-
-
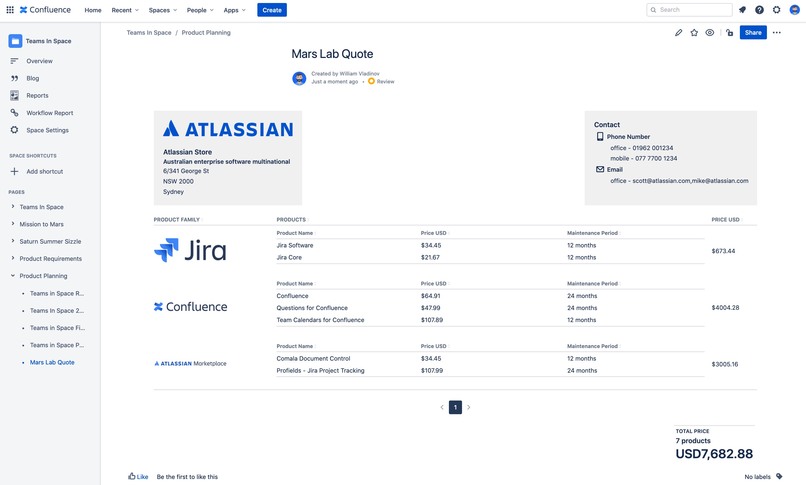
Atlassian Store Quote template
-
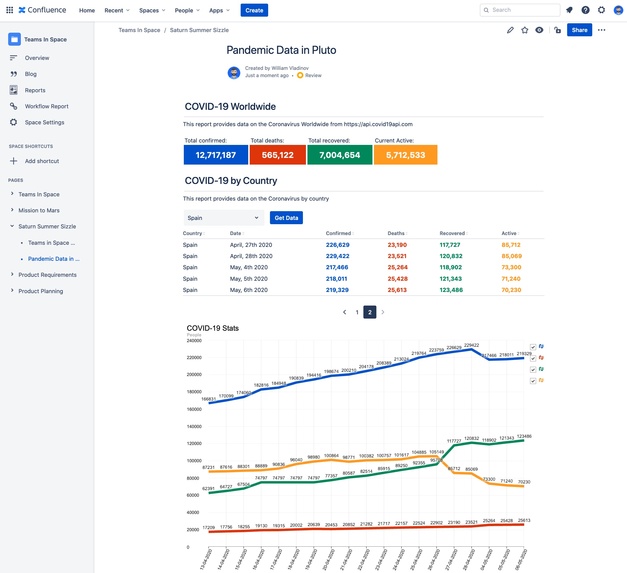
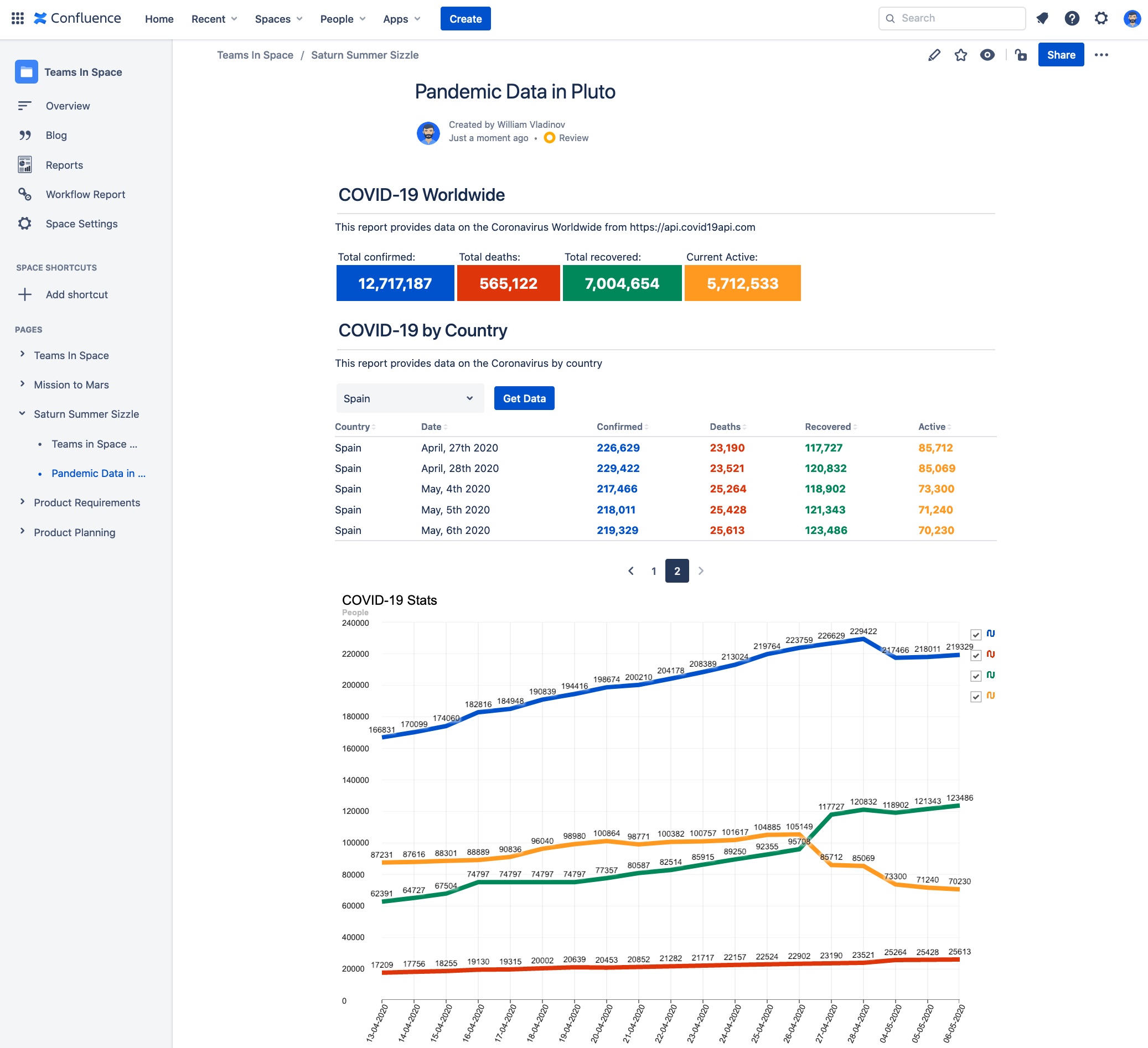
COVID-19 template
-

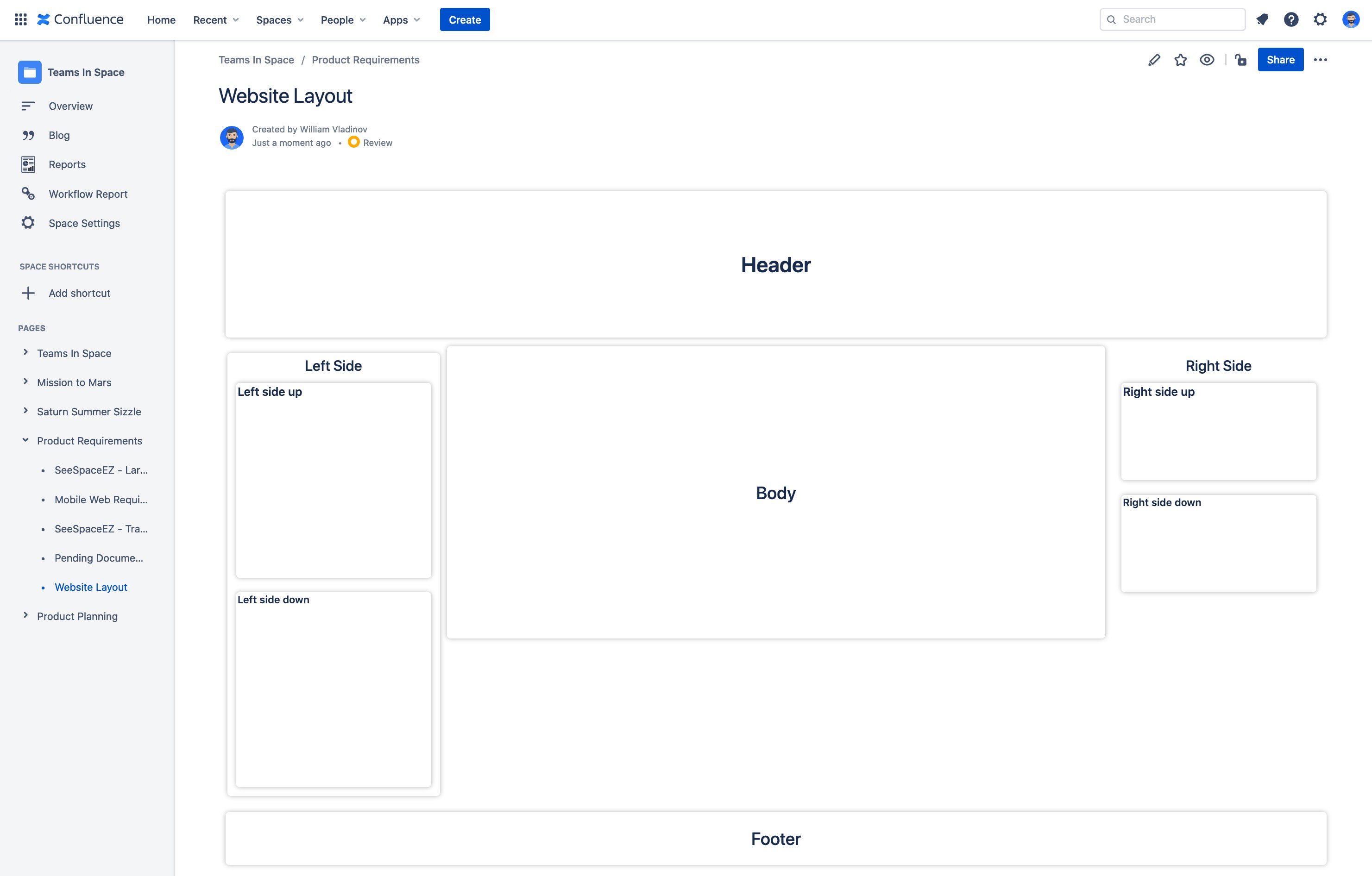
Flexbox Layout template
-
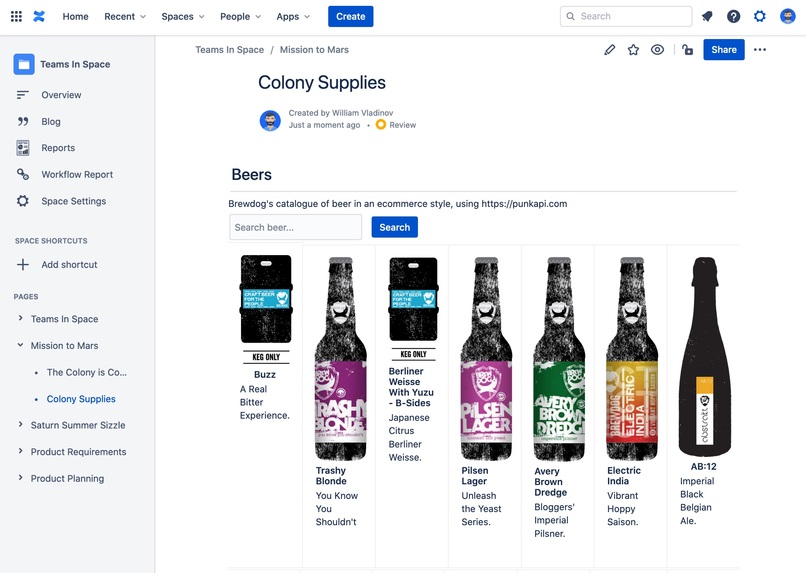
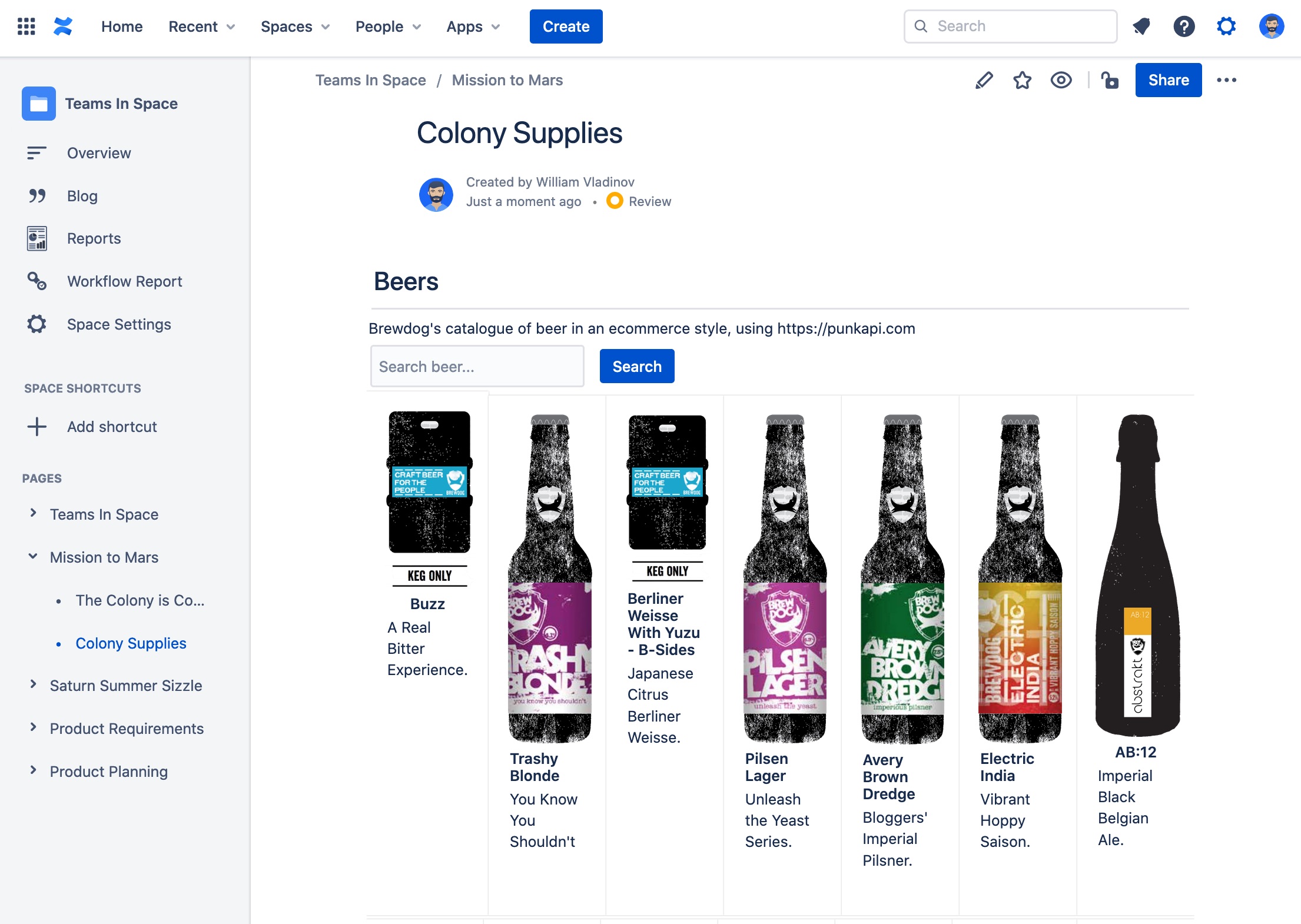
Beer ecommerce template
-
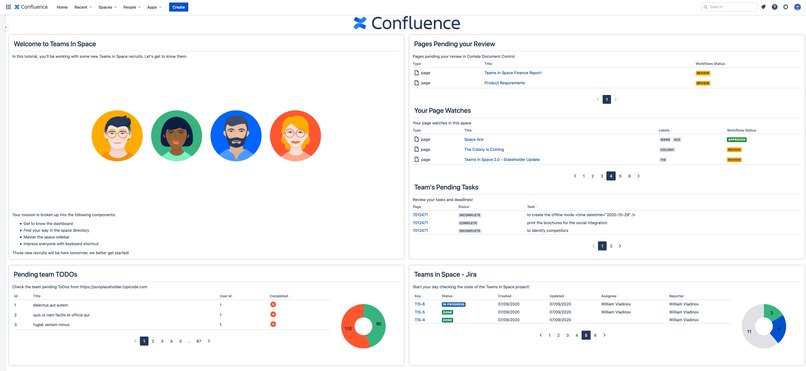
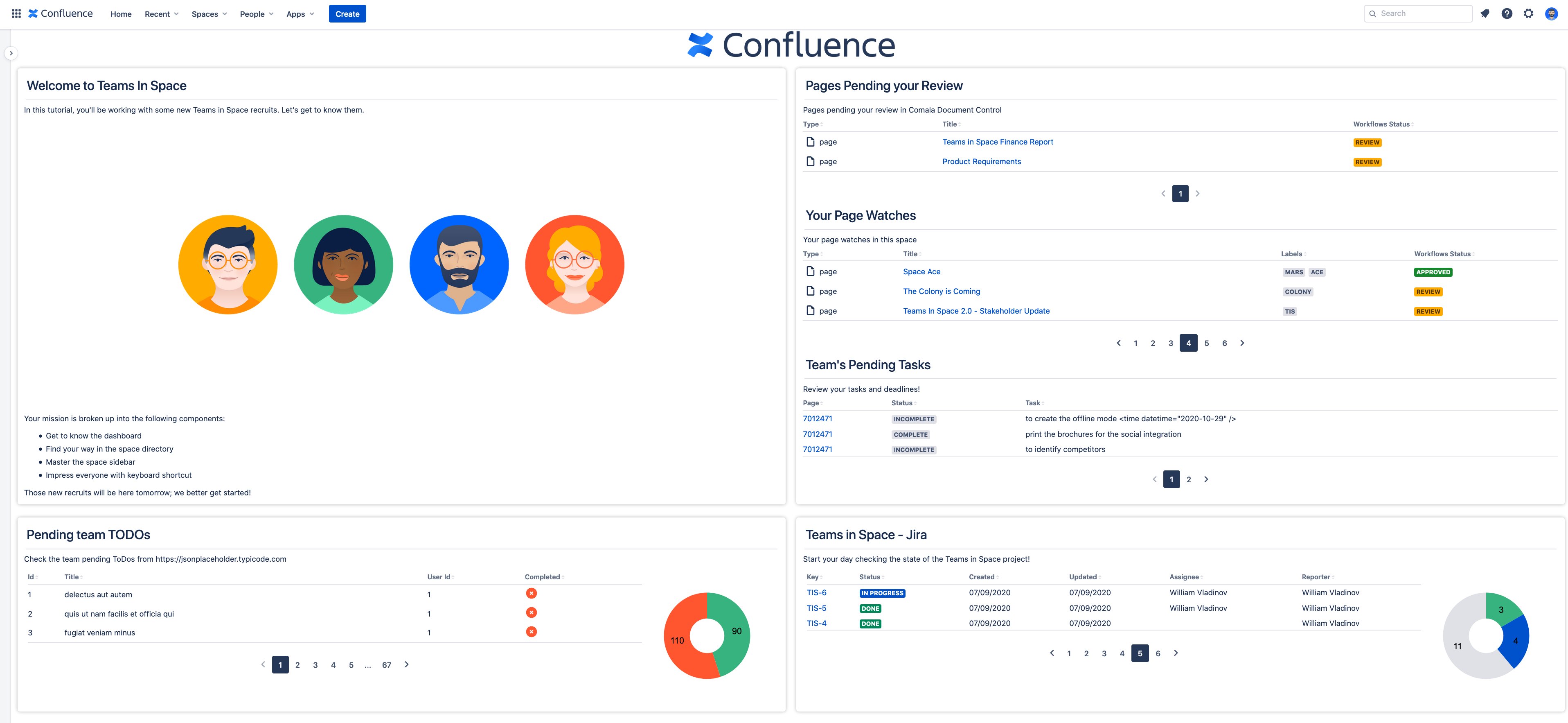
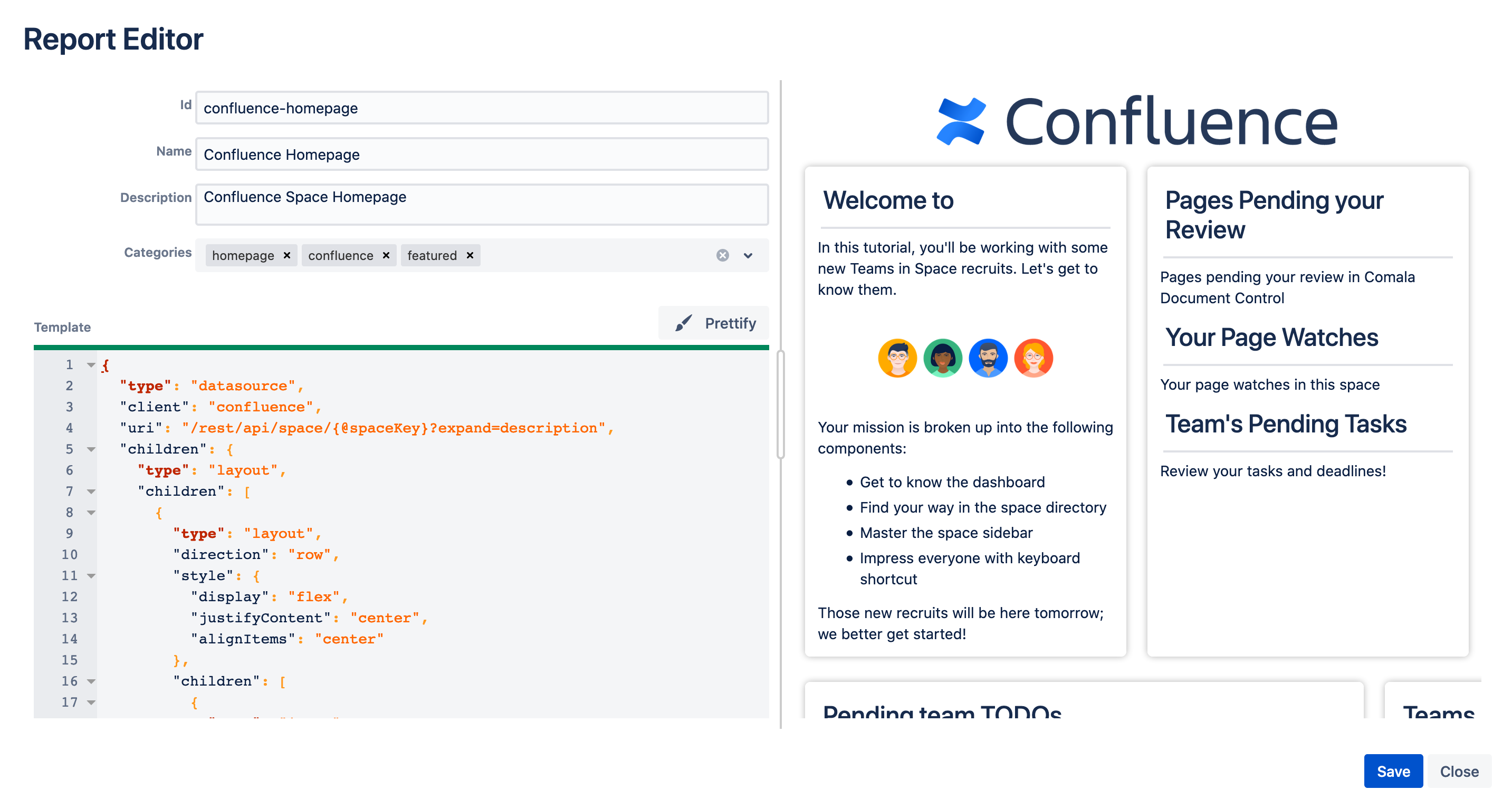
Confluence Homepage template
-
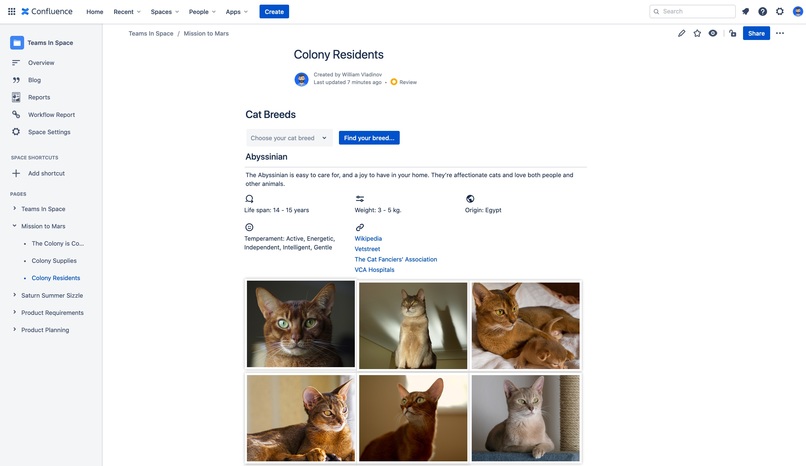
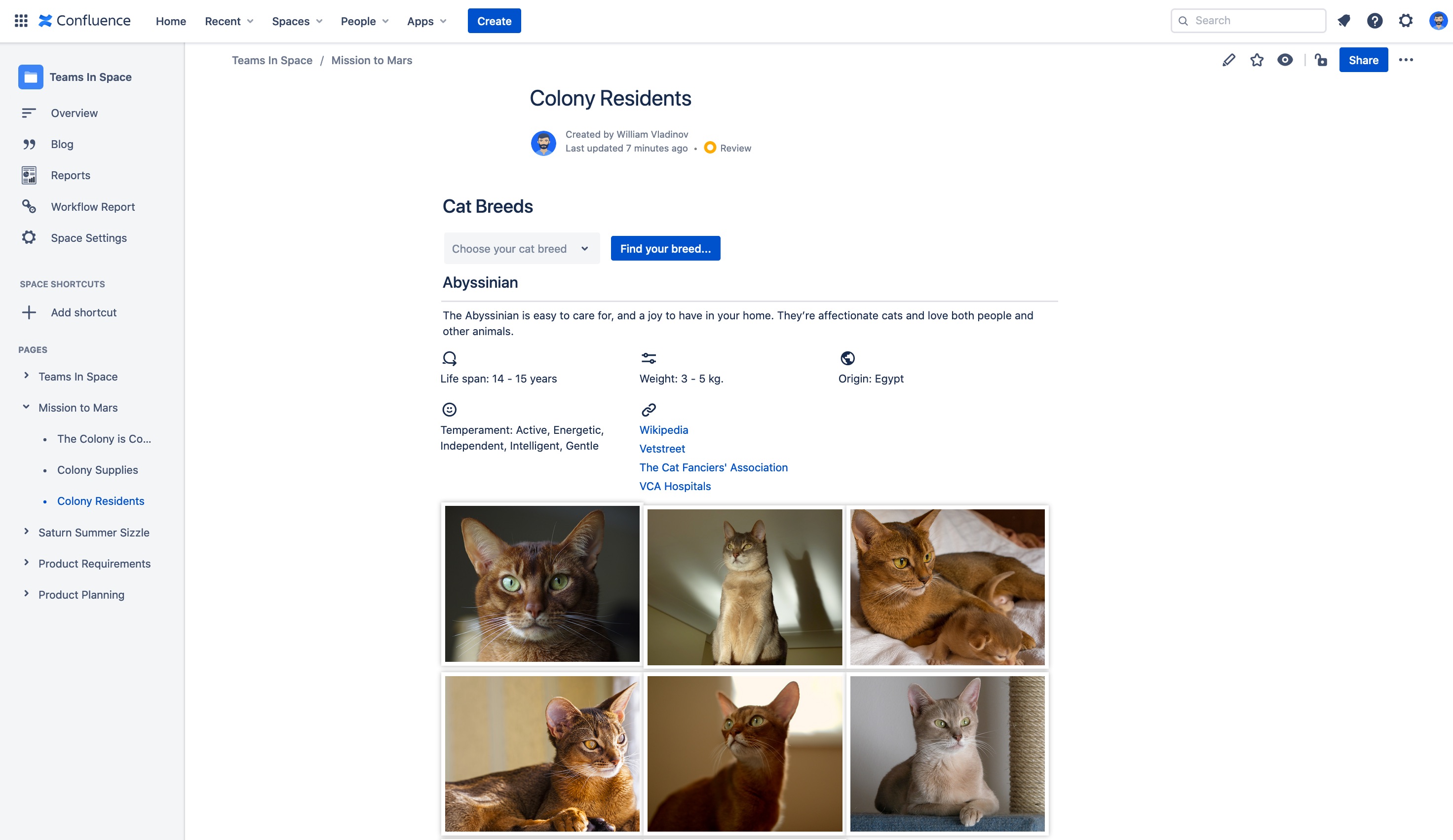
Cat Breeds template
-
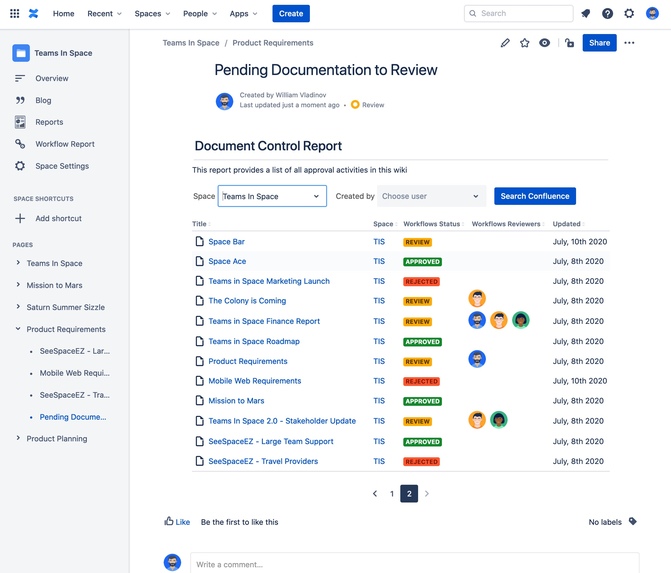
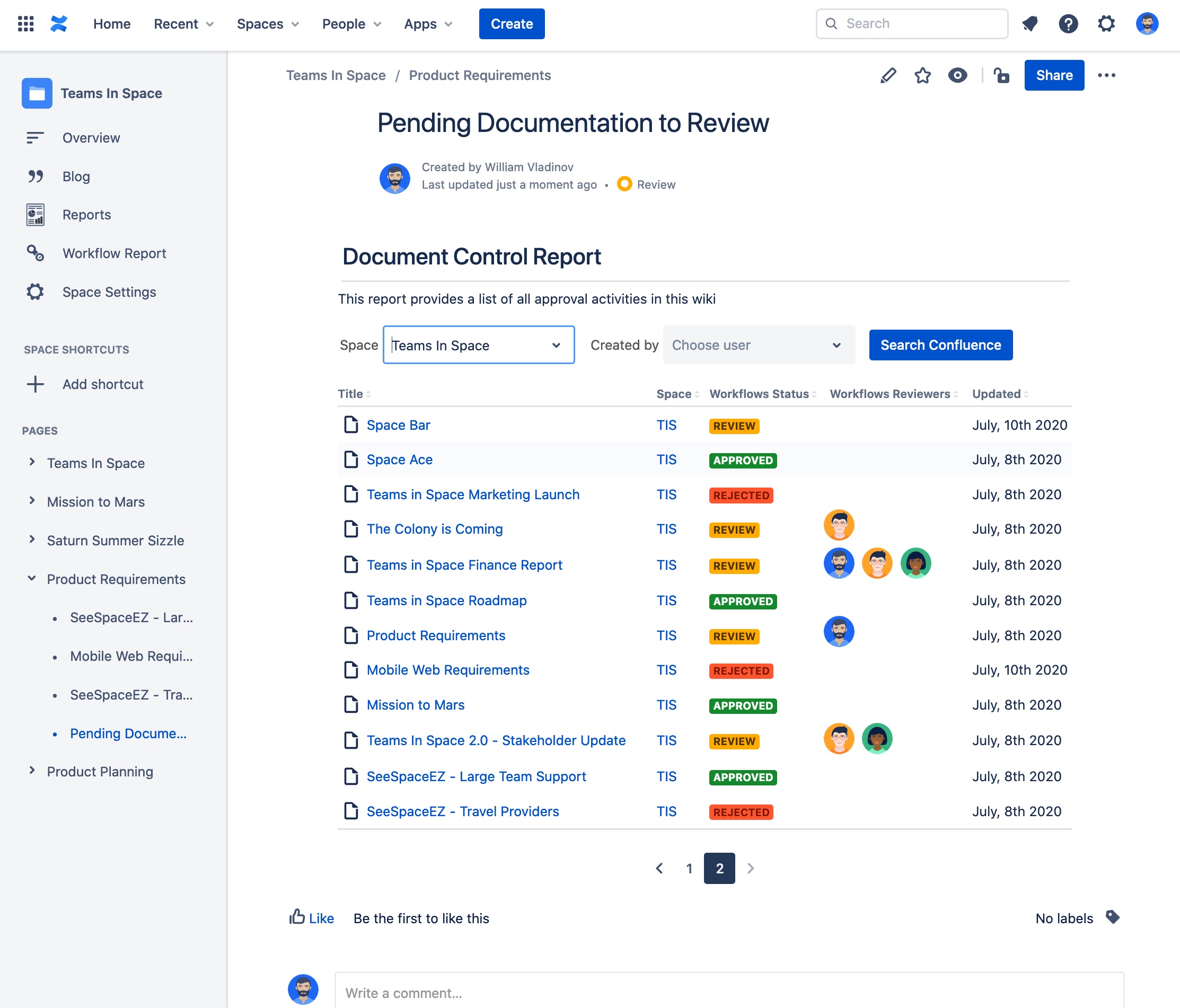
Comala Document Control template
-
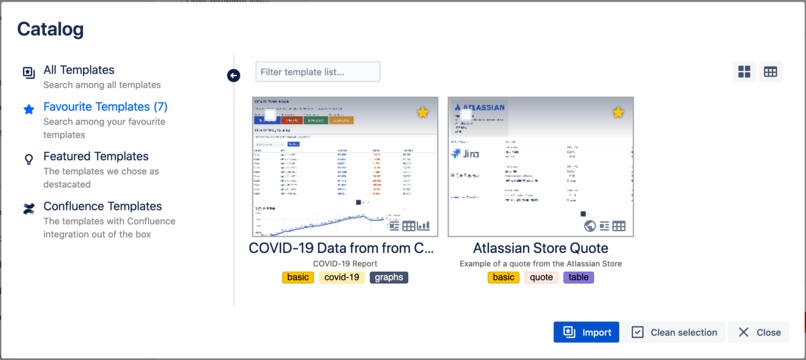
Templates Catalog
-
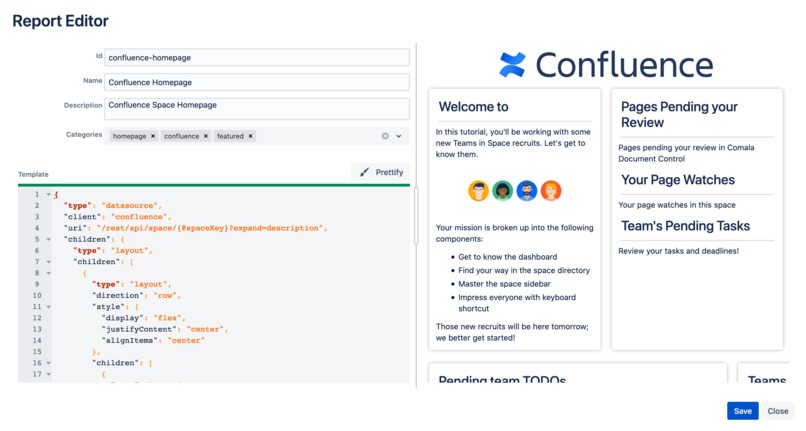
Report Editor

Inspiration
We believe that our solution tackles two important aspects: i) Data Integration, and ii) Data Presentation.
On the one hand, one of the key features that keeps customers coming to the Atlassian ecosystem is the tight integration among all the products e.g., a single Jira issue displays information from Bitbucket, Confluence, Bamboo, Pipelines… But customers still suffer two main friction points, which are still to be overcome when it comes to data integration:
- Data coming from marketplace vendor apps
- Data coming from vendors outside the marketplace (ERP, CRM, SaaS…)
On the other hand, and after having worked for two vendors of the Atlassian Marketplace (Keinoby and Comalatech), we realized that we’d built different reports for all their apps, and sometimes had to do it several times for the same app. We also created some custom apps for third party organizations, which also needed reports.
So, reports are a commodity in the ecosystem. But currently, these reports fail when customers need the information in an organized format due to the lack of flexibility of the current solutions. There’s no way to present the data adequately for the audience at hand, nor to integrate data.
What it does
Ronin Reports allows users to create reports using tables, graphs, charts, images or plain text to present the information. In addition, this app gives flexibility to design the reports in a flexible and responsive layout structure.
Ronin Reports uses JSON as data source, a static JSON, from a REST API endpoint (public or private), GraphQL endpoints… So it could combine data from Confluence, Jira, Hubspot and your favourite cat API if it’s needed in a single report. Even databases can expose the data through a REST API in JSON format, so we can capitalize on that too. And we also allow user interaction, so the reports present dynamic information.
Keeping it simple: Ronin Reports creates flexible and dynamic reports using JSON data.
How we built it
Using React capabilities and it's tree component model, we created specialised view components, which can be mapped into any part of a JSON structure.
A key part was to provide a powerful data source implementation to smartly gather data in any source (static JSON, a public REST API, a proxied API to solve CORS issues, Confluence using AP.request bridge, and so on) and the puzzle is complete: A markup JSON based definition where users create a powerful, custom and free-layout visualization to display it within Confluence.
Challenges we ran into
While the idea it's simple, we run into multiple challenges (still working on some of them):
Powerful custom reports. We focused on giving users a powerful tool with a lot of flexibility, but that brought complexity. The current solution demands users to have basic knowledge of CSS (Flexbox) and JSON path. To reduce this barrier, we provide a catalog of templates. This set of examples cover different use cases that users can copy, tweak and adapt to their needs. We think this can hinder adoption, so we are working to make it as easy as possible.
Dynamic reports: We didn’t want to provide just a static version of the data, but dynamic reports based on custom parameters. The logic behind it was complex, as we needed to have a fine control on how React controls the rendering. We manage multiple contexts, and this has to be done properly.
Recursivity: Reports are recursive tree structures. This means that a customer can have a table within a cell table or multiple nested data sources. This provoked several issues due to incorrect nested structures, so we had to delimit where to allow customers to use recursivity.
Isolate the report core: After implementing the PoC to validate our ideas, we thought we should separate the rendering code. In this way, it can be reused, but this called for an early refactor of the entire project.
Accomplishments that we're proud of
We think we have created a solution flexible enough to solve several of the current reporting problems in the ecosystem, with some opinionated technical decisions:
JSON as data format
HTTP REST as first order data source
Extended JSON path as data mapping solution
CSS Flexbox as basis for the layout design
Custom and specialized view solutions: Text, tables, lists, graphs, etc.
A reusable library that could be the core report engine for other app vendors
With these pieces, a user can offer beautiful, custom and powerful data abstractions to present information in an organized format to the rest of the team.
What we learned
Advanced React skills
Importance of balancing power with complexity when providing features
Overcoming several oddities in REST APIs: Rate limits, CORS, etc.
Advanced features: PDF and image export (WIP)
What's next for Ronin Reports
The main challenge we face is to reduce the complexity when building the reports. We are going to start providing a catalog with several templates covering the main features and possibilities. Next step is to provide small improvements to reduce that complexity: Extract the datasource logic to the configuration area, create a simple layout design builder… A rough outline of our roadmap -which changes everyday 😺:
Short term:
Compose facilities: Allow templates to be broken down into smaller buildable pieces
Configurable query cache
Nested datasource queries
Enhanced authentications: OAuth 2.0
Automated pagination
Improve filtering and parameter support
Multiple UI enhancements (tables, styles, graphs, etc)
Catalog: Add several useful examples and integrations
Middle term:
Report builder: Simplify the report creation and layout design
Provide the functionality as a library for third parties, like other app vendors. So they can use it in their apps and forget about maintaining their own reporting solutions
Improve and create new exporters: PDF, CSV, image, etc.
Catalog: Add custom third party integrations and customer contributions
Long term:
- Increase the power of the reports by allowing interaction with the data e.g., POST/PUT actions in endpoints, metadata, etc.











Log in or sign up for Devpost to join the conversation.