-
-
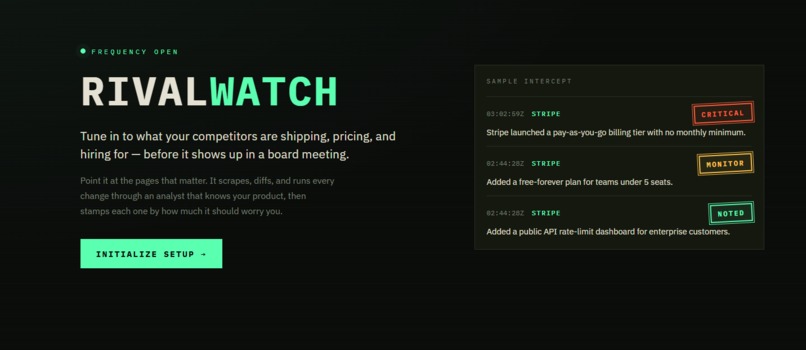
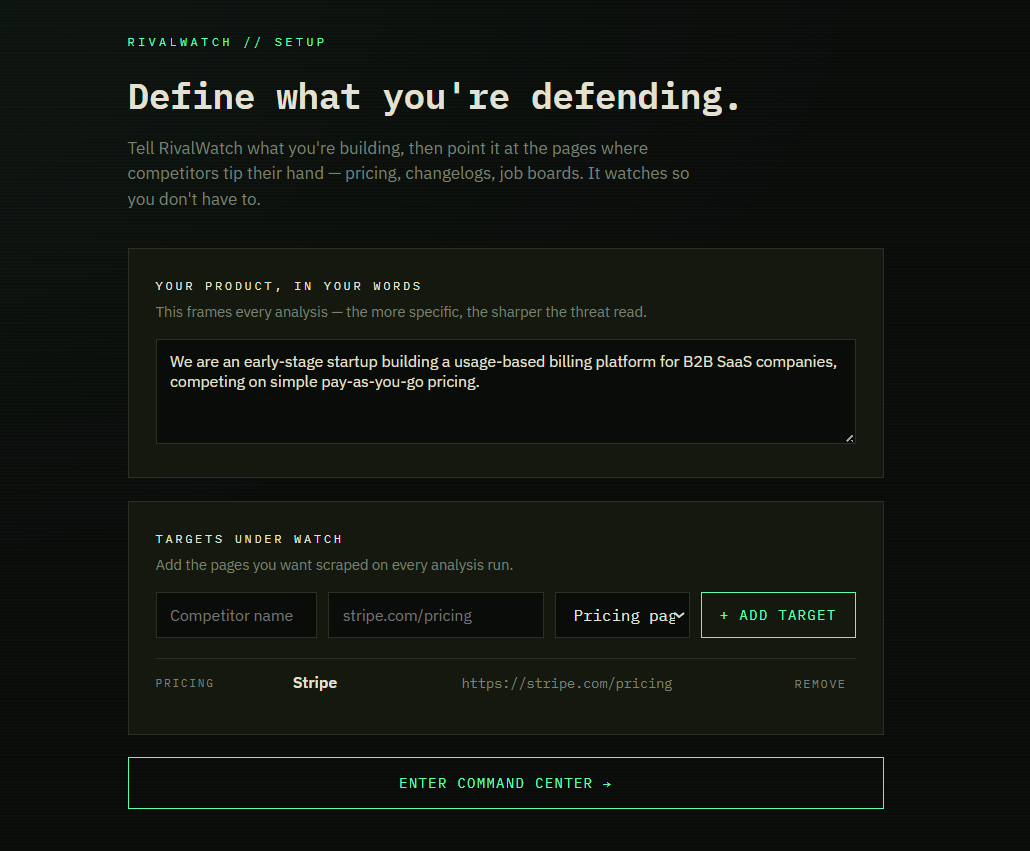
Landing page
-
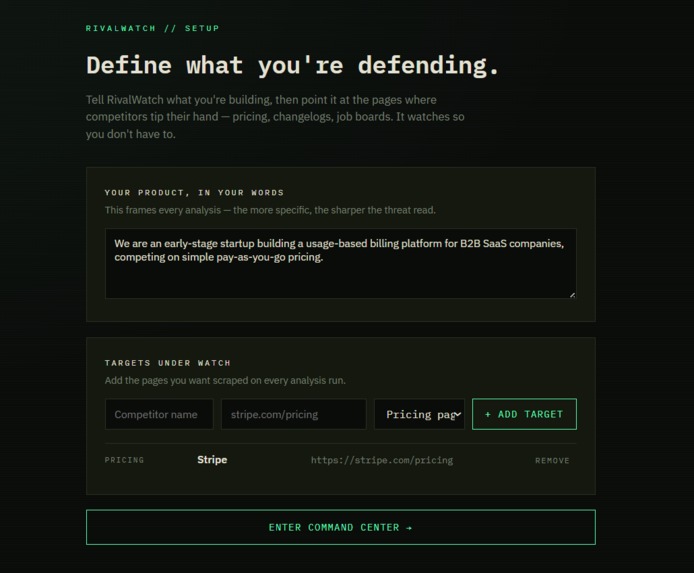
Setup
-
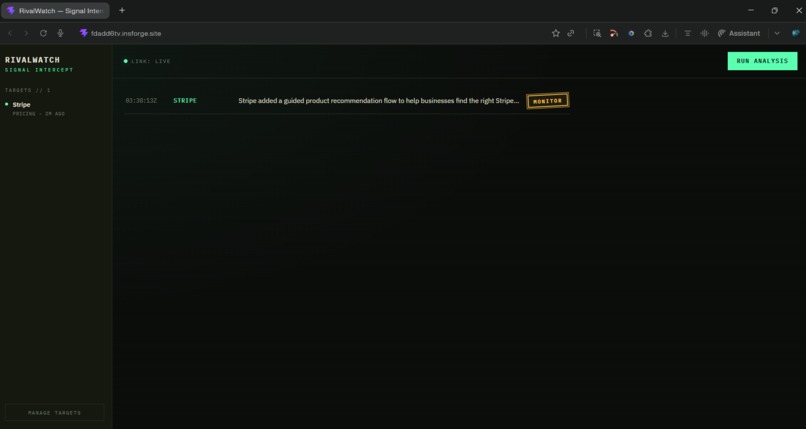
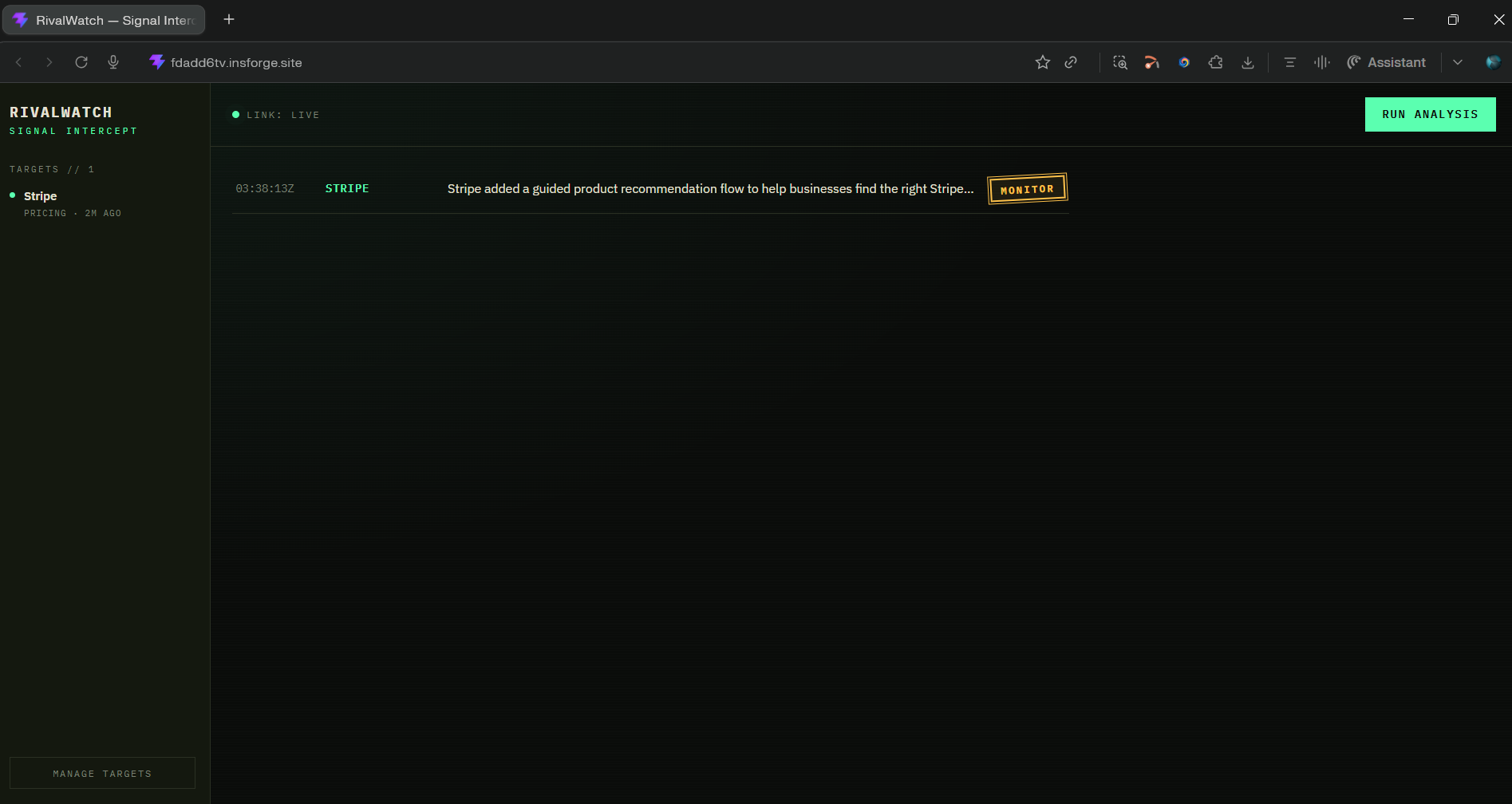
Command Center
Inspiration
Every early-stage founder has had the same gut-punch moment: you're deep in building a feature, feeling good about your roadmap, and then you find out a competitor shipped the exact same thing three weeks ago. You missed it because you were heads-down building. Competitive intelligence at early-stage startups is either nonexistent or it's a founder manually checking five tabs every Friday. There's no middle ground between "I'm too busy" and "hire a full-time analyst." We built RivalWatch to be that middle ground: an agent that never sleeps, never misses a changelog, and tells you exactly what to do about what it finds.
What it does
RivalWatch is an autonomous competitive intelligence agent for early-stage startup founders. You give it three things: your competitors' URLs, what type of page to watch (changelog, pricing, jobs), and a one-sentence description of your own product.
From there it runs entirely on its own. Every week, it scrapes your competitors' pages, diffs the content against the previous snapshot, and sends the delta to an AI analyst that reads the changes through the lens of your specific product positioning. Every detected change comes back classified as High, Medium, or Low threat, with a rationale and a concrete recommended action. The moment analysis finishes, a real-time digest pushes to your dashboard over a WebSocket connection. No refresh. No polling. The intel just arrives.
How we built it
RivalWatch is built entirely on InsForge, using every major service the platform offers.
Agent pipeline (Python): A three-stage autonomous pipeline, Scraper, Analyst, and Publisher, runs on a weekly cron schedule. The Scraper fetches competitor pages and extracts clean text using Trafilatura. The Differ compares the new snapshot against the previous one stored in InsForge Postgres. The Analyst Agent sends the diff to Claude via the InsForge Model Gateway with a structured prompt that scores each change against the user's product description and returns a typed JSON array of intel items. The Publisher writes the digest to InsForge Storage and fires a Realtime event.
InsForge infrastructure: Postgres stores competitors, snapshots, intel items, and digests. Storage holds the full weekly markdown digest. Edge Functions handle the HTTP-triggered pipeline entrypoint. The Realtime pub/sub channel pushes the completed digest to the frontend the instant analysis finishes. The Model Gateway routes all Claude calls through InsForge with no direct API key management needed.
Frontend (React + Vite): A dark, data-dense dashboard that subscribes to the InsForge Realtime channel on load. When the agent publishes a digest, a banner fires and the intel feed populates live, threat-ranked from High to Low, with full rationale and recommended response on each item. Deployed to InsForge Sites.
Challenges we ran into
Scraping reliability. Production websites have bot protection, inconsistent structure, and JavaScript-rendered content. Getting clean, diffable text out of a changelog page that looks totally different from a pricing page required building a robust extraction layer with Trafilatura and fallback strategies. The diff itself needed tuning: a naive line diff produces too much noise, so we had to filter to semantically meaningful additions only before sending to the analyst.
Prompt precision for threat classification. Getting Claude to consistently return structured, typed JSON with meaningful threat classifications required careful prompt engineering. The system prompt had to encode a specific rubric for what constitutes High vs Medium vs Low threat, grounded in the user's actual product context, not generic competitive analysis heuristics.
Realtime timing. The pipeline is async by design: the edge function triggers it and returns immediately. Wiring the frontend to receive the completion event over WebSocket rather than polling required careful state management to ensure the UI updated exactly once when the digest arrived, without flickering or stale data.
Accomplishments that we're proud of
The realtime moment. Watching a digest push to a live dashboard the instant an autonomous agent finishes its analysis, with no page refresh, no polling, no manual trigger, is the thing we're most proud of. It's what makes RivalWatch feel like a living system rather than a report generator.
We're also proud of the depth of InsForge integration. Database, storage, edge functions, model gateway, realtime, cron scheduling, and sites: every service is load-bearing. Pull any one of them out and the product breaks. That's what genuine platform integration looks like, and it's what we set out to build.
What we learned
Building a production-grade agentic pipeline is mostly a data quality problem, not an AI problem. The hardest part wasn't getting Claude to produce good analysis: given clean, well-diffed input it does that reliably. The hardest part was making the scraper produce input clean enough that the analyst could reason about it meaningfully. Garbage in, garbage out applies to agents more brutally than anywhere else.
We also learned that InsForge's agent-native design philosophy is real and not marketing. The CLI's structured JSON output and semantic exit codes made it genuinely easy to drive from a Python subprocess loop. We never had to parse human-readable output or handle ambiguous responses from the infrastructure layer. That matters more than it sounds when you're building an autonomous pipeline that can't have a human in the loop to interpret errors.
What's next for RivalWatch
Multi-source intel. Right now we watch web pages. The next layer is job postings: a competitor suddenly hiring six ML engineers tells you something their changelog won't for six months. After that: GitHub repos, patent filings, and App Store reviews.
User accounts and team digests. The current build is single-user. The obvious next step is team support: one workspace, shared competitor tracking, digest delivered to Slack or email.
Trend memory. Right now each digest is stateless. The agent doesn't know that a competitor has been steadily lowering their pricing for three quarters. Adding longitudinal analysis across snapshots turns RivalWatch from a change detector into a genuine strategic intelligence layer.
Confidence scoring. Not every detected change is equally meaningful. Training the analyst on historical data about which changes actually mattered to which types of companies would let us move from three threat levels to a continuous confidence score with much higher precision.

Log in or sign up for Devpost to join the conversation.