-
-
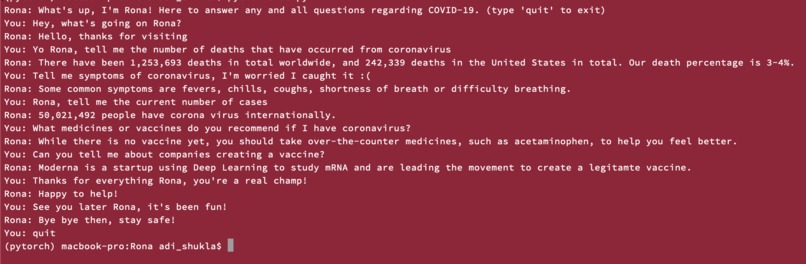
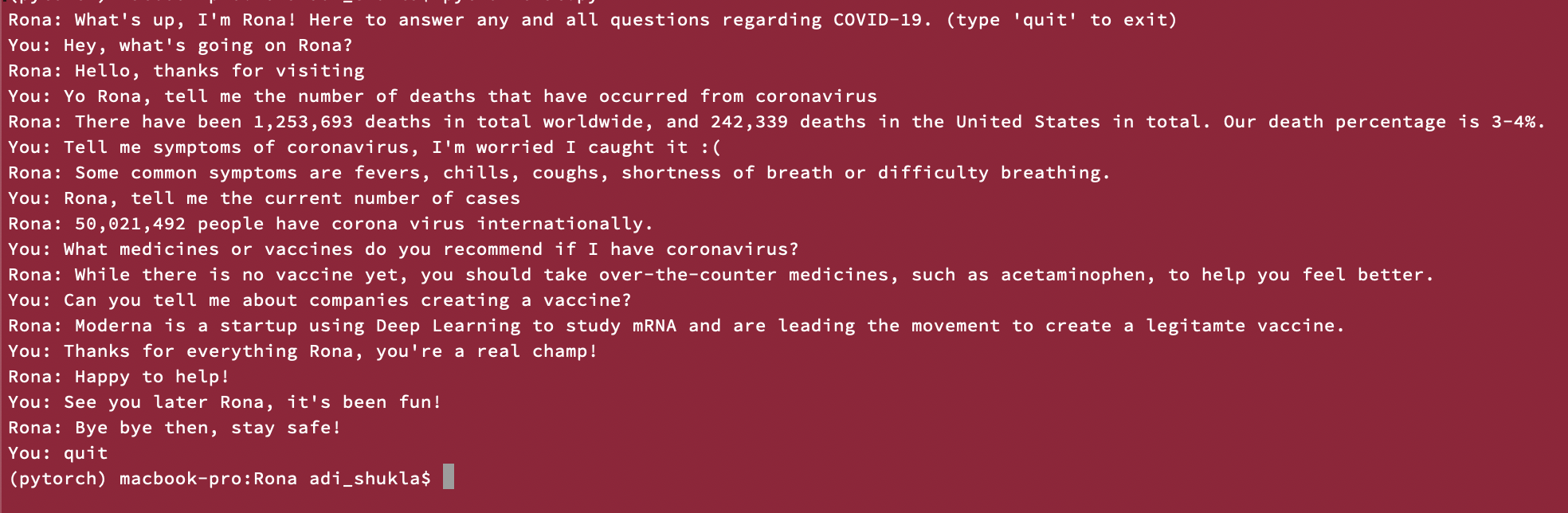
Rona in action! Rona answered these questions on her own because of the training from the feed forward neural net. No prewritten questions!
Inspiration
A chatbot is often described as one of the most advanced and promising expressions of interaction between humans and machines. For this reason we wanted to create one in order to become affiliated with Natural Language Processing and Deep-Learning through neural networks.
Due to the current pandemic, we are truly living in an unprecedented time. As the virus' spread continues, it is important for all citizens to stay educated and informed on the pandemic. So, we decided to give back to communities by designing a chatbot named Rona who a user can talk to, and get latest information regarding COVID-19.
(This bot is designed to function similarly to ones used on websites for companies such as Amazon or Microsoft, in which users can interact with the bot to ask questions they would normally ask to a customer service member, although through the power of AI and deep learning, the bot can answer these questions for the customer on it's own)
What it does
Rona answers questions the user has regarding COVID-19.
More specifically, the training data we fed into our feed-forward neural network to train Rona falls under 5 categories:
- Deaths from COVID-19
- Symptoms of COVID-19
- Current Cases of COVID-19
- Medicines/Vaccines
- New Technology/Start-up Companies working to fight coronavirus
We also added three more categories of data for Rona to learn, those being greetings, thanks and goodbyes, so the user can have a conversation with Rona which is more human-like.
How we built it
First, we had to create my training data. Commonly referred to as 'intentions', the data we used to train Rona consisted of different phrases that a user could potentially ask. We split up all of my intentions into 7 categories, which we listed above, and these were called 'tags'. Under our sub-branch of tags, we would provide Rona several phrases the user could ask about that tag, and also gave it responses to choose from to answer questions related to that tag. Once the intentions were made, we put this data in a json file for easy access in the rest of the project.
Second, we had to use 3 artificial-intelligence, natural language processing, techniques to process the data, before it was fed into our training model. These were 'bag-of-words', 'tokenization' and 'stemming'. First, bag-of-words is a process which took a phrase, which were all listed under the tags, and created an array of all the words in that phrase, making sure there are no repeats of any words. This array was assigned to an x-variable. A second y-variable delineated which tag this bag-of-words belonged to. After these bags-of-words were created, tokenization was applied through each bag-of-words and split them up even further into individual words, special characters (like @,#,$,etc.) and punctuation. Finally, stemming created a crude heuristic, i.e. it chopped off the ending suffixes of the words (organize and organizes both becomes organ), and replaced the array again with these new elements. These three steps were necessary, because the training model is much more effective when the data is pre-processed in this way, it's most fundamental form.
Next, we made the actual training model. This model was a feed-forward neural network with 2 hidden layers. The first step was to create what are called hyper-parameters, which is a standard procedure for all neural networks. These are variables that can be adjusted by the user to change how accurate you want your data to be. Next, the network began with 3 layers which were linear, and these were the layers which inputted the data which was pre-processed earlier. After, these were passed on into what are called activation functions. Activation functions output a small value for small inputs, and a larger value if its inputs exceed a threshold. If the inputs are large enough, the activation function "fires", otherwise it does nothing. In other words, an activation function is like a gate that checks that an incoming value is greater than a critical number.
The training was completed, and the final saved model was saved into a 'data.pth' file using pytorch's save method.
Challenges we ran into
The most obvious challenge was simply time constraints. We spent most of our time trying to make sure the training model was efficient, and had to search up several different articles and tutorials on the correct methodology and API's to use. Numpy and pytorch were the best ones.
Accomplishments that we're proud of
This was our first deep-learning project so we are very proud of completing at least the basic prototype. Although we were aware of NLP techniques such as stemming and tokenization, this is our first time actually implementing them in action. We have created basic neural nets in the past, but also never a feed-forward one which provides an entire model as its output.
What we learned
We learned a lot about deep learning, neural nets, and how AI is trained for communication in general. This was a big step up for us in Machine Learning.
What's next for Rona: Deep Learning Chatbot for COVID-19
We will definitely improve on this in the future by updating the model, providing a lot more types of questions/data related to COVID-19 for Rona to be trained on, and potentially creating a complete service or platform for users to interact with Rona easily.
Built With
- deep-learning
- natural-language-processing
- python
- pytorch

Log in or sign up for Devpost to join the conversation.