-
-

Home page
-
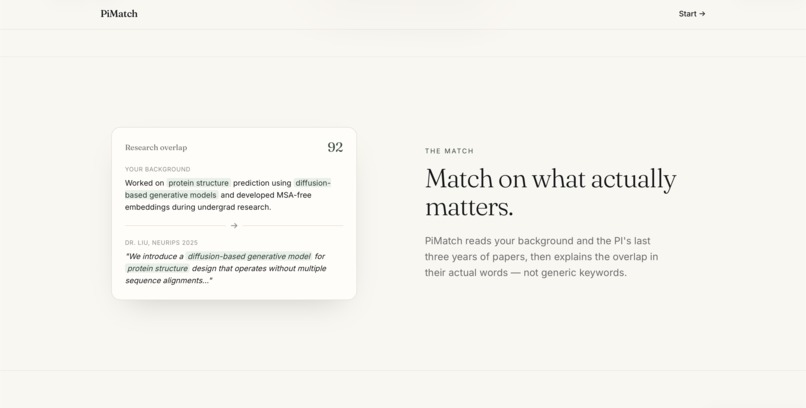
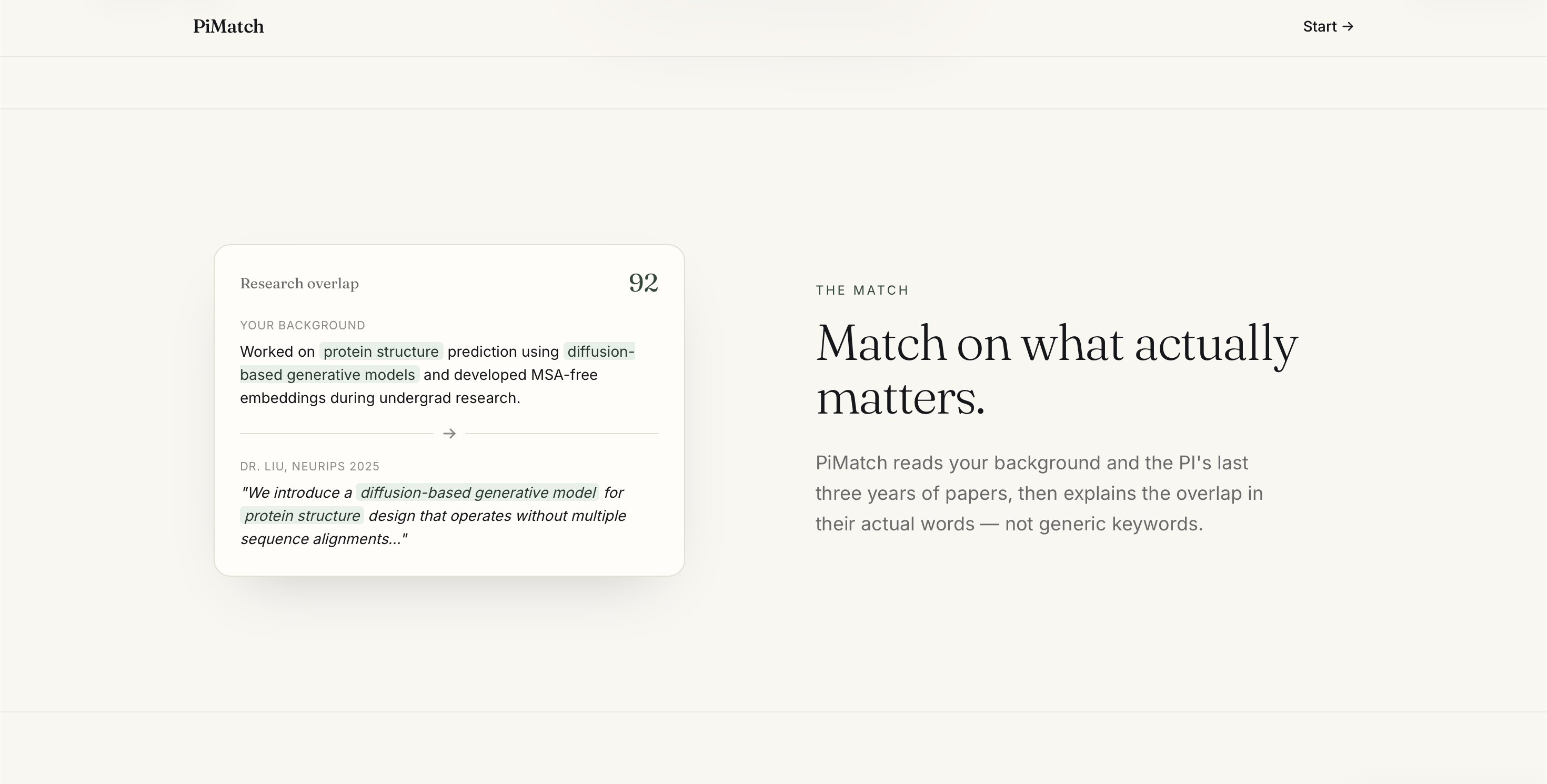
The Match Feature
-

The Conversation Feature
-
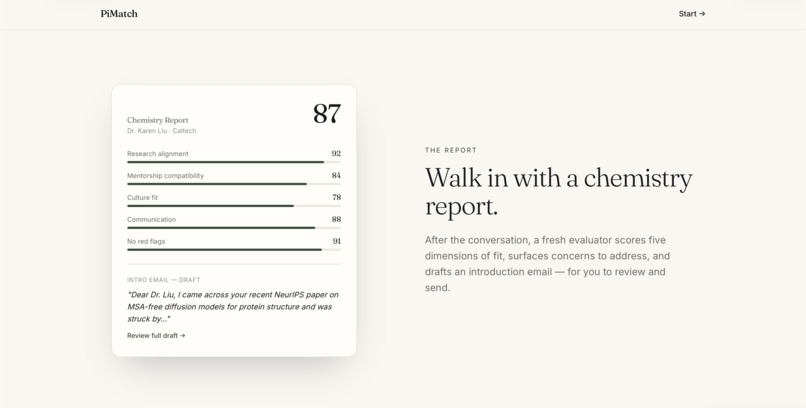
The Report Feature
-
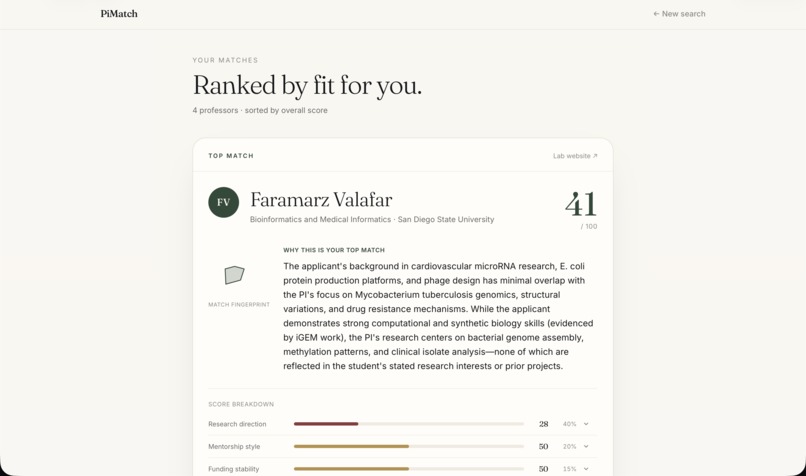
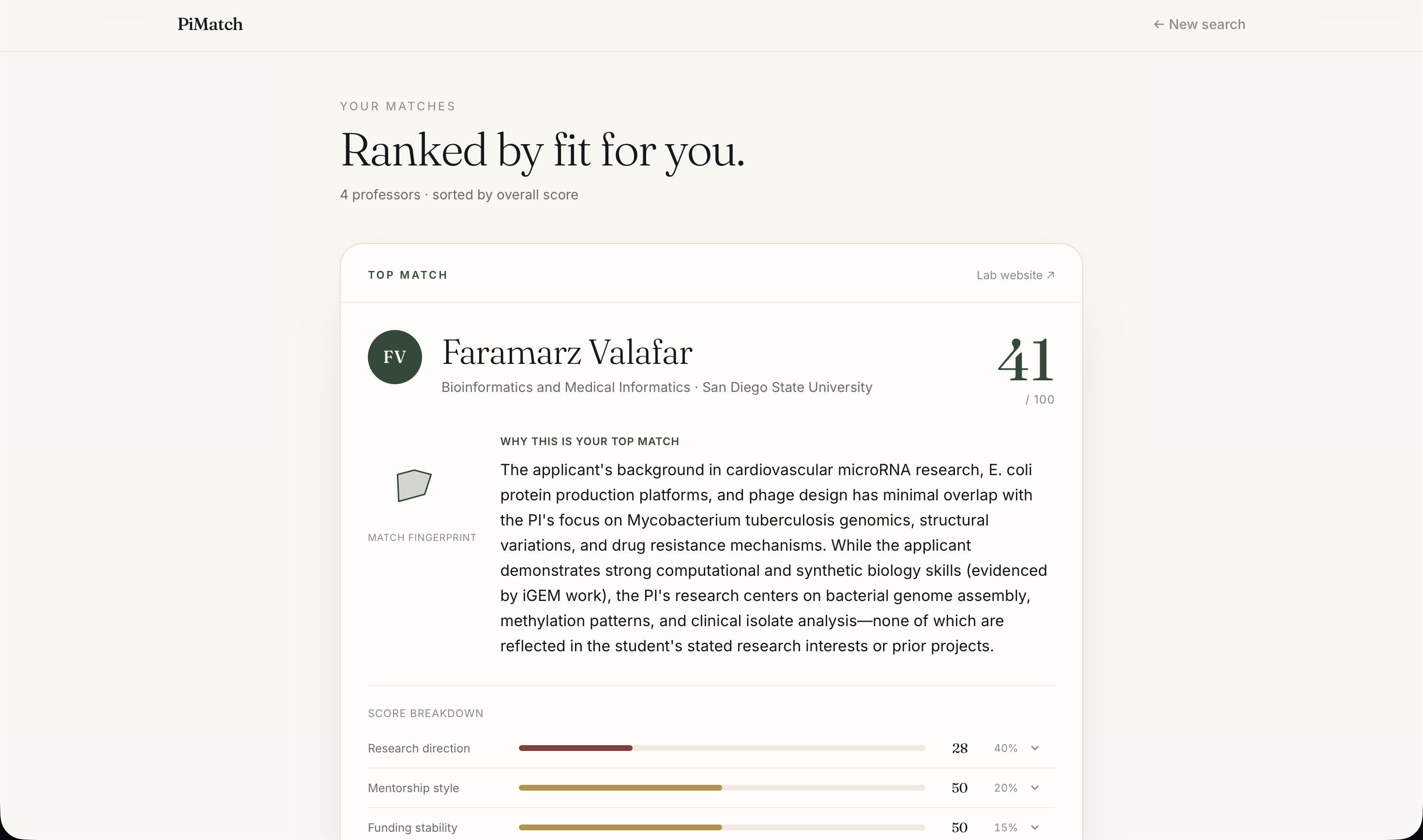
Match - Top Pick
-
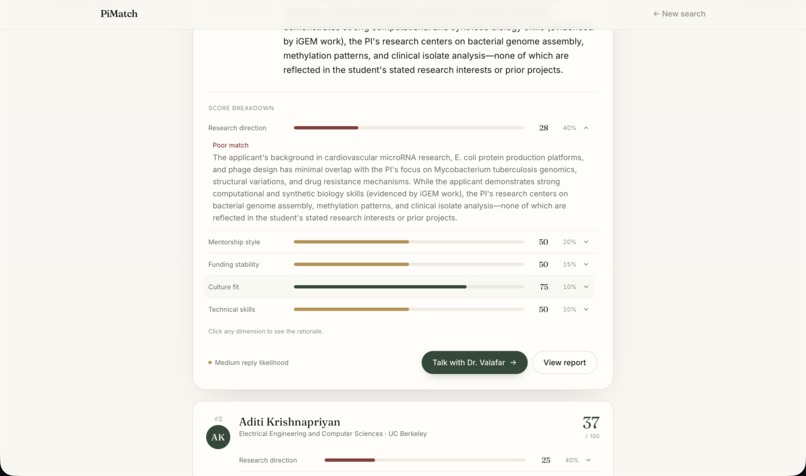
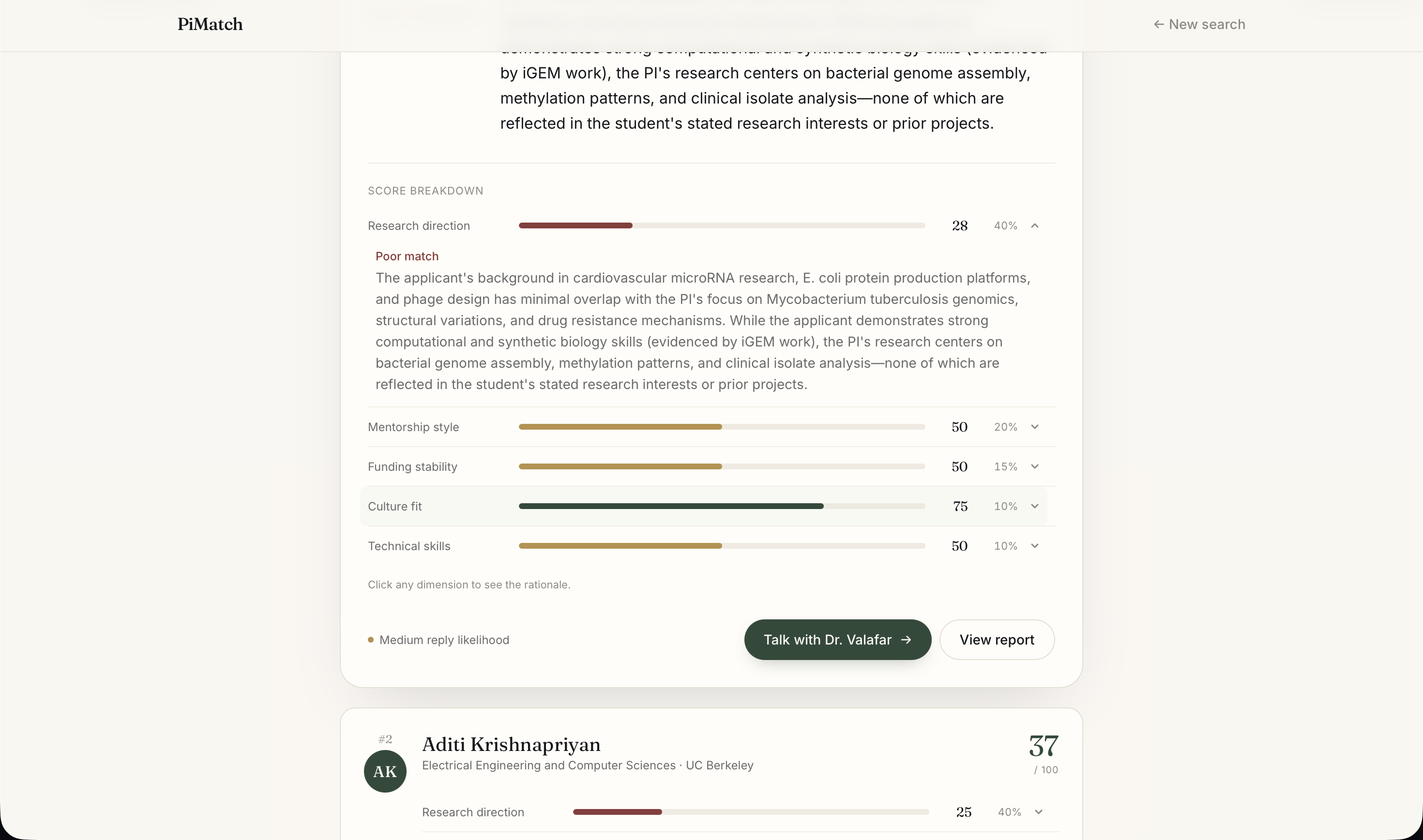
Match - Details
-
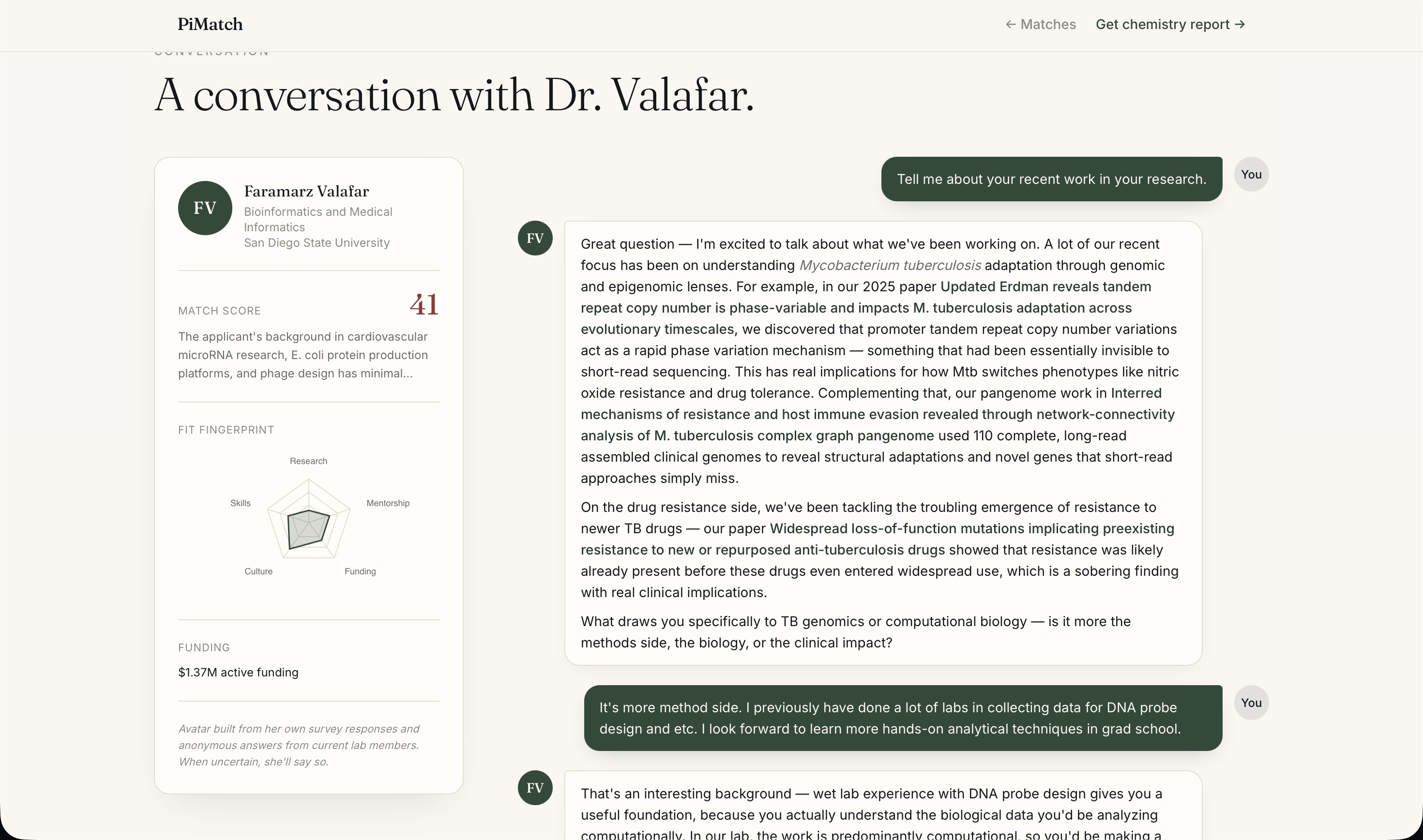
Conversation
-
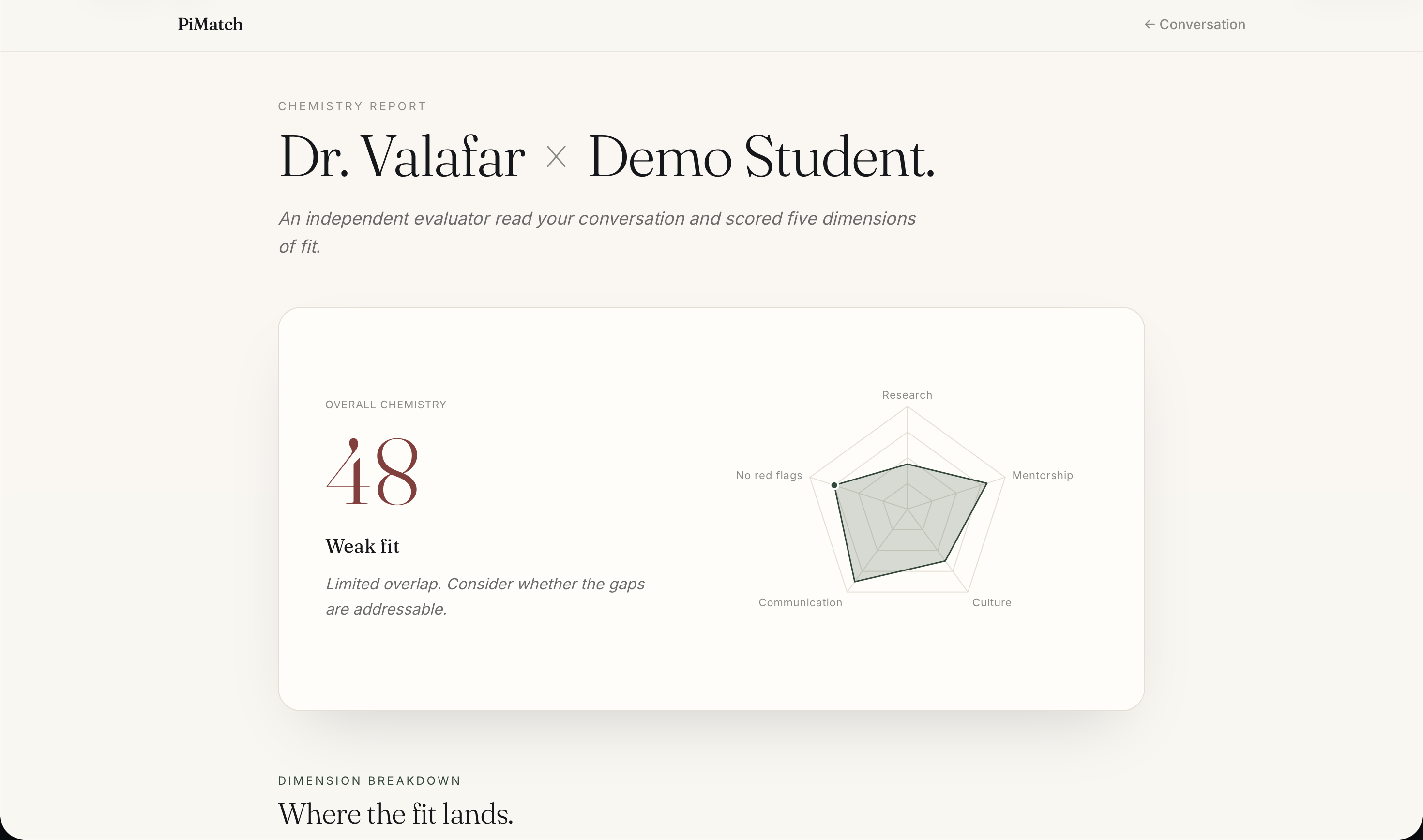
Report - Fitness
-
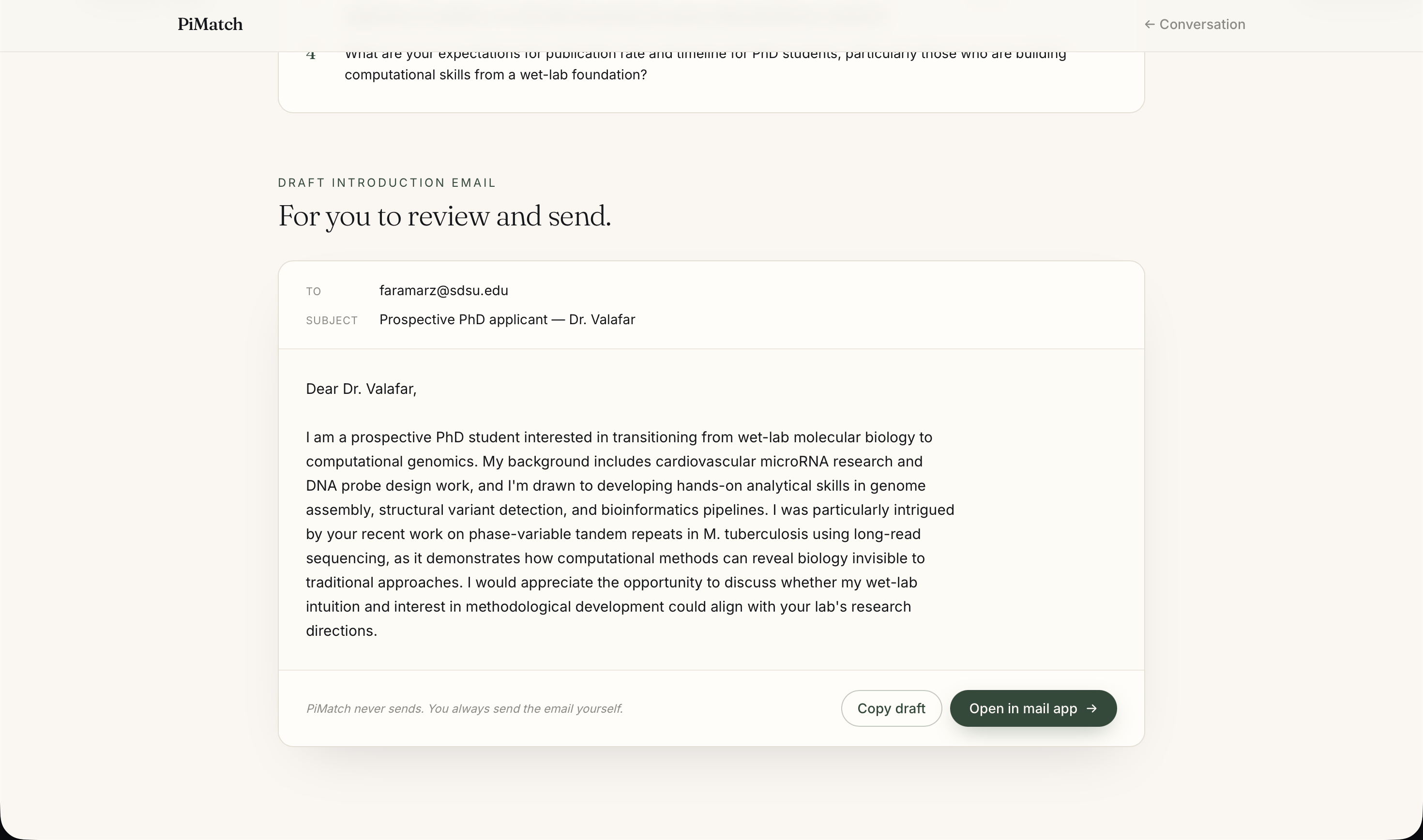
Report - Out Reach
-
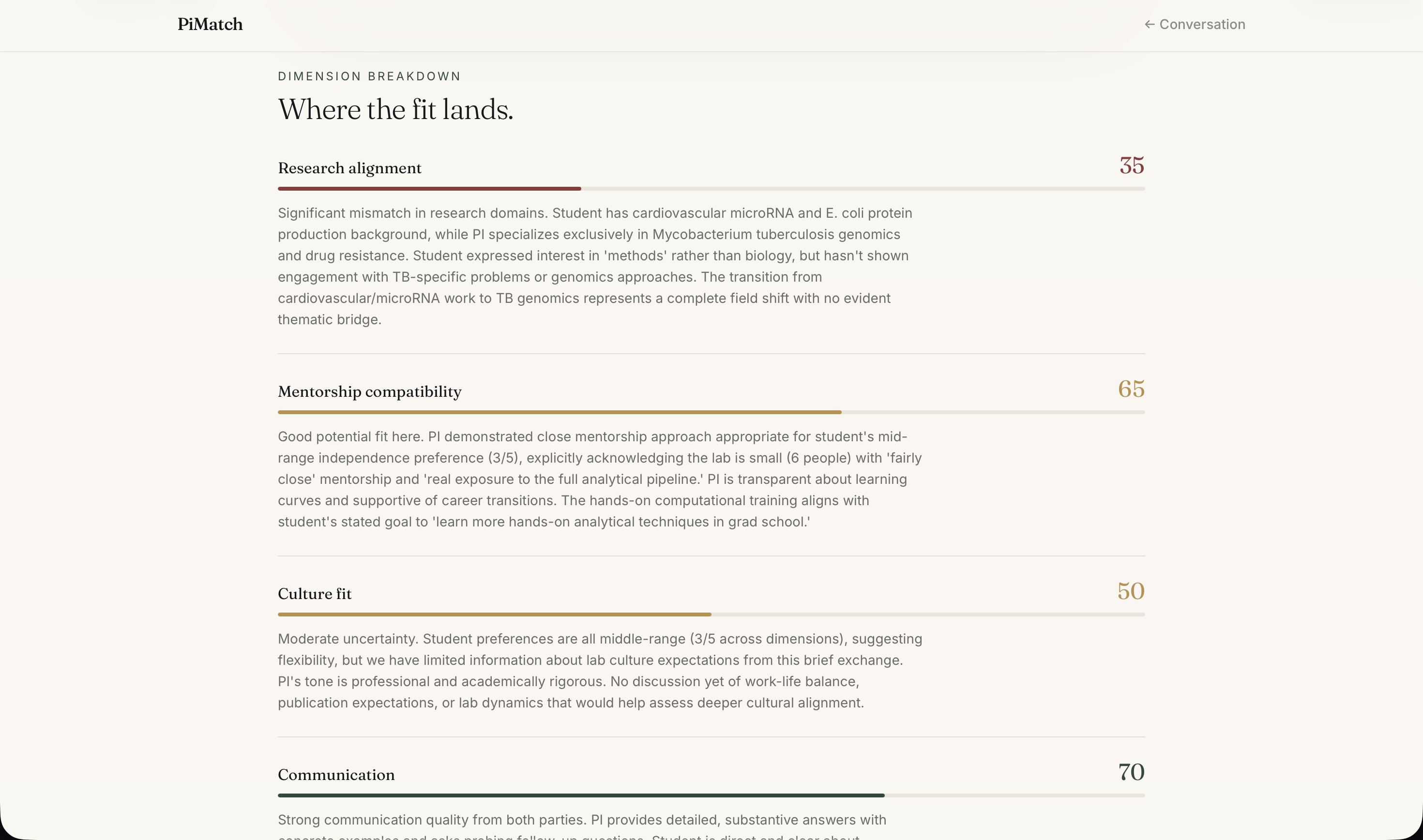
Report - Reasoning



What Inspired Us
All four of us are planning to pursue a PhD after graduating from college. We're not designing for a hypothetical user — we're designing for ourselves, and for the version of this decision that's coming for each of us. We all want to find an advisor who's truly a match — someone whose research, mentorship style, and lab culture fit who we are. This decision shapes the next five to seven years of our lives, and a lot of what comes after.
The more we talked through it, the more we realized how broken the current process is. Every year, more than 50,000 students in the U.S. start a PhD. Five to seven years later, 30–50% of them never finish. Ask why, and the same answer comes back: I picked the wrong advisor.
This is one of the largest, most consequential matching markets in the world. And it runs on cold emails, secondhand gossip, and a 30-minute lab visit. Compare that to how much engineering effort goes into matching you with a Spotify playlist, a Tinder date, or a Lyft driver. The asymmetry is absurd.
So we asked: what would it look like if PhD admissions had real infrastructure? Eleven dimensions of compatibility. Coauthor networks mapped automatically. Funding constraints surfaced before, not after, the application. Research alignment scored against actual papers, not job titles. That's PiMatch.
What it does
Choosing a PhD advisor is one of the most consequential decisions a researcher will ever make — and the process is almost entirely broken. Students send cold emails into the void, attend brief conference meetings, and rely on word-of-mouth from a handful of people who happened to work in similar labs. The fit between student and advisor determines not just career outcomes but mental health, time-to-degree, and whether someone stays in research at all.
PiMatch fixes this. Students fill out a structured profile — research background, mentorship style preferences, citizenship status, location, and independence level — and PiMatch ranks matching faculty across five weighted dimensions: research direction (40%), mentorship style (20%), funding stability (15%), technical skills (10%), and culture fit (10%). It detects direct connections ("you know this professor") and indirect ones ("your advisor co-authored with them"), surfaces citizenship-restricted funding flags, and predicts reply likelihood so students can prioritize their outreach.
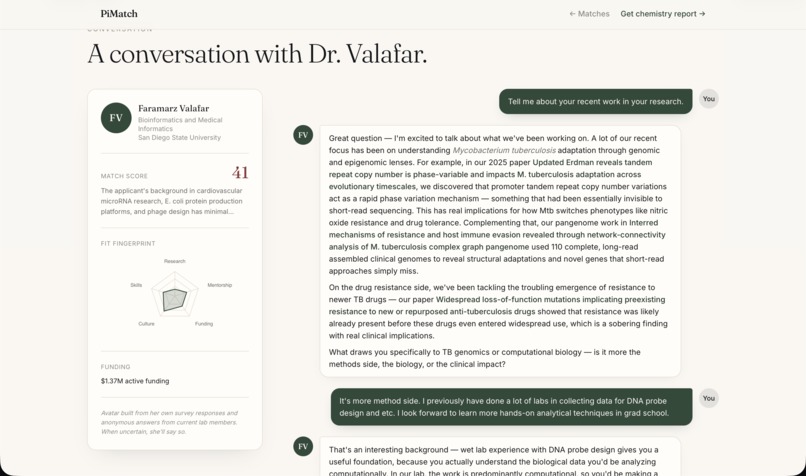
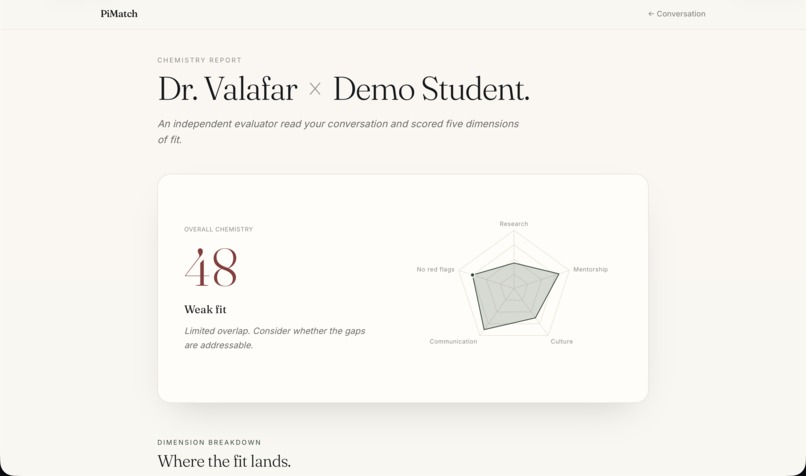
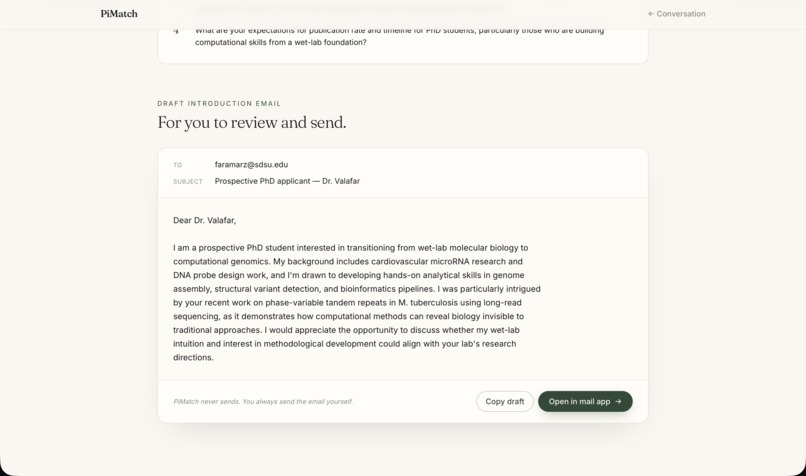
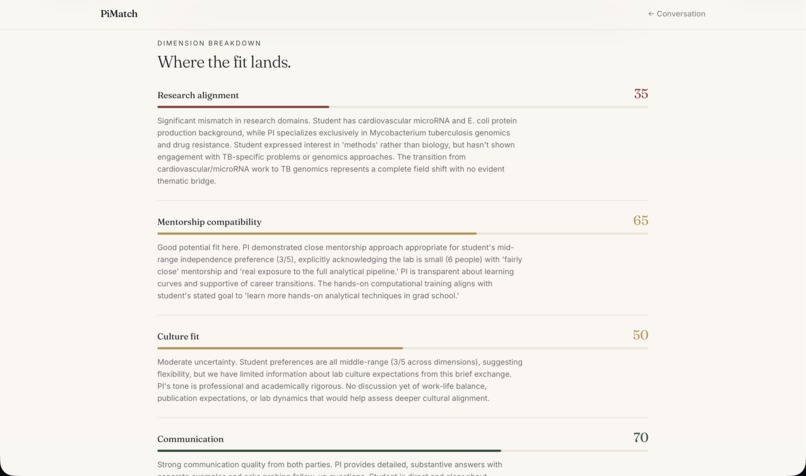
Then it goes further. Students can have a live conversation with an AI avatar of any matched professor — built from the professor's own survey responses, their students' anonymous feedback, and their actual published papers with real DOI links. The avatar asks one question per turn, draws only from verified information, and never fabricates. After the conversation, a Chemistry Report evaluates fit across five dimensions, surfaces key positives and concerns from the transcript, and drafts a personalized introduction email the student can review and send.
The result: a student who came in knowing nothing about a lab can leave with a ranked list of genuine matches, a real conversation on record, and a ready-to-send email — in under ten minutes.
How we built it
The backend is Python + FastAPI with SQLite via SQLModel. Every matching dimension except research fit is computed deterministically from structured data — funding from NSF APIs, mentorship from professor survey responses mapped to 1–5 numeric scales, co-authorship graphs from Semantic Scholar. Research fit is the exception: it uses Claude claude-sonnet-4-5 to semantically compare the student's background against the PI's recent paper abstracts, with a prompt that explicitly requires citing specific paper topics rather than generating generic phrases.
The professor data pipeline has two tracks. Track A is a curated seed of five Caltech PIs with hand-verified abstracts, NSF grants, and lab data. Track B — which is what makes this demo real — ingests actual Google Forms survey responses from professors and their current students. A normalization pipeline (dedup_seeds.py) merges variant name entries — handling lab-name suffixes, trailing whitespace, and OCR-style character substitutions — drops unknown rows, and ensures idempotent seeding. Student feedback is parsed separately and mapped into anonymous student_survey_responses that feed the avatar without ever being exposed via any public API endpoint.
The avatar system prompt is assembled from three sources depending on data availability: PI survey responses in first-person voice, anonymous current-student perspectives thematically aggregated, and public research data. A profile_builder.py validation layer assigns each professor a pipeline type — PI_and_student, PI_only, or public_only — and the avatar prompt adjusts accordingly, falling back to honest uncertainty rather than fabrication.
The frontend is React + Vite + TypeScript with Tailwind CSS, deployed to Vercel. The backend runs on Render with SQLite. The match page features an expandable score accordion with rationale text rendered as markdown. The chat page renders PI responses with clickable paper DOI links. The report page shows a Recharts radar chart, key positives and concerns extracted from the transcript, recommended follow-up questions, and a copyable introduction email draft.
Challenges we ran into
Survey data is messier than expected. Real Google Forms exports contain Unicode line separator characters (U+2028) embedded in column headers, curly apostrophes (U+2019) in place of straight ones, and professor names entered inconsistently across PI and student forms (first-name-only vs. full-name, lab-suffix variants, even OCR-style typos like a lowercase L substituted for a capital I). We built a normalization layer that handles character-level encoding, name canonicalization, and cross-form identity matching — but it took longer than any of us expected.
Getting Claude to stay in character. Early avatars hallucinated institutions, invented paper titles, and occasionally forgot which university they were at. We solved this with explicit identity grounding at the top of every system prompt ("You are NOT at any other university. This is non-negotiable."), a curated paper list with the instruction to only cite from it, and a rule that uncertainty must be voiced rather than papered over. The difference in output quality between the first and final prompts was dramatic.
The validator was too strict. Our profile_builder.py validator checked every key in the pi_survey dict for non-empty values — including optional extended fields that are legitimately blank. This silently downgraded professors with real survey data to PUBLIC_ONLY pipeline, stripping out their mentorship voice entirely. The bug was invisible because the research data still loaded; only the survey sections were missing. We caught it by inspecting the rendered system prompt directly.
Two databases. Running the backend from backend/ means ./pimatch.db resolves to backend/pimatch.db, not the root. Several of our update scripts targeted the wrong file before we caught the discrepancy — a reminder that SQLite's zero-configuration simplicity has a sharp edge when the working directory changes.
Accomplishments that we're proud of
We are most proud of the fact that the professors in our demo are real, and their avatars are built from what they actually said.
One of our seed professors — a real PI at a Claremont-area institution — filled out our survey and gave us permission to build a simulated lab profile. Three of their current PhD students filled out a separate feedback form describing what it is actually like to work in their lab: the demands, the mentorship style in practice, what they wish they had known before joining. That real, human signal flows directly into the avatar. When a student asks "what is your lab actually like?", the response draws on the PI's own words and on what their students reported — anonymized but genuine.
We also built the full pipeline cleanly enough that adding a new professor is now a matter of having them fill out a form. The deduplication, normalization, validation, and avatar assembly are all automatic. The hard infrastructure work is done.
On the technical side: the three-tier evaluation — data match → avatar conversation → chemistry report — gives students something no cold email or coffee chat can: a structured record of an actual exchange, with AI-extracted positives and concerns and a ready-to-personalize introduction email. That arc, from blank intake form to "here is the email you should send," was the original vision and it works end to end.
What we learned
The unsexy insight is that data quality dominates everything. We spent far more time cleaning, normalizing, and validating survey data than we spent on matching algorithms or UI. A sophisticated Claude prompt does nothing useful if the professor's mentorship style is silently missing from the avatar context because a validation rule fired incorrectly. The unsexy infrastructure is the product.
We also learned that "simulate humanity" is harder than it sounds for a very specific reason: real people have opinions they haven't written down. A professor's survey tells you what they think they value. Their students' feedback tells you what it is actually like. Those two things are not always the same, and the most interesting part of the avatar is when it has to hold both. Designing prompts that honor that tension — rather than flattening it into a marketing pitch — took real iteration.
Finally: the PhD advising problem is genuinely underserved. Every student we talked to had a story about a match that went wrong because they didn't have good information. The demand is there. The data is acquirable. The AI tools are ready. What has been missing is someone willing to do the unglamorous work of actually collecting professor surveys and student feedback at scale — which turns out to be a distribution problem, not a technical one.
What's next for PiMatch
Scale the survey network. The platform is only as good as the professors who have filled out the survey. The immediate next step is partnering with graduate program coordinators and department administrators to distribute the PI survey at the department level, and with graduate student associations to distribute the student feedback form. Even 50 professors with real survey data would make PiMatch meaningfully useful to incoming PhD applicants.
Two-sided matching. Right now PiMatch is one-sided: students see ranked professors, but professors see nothing. The next version gives professors a dashboard showing which applicant profiles have matched with them, so they can proactively reach out to strong fits before application season. This flips the cold email dynamic entirely.
Richer research matching. The current research fit score is a single Claude call against recent abstracts. A stronger version would embed both student backgrounds and professor abstracts in a shared vector space, enable semantic search ("show me professors working on foundation models for genomics"), and incorporate citation network data to surface emerging research directions the professor hasn't published on yet but is moving toward.
Longitudinal outcomes. Once students enroll, we want to close the loop — did the match work out? Tracking outcomes would let us improve scoring weights empirically rather than relying on our current hand-tuned values, and would let us identify early warning signals for advising relationships that need intervention.
Institutional licensing. Graduate schools spend significant resources on admissions outreach and yield. A version of PiMatch licensed to universities — pre-loaded with every faculty member's profile, integrated with the application portal — could measurably improve both yield and student-advisor fit at scale. That is the commercial path.
Built With
- anthropic-api
- claude
- fastapi
- google-docs
- nsf-api
- python
- react
- recharts
- render
- semantic-scholar-api
- sqlite
- sqlmodel
- tailwindcss
- typescript
- vercel
- vite
 Chen")
 Chen")

Log in or sign up for Devpost to join the conversation.