-
-
Preparing file and waiting for result
-
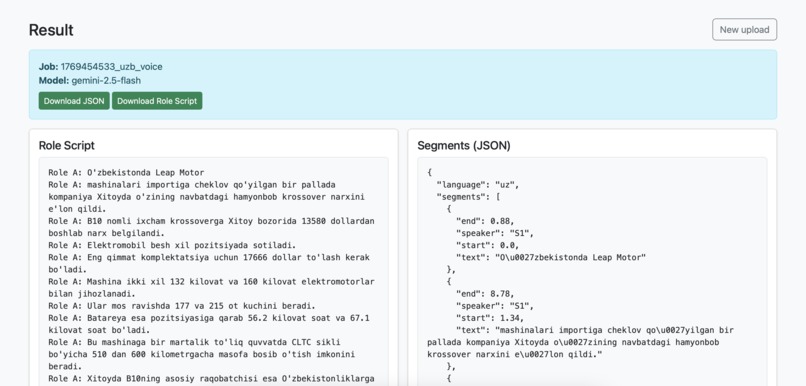
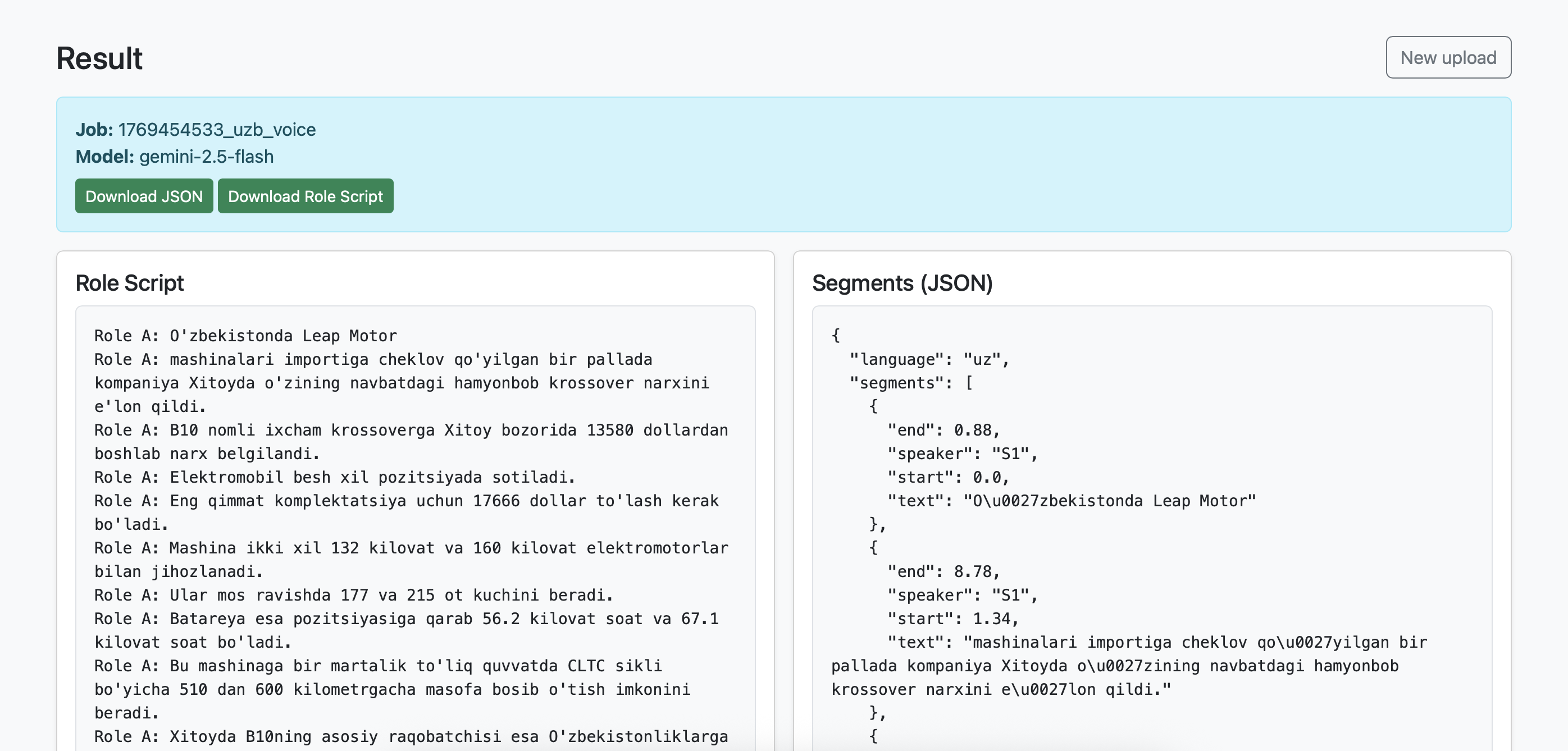
result appears as Role Script and Segments (JSON) which is really need for dubbing services
Inspiration
Dubbing and dialogue localization workflows often start with a simple task: turning audio into text. In practice, this step is surprisingly painful. Most speech-to-text tools produce long, unstructured transcripts that ignore who is speaking, require heavy manual cleanup, and are not designed for dubbing or role-based dialogue at all. This problem becomes even more visible when working with less-represented languages, where accuracy issues, speaker switches, and formatting errors can slow down the entire workflow. I wanted to explore whether modern multimodal AI could move beyond “raw transcription” and directly produce structured, role-aware scripts that are actually usable in real production. That idea became RoleScript.
What it does
RoleScript transforms audio or video into structured, role-based dialogue scripts designed for dubbing and dialogue workflows. Instead of producing a flat transcript, the system automatically: Transcribes speech from audio or video Separates speakers into distinct roles Splits dialogue into short, natural segments Outputs both structured JSON and a clean Role A / Role B script This makes the output immediately usable for dubbing, translation, and dialogue editing without heavy manual cleanup.
How we built it
RoleScript transforms audio or video into structured, role-based dialogue scripts designed for dubbing and dialogue workflows. Instead of producing a flat transcript, the system automatically: Transcribes speech from audio or video Separates speakers into distinct roles Splits dialogue into short, natural segments Outputs both structured JSON and a clean Role A / Role B script This makes the output immediately usable for dubbing, translation, and dialogue editing without heavy manual cleanup.
Challenges we ran into
RoleScript was built as a lightweight web application using Flask and Bootstrap for a simple and fast user interface. On the backend, we used the Gemini API to analyze uploaded audio files. Gemini handles: speech transcription speaker diarization timestamp extraction structured JSON generation The application uploads audio, waits for processing to complete, requests a structured transcription from Gemini, and then post-processes the result into role-based dialogue scripts. The final output is displayed in the browser and can be downloaded for further use.
Accomplishments that we're proud of
One of the biggest challenges was dealing with real-world API constraints, including quota limits, rate limits, and project configuration issues. Debugging these limitations was essential to get a stable working demo. Another challenge was ensuring that the transcription output was usable, not just accurate. Raw transcripts often require heavy editing, so we had to carefully design prompts and segmentation logic to produce clean, dubbing-ready dialogue. Handling asynchronous file processing and keeping the UI responsive during longer operations were also key technical challenges.
What we learned
We learned that multimodal AI systems like Gemini are most powerful when used to generate structured outputs, not just text. We also gained hands-on experience with: audio processing pipelines API quota management prompt design for structured reasoning turning AI capabilities into practical tools rather than demos Most importantly, we learned that focusing on a specific real-world workflow leads to stronger and more meaningful AI applications.
What's next for Role Script
Future improvements include: editable dialogue segments directly in the UI subtitle (SRT) export for video workflows accuracy improvements using custom vocabularies and glossaries draft voice synthesis to preview dubbing output RoleScript aims to evolve into a complete dialogue preparation tool for modern dubbing and localization workflows.


Log in or sign up for Devpost to join the conversation.