprehensive solution, addressing these concerns and thereby enabling businesses to fully harness the potential of LLM applications. This unlocks the capability to analyze customer intent and topics, providing valuable insights that contribute to an enhanced understanding of customer interactions.
What if ?
Imagine a future where enterprises seamlessly harness their data with Large Language Models (LLMs) without any worries about data privacy, security, hardware compute, scalability, data interoperability across various platforms, model hosting, and model experimentation. In this project, we explore the possibility of establishing a framework/pipeline and run on Databricks that provides easy access to the required data, supports a scaled system equipped with GPUs for both LLM model fine-tuning and serving, and addresses various concerns related to data utilization.
What it does
Contact Catalyst offers a state-of-the-art, highly customizable pipeline that empowers businesses to analyze customer conversation data in an automated fashion using advanced LLM capabilities. Our solution powered by DataBricks provides several unique and powerful features that include:
- Intent Classification - Label and categorize customer conversations according to a pre-existing set of labels informed by the business context.
- New Topic Detection - Ability to detect novel customer conversation topics as they arise in real-time, enabling businesses to stay ahead of the curve.
- Content Summarization - Condense complex conversations into a narrative format that captures essential details in the structure of situation, action and outcome. This process distils key information and facilitate the input of summarized data into downstream models for tasks such as classification or clustering.
- Sentiment Analysis - Whether a customer conversation is positive, neutral, or negative, providing deep insights into customer satisfaction.
- Aggression Detection - Detection of aggressive language in customer conversations, allowing businesses to address customer concerns quickly, proactively and efficiently
How we built it
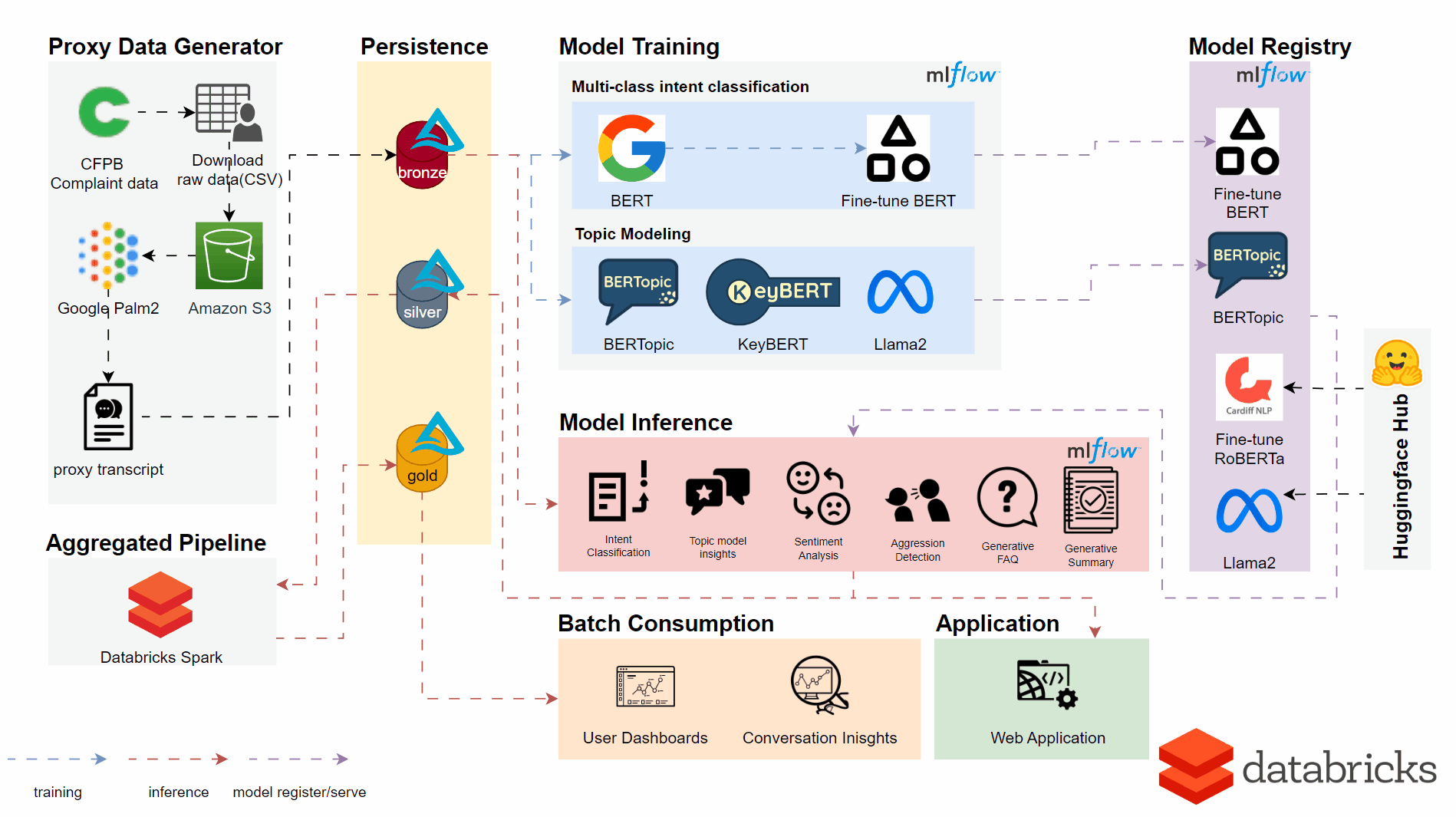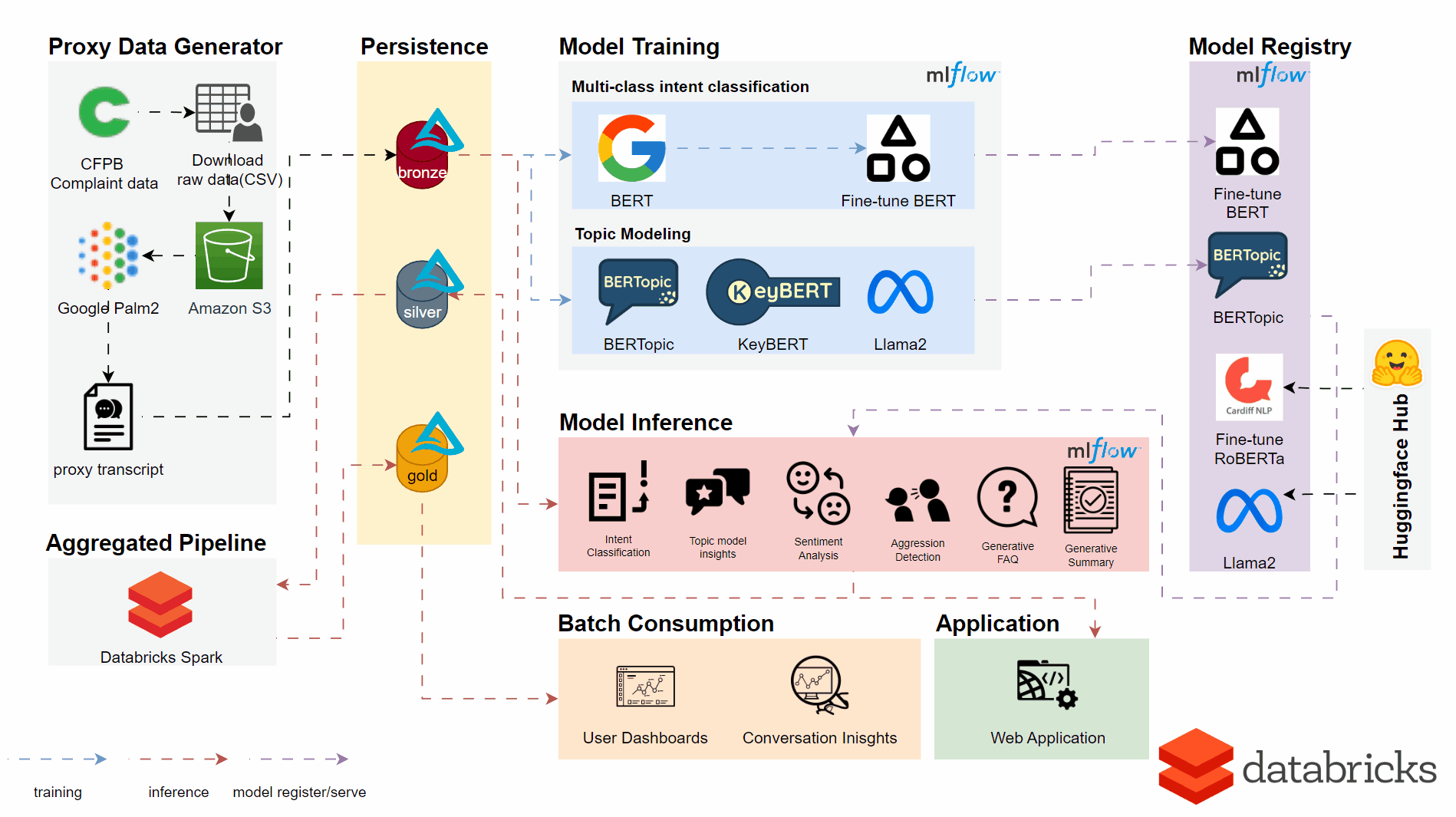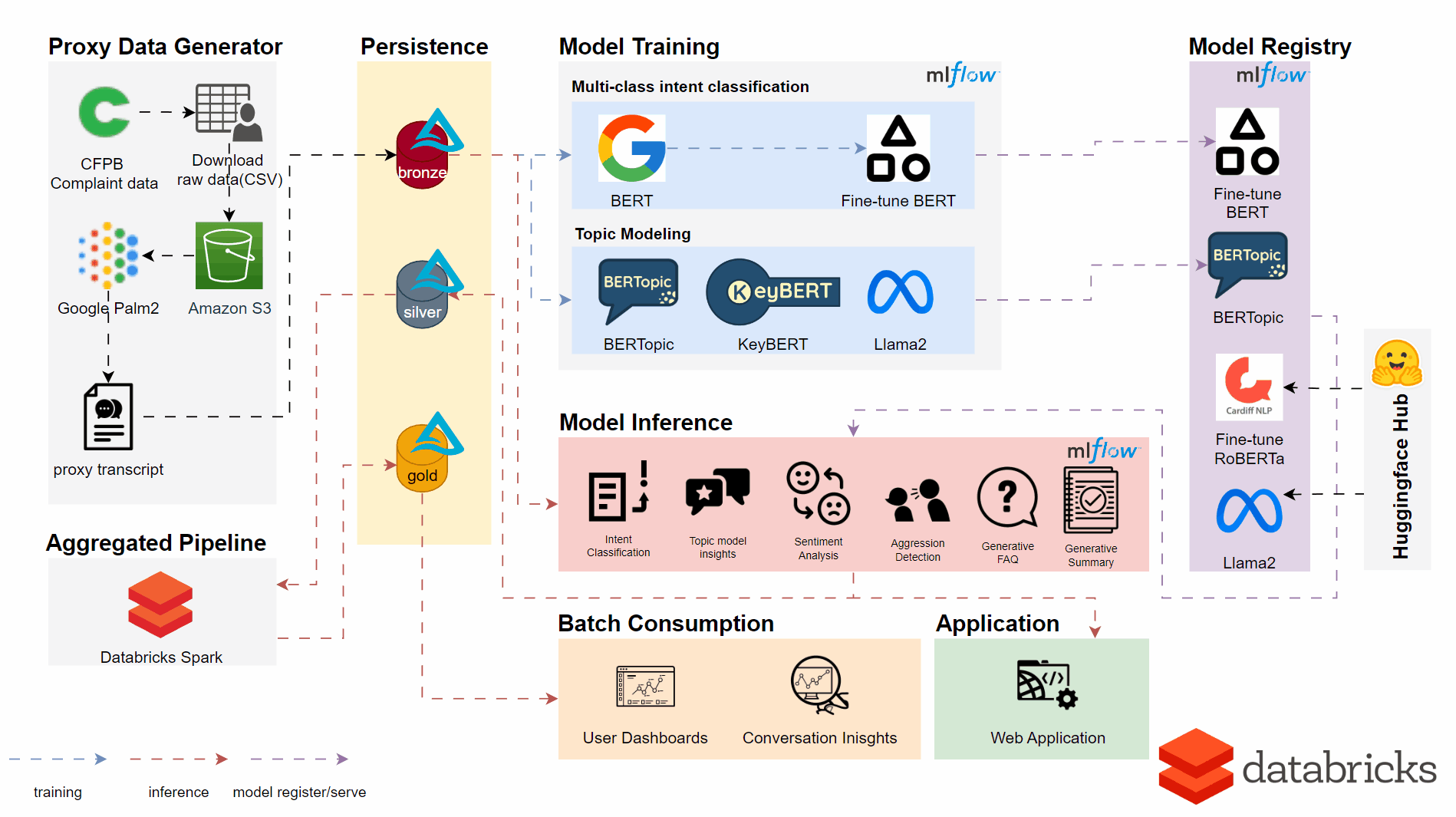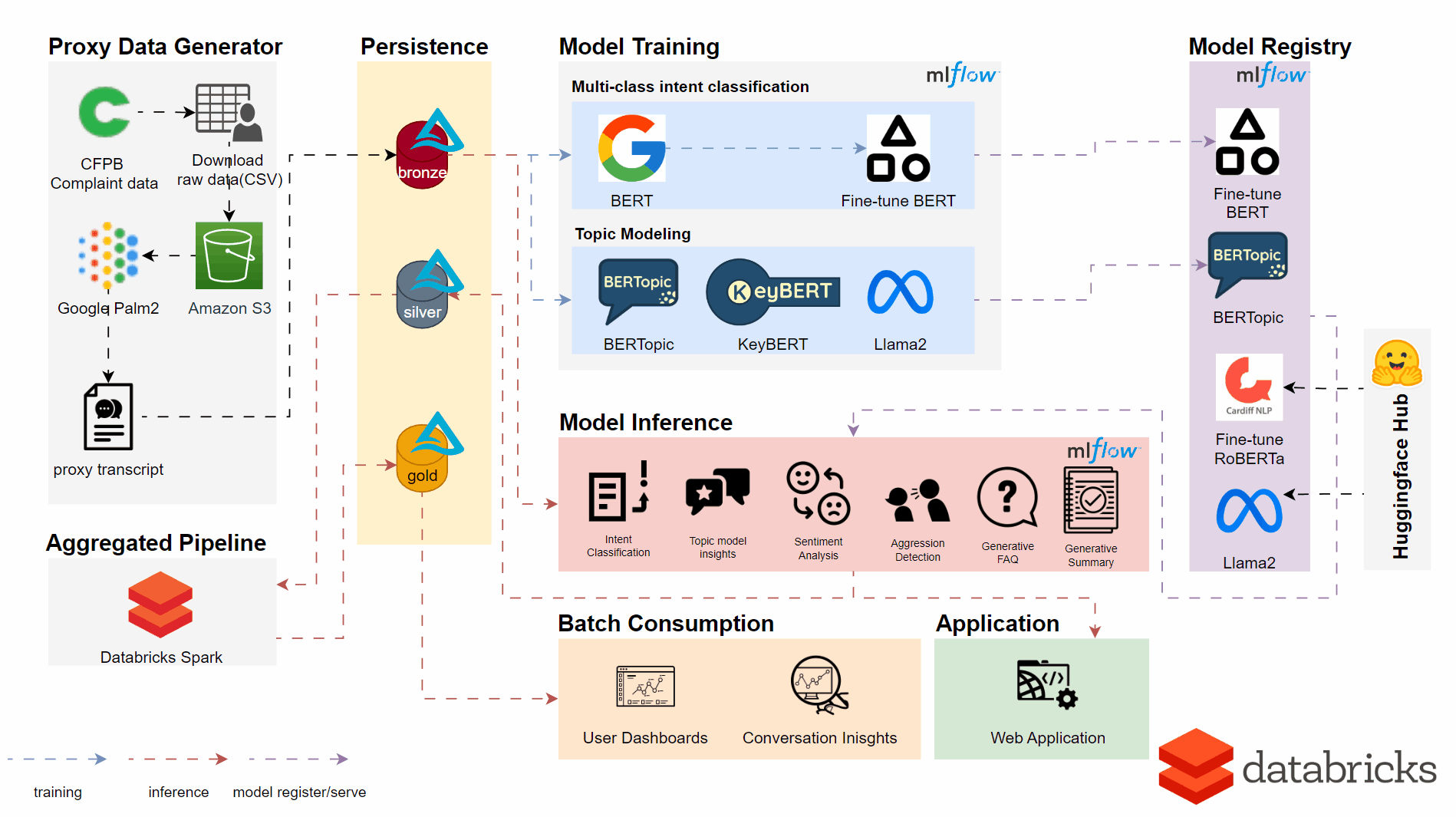
Utilising the DataBricks platform in the backend we made use of a number of techniques and models for respective user features and insights.
- BERTopic, KeyBERT & Llama2 API for New Topic Detection
- Fine-tuned BERT Model for Intent Classification
- Fine-tuned RoBERTa Model for Sentiment Analysis and Aggression Detection
- Llama2 API for generative AI content summarisation
- DataBricks Dashboard for an Analyst User Interface
- Gradio for the Web Application with both single transcript classification/batch upload functions
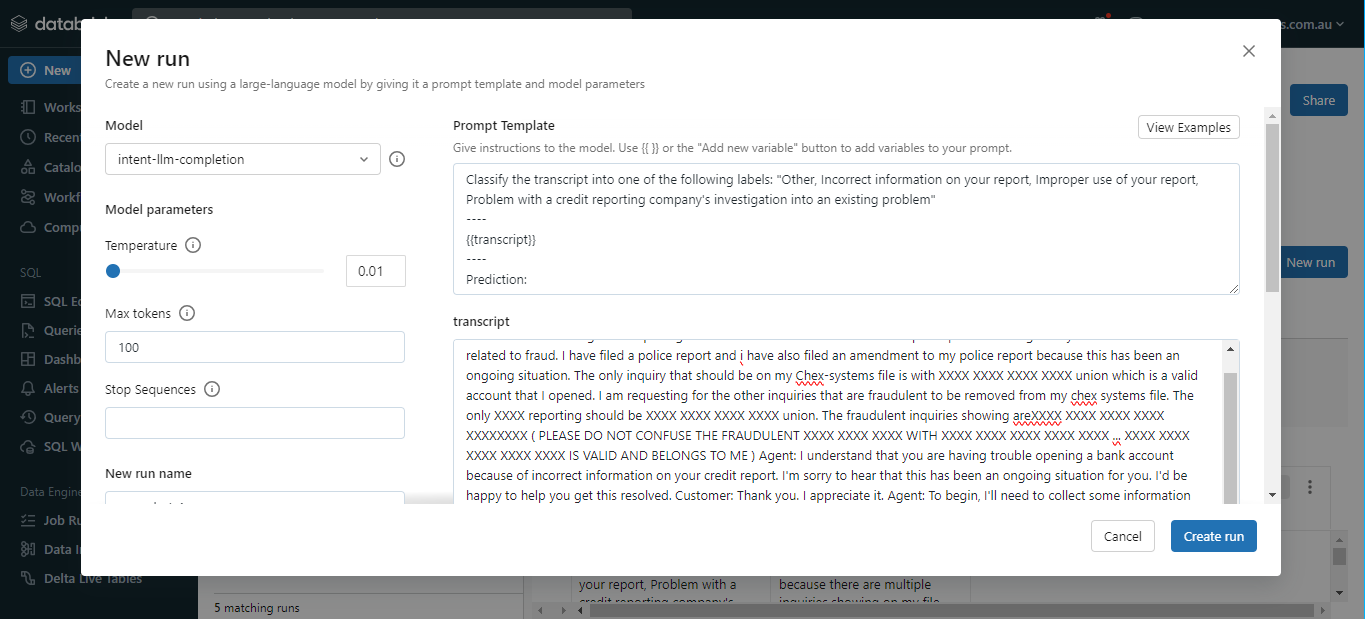
An overview of the implemented architecture and pipeline is seen below.

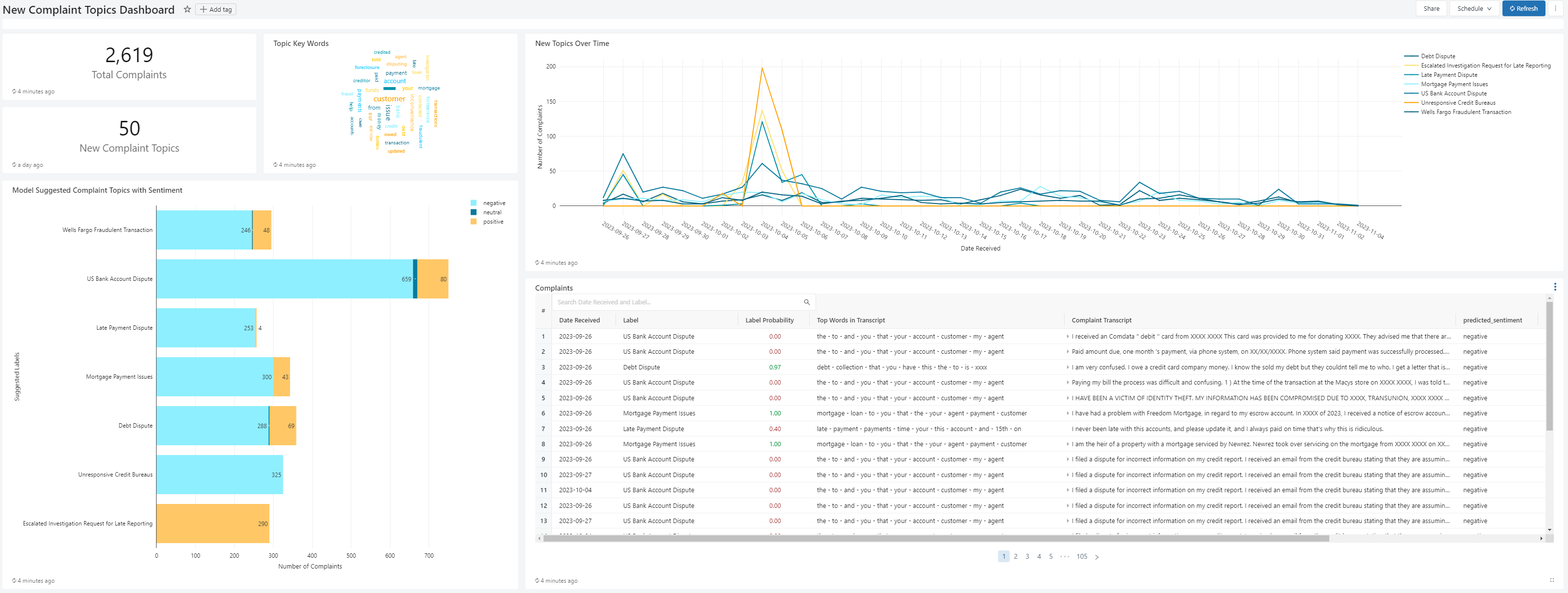
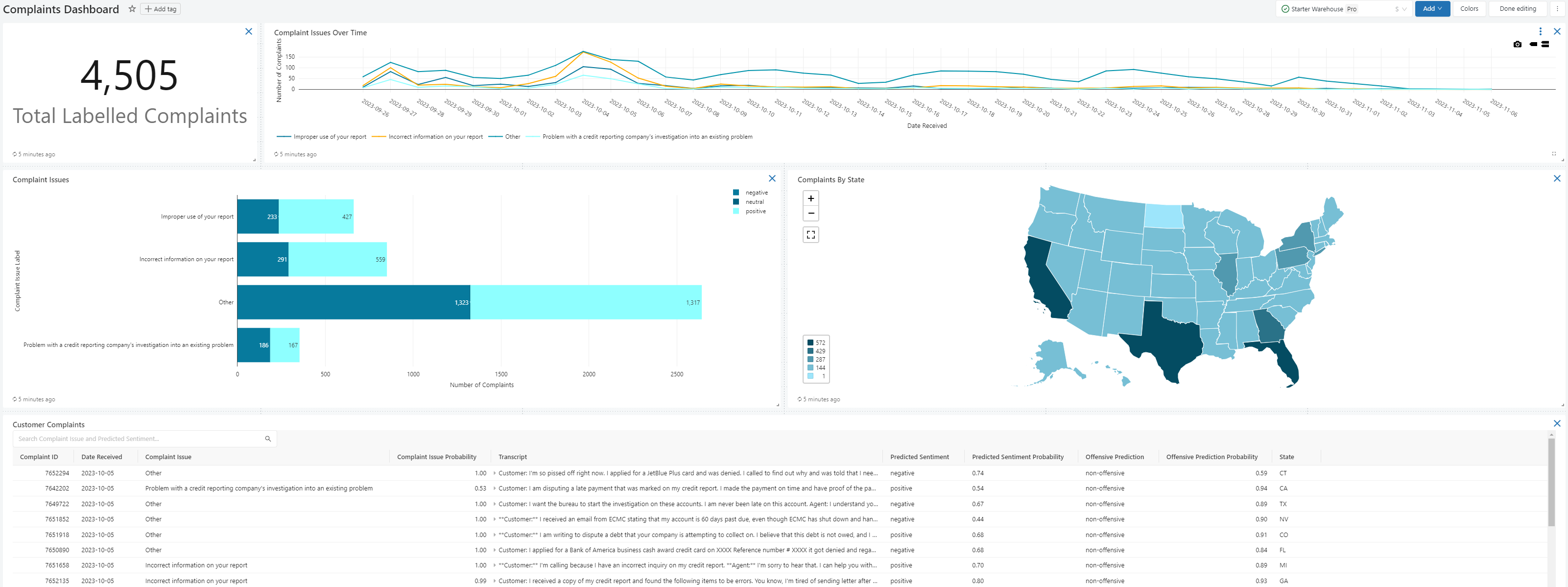
In the front-end we made use of the DataBricks Dashboard as a User Interface for analysts to delve into the pipeline insights. The two dashboard views can be seen below utilising the public complaint dataset from Consumer Financial Protection Bureau (cfpb) as the input to the pipeline.
- View 1: New Topic Detection Dashboard
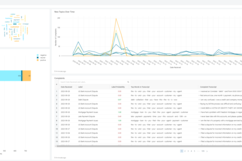
- View 2: Intent Classifier Dashboard
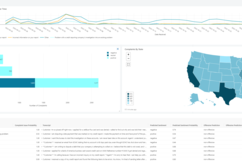
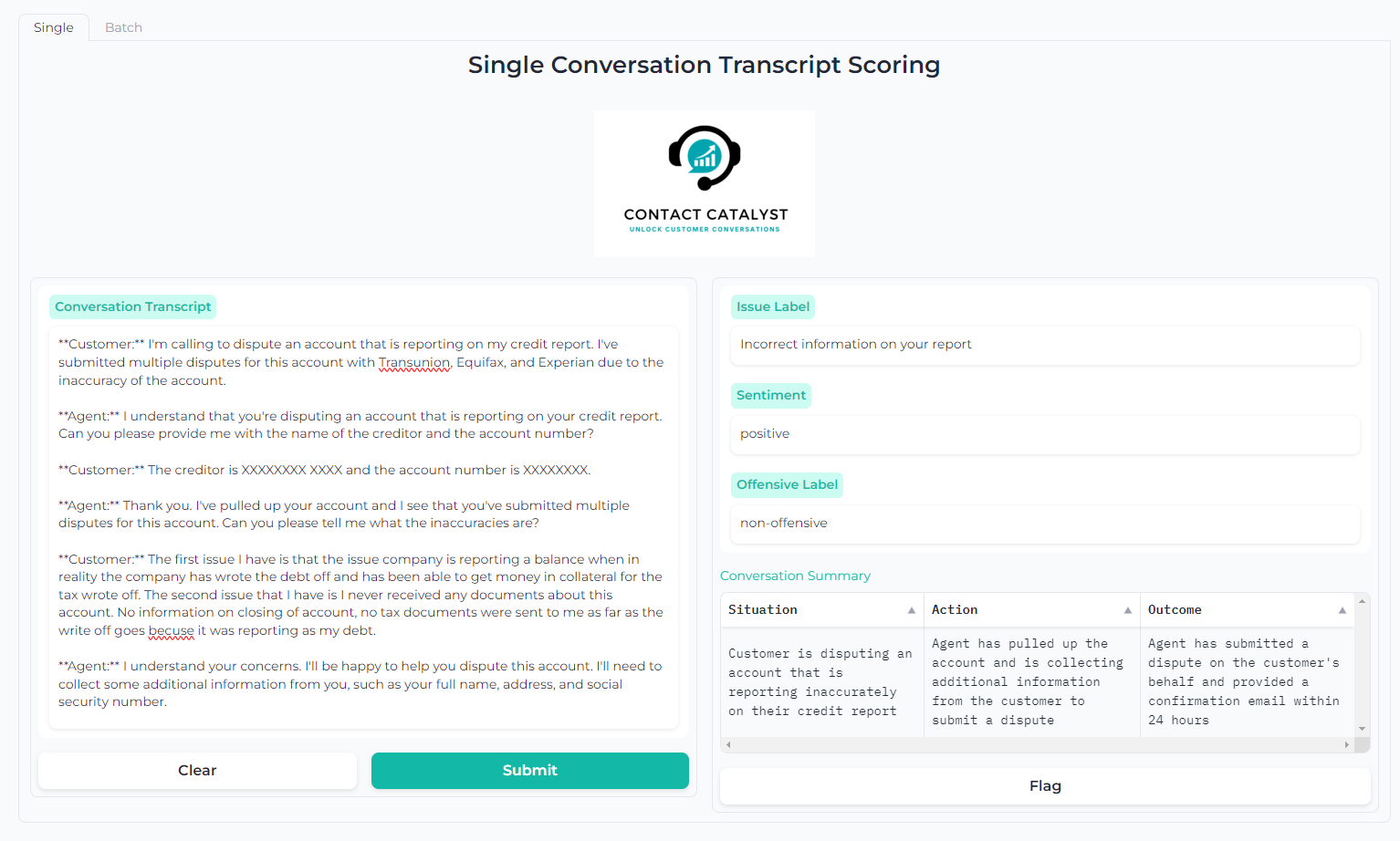
The second component of our front-end solution is a web application that allows users to perform single and batch transcript scoring using model serving endpoints. The interface can be seen below or within the demo video.
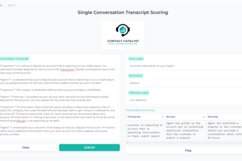
Challenges we ran into
1) Getting access to the Databricks environment which was promptly resolved by Databricks team.
2) Getting access to the blob storage which was resolved by Databricks team.
3) Considerations around a LLM POC for the business problem, as the following issues raised concern:
- No access to GPU to host LLM models.
- No business data to send to overseas [LLM API] To resolve this, we used a proxy generator to generate a business-like dataset and host LLM models in Databricks.
4) Zero-shot/few-shot learning from LLM did not perform as expected, with inaccurate output despite prompt engineering attempts. We opted for a fine-tuned BERT model instead that produced improved results.
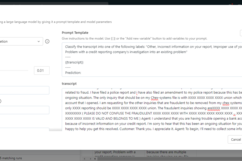
5) The web application couldn't receive the prediction Mlflow run. To resolve this, we setup model serving endpoints in Datbaricks to provide both real-time and batch-scoring capabilities.
6) Due to time constraints and the fact that all team members have full-time work commitments, we faced the challenge of not having enough time to explore and implement all of our ideas. To address this, we collectively decided to prioritize an iterative approach, leveraging each other's strengths, and making personal sacrifices by dedicating extra time to ensure project completion.
Accomplishments that we're proud of
Throughout the hackathon, we embarked on a remarkable journey, and we are immensely proud of what we achieved. Our team successfully designed and implemented an end-to-end pipeline, all of which was exclusively hosted on Databricks, covering a wide spectrum of tasks from the backend to the frontend.
Our accomplishments included:
Ideation and Architecture: We began with a robust ideation phase, followed by meticulous architectural planning, ensuring that our project was built on a solid foundation.
Data Generation and Pipeline: We created a data generation process and a seamless pipeline to ensure the smooth flow of data, which was crucial for our project's success.
Model Experiments and Fine-Tuning: Our team conducted extensive model experiments, iteratively refining and optimizing our machine learning models to achieve the best possible results.
Model Serving: We implemented a robust system for serving our models in real-time and batch load, ensuring their availability and responsiveness when needed.
Dashboard Building: To provide a user-friendly interface for our solution, we developed an intuitive dashboard, making it easy for end-users to interact with our data and insights.
Web Development: Our web development efforts helped us create a user-friendly web application that seamlessly integrated all components of our solution.
All these achievements were made possible through exceptional teamwork and strong collaboration. We couldn't be prouder of our dream team, whose dedication, skills, and enthusiasm were instrumental in our success. Additionally, we extend our heartfelt gratitude to the Databricks team for their invaluable support throughout this journey.
What we learned
- Technical Skills:
- The capabilities of the Databricks platform alongside the potential applications of LLM's in the customer conversation data space.
- Experiment with many different ML models and packages
- Databrick's dashboarding features as a front-end user interface.
- Building a gradio web application as a front-end user interface.
- Problem-solving skills
- The business problem is very complex; we had to iteratively break it down and innovate with LLMs to directly address the needs of the business use case.
- Learn to adapt, change and make quick decisions under time constraints.
- Resolve technical issues in a collaborative manner.
- Teamwork and Collaboration
- Collaborate effectively, manage tasks, leverage each other's strength and assist one another when faced with blockers and challenges.
- Presentation and Pitching
- Enhance our abilities in presenting, creating videos, and crafting compelling narratives.
What's next for Contact Catalyst
1) To enhance the capability of our web application to include the serving of the New Topic Detection Model as well as other features such as human feedback in the loop.
2) To implement the solution into production within business particularly at Optus. With the demonstration of the solution for our use case alongside recognition from the Databricks team professionals trust and confidence can be built to back the LLM solution to accelerate the AI development and production in our Unified Data Platform on Databricks.
Special Thank You to the Databricks Team
Brian Law, June Tan, Rabi Abbasi. We wanted to take a moment to express our sincere gratitude for the incredible efforts and support you have provided us throughout the hackathon journey.
Built With
- bert
- bertopic
- databricks
- gradio
- huggingface
- llama2
- mlflow
- palm2
- python









Log in or sign up for Devpost to join the conversation.