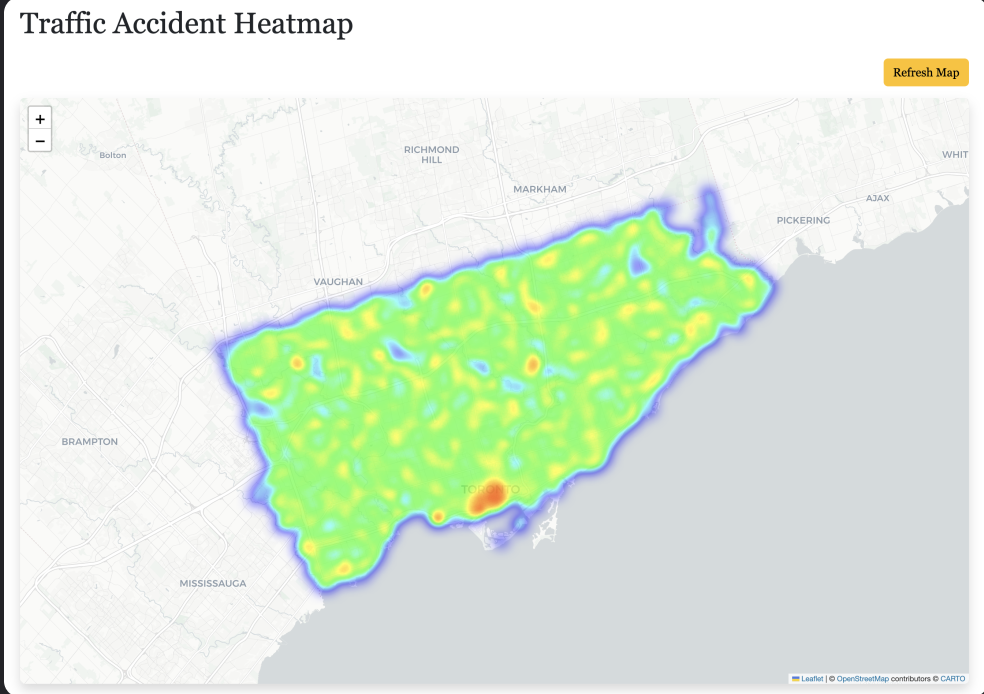
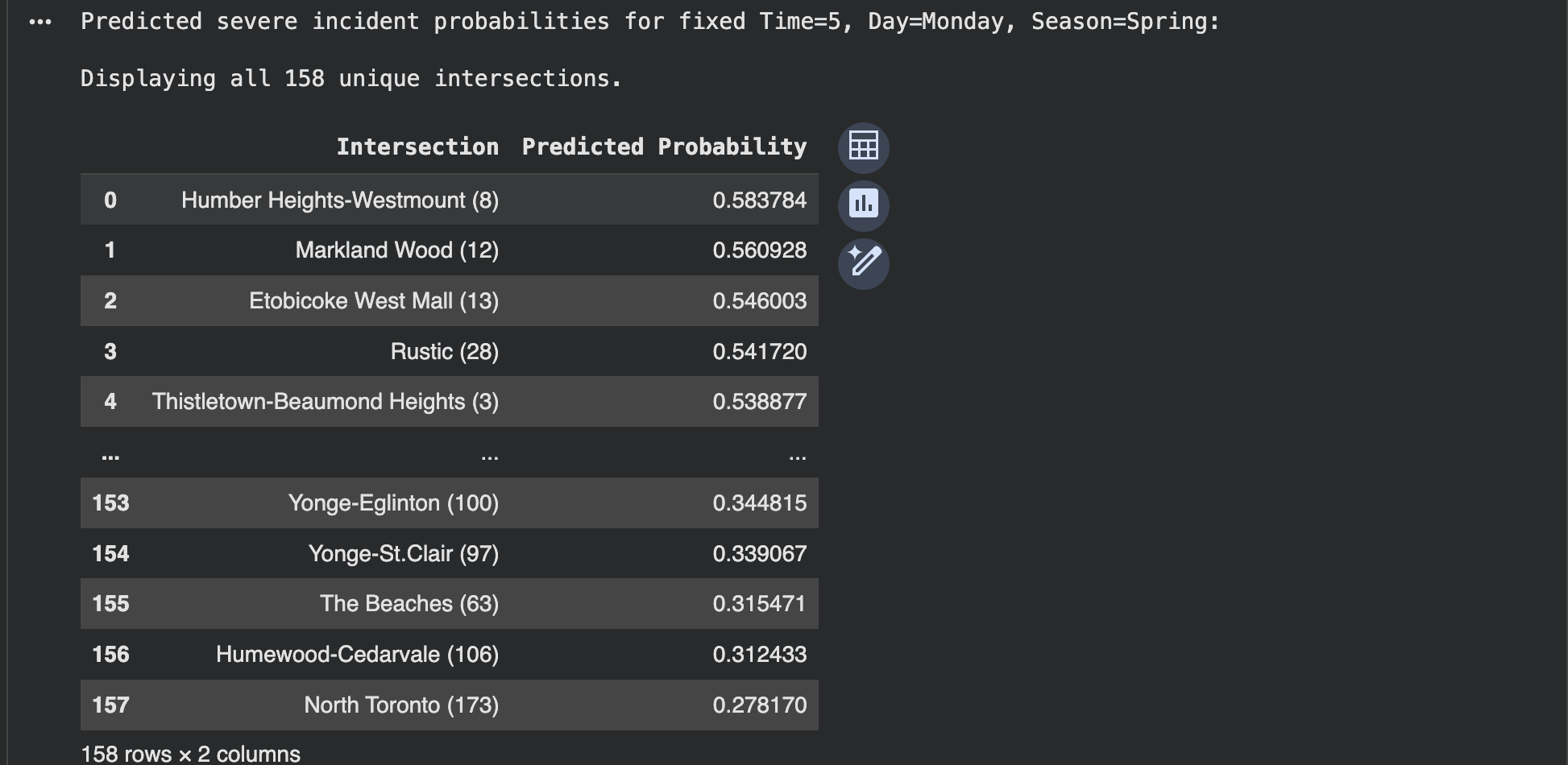
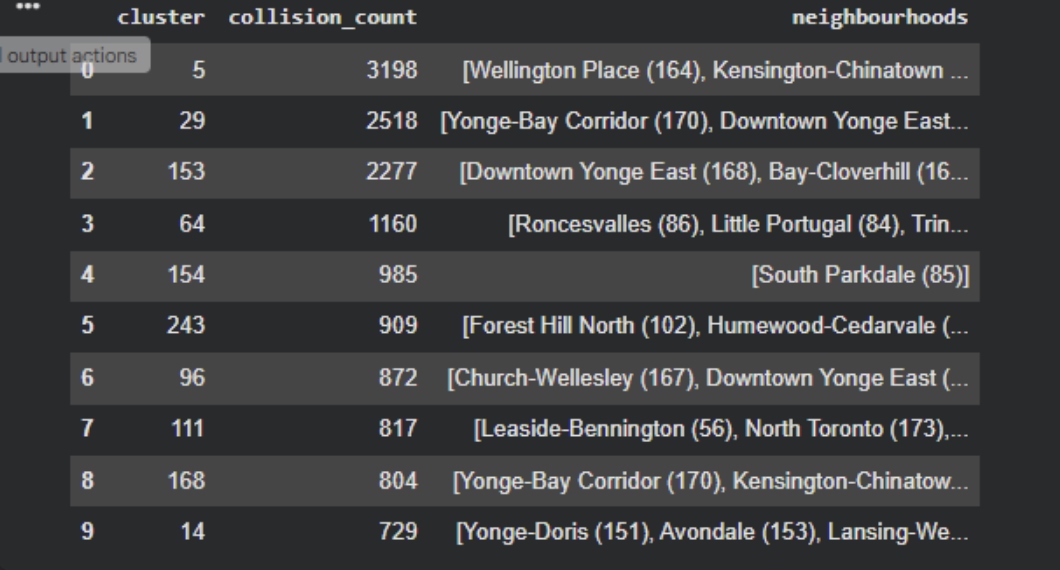
This project uses three machine learning models to enhance urban safety by predicting accident hotspots, incident probabilities, and pedestrian vulnerability in Toronto. The first model, DBSCAN Spatial Clustering, applies a density-based clustering algorithm to 2023 collision data, identifying natural high-risk zones without predefined boundaries. It classifies these hotspots by severity and provides valuable data for infrastructure improvements, enforcement zones, and policy planning. The second model, Incident Occurrence Probability, predicts the likelihood of a collision based on temporal features such as the hour, day, and month. By training models like Logistic Regression and Random Forest, it generates probability scores to identify high-risk times and locations for better traffic management and safety measures.
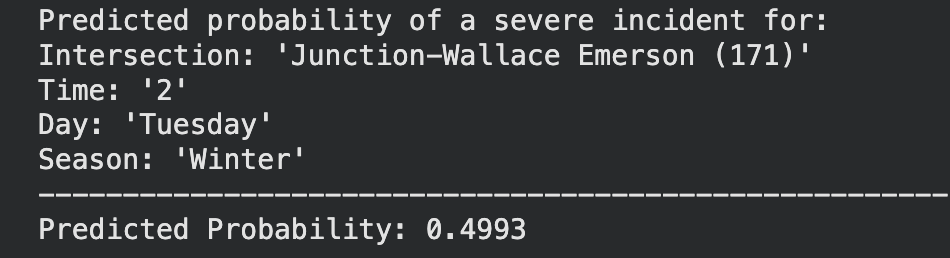
The third model, Pedestrian Vulnerability Risk, offers real-time location-based risk predictions for pedestrians and cyclists by using historical collision data to assess safety at any given coordinate. A Random Forest Classifier is used to classify risk levels and create an interactive heatmap, highlighting the nearest hotspots and their severity. This model enables urban planners, policymakers, and citizens to better understand and navigate areas of risk. Together, these models provide a comprehensive, data-driven safety system that identifies where, when, and how accidents occur, enabling targeted interventions for improving pedestrian and traffic safety in Toronto.
Built With
- angular.js
- folium
- html5
- matplotlib
- pandas
- python
- seaborn
- sklearn







Log in or sign up for Devpost to join the conversation.