-
-

logo
-
-
-
-
-



Inspiration
The idea for RoleCall AI came from a real problem we kept thinking about: most people in service roles are expected to communicate well under pressure, but they usually become good only after facing real situations over time.
A nurse does not become confident on the first difficult patient call. A customer service worker does not automatically know how to calm down an angry customer. A student may freeze during a job interview. A new employee may not know when to ask another question, when to stop talking, or when to escalate the situation.
In many industries, the first real practice often happens with a real patient, customer, client, or interviewer. That means people learn through pressure, mistakes, and experience. But not every first mistake is harmless.
That made us ask:
What if people could practice the hard version of the conversation before they face it in real life?
Instead of giving trainees a script, we wanted to generate a realistic person to practice with. Not just a chatbot, but a persona with a role, age, tone, mood, hidden information, memory, and a realistic way of speaking.
We also realized this idea can go beyond training for jobs. A user could generate a customer, patient, interviewer, scammer, teacher, client, or even a persona inspired by someone they miss. The more detailed the prompt is, the more detailed and specific the simulation becomes. A general prompt creates a general simulation, while a detailed prompt creates a persona with stronger behavior, context, and emotional depth.
That became the idea behind RoleCall AI: a system that lets anyone generate a realistic persona and safely practice the conversation before it matters.
What it does
RoleCall AI is a voice and video simulation platform for practicing real-world communication under pressure.
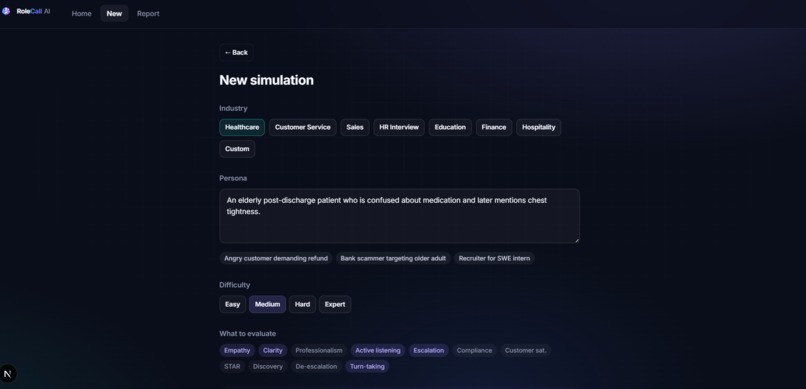
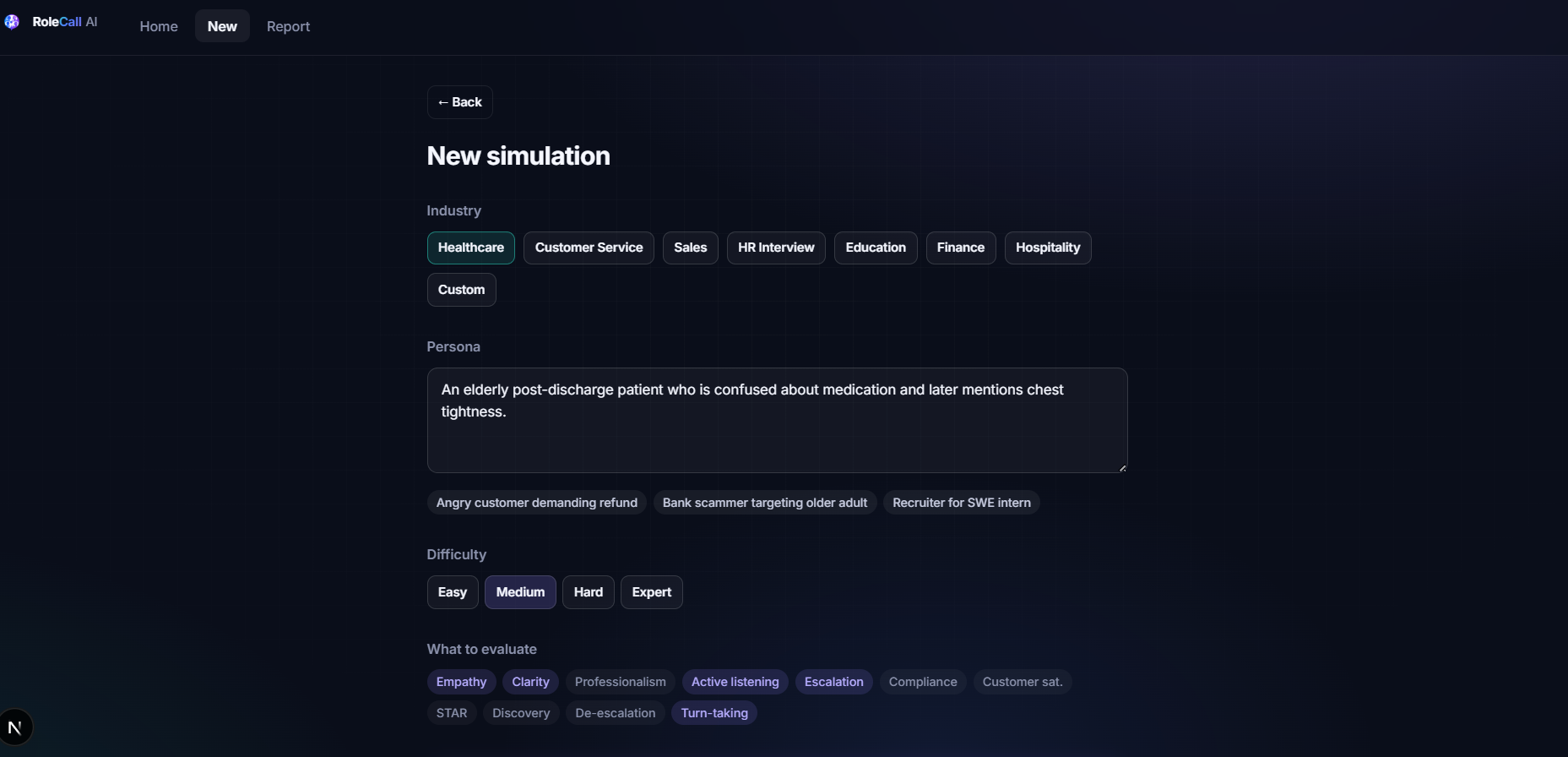
A user can describe the person and situation they want to practice with. For example:
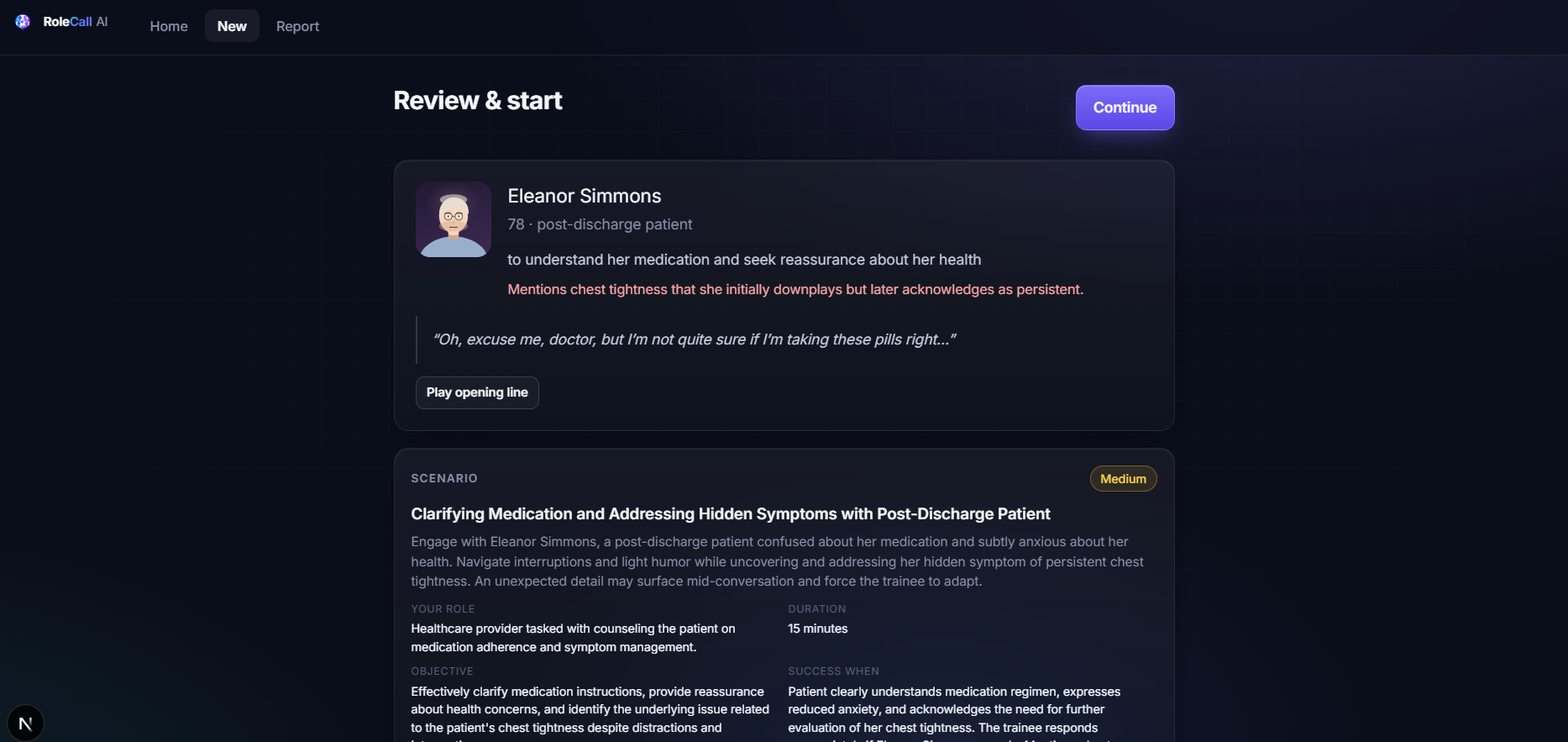
“Create an elderly post-discharge patient who is confused about medication and later mentions chest tightness.”
Or the user can make it more detailed:
“Create an elderly post-discharge patient named Margaret. She is polite but worried, gets confused when instructions are too fast, does not mention chest tightness immediately, and only reveals it if I ask about symptoms or if the call goes on too long.”
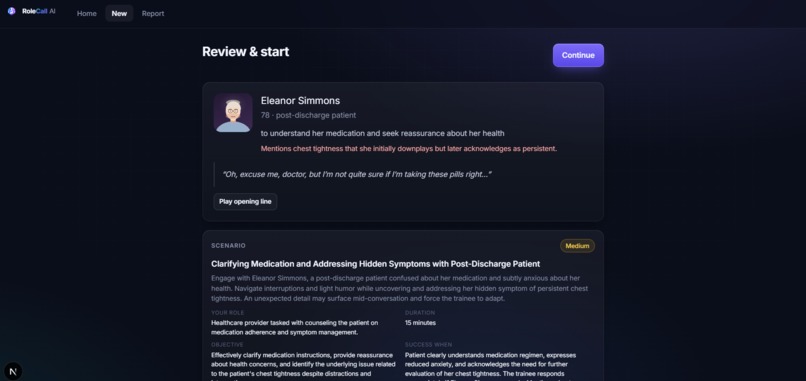
RoleCall AI turns that prompt into a complete practice simulation.
The system generates:
- a realistic persona agent
- a conversation scenario
- hidden information or edge cases
- an evaluation rubric
- a voice style for the persona
- a live practice call
- a post-call feedback report
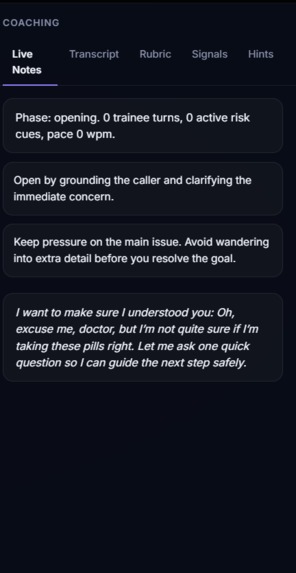
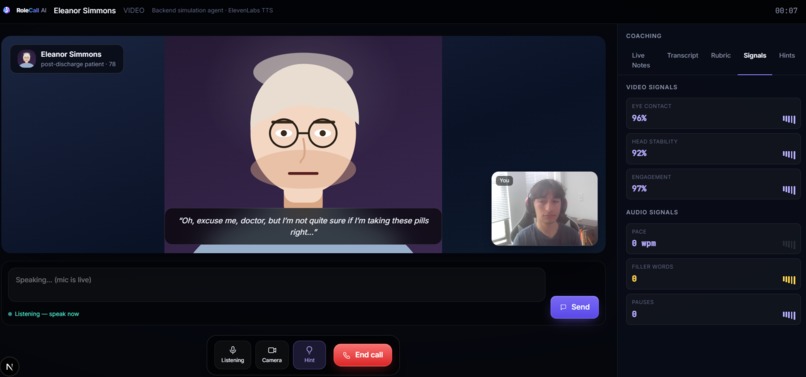
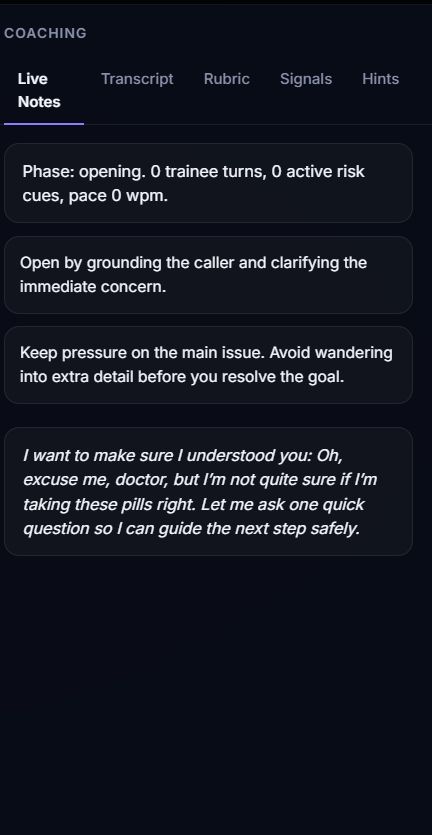
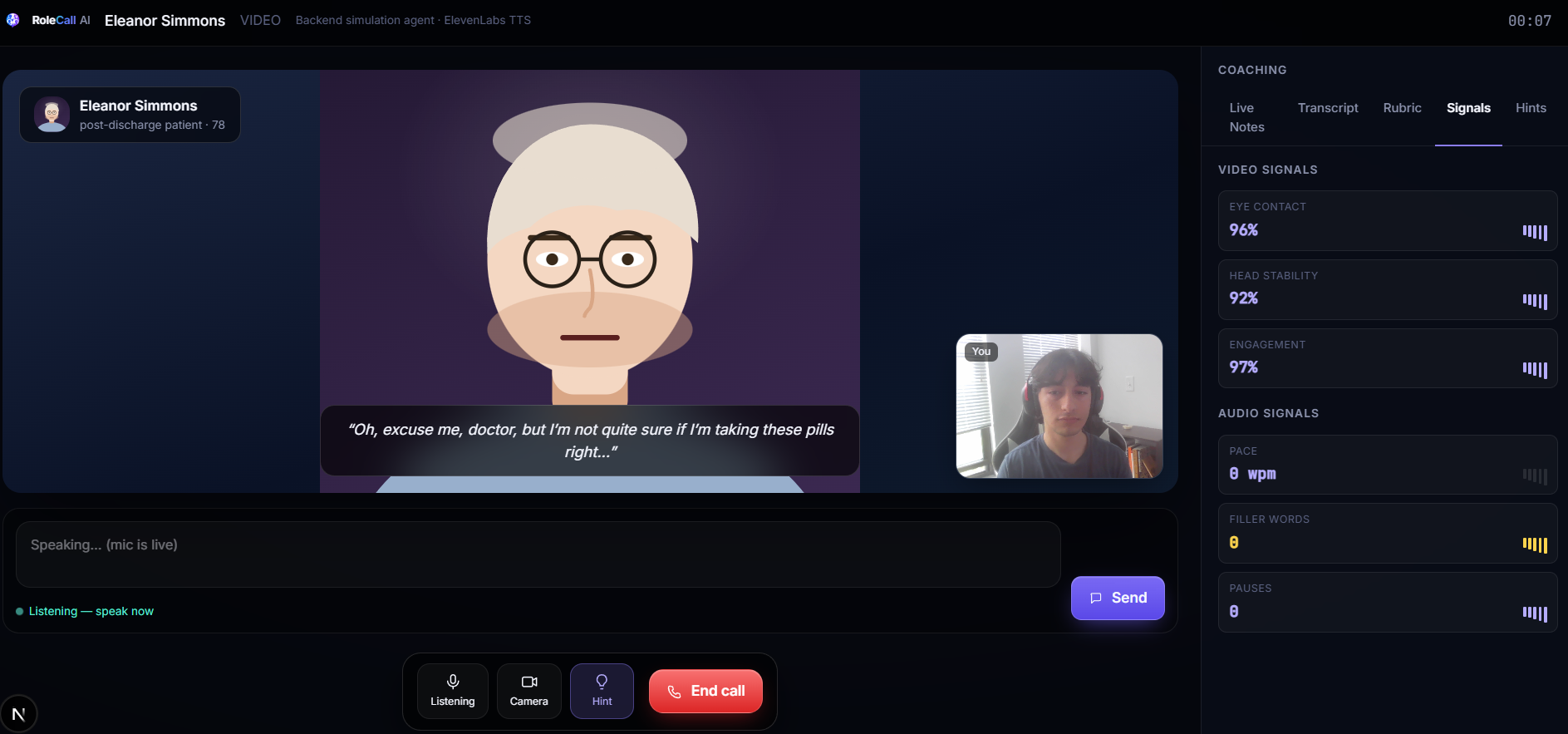
The user can practice through a browser voice or video call. During the conversation, the persona responds based on its role, personality, memory, conversation phase, and hidden goals. After the call, RoleCall AI evaluates the conversation and generates a coaching report.
Our current feedback report includes:
- overall score
- weighted rubric scores
- transcript-based evidence
- key conversation moments
- empathy scoring
- clarity scoring
- question quality scoring
- escalation handling score
- summary and closing behavior
- speaking pace
- pauses
- filler words
- interruptions
- response timing
- eye-contact estimate in video mode
- face-centered estimate in video mode
- head-movement stability in video mode
- facial engagement estimate in video mode
- modality contribution breakdown
- multimodal insights
- agent-generated coaching suggestions
The report does not just say “good job” or “bad job.” It shows what happened, why it mattered, which part of the conversation affected the score, and what the user should try next.
How we built it
RoleCall AI uses a two-service architecture.
The frontend is built with Next.js, React, and TypeScript. It handles the simulation creation flow, persona preview, camera and microphone setup, live call interface, transcript display, coaching sidebar, analyzing state, and final report page. We use Zustand to store simulation state across the full flow: create, preview, setup, call, analyzing, and report.
The backend is built with FastAPI and Python. It handles persona generation, scenario generation, rubric generation, simulation replies, evaluation, audio analysis, video analysis, and voice synthesis. Pydantic models define the contracts for personas, scenarios, rubrics, transcript turns, audio signals, video signals, and evaluation reports.
Instead of building one generic chatbot, we structured RoleCall AI around specialized backend services:
- Persona Generator Agent creates the person the trainee will talk to.
- Scenario Builder Agent turns the persona into a realistic training situation.
- Rubric Generator Agent creates measurable evaluation criteria.
- Simulation Agent roleplays the conversation while tracking state.
- Audio Signal Analysis Service analyzes speech pace, pauses, filler words, interruptions, and response timing.
- Video Signal Analysis Service estimates coaching-safe nonverbal signals.
- Coaching Report Agent combines transcript, audio, video, and rubric evidence into a final report.
The Simulation Agent is stateful. It tracks conversation phase, revealed facts, trainee actions, pending goals, safety status, hidden information, and industry-specific escalation logic. This allows the persona to change as the conversation develops. For example, a patient may not reveal chest tightness immediately. A scammer may begin politely and become more forceful later. A recruiter may ask follow-up questions based on the candidate’s answer.
For voice, we use ElevenLabs for text-to-speech, with voice selection mapped from persona characteristics such as age and gender buckets to different voice IDs. The simulation reasoning stays inside our RoleCall backend, while ElevenLabs makes each persona sound more realistic and distinct.
For video mode, we use browser getUserMedia for camera and microphone access. During the call, live frames are sampled and sent to the backend. Our current video path uses an OpenCV-based face-detection pipeline. From that pipeline, we estimate coaching-safe signals such as eye-contact estimate, face-centered estimate, head-movement stability, and facial engagement estimate.
The final evaluation is multimodal but evidence-based:
- transcript content drives empathy, clarity, question quality, escalation handling, and summary behavior
- audio signals drive pace, filler-word, interruption, and turn-taking scoring
- video signals are only used in video mode for nonverbal presence and eye-contact estimate
We are careful not to treat video signals as emotion detection, truth detection, or mental-state analysis. They are used only as communication coaching cues.
A simplified view of our scoring idea is:
$$ \text{Final Score} = w_t(\text{Transcript Score}) + w_a(\text{Audio Score}) + w_v(\text{Video Signal Score}) $$
where each weight depends on the simulation mode. For example, in a voice-only simulation, video signals are not included. In a video simulation, nonverbal communication signals contribute to the final coaching report.
Voice and persona realism
A major part of RoleCall AI is making each generated persona feel different.
We did not want every persona to sound like the same AI assistant. A worried elderly patient, an angry customer, a professional interviewer, and a manipulative scammer should create completely different practice experiences.
That is why we designed the system to use different ElevenLabs voices based on generated persona details. Voice selection is connected to the persona’s age range, role, tone, and context.
The voice is not just decoration. It is part of the simulation.
We also explored how a persona should speak more naturally:
- how long it should talk
- when it should stop
- when it should pause
- when it should interrupt
- when it should reveal hidden information
- how its tone should change under pressure
For example, a scammer may start polite and official-sounding, but become more serious or forceful when the user refuses to share information. A patient may sound hesitant and confused. A recruiter may sound professional and direct. These details make the simulation feel more realistic and useful.
Challenges we ran into
The hardest part was making the AI persona feel like a real person instead of a generic assistant.
A normal AI chatbot can answer questions, but RoleCall AI needs to behave like a specific person in a specific situation. A patient should not sound like a recruiter. A scammer should not sound like a teacher. An angry customer should not speak like a calm customer. Even inside the same industry, every person has a different tone, patience level, and way of revealing information.
We had to think deeply about:
- how to make one generated persona different from another
- how to make the persona remember its role and hidden goals
- how to make the voice match the persona
- how to decide when the persona should reveal important information
- how much the AI should say at once
- when the AI should pause, stop, or interrupt
- how the persona’s tone should change under pressure
- how to evaluate the trainee fairly from transcript, audio, and video signals
One major challenge was turn-taking. Human conversation is not just about what someone says. It is also about when they say it, how long they speak, when they stop, and whether they interrupt. We had to tune the simulation so the AI persona would not over-explain everything immediately.
Voice realism was another major challenge. If every persona sounds the same, the simulation feels fake. We mapped persona details to different ElevenLabs voices and thought carefully about how age, role, emotion, and situation should affect the voice.
The video-analysis path also had tradeoffs. We originally considered a full landmark-based pipeline, but the OpenCV face-detection path was more stable in our current environment. We decided to focus on reliable coaching-safe signals first instead of forcing an unstable ML pipeline.
We also had to balance realism and responsibility. A scam simulation should feel realistic enough to train people, but it should not become a tool for teaching harmful behavior. A healthcare simulation should train communication and escalation, but it should not pretend to give medical advice.
Accomplishments that we're proud of
We are proud that RoleCall AI became a real simulation system, not just a voice chatbot.
The biggest accomplishment is that a user can describe a person and situation in natural language, and RoleCall AI turns it into a full practice experience: persona, scenario, rubric, voice, live conversation, multimodal analysis, and coaching report.
We are especially proud of building a system where the persona is not static. The Simulation Agent tracks conversation state, revealed facts, hidden risks, trainee actions, and escalation logic. This makes the AI behave more like a real person as the call develops instead of simply answering one message at a time.
We are also proud of how we used voice as a core part of the simulation. ElevenLabs is not just an add-on for us. It helps make the generated persona feel present. By mapping different persona types to different voices, we made the training experience more realistic across patients, customers, interviewers, and other roles.
Another accomplishment is the video-call experience. RoleCall AI does not only analyze what the trainee said. It also looks at how the trainee communicated during the call through coaching-safe signals like eye-contact estimate, face-centered estimate, head movement, speaking pace, pauses, and interruptions. This makes the final report feel closer to real communication coaching.
We are also proud of making the evaluation evidence-based. The report does not just give a random score. It connects scores to transcript moments, audio/video signals, missed opportunities, and better response examples. For example, if the patient mentions chest tightness and the trainee misses it, the report points to that exact moment and explains why escalation mattered.
Most importantly, we built something that can help people practice before the real pressure happens. New workers, students, and service-role trainees often learn by making mistakes in real situations. RoleCall AI gives them a safer place to make those mistakes, understand them, and improve.
What we learned
We learned that realistic communication training is much harder than generating text.
At first, the problem sounds simple: let the user talk to an AI. But for the simulation to be useful, the AI needs to act like a believable person with a role, memory, tone, goal, hidden information, and changing behavior.
We also learned that voice changes everything. The same sentence can feel calm, nervous, professional, threatening, or confused depending on how it is spoken. That made ElevenLabs a key part of our project, because voice is what turns a generated persona from text into something that feels closer to a real conversation.
We learned that feedback has to be specific to be useful. A score alone does not help someone improve. The trainee needs to know what happened, when it happened, why it mattered, and what they could say next time.
We also learned to be careful with multimodal analysis. Audio and video signals can make coaching more helpful, but they must be presented responsibly. That is why we describe video analysis as coaching estimates, not emotion detection or psychological assessment.
What's next for RoleCall AI
Next, we want to make RoleCall AI feel even closer to real training.
One major direction is deeper voice personalization. In the future, organizations could use approved past training calls or customer-service recordings to create more realistic persona voices and speaking styles with ElevenLabs voice technology(Voice Clone). With permission, a business could train new staff on the types of callers they actually face: frustrated customers, confused patients, nervous applicants, difficult sales prospects, angry guests, or high-pressure support calls.
We also want to improve turn-taking and conversational behavior. The next version should better understand when to pause, when to interrupt, when to reveal hidden information, and when to change tone based on how the trainee responds.
Another future direction is moving beyond conversation simulation into case simulation. Instead of only joining a voice or video call, trainees could enter an AR/VR environment and handle a full scenario: a clinic front desk, hospital discharge follow-up, customer escalation room, sales meeting, interview room, or scam-defense training environment.
This would turn RoleCall AI from a call simulator into a complete practice environment.
Future improvements include:
- deeper ElevenLabs voice tuning
- voice cloning from approved training recordings
- more realistic persona memory
- stronger interruption and turn-taking
- multilingual simulations
- real phone-call mode
- company-specific training libraries
- team dashboards
- progress tracking over repeated simulations
- generated avatar images
- 3D or talking avatars
- AR/VR case simulations
- stronger multimodal evaluation
Our long-term vision is simple:
People should not have to wait for real pressure to learn how to communicate under pressure.
RoleCall AI gives them that practice before it matters most.



Log in or sign up for Devpost to join the conversation.