-
-
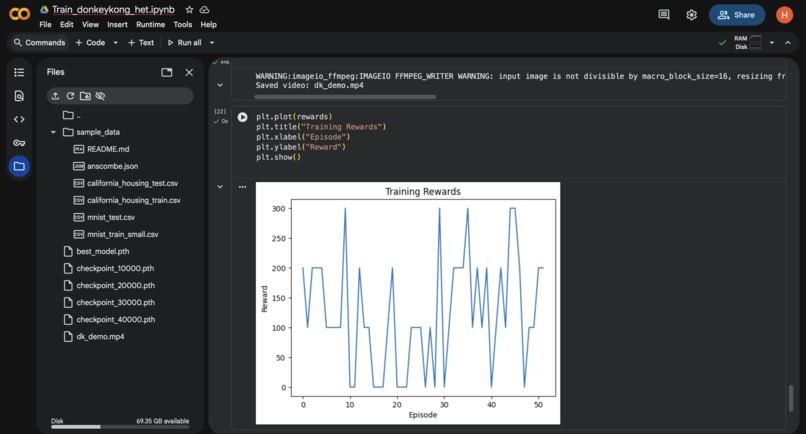
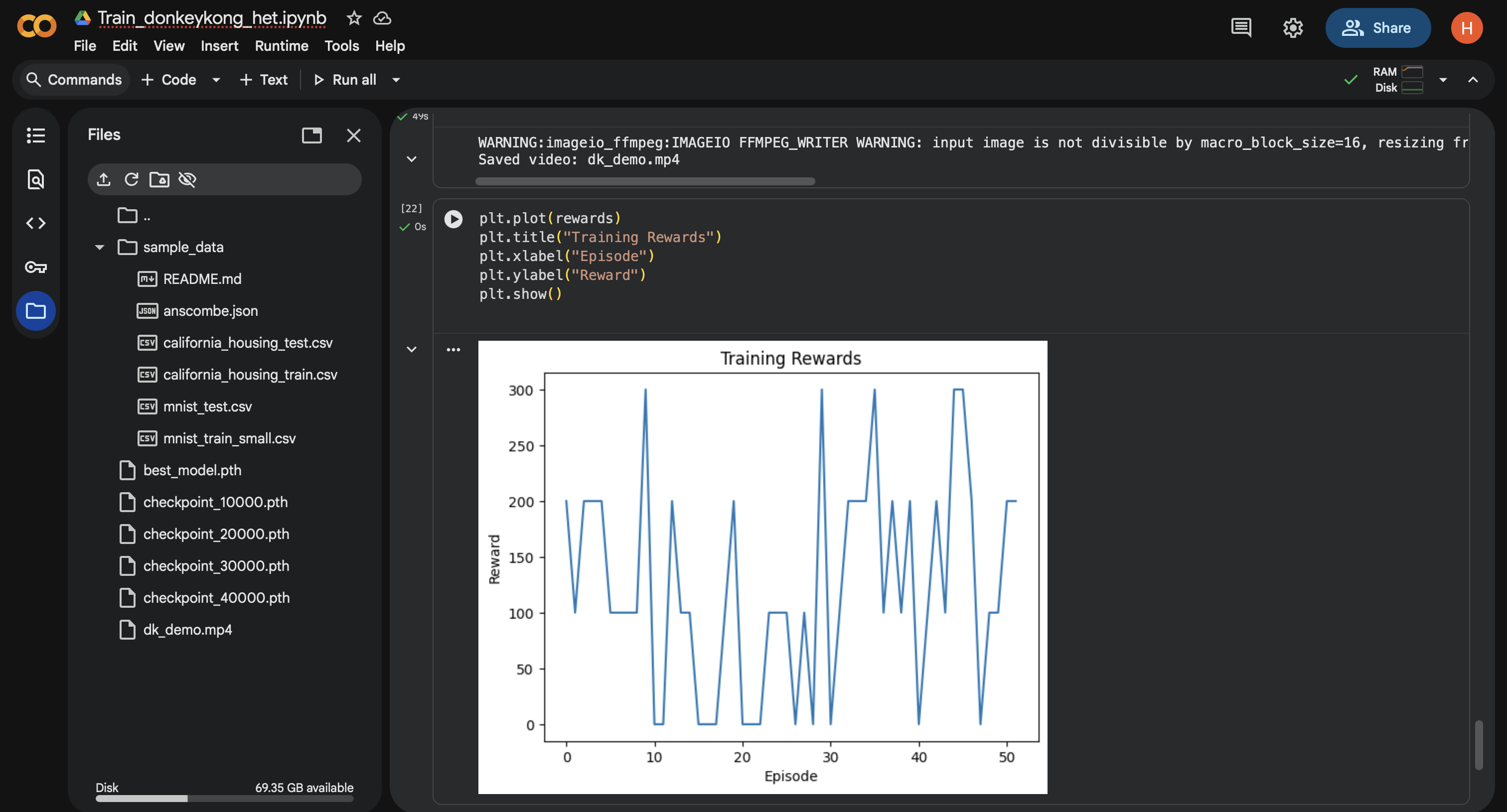
reward to episode graph
Inspiration
Classic arcade games like Donkey Kong are surprisingly difficult for reinforcement learning because they require long-term planning, precise jumps, and survival under sparse rewards. I wanted to see how far I could push a lightweight Rainbow DQN agent with a strict compute and time budget—and whether it could learn meaningful behavior from raw pixels in just 40,000 frames.
What it does
This project trains a reinforcement learning agent to play Atari Donkey Kong using only the visual game screen as input. The final agent: jump over barrels, survive longer on the first platform, and consistently achieves 200–300 reward, despite extremely sparse feedback and limited training time. An evaluation notebook loads the best model and produces a 30-second gameplay video showing the agent in action.
How I built it
I implemented a streamlined version of Rainbow DQN, combining: NoisyLinear layers for exploration A simple replay buffer A target network for stabilizing value estimation Atari preprocessing + 4-frame stacking Training was performed for 40,000 frames due to hardware/time constraints. We logged episodes, saved checkpoints, and exported the final best_model.pth for evaluation.
Challenges I ran into
Sparse rewards: Donkey Kong gives almost no points unless you jump over barrels or climb. Long horizon: To reach higher platforms, the agent must execute many correct actions in a row. Runtime constraints: With limited time, we couldn’t train to 200k–1M frames, where agents typically learn full level completion. Model mismatch: Ensuring the evaluation notebook used the exact same architecture as the training notebook was critical for loading weights properly.
Accomplishments that I am proud of
Successfully trained an agent from raw pixels only Achieved meaningful behavior (jumping, climbing, survival strategies) Reached stable reward scores of 200–300 in limited time Built a clean, reproducible evaluation notebook Generated a working 30-second demo video Gained hands-on experience with distributional RL and NoisyNets Accomplished everything under tight time constraints
What I learned
How powerful Rainbow components are—even simplified ones How crucial architecture matching is for model loading The difficulty of sparse-reward environments How exploration techniques like NoisyNets help in complex games Best practices for structuring RL projects (train vs eval notebooks)
Built With
- ai
- atari
- colab
- machine-learning
- openai
- python
- rainbow
- reinforcement-learning


Log in or sign up for Devpost to join the conversation.