-
-

Personal Guide
-

Scanning Real-World Monuments
-
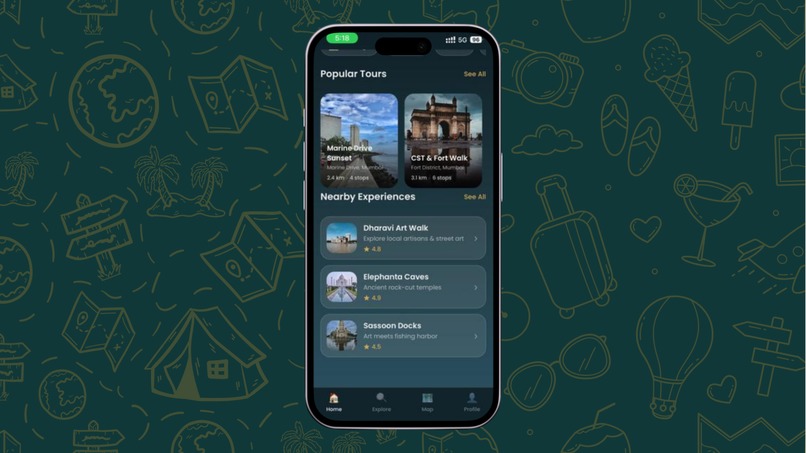
HomePage
-
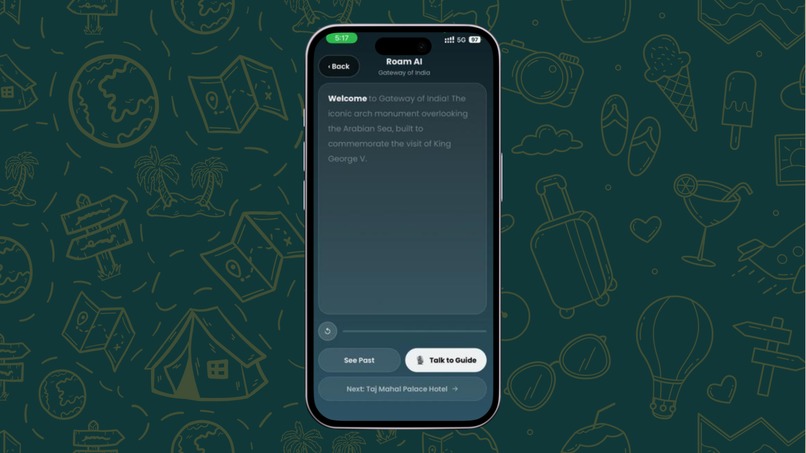
Audio Guide with Subtitles
-
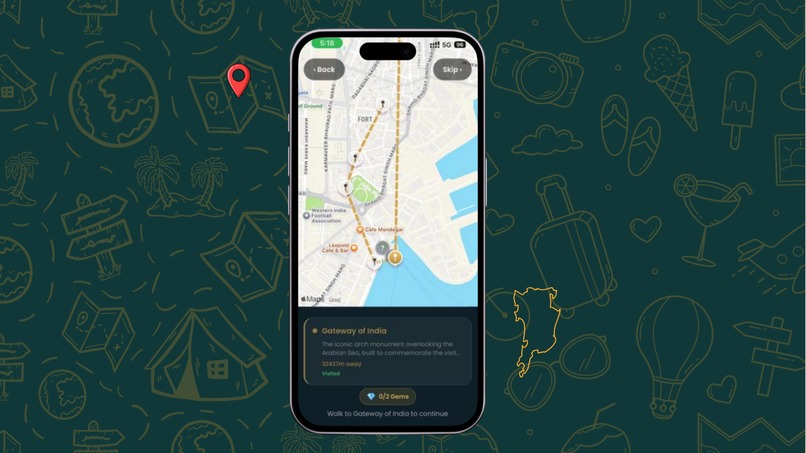
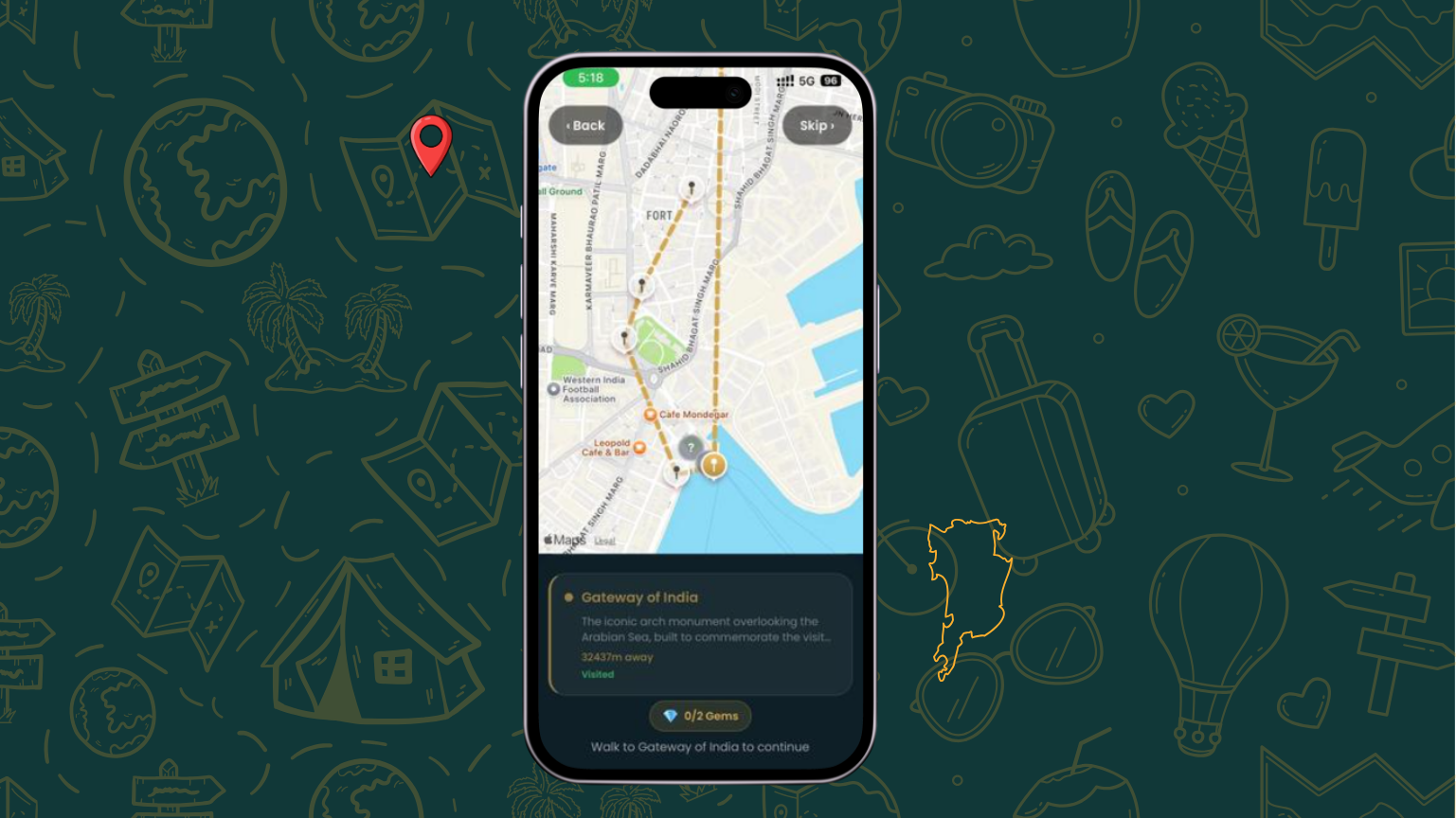
Tour Map
-
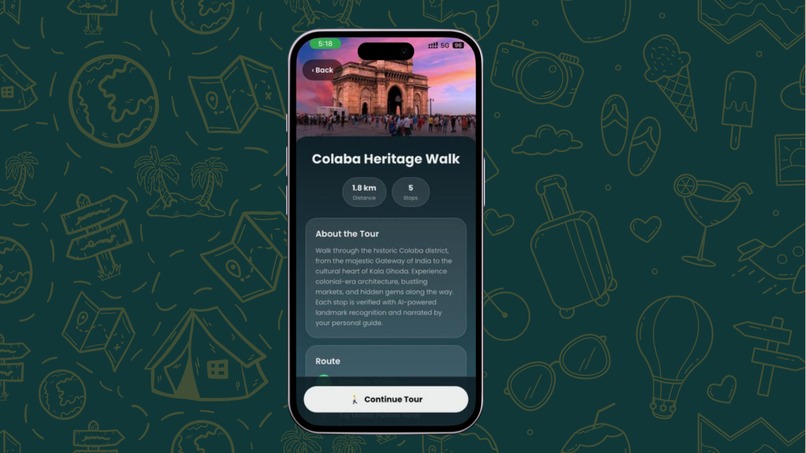
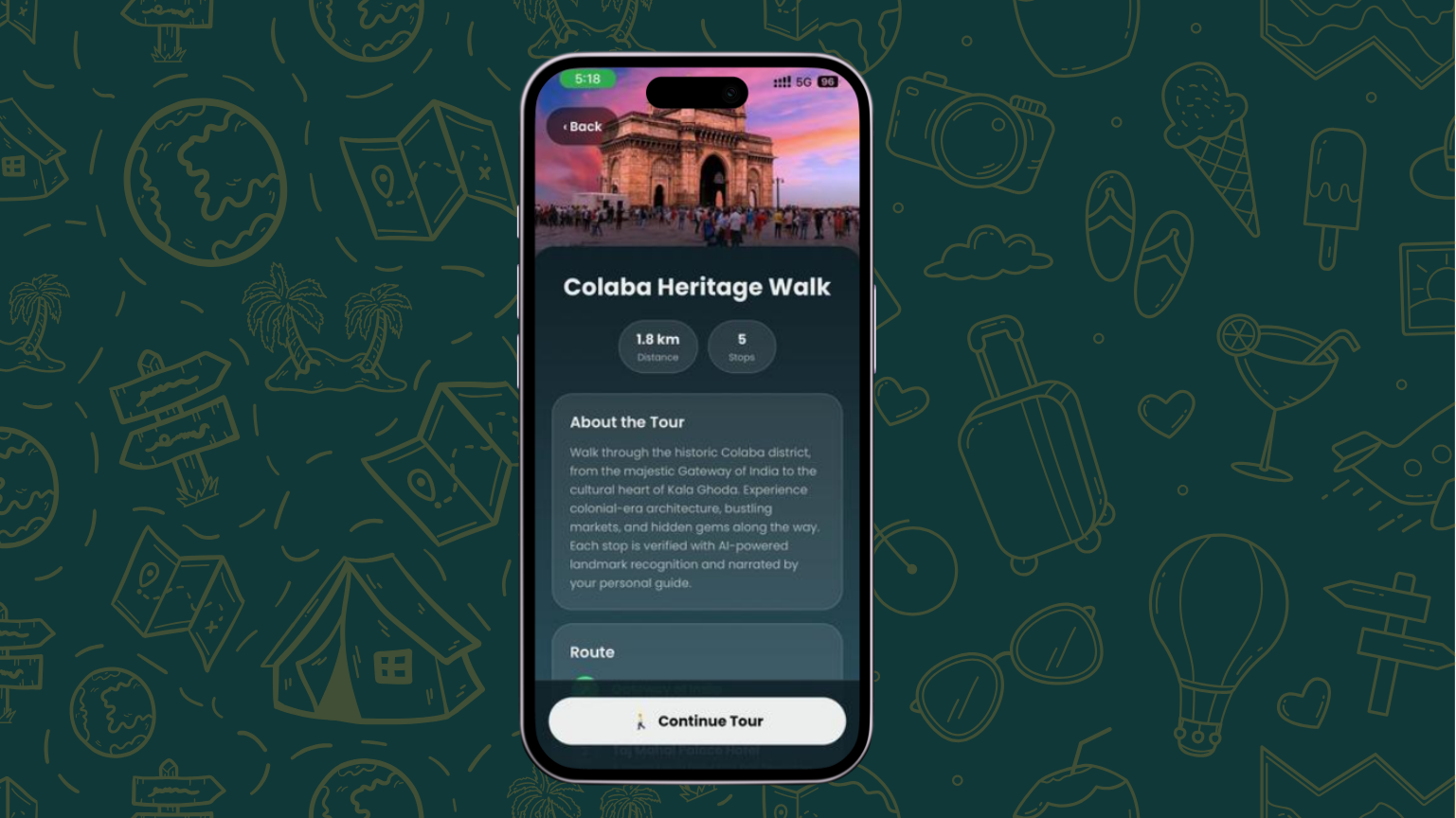
Tour Summary
-
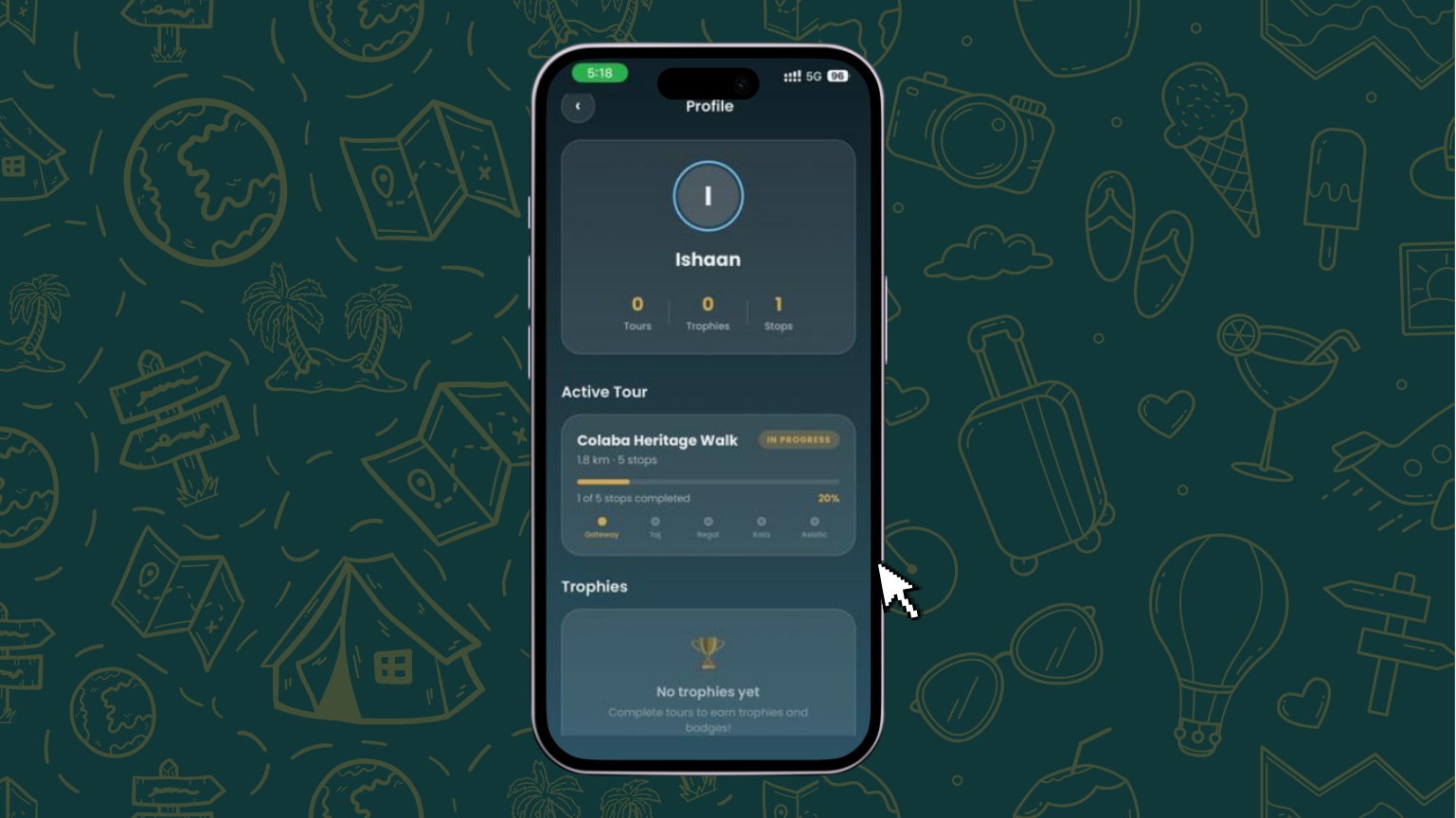
Profile Page
-
Architecture Diagram


Roam: AI Tour Guide
Inspiration
We love exploring cities on foot, but traditional audio tours feel lifeless — pre-recorded clips that drone on regardless of what you're looking at or what you care about. Meanwhile, guidebooks can't answer follow-up questions, and human guides don't scale. We wanted something that combined the best of all three: a guide that's always available, deeply knowledgeable, adapts to your personality and language, and can actually see the world through your eyes. When Google released Gemini's native audio and vision capabilities, we realized we could build exactly that — a real-time, conversational AI tour guide that listens, sees, and responds like a human companion walking beside you.
What it does
Roam transforms city walks into immersive, AI-narrated heritage experiences. Here's the full journey:
Personalized Onboarding — Choose your name, pick one of four guide personalities (Professor Arjun the historian, Mischief Maya the comedian, Dreamy Luna the poet, or Captain Rex the adventurer), and select from 8 languages including English, Hindi, Spanish, French, Arabic, Portuguese, Japanese, and German.
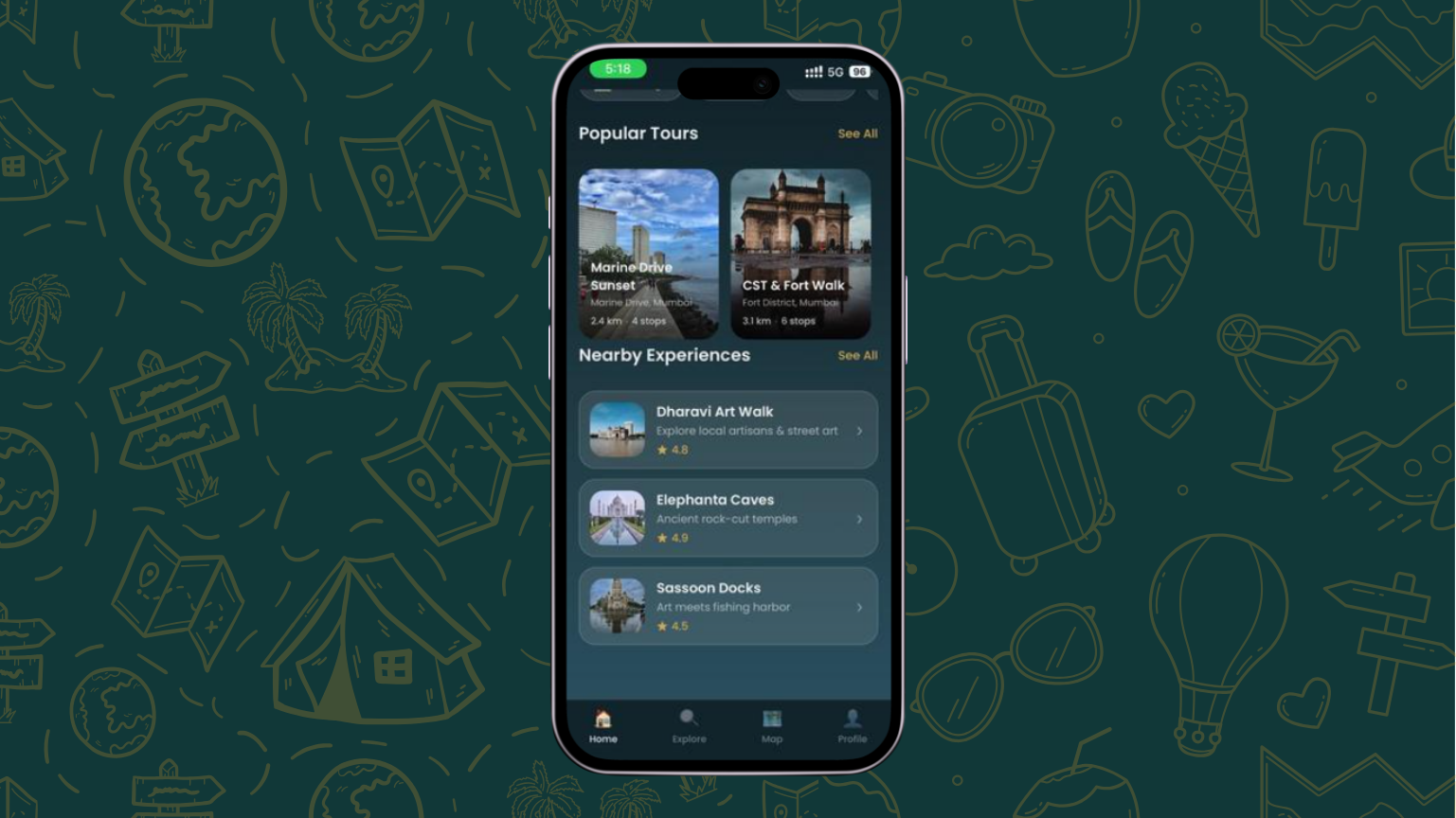
Guided Walking Tours — Follow stop-by-stop routes on an interactive map with real-time GPS tracking and distance countdowns. Our launch tour — the Colaba Heritage Walk — covers 5 iconic landmarks across South Mumbai: Gateway of India, Taj Mahal Palace Hotel, Regal Cinema, Kala Ghoda, and the Asiatic Library.
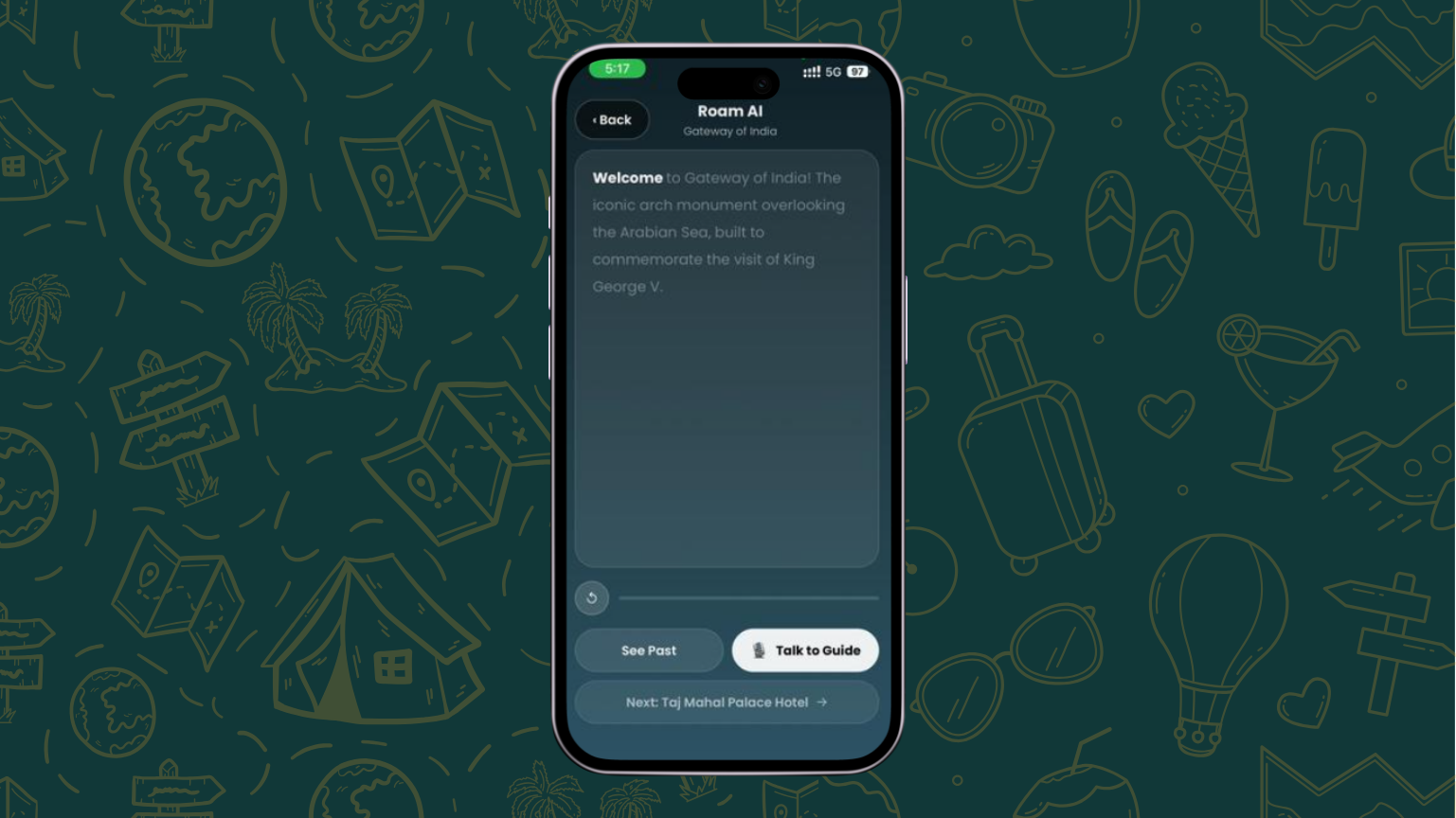
AI Landmark Verification — At each stop, point your camera at the landmark and tap to verify. Gemini Vision analyzes your photo and confirms you're at the right location with a confidence score — no couch completions allowed.
Word-Synced Narration — Once verified, Roam generates a fresh, personalized narration using Gemini TTS in your chosen guide's style. As audio plays, words highlight in real-time — like karaoke for culture. Each narration references your journey context, mentioning the next stop to build anticipation.
Live Voice Conversation — The core experience. Tap "Live Guide" to start a real-time voice conversation over WebRTC. The AI guide responds with near-zero latency, can see your camera feed, and references what you're looking at: "Oh, I see you're near the stone elephants on the arch!" It shares facts, tells stories, cracks jokes, and matches your energy — all in your chosen language and personality style.
Hidden Gems Gamification — Each stop has 2-3 secondary points of interest that most tourists miss — a statue tucked behind a pillar, architectural details on a facade. During live conversations, point your camera at these gems and your AI guide visually recognizes them, celebrates the discovery with an animated toast, and shares a fun fact. Track your progress and earn the "Eagle Eye" badge for finding them all.
History & Reflection — View auto-rotating historical photos of each landmark alongside AI-generated narratives about what the place looked like in its earliest days.
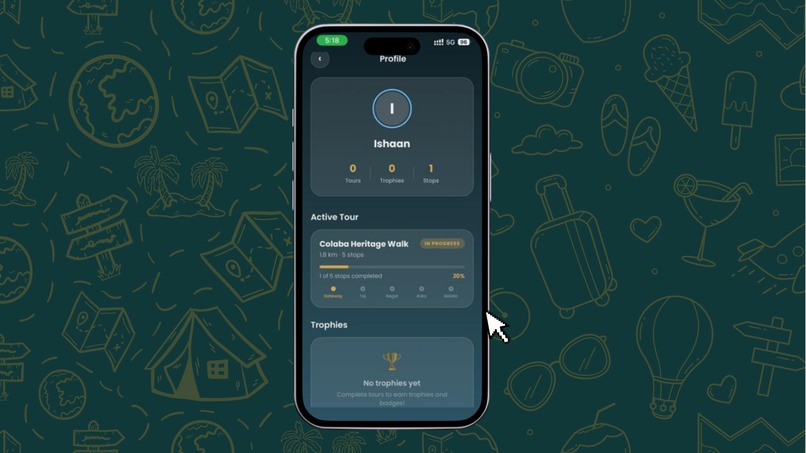
Badges & Progress — Earn the "Colaba Explorer" badge for completing the heritage walk, track completed tours, trophies, and total landmarks visited on your profile.
How we built it
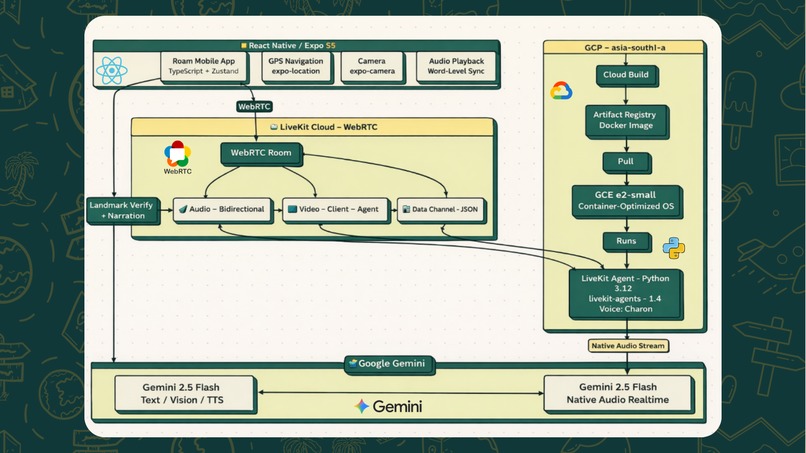
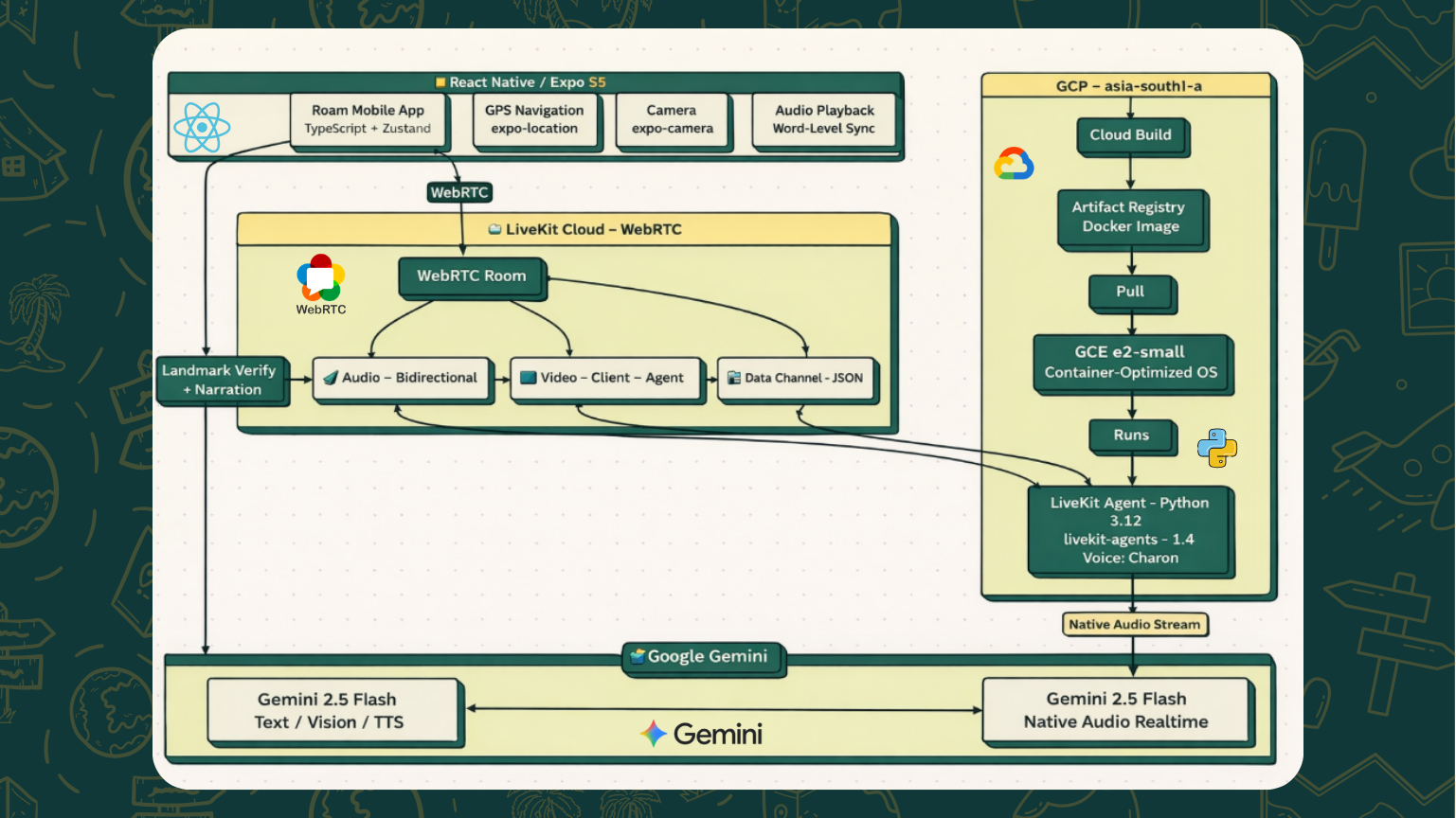
Frontend: React Native + Expo (TypeScript) with Expo Router for file-based navigation. React Native Maps for GPS tracking, expo-camera for landmark capture, expo-audio for narration playback with word-level timing sync, and Zustand for state management. The UI follows a glassmorphic design system with Poppins typography and a gold accent palette.
AI Agent: A Python server built on the LiveKit Agents framework. The agent connects to LiveKit Cloud via WebRTC and uses Gemini 2.5 Flash Native Audio Preview for real-time bidirectional voice conversation at 24kHz. It receives the user's camera feed as a video track and analyzes it for hidden gem detection. System prompts are dynamically built from the current stop data, user preferences, and hidden gem definitions.
Gemini Models — Four Models, One Experience:
- Gemini 2.5 Flash Native Audio (
gemini-2.5-flash-native-audio-preview) — Powers the live voice conversation with native audio I/O for ultra-low latency - Gemini 2.5 Flash Vision — Analyzes camera photos for landmark verification with confidence scoring
- Gemini 2.5 Flash TTS (
gemini-2.5-flash-preview-tts) — Generates narration audio with word-level timestamps for sync highlighting - Gemini 2.5 Flash — Text generation for historical narratives and chat responses
Real-Time Infrastructure: LiveKit Cloud handles WebRTC signaling, media routing, and participant management. The agent registers as roam-guide and is automatically dispatched when a user creates a room. Participant attributes carry user preferences (name, narration style, language) so the agent personalizes from the first word.
Gamification: The agent has a custom function tool report_hidden_gem_discovery() that publishes discovery events via LiveKit data messaging on a hidden_gems topic. The frontend listens for these events and triggers celebration animations.
Deployment: Dockerized Python agent deployed on Google Cloud (GCE e2-small in asia-south1), built via Cloud Build and pushed to Artifact Registry. Automated deployment script handles the full pipeline.
Challenges we ran into
LiveKit Cloud connectivity from GCP — Our first deployment in us-central1 couldn't reach LiveKit Cloud's IPs (hosted on Fly.io infrastructure). TCP connections to port 443 simply timed out. We spent hours debugging before discovering it was a cloud-to-cloud routing issue. Moving the instance to asia-south1 (Mumbai) resolved it and also reduced latency for our target users.
Word-level audio sync — Getting narration text to highlight word-by-word as audio plays required precise timestamp alignment from the TTS API. Gemini's TTS returns word-level timing data, but mapping it correctly to the rendered text with varying font widths and line breaks was tricky. We built a custom sync engine that tracks playback position and highlights the active word in real-time.
Real-time vision + audio simultaneously — Having the agent process both audio conversation and camera video feed concurrently pushed us to carefully manage the Gemini session. The native audio model handles both modalities in a single session, but getting the prompting right so the agent naturally references visual input during conversation (without awkward pauses or hallucinations) took significant iteration.
Multi-language consistency — Ensuring the AI guide stays in one language throughout a session (and doesn't slip back to English) required explicit system prompt engineering. We enforce language compliance at the prompt level and pass the language preference as a session attribute.
Generous but accurate landmark verification — Too strict and users get frustrated; too lenient and the gamification loses meaning. We tuned the vision prompt to be "generously accurate" — verifying if the photo reasonably shows the landmark without requiring a perfect shot.
Accomplishments that we're proud of
A truly conversational guide that sees — Not a chatbot, not a pre-recorded tour. A guide that holds natural voice conversations in real-time while actually seeing and referencing what you're looking at through your camera. This felt magical the first time it worked.
Four distinct personalities that genuinely feel different — Professor Arjun delivers dates and scholarly context; Mischief Maya roasts the British Empire's architectural choices; Dreamy Luna turns the Gateway of India into poetry; Captain Rex makes walking to the next stop feel like an expedition. Same facts, completely different vibes.
Hidden gems that the AI discovers visually — The agent doesn't just track GPS. It looks through your camera, recognizes secondary landmarks, and celebrates discoveries in real-time. The moment it says "Wait — is that the Chhatrapati Shivaji statue? You found a hidden gem!" feels genuinely exciting.
End-to-end Gemini integration — Four Gemini models working together seamlessly: native audio for conversation, vision for verification, TTS for narration, and text for historical content. One AI family powering the entire experience.
Word-synced narration — The karaoke-style word highlighting during narration playback is a small detail that makes the experience feel polished and intentional.
What we learned
Native audio models change everything — The jump from text-to-speech pipelines to Gemini's native audio I/O is transformative. Sub-second response times with natural prosody make the conversation feel human. This is the future of voice interfaces.
Multimodal AI enables new interaction paradigms — Being able to send a camera feed alongside voice and have the AI naturally reference visual context opens up applications we hadn't considered. The hidden gems feature emerged directly from realizing "the agent can see."
Cloud-to-cloud networking is unpredictable — Never assume two cloud providers can talk to each other. Always test connectivity before building on assumptions about network reachability.
Personality prompting is an art — Small changes in system prompts dramatically shift the guide's character. Getting four personalities that are distinct yet consistently helpful required dozens of iterations. The key insight: define what each character would never say, not just what they would say.
Gamification drives exploration — Early testers who used the hidden gems feature spent 2-3x longer at each stop compared to those who just listened to narrations. Giving people a reason to look closer transforms passive sightseeing into active discovery.
What's next for Roam: AI Tour Guide
More cities, more tours — Expanding beyond Mumbai to cities worldwide. The architecture is tour-agnostic — we just need stop coordinates, descriptions, and hidden gems. Dharavi Art Walk, Mumbai Street Eats, and Marine Drive Sunset tours are already defined and ready to launch.
AR landmark overlays — Using the camera feed we already have to overlay historical reconstructions on landmarks. Imagine seeing the Gateway of India during its 1924 inauguration through your phone screen.
Community-created tours — Opening a tour builder so locals can create and share walking tours for their neighborhoods. The AI agent adapts to any set of stops and descriptions.
Offline mode — Pre-downloading narrations and map data so tours work without connectivity. The live voice guide would remain online-only, but the core tour experience would work anywhere.
Group tours — Shared rooms where friends, families, or school groups explore together with the same AI guide addressing everyone. LiveKit's multi-participant architecture already supports this.
Monetization — Premium guide voices (celebrity narrators, local historians), paid tour content from cultural institutions, and partnerships with nearby restaurants and shops mentioned during tours.
Accessibility — Haptic navigation for visually impaired users, sign language integration via camera, and simplified UI modes for elderly tourists.



Log in or sign up for Devpost to join the conversation.