
Inspiration
As a machine learning engineer and a PhD candidate in Reinforcement Learning I spend a lot of time evaluating the trained agent's behavior. While some of the information can be presented in TensorBoard in the form of Key Performance Indicators (KPIs), some insights can be gathered only by visualizing agent's behavior and observing it with a human eye. Typically, this kind of visualization is done using render() method of an OpenAI Gym-compatible environment, but this approach suffers from four major drawbacks:
- the trajectory is generated live, thus if you haven't specified a seed value, you won't be able to replay the same trajectory once again;
- by default, there is no control on the playback - you have to implement pausing on your own, but rewinding is completely out of the scope;
- the
render()method have access to the whole internal state of the environment. This might potentially lead to dangerous situations, where the scene is rendered using data that is not included in the observation; - the visualization of the observation only doesn't fully explain why the agent picked an action A, instead of an action B, at some time step T.
What it does
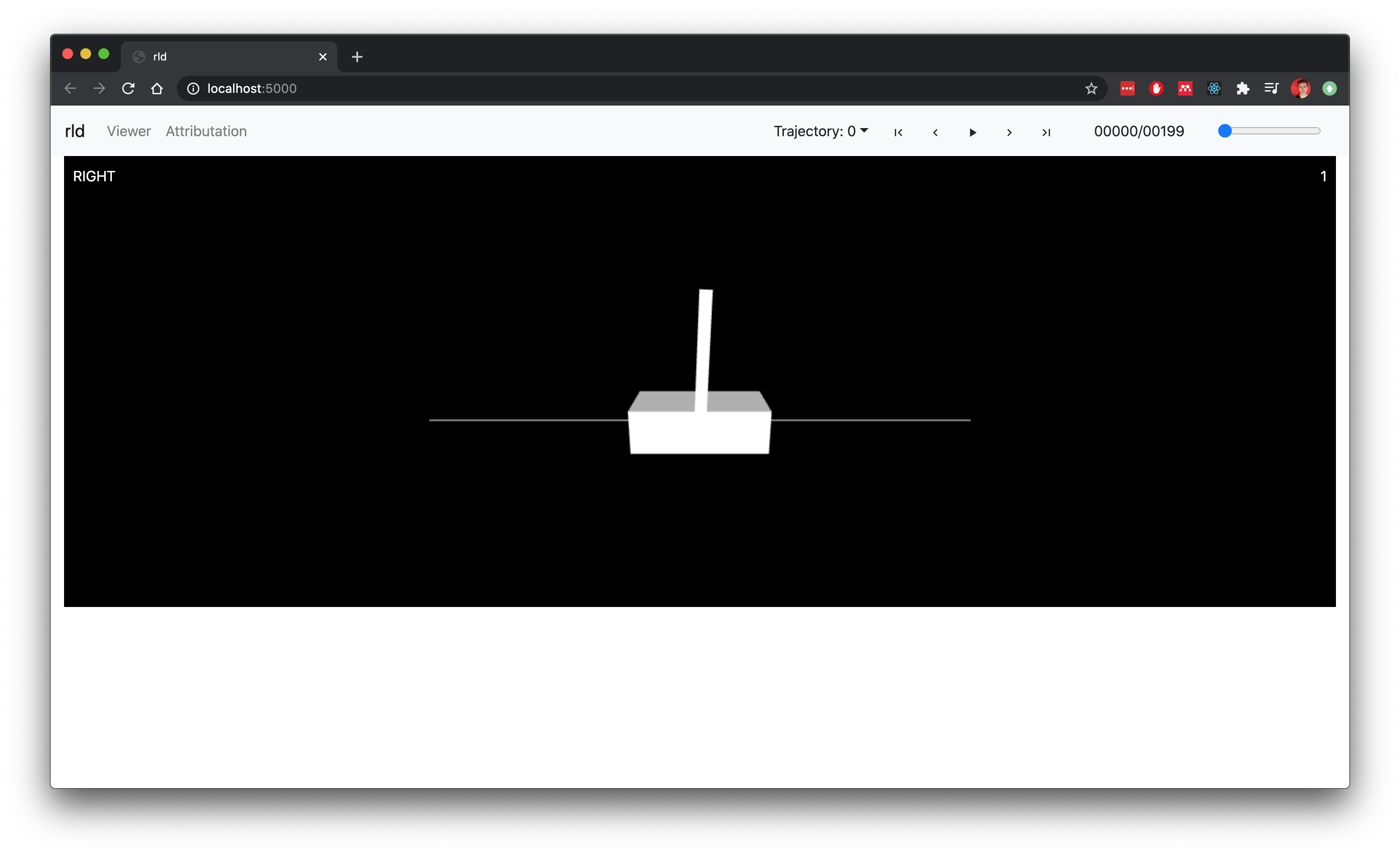
rld solves these drawbacks by using offline rollouts and providing a fully-controllable external viewer, which uses only the observation data to render the scene.
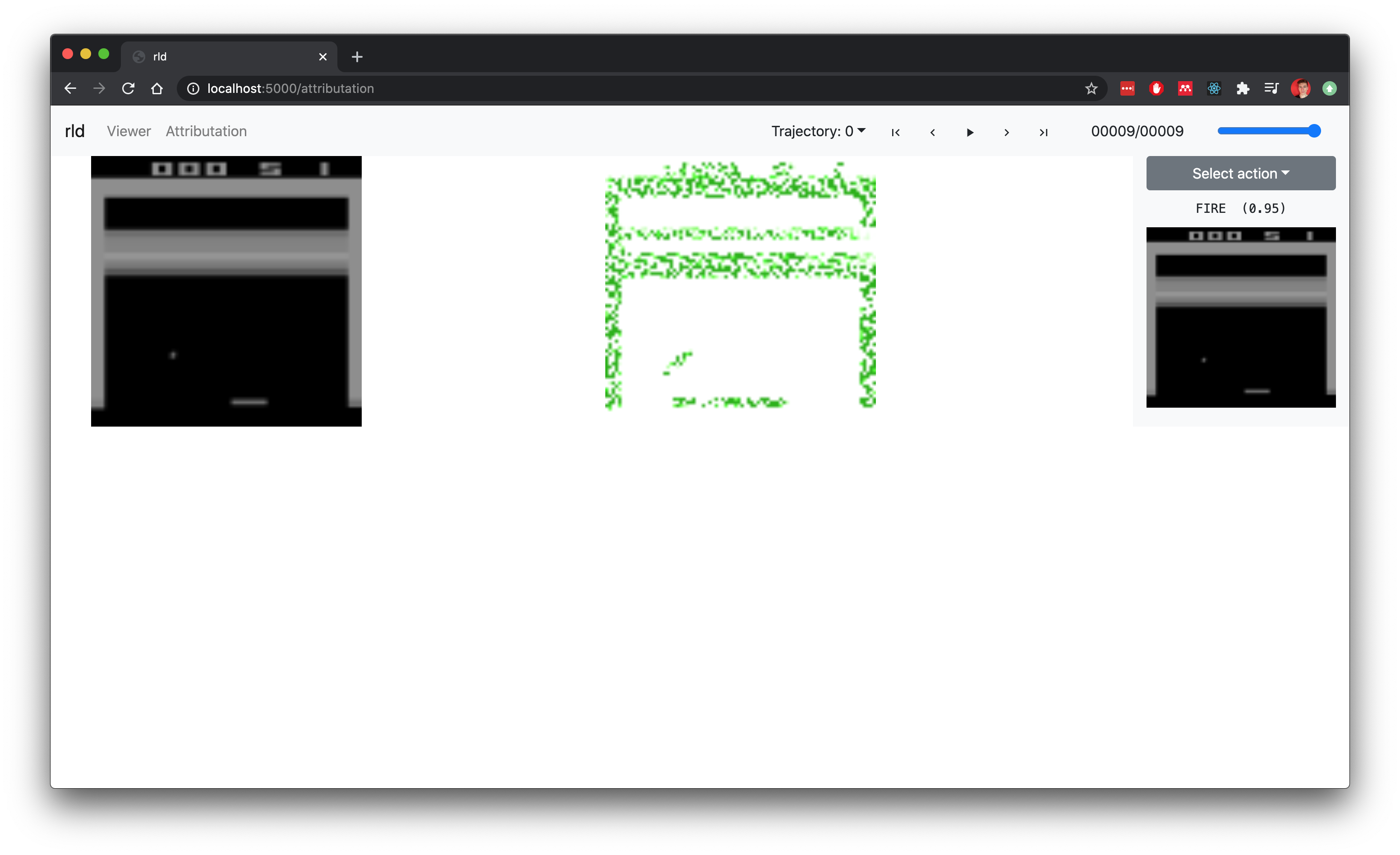
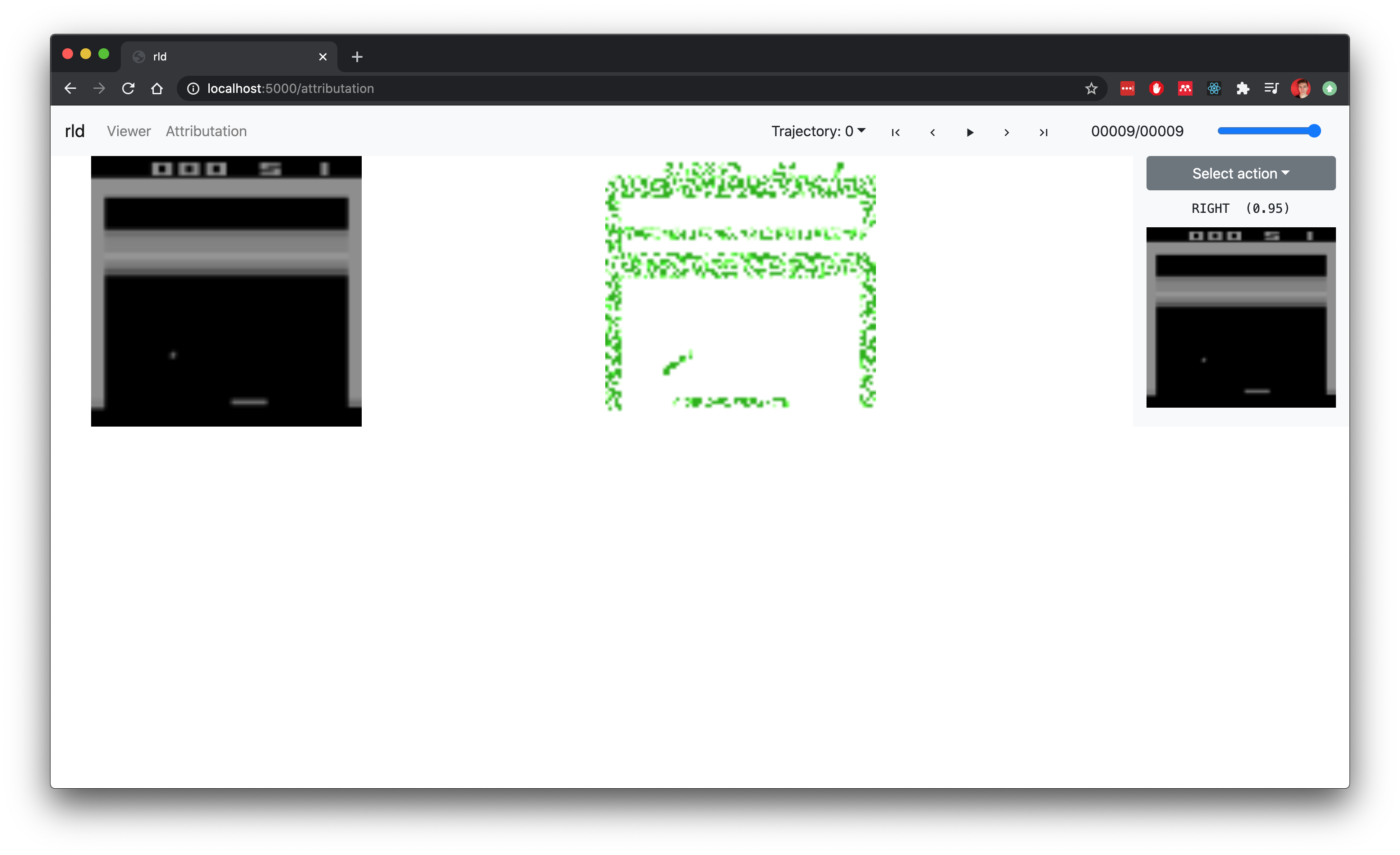
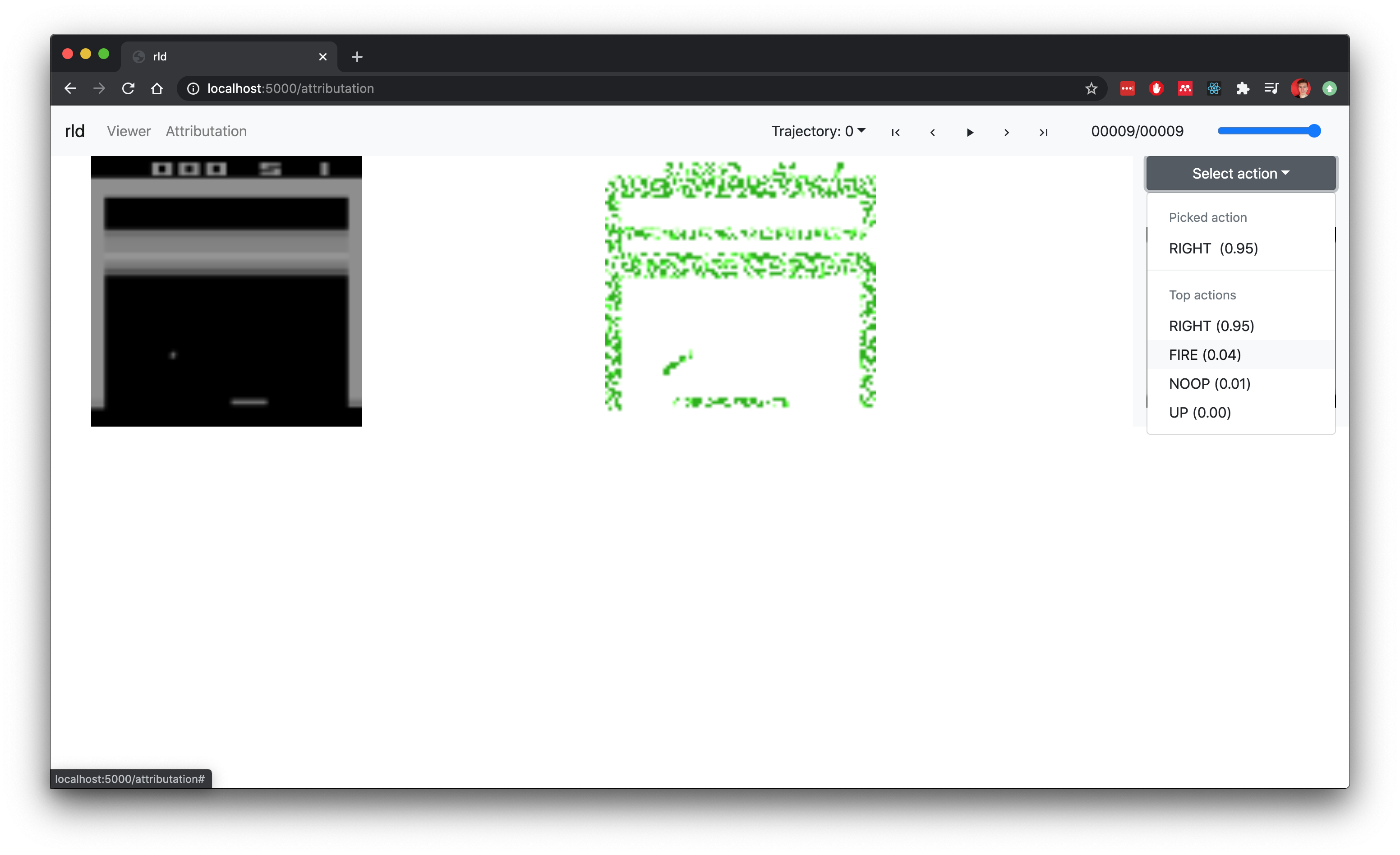
rld also allows to calculate and visualize observation attributations with respect to a picked or any given action.
How I built it
Captum and PyTorch are used to calculate attributations of the observation with respect to the given actions. Flask is used to serve static files and provide simple API to query for the rollout and its trajectories. The front-end is written in React and one type of viewers (WebGLViewer) is using three.js for WebGL in the browser.
Challenges I ran into
Currently, Captum only accepts torch.Tensors as an input and allows for a single target definition. To use it in reinforcement learning field, I had to implement multiple wrappers, which encodes e.g. dict-like observation space into a single torch.Tensor or stacks multiple torch.Tensors to calculate attributations for the same observation, but for the multiple targets (e.g. with MultiDiscrete action space).
Additionally, when testing rld on Atari environments, it turned out that serializing large arrays to JSON format is not the most efficient solution. :)
Accomplishments that I'm proud of
Completed the hackathon!
What I learned
React.
What's next for rld
Enhancing compatibility by adding new viewers and improving API to use custom viewers, and extending functionality by adding more debugging tools (e.g. trajectory hotspots, observation surgery tool).

Log in or sign up for Devpost to join the conversation.