-
-
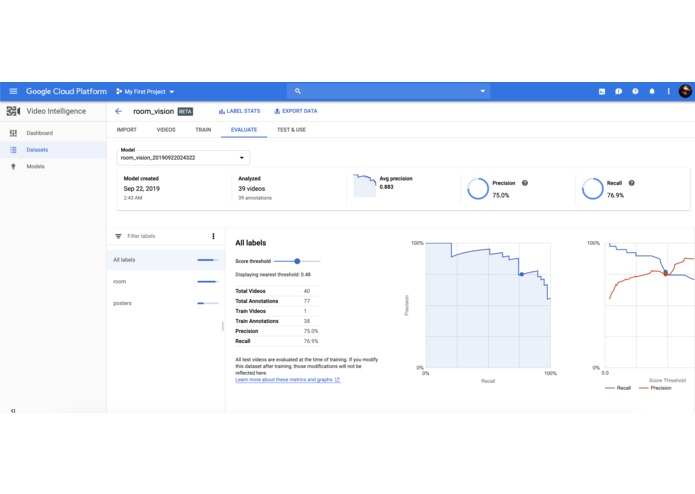
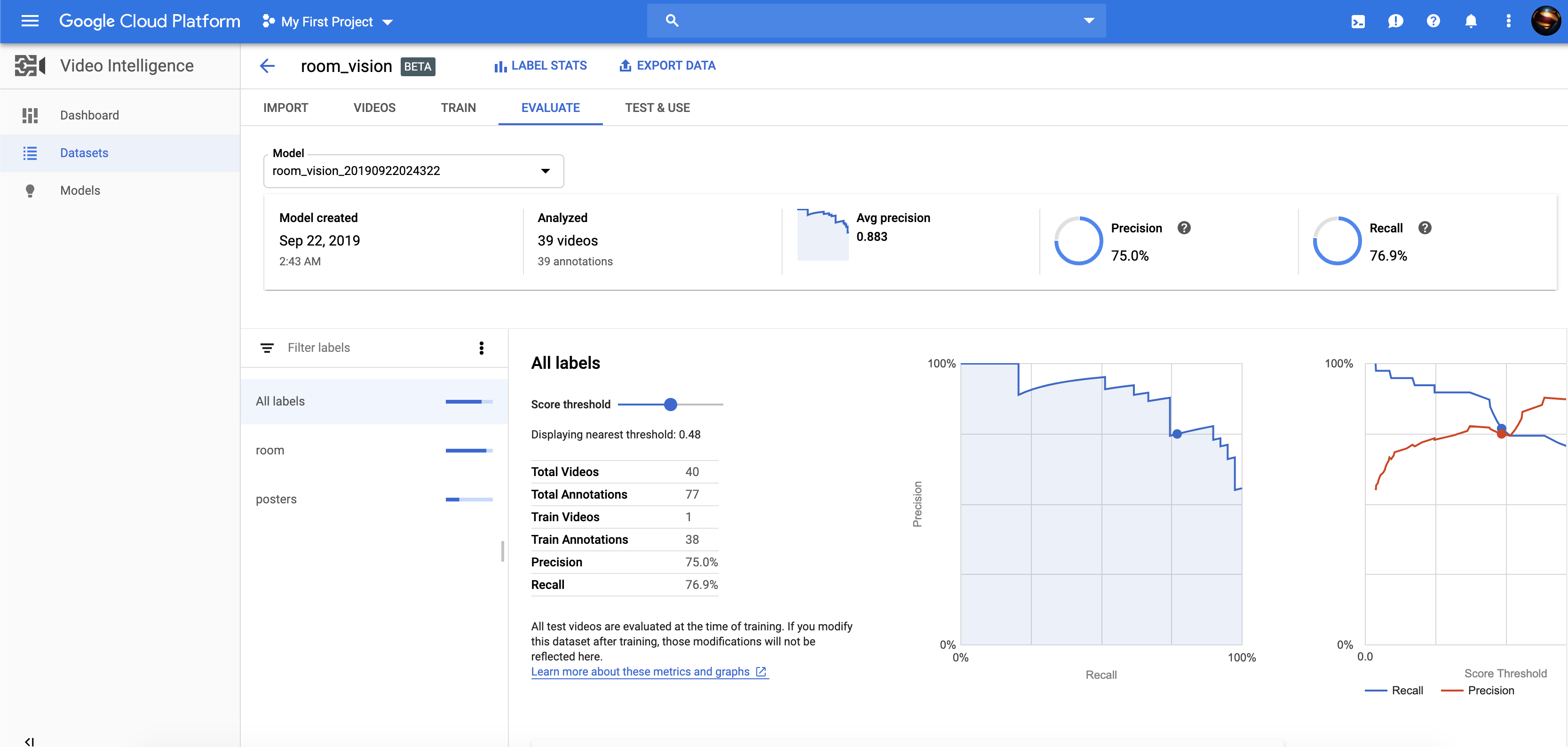
Some stats on one of our RoomVision models.
-
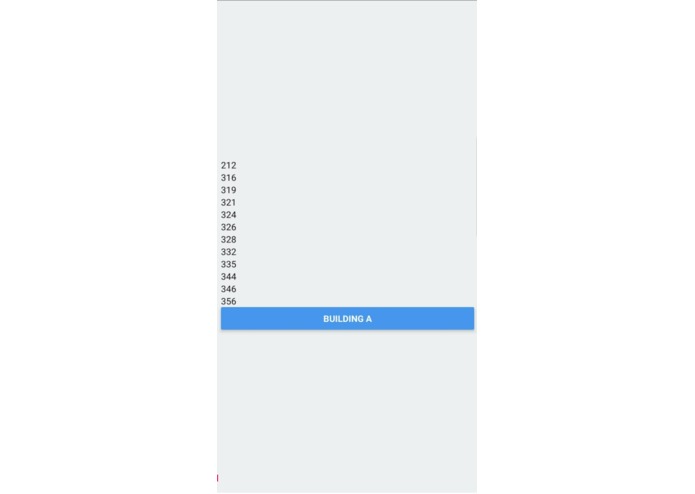
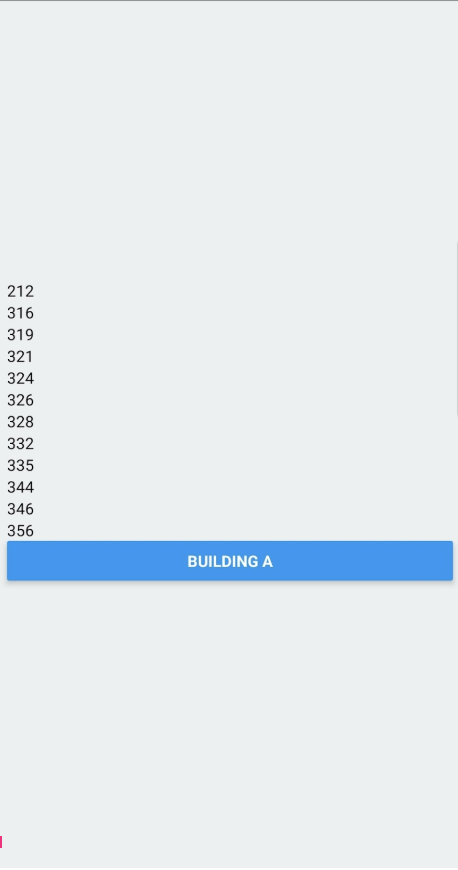
Initial application screenshot
Inspiration
The main inspiration behind this project was the idea to translate information between senses to help people who might be impaired of any. In specific, the idea behind our application is for it to translate visual information to auditory information.
What it does
The purpose of our application is to allow people who are visually impaired to traverse through a building and hear the room numbers as they walk by them.
How we built it
The back end was made with Python and utilized Google clouds Video Intelligence to solely obtain the room numbers from a video we took at eye level simulating someone walking down a hallway in a building here at Cornell. From this video, the room numbers where extracted and converted to text and then sent to the front end when requested by the user.
The frontend was written in React Native: a cross-platform, mobile framework for JavaScript. Using a JavaScript Text-to-Speech API, we were able to convert JSON data from the Flask App into an understandable speech soundbyte.
Once the button on the application is pressed, the application initializes the server side code which runs the Google Cloud Video Intelligence API and extracts the room number text from a video file we uploaded to google cloud. The room number text is then sent back to the front end where it is then converted to speech.
Challenges we ran into
*Using the Google Cloud APIs for the first time was pretty confusing to get up and running, we definitely learned a lot as time went on.
We created our own machine learning model via Google Clouds AutoML, this resulted in a model that would accurately identify and label room number signs from the simulated walking video. Our challenge was having enough time to accurately train and test this model as well as implementing it into our application to facilitate our Google Cloud video intelligence python script in detecting the correct text and filtering out unwanted information.
Accomplishments that we're proud of
*The accuracy of the machine learning models, text detection models, We are mostly proud of our machine learning model that we trained by taking various videos walking through hallways of building here in Cornell. We are also proud of how we were able to filter unwanted information from the recorded videos.
What we learned
This was our first time ever using machine learning and we learned that machine learning models take longer than expected to train and test although the google cloud AutoML definitely facilitates the process.
What's next for RoomVision
We plan to continue our implementation of our RoomVision ML model into our overall application. Our plan is to make a prototype with glasses to hold three mini cameras (one facing the front, one left, one right) to detect the room signs, and earbuds to receive the room number audio.
We have very ambitious ideas for RoomVision, we believe that with the right hardware and implementation of machine learning we can make a real product that could make the world a better place for those who are visually impaired. We envision to continue training our model so that anyone anywhere can walk into a building and hear where the rooms are.
Built With
- expo-speech
- flask
- googlecloudautoml
- googlecloudvideointelligence
- python
- react-native


Log in or sign up for Devpost to join the conversation.