-
-
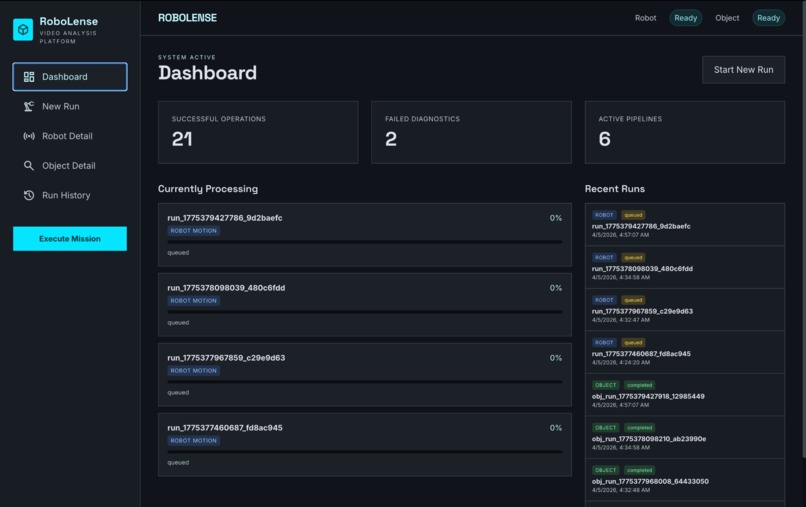
Landing Page / Dashboard
-
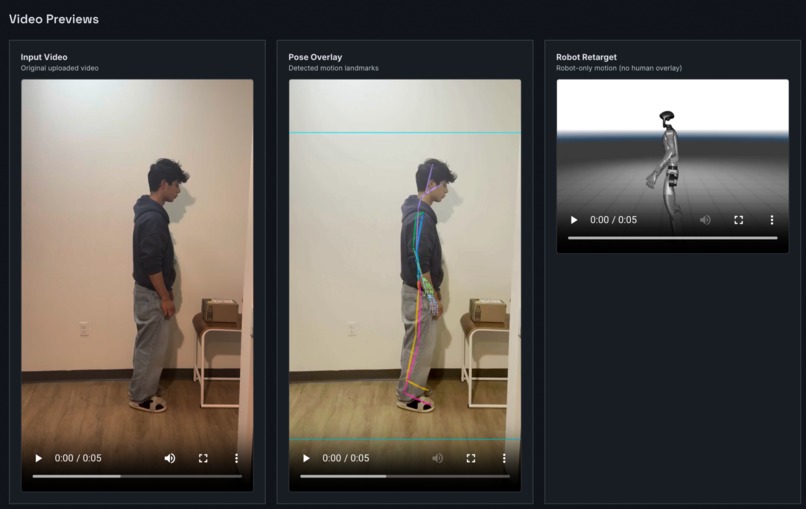
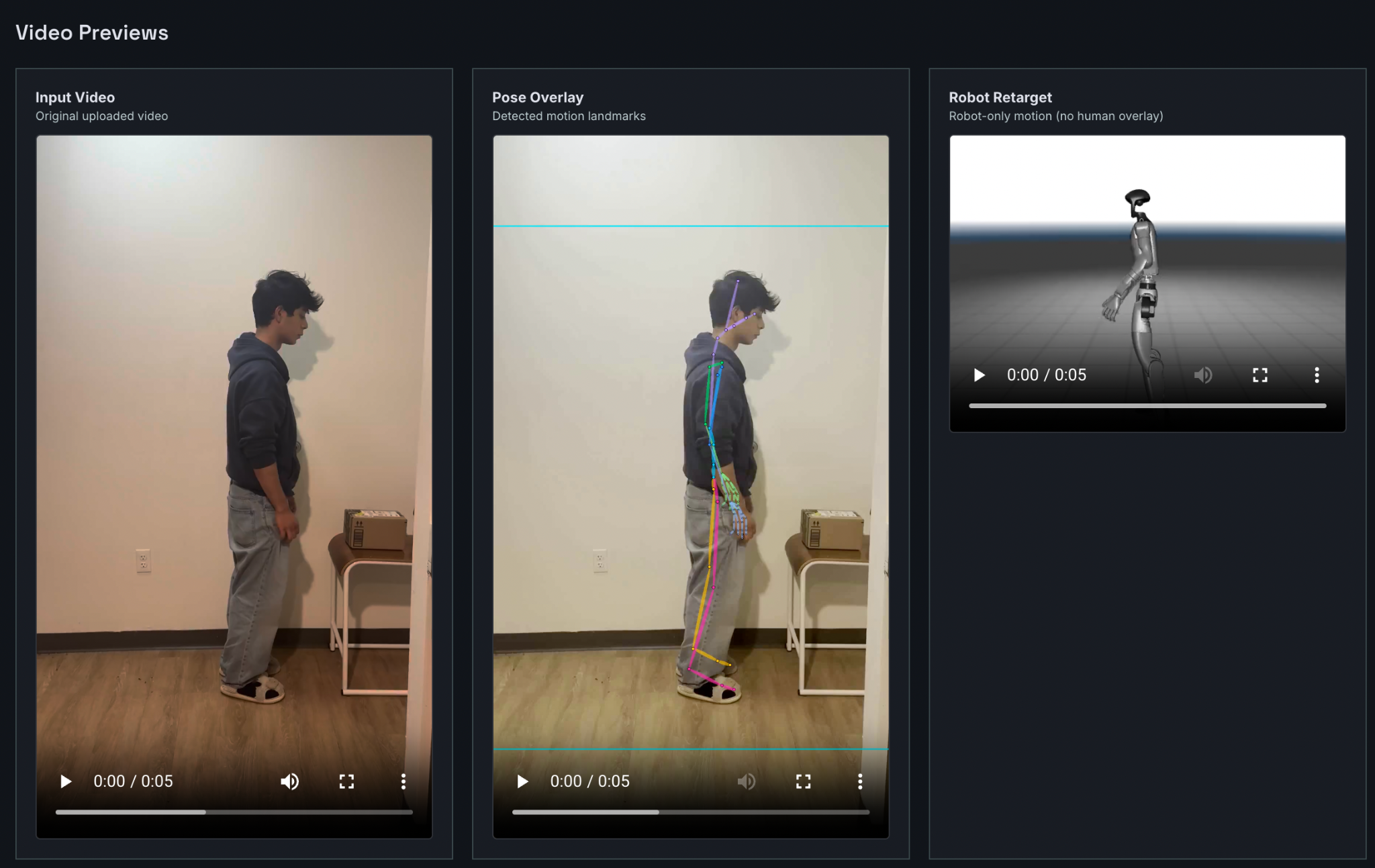
Human pose detection + MuJoCo simulation with Unitree G1
-
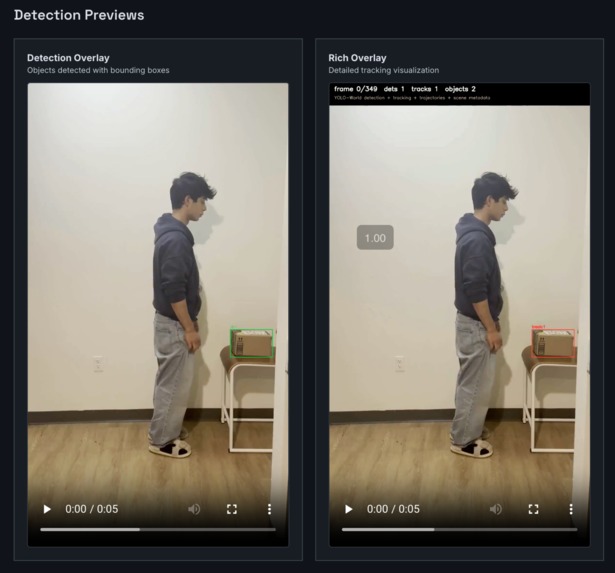
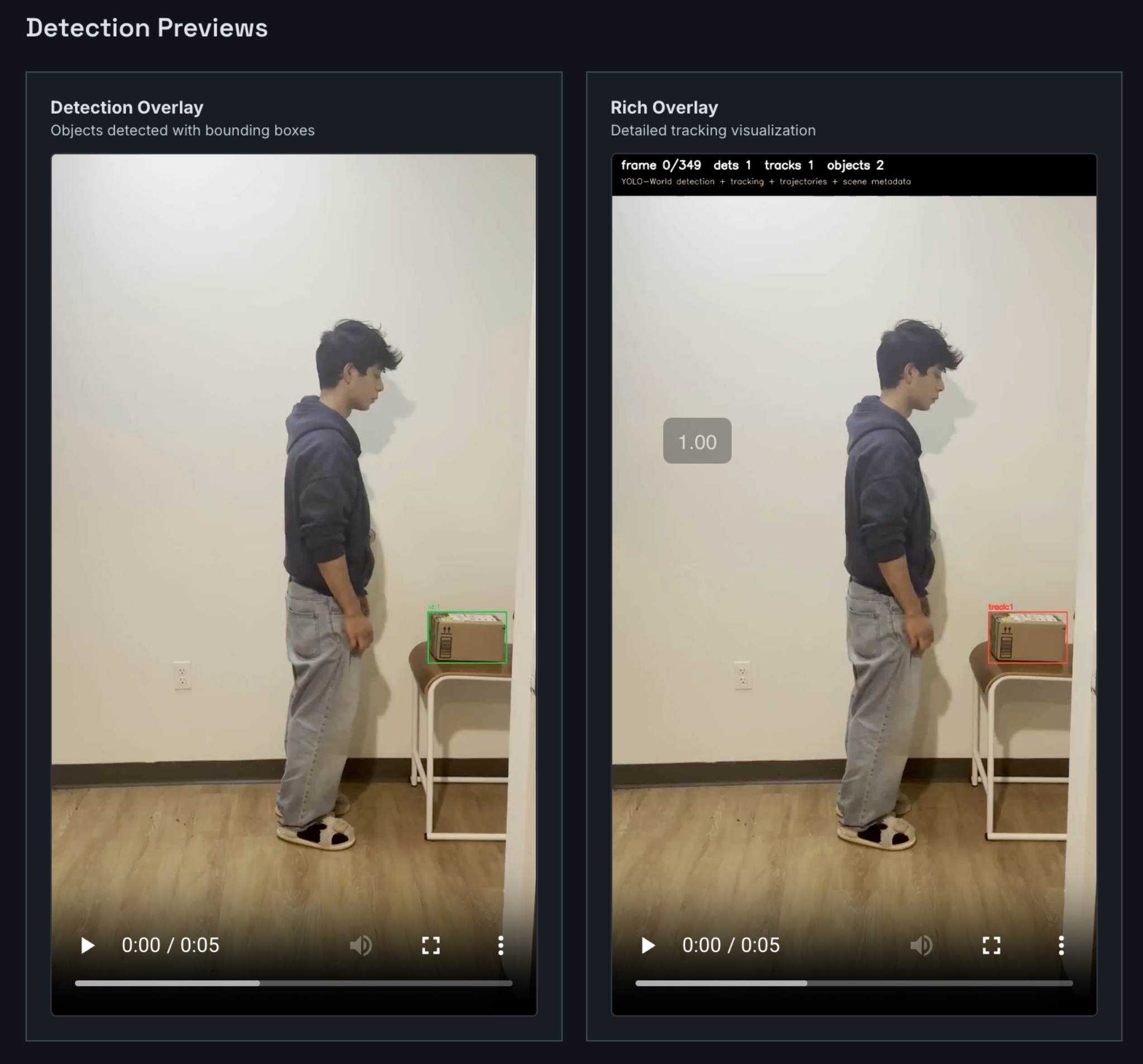
Object detection + pose estimation
-
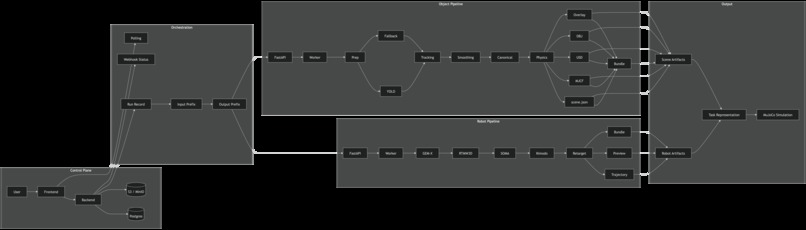
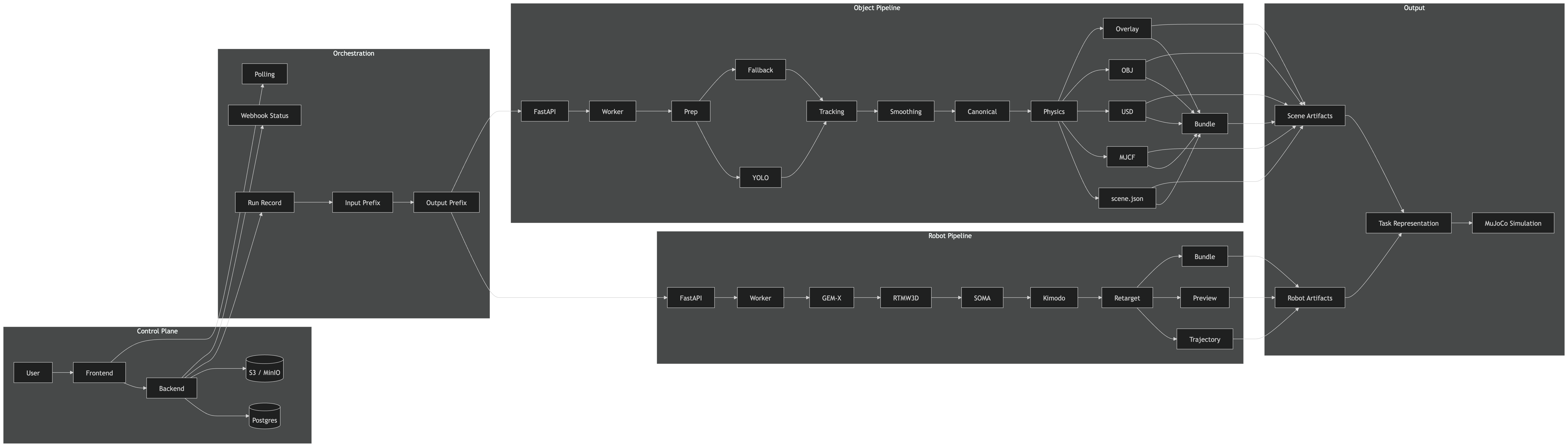
System Architecture
RoboLens automates the conversion of raw human task videos into robot-ready MuJoCo simulations.
Inspiration
Training robots today is still painfully manual.
If you want a robot to learn a task, you usually need to hand-script behaviors, label demonstrations, rebuild scenes in simulation, and manually translate human actions into something a robot can actually use. That workflow is slow, expensive, and one of the biggest bottlenecks in physical AI.
We built RoboLens to automate that pipeline.
Instead of spending hours turning a human demonstration into structured robotics data, RoboLens takes a video and automatically converts it into a robot-ready simulated task.
What it does
RoboLens is an automation pipeline for physical AI.
Given a video of a person performing a task, RoboLens automatically:
- extracts the human motion
- retargets that motion to a robot
- detects and tracks the objects in the scene
- reconstructs the environment
- generates simulation-ready assets
- outputs the full task inside a working MuJoCo simulation
In other words, RoboLens automates one of the most repetitive parts of robotics development: turning real-world demonstrations into structured training data and simulation workflows.
How we built it
We built RoboLens as a modular, distributed system with three main parts:
Frontend
- handles video upload, run tracking, and artifact visualization
Robot pipeline
- extracts human pose and converts it into robot-compatible motion trajectories using the SOMA pipeline
Object pipeline
- detects, tracks, and reconstructs objects and scene structure from the same video
We then merge both outputs into a unified scene representation and export the final result into a MuJoCo simulation.
Under the hood, the system uses async microservices, Dockerized services, cloud object storage, tracking and detection models, and a simulation export pipeline so the full workflow runs automatically end to end.
Challenges we ran into The hardest part was not building one model, it was automating the entire workflow reliably.
We had to:
- align human motion and object understanding from the same video
- make noisy vision outputs stable enough for simulation
- convert detections into structured scene geometry and physical metadata
- ensure the final outputs were not just predictions, but actually usable in MuJoCo
A big challenge was bridging three very different domains at once: computer vision, robotics, and simulation.
Accomplishments that we're proud of
We’re proud that RoboLens is not just an analysis tool, its a full system! In a single pipeline, we automated:
- human motion extraction
- robot retargeting
- object and scene understanding
- simulation asset generation
- MuJoCo task reconstruction
That means we took a workflow that would normally require significant manual robotics and simulation work and turned it into an end-to-end system. We also built it as a real multi-service product, not a one-off script, which makes it much more extensible beyond the hackathon.
What we learned
We learned that in physical AI, the biggest opportunity is often not just better models its being able to use them better through automation.
The real bottleneck is the manual work between steps: turning raw demonstrations into structured, usable outputs. We also learned that building for robotics means accuracy alone is not enough; outputs have to be consistent, interpretable, and simulator-ready.
Most importantly, we learned that connecting ML, infrastructure, and robotics into one seamless workflow creates much more value than solving any one piece in isolation.
What’s next for RoboLens
Next, we want to improve the physical fidelity and scalability of the system. That includes:
- more accurate 3D reconstruction
- stronger physics and object property estimation
- support for more simulators beyond MuJoCo
- larger-scale dataset generation from video demonstrations
- tighter integration with real robot training workflows
Our long-term vision is for RoboLens to become an automation layer for physical AI: a system that can turn massive amounts of real-world video into robot training data at scale.
Built With
- amazon-web-services
- docker
- express.js
- fastapi
- gem-x
- minio
- mmpose
- mujoco
- opencv
- python
- pytorch
- react
- s3
- soma
- typescript
- yolo

Log in or sign up for Devpost to join the conversation.