-
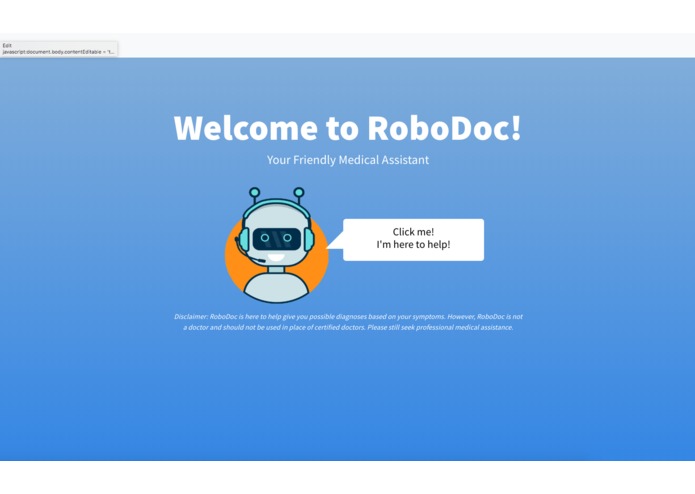
RoboDoc is an intelligent chatbot for rapid and friendly predictive disease diagnosis based on large text corpora.
-
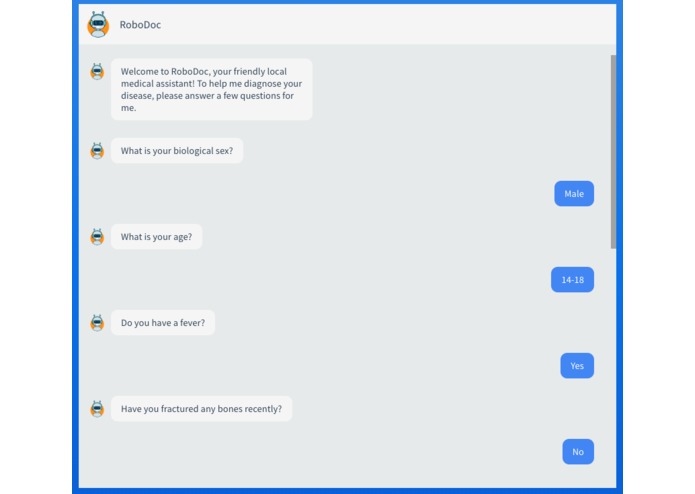
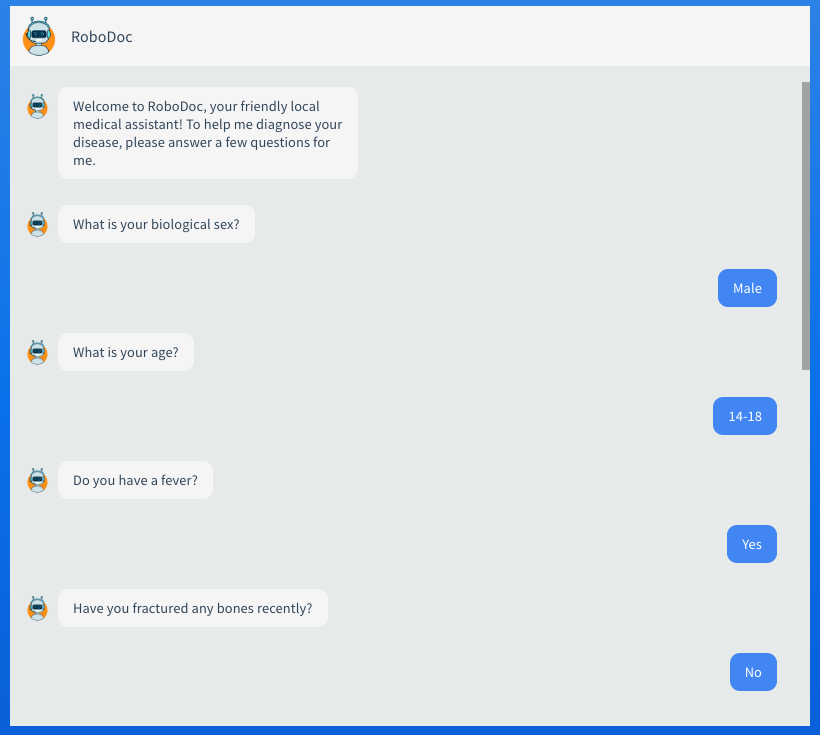
The RoboDoc chatbot is intelligent, friendly, and responsive.
-

RoboDoc provides a potential diagnosis and credible links to obtain more information.
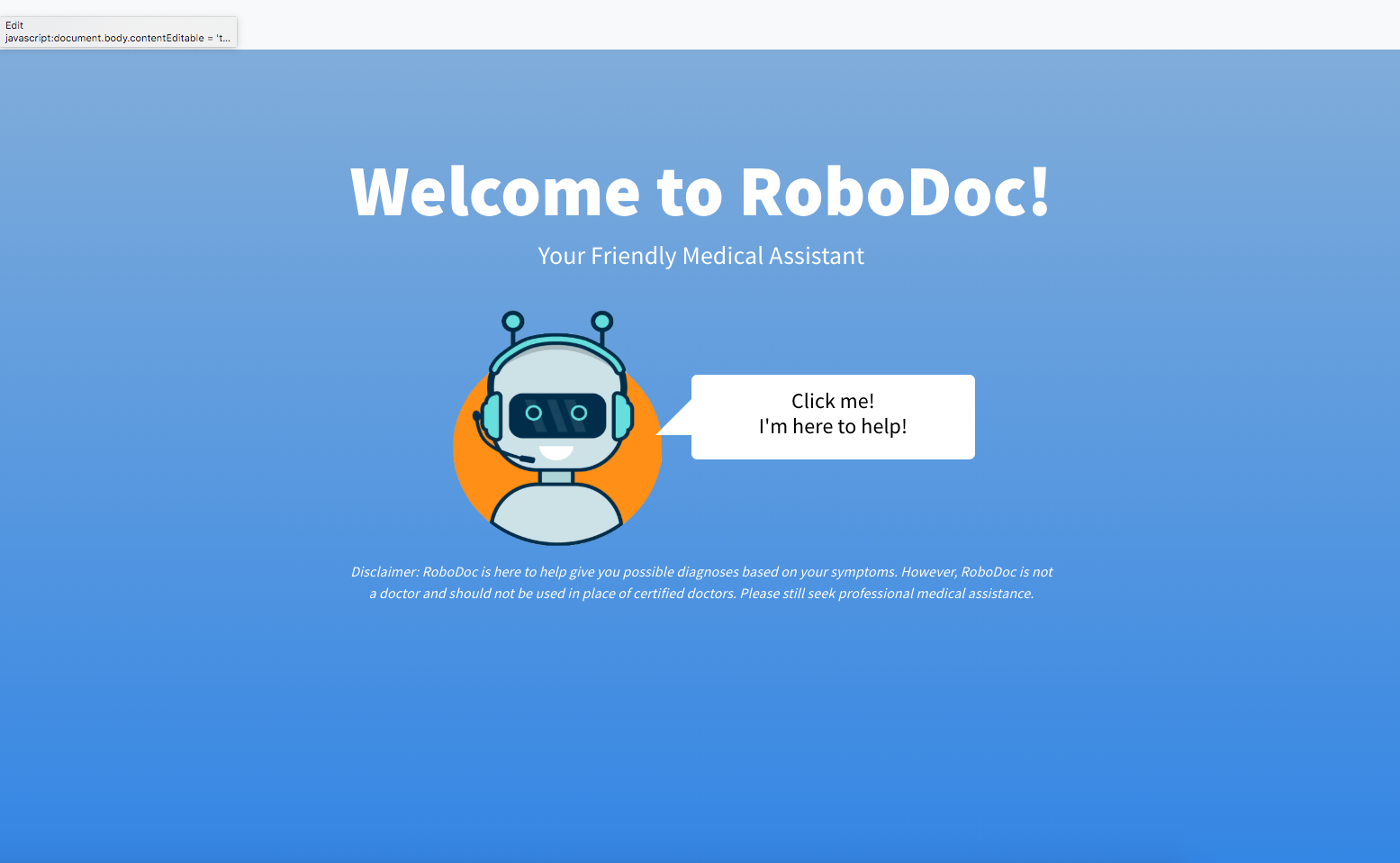

RoboDoc - Your Friendly Medical Assistant
RoboDoc is a tool for rapid and friendly predictive disease diagnosis based on large text corpora. It takes the form of an intelligent chatbot that prompts a user for common symptoms, determining the best symptom to ask next based on the user’s responses.
RoboDoc uses novel probabilistic models based on word similarity scores calculated from large internet corpora, such as Wikipedia, WebMD, Mayo Clinic, and Google Search. This approach allows us to develop a sense of which symptoms are most strongly correlated with which diseases, even when reviewed physicians’ data is lacking or hard to access.
We used web scraping to obtain data on the correlation of symptoms with diseases. We first normalize this data to account for the prevalence of a given disease and demographic information of the user. We then represent each disease’s mapping against symptoms as a vector, allowing easy calculation of a probabilistic score to represent the relative likelihood of the disease given the user’s symptoms. At each stage, we utilize a naive Bayes classifier to determine the optimal next question to ask the user. Once we obtain a desired level of confidence, we inform the user of the most probable diseases they have based on their symptoms, along with possible next steps (e.g. reading up more on the possible disease). We host our application through Google Cloud Platform’s Google App Engine.
In addition, RoboDoc’s polished and user-friendly interface allows it to collect data from users in a friendly and conversational manner. This combination of an accessible interface and low-maintenance approach means that RoboDoc holds special promise in targeting neglected or poorly studied diseases, especially in areas that may be hard to reach through traditional methods. Although many diseases may suffer from a dearth of physician-reviewed data, mining social media for word associations allows for a first-hand view into less commonly studied diseases.
Although RoboDoc currently focuses on word correlations, it could be easily extended through large public health databases. Therefore, to improve the model, we plan to further incorporate more data from national health organizations. We also have plans to increase the robustness of the algorithm by further analyzing the user’s demographics to weight the prevalence of a given disease for the user.




Log in or sign up for Devpost to join the conversation.