-
-

Logo
-
Landing Page

Rolodex — Devpost Submission
Inspiration
B2B contact data decays at 20–30% per year. People change jobs, get promoted, retire — and sales teams waste thousands of hours a year emailing the wrong person. Existing solutions like ZoomInfo cost $10k+/year and still refresh on slow quarterly cycles. We wanted to build an autonomous agent that keeps contact lists fresh in real time, and — critically — proves its own financial value on every single run instead of hiding behind a flat subscription fee.
What it does
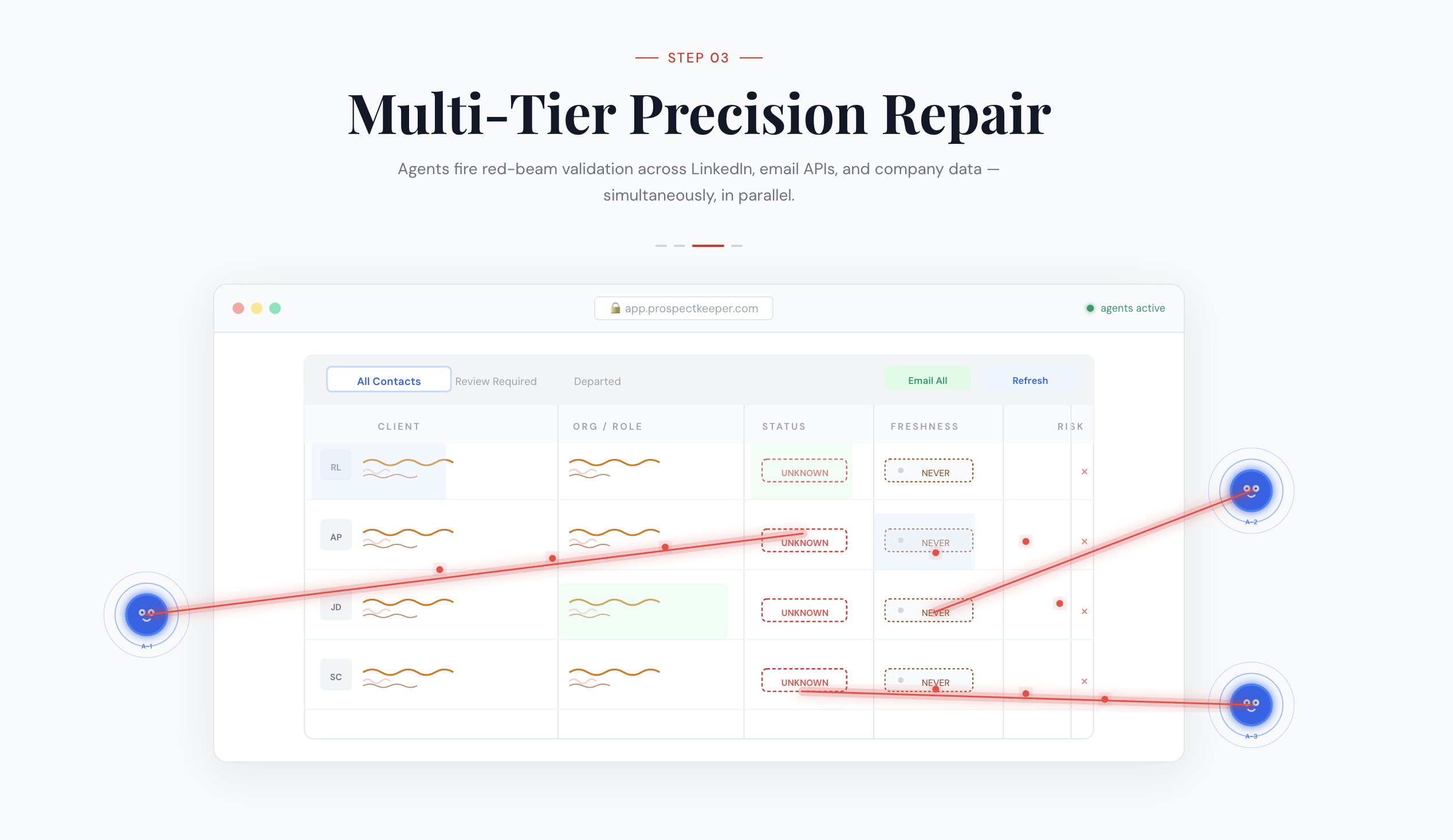
Rolodex is an agentic CRM that autonomously verifies whether B2B contacts are still active in their roles. It:
- Scrapes LinkedIn profiles via a headless browser (nodriver) to verify current employment and detect job changes in real time
- Sends confirmation emails (Resend) asking contacts to verify their own info, with auto-parsing of replies and out-of-office messages via Claude
- Processes inbound email replies using Claude to extract corrected contact information automatically
- Flags uncertain contacts for human review with a dedicated review queue in the UI, rather than silently corrupting data
- Streams agentic verification live — Claude autonomously decides which tools to call (lookup → website scrape → LinkedIn → email), with real-time Server-Sent Events streamed to a React "Agent Workbench" modal so you can watch the agent think
- Generates a Value-Proof Receipt after every batch: exact API costs (Claude tokens) vs. estimated SDR hours saved, producing a live ROI figure (typical: +30,000% ROI per run)
- Simulates outcome-based billing — $0.10/verification, $2.50/replacement found — demonstrating a pricing model where customers only pay for value delivered
How we built it
- Backend: Python + FastAPI (single unified server), Clean Architecture with Hexagonal/Ports-and-Adapters pattern and Domain-Driven Design. The domain layer has zero dependencies on external services.
- AI/Agent: Anthropic Claude (
claude-sonnet-4-6) with nativetool_use— a true agentic loop where Claude autonomously selects and sequences tools across up to 10 iterations. Langfuse for LLM observability and cost tracking. - LinkedIn Scraping: nodriver (undetected headless Chromium) with stored session cookies, parsing full profiles including experience, education, and skills sub-pages.
- Frontend: React + TypeScript + Vite + Tailwind CSS v4. Features include a contact management table with LinkedIn freshness indicators, change-detection diffs, an inline Agent Workbench with SSE streaming, edit/delete CRUD, email sending, and a Value Receipt dashboard.
- Database: Supabase (PostgreSQL) with tables for contacts, verification results, agent economics, and LinkedIn snapshots with hash-based change detection.
- Email: Resend for outbound confirmation emails, with a Zapier webhook endpoint for parsing inbound replies.
- Architecture: Full dependency injection via a Container, interface-driven adapters, and a tiered cost-aware routing engine (free scraping → LinkedIn → Claude) that minimises API spend.
Challenges we ran into
- LinkedIn anti-bot defences were aggressive — we had to move from Playwright to CamoUFox to nodriver to find a stealth browser that could reliably load profiles without triggering auth-walls or CAPTCHAs. Cookie management and session rotation added significant complexity.
- Keeping the agent economically rational — Claude's default instinct is to use every tool available. We had to carefully engineer the system prompt and tool ordering so the agent reliably starts with free signals (website scrape) before escalating to paid ones (Claude analysis, LinkedIn).
- Streaming agentic verification to the frontend — wiring Claude's multi-turn
tool_useloop into Server-Sent Events that update a React UI in real time, while handling errors, timeouts, and partial results gracefully, was harder than expected. - Recieving Emails — our only available DNS server did not support receiving emails, meaning we needed to apply an additional layer through Zapier
- Change detection at scale — detecting meaningful profile changes (vs. trivial reformatting) required hash-based snapshot comparison with field-level diff summaries stored in JSONB.
Accomplishments that we're proud of
- True agentic autonomy: Claude genuinely decides its own verification strategy per contact — it's not a hardcoded pipeline. The agent reasons about cost vs. confidence and stops early when a cheap signal is conclusive.
- The Value-Proof Receipt: Every batch run produces a real, auditable breakdown of API costs vs. SDR hours saved. The agent literally proves it's worth more than it costs, every time.
- Clean Architecture in a hackathon: Despite the time pressure, the codebase follows Hexagonal Architecture with proper domain entities, use case boundaries, and adapter interfaces — no business logic leaks into the HTTP layer.
- End-to-end LinkedIn freshness tracking: Real-time scraping with hash-based change detection, field-level diffs in the UI, and confidence scores derived from data age — giving users an at-a-glance view of how trustworthy each contact record is.
What we learned
- Cost-aware AI agents are a genuine product differentiator. Users care much more about "this cost $0.42 and saved 4.5 hours" than "task complete." Transparent economics builds trust.
- Agentic
tool_useis powerful but needs strong guardrails. Without careful prompt engineering and iteration limits, Claude will happily burn through tokens on unnecessary tool calls. - LinkedIn is the hardest data source to scrape reliably. Anti-bot measures are a moving target — what works today may break tomorrow. Building the system with swappable adapters (the Hexagonal pattern) made pivoting between scraping strategies painless.
- Streaming UX for AI agents dramatically improves the user experience. Watching the agent think and act in real time (vs. waiting for a spinner) makes the product feel alive and trustworthy.
What's next for Rolodex
- Google/Bing Search API integration as an additional free signal tier — querying
"{name}" "{organization}"to cross-reference public web mentions before escalating to LinkedIn or Claude - Bulk batch scheduling with cron-based automatic re-verification of stale contacts on a configurable cadence
- MX record and domain-level checks — if a company's mail server is dead, mark all contacts at that domain as inactive in one sweep
- Engagement signal ingestion — import email open/click data from ESPs (Mailgun, SendGrid) to auto-confirm active contacts without spending any API credits
- Multi-user auth and team workspaces with role-based access control
- Production deployment on Railway with proper secret management and rate limiting
- Statistical confidence scoring — replacing the current heuristic freshness model with a Bayesian approach that weights multiple independent signals

Log in or sign up for Devpost to join the conversation.