-
-
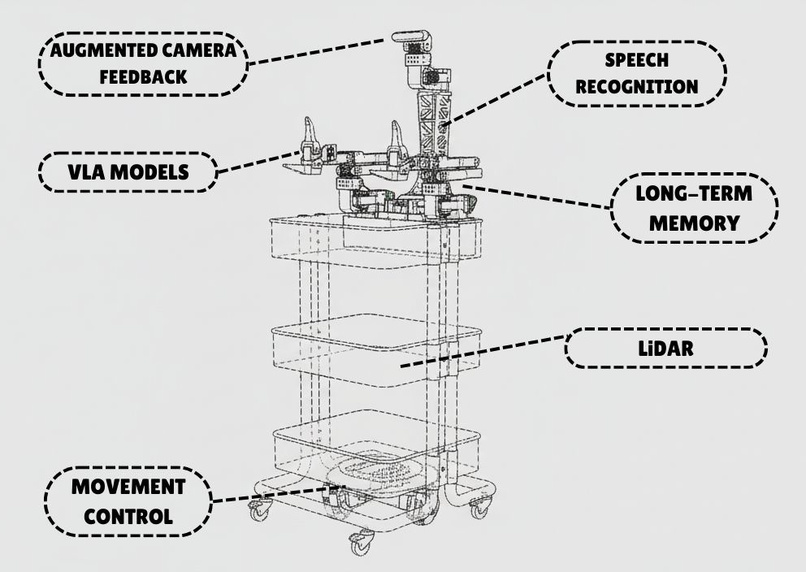
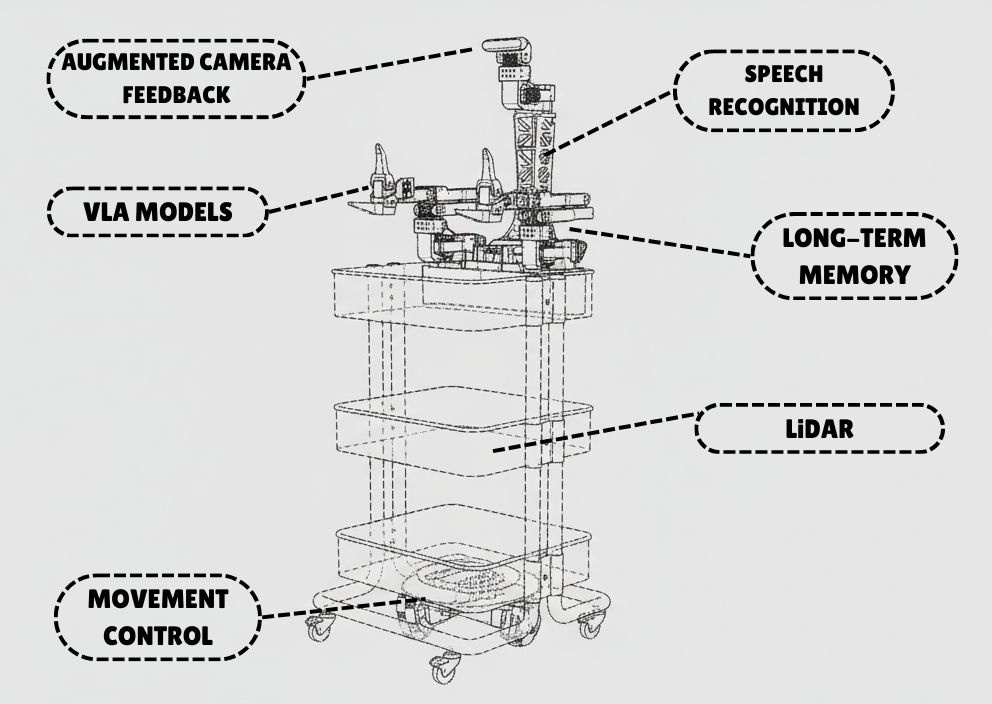
Main features of RoboCrew
-
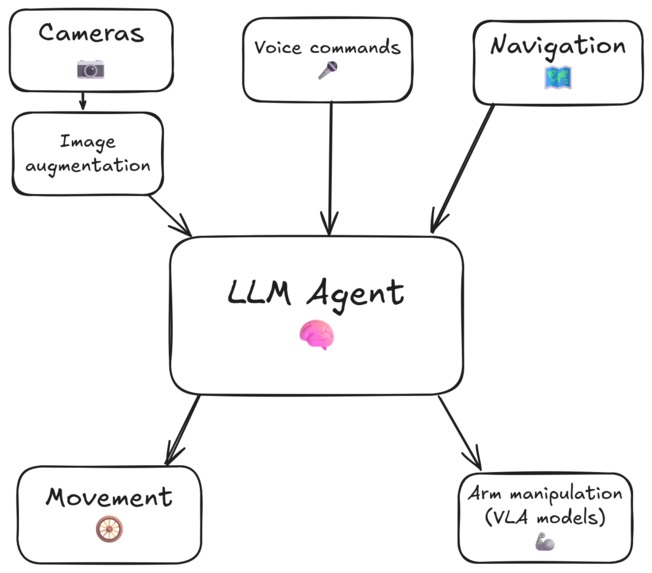
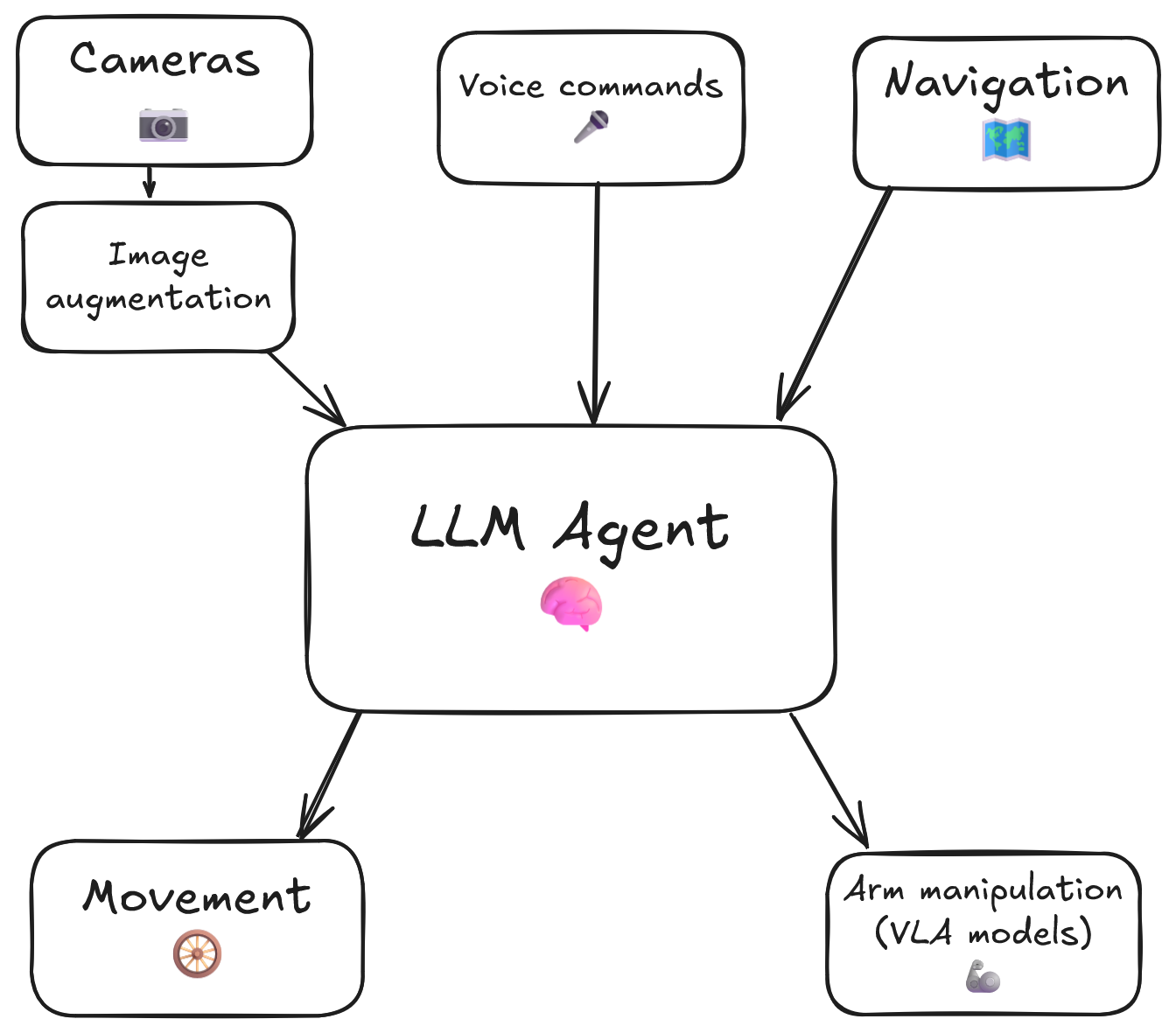
Scheme of our embodied agent
Inspiration
Most of the robotic community nowadays tries to solve the biggest robotic problem - generalisation - by developing bigger and better VLA models, feeding it with better data etc. Problem, which we have already solved by embodying LLM into the robot and equipping it with appropriate tools, helpers and automations.
What it does
The idea of generalisation is to make robot consciously operate in unknown environment. If we bring it to our house (which it never seen before) and ask it to clean the kitchen, robot should be able to find where the kitchen is and how to clean it.
While others try to solve it just improving a VLA (vision-language-action) models, we choose other approach. LLM agent inside our robot analyzes image from camera and other sensors (as lidar) to understand its surroundings, and makes a decision what to do next to fulfill his task. He can use variety of tools, as movement ones (go forward, turn left/right etc.) and manipulation (VLA policies to grab a notebook from the table, give it to a human, clean the trash from the table etc.)
How we built it
We built our agent on the top of XLeRobot - mobile household robot with two arms and wheels; but library is built to support different robots - we already succesfully implemented it on the Earth Rover Mini as well. Core idea of RoboCrew is that it makes our robot to be conscious. For example, robot receives a task to "bring documents to human", and in order to accomplish it first looking around to find a documents, then approaching it, then grabs, after looks for and approach human, and finally gives documents to human. Robot just received high-level task, but plannded and made all intermediate steps by itself.
Challenges we ran into
There have been ton of challenges, I'll describe only some of them ;)
- LLMs had a problem on recognizing right and left - robot often mismatched the direction of his turn. To overcome it, we introduced image augmentation before sending it to LLM - we writing directly on the image where is the right/left, and draw the angle grid. After that change robot began to turn more precisely.
- Making LLM to steer robot precizely. At some point we made our agent to be able to maneur with the robot and to use arms for object manipulation. We given it a task to approach a table and grab a notebook from it. But agent wasn't able to approach a notebook precizely to grab it! Or it acivated grabbing tool when robot too far, or robot moves somewhere sideways and tries to grab notebook when not facing it. To solve the problem, we introduced a "precize" navigation mode - which robot activate when it close to obstacles. In that mode robot has camera turned by different angle - to see its body, and is able to do only small precize moves.
Accomplishments that we're proud of
We did something that most of the robotic community has unsuccessfully tried for last monthes, and much more. While others just use VLAs to make robot do one simple task, our robot makes own decisions, listen for voice commands, navigates spaces it never been and manipulates objects.
What we learned
We learned that LLMs are not good in physical world understanding today - LLMs are not trained for it. To deal with it, we needed to do many tricks, as for example image augmentation. Also we found that Gemini models performing much better in real world understanding in comparison to OpenAI or Anthropic.
What's next for RoboCrew
There are lot of things to improve:
- We need to make arms manipulation to work more smooth,
- We need to improve indoor navigartion by introducing mapping (memorizing how does rooms look like to find a kitchen or bedroom faster next time); we already done first step to it by adding a support for LiDAR sensor.
- Also we need to improve the way our LLM thinks - make it to reason better and make better decisions.
Built With
- gemini-3-flash
- lerobot
- xlerobot
Log in or sign up for Devpost to join the conversation.