-

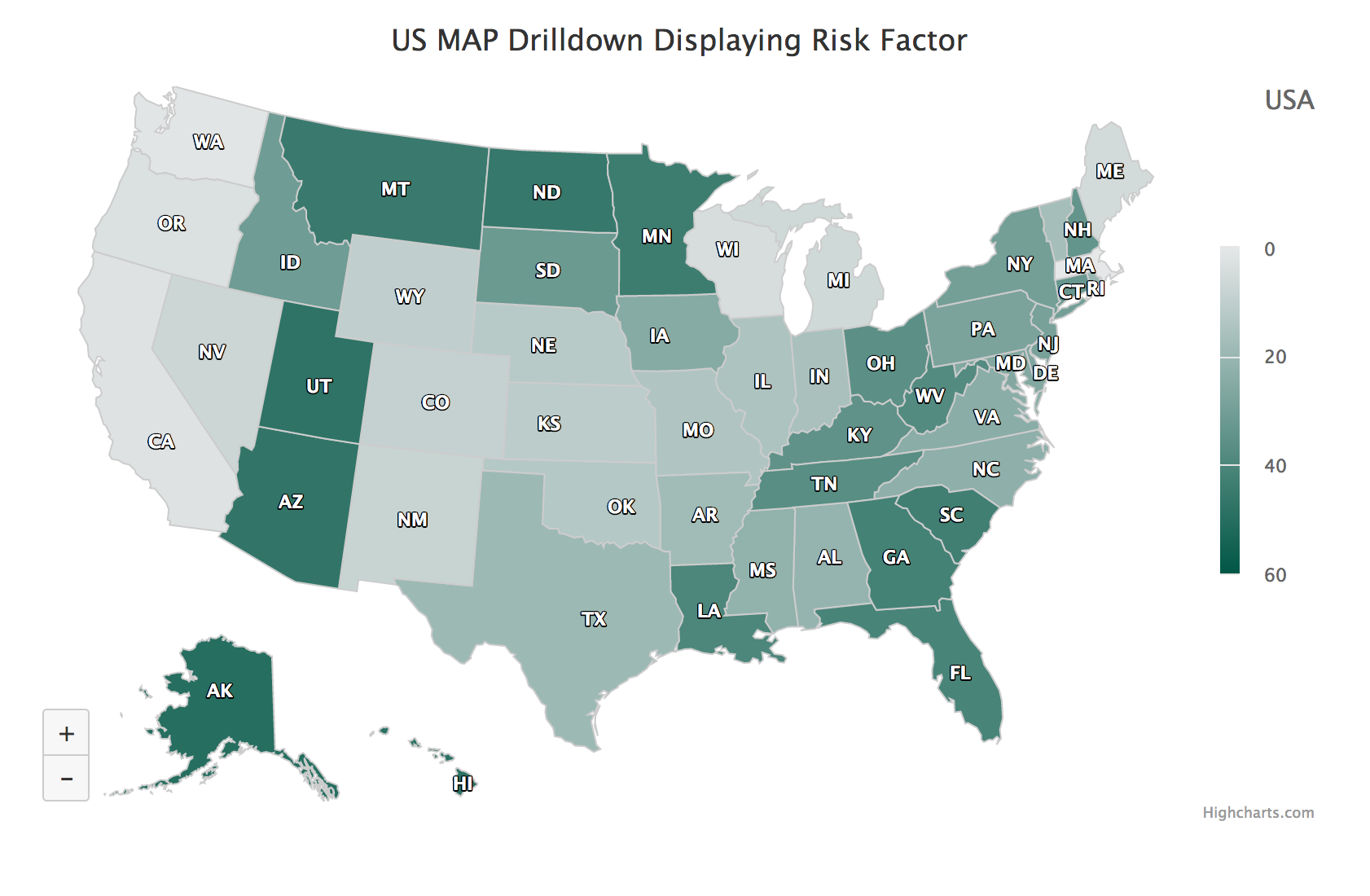
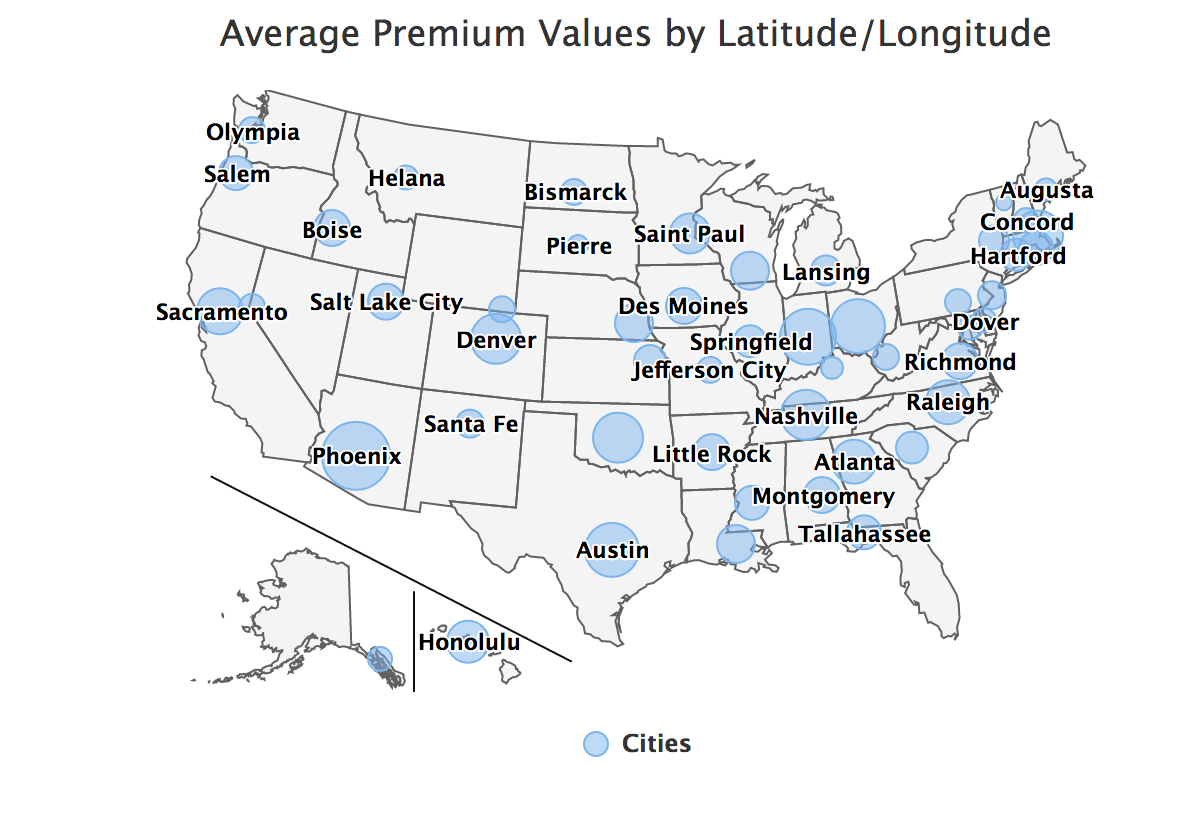
Risk Factor State Map
-

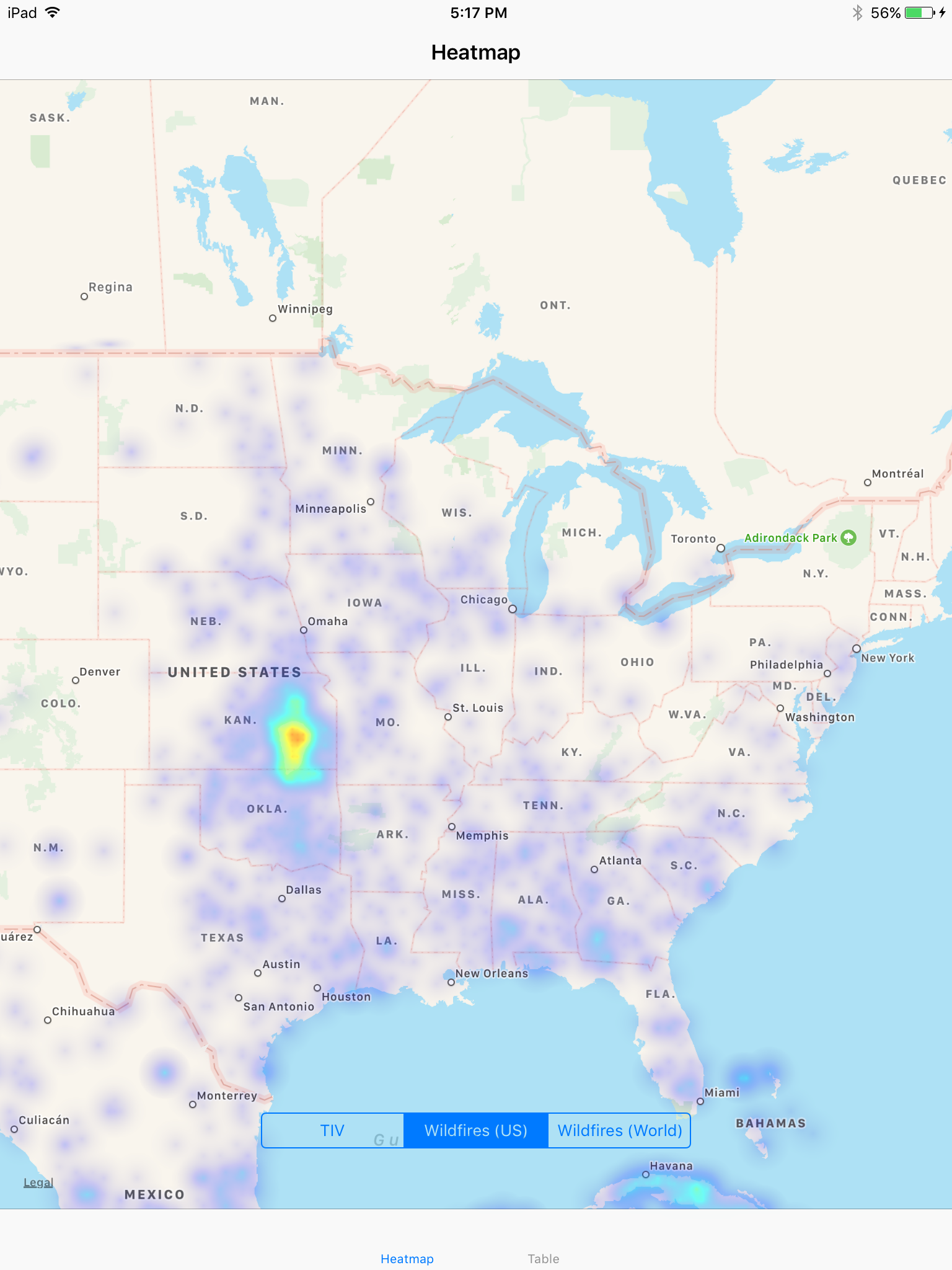
Wildfires in the US
-

-

-

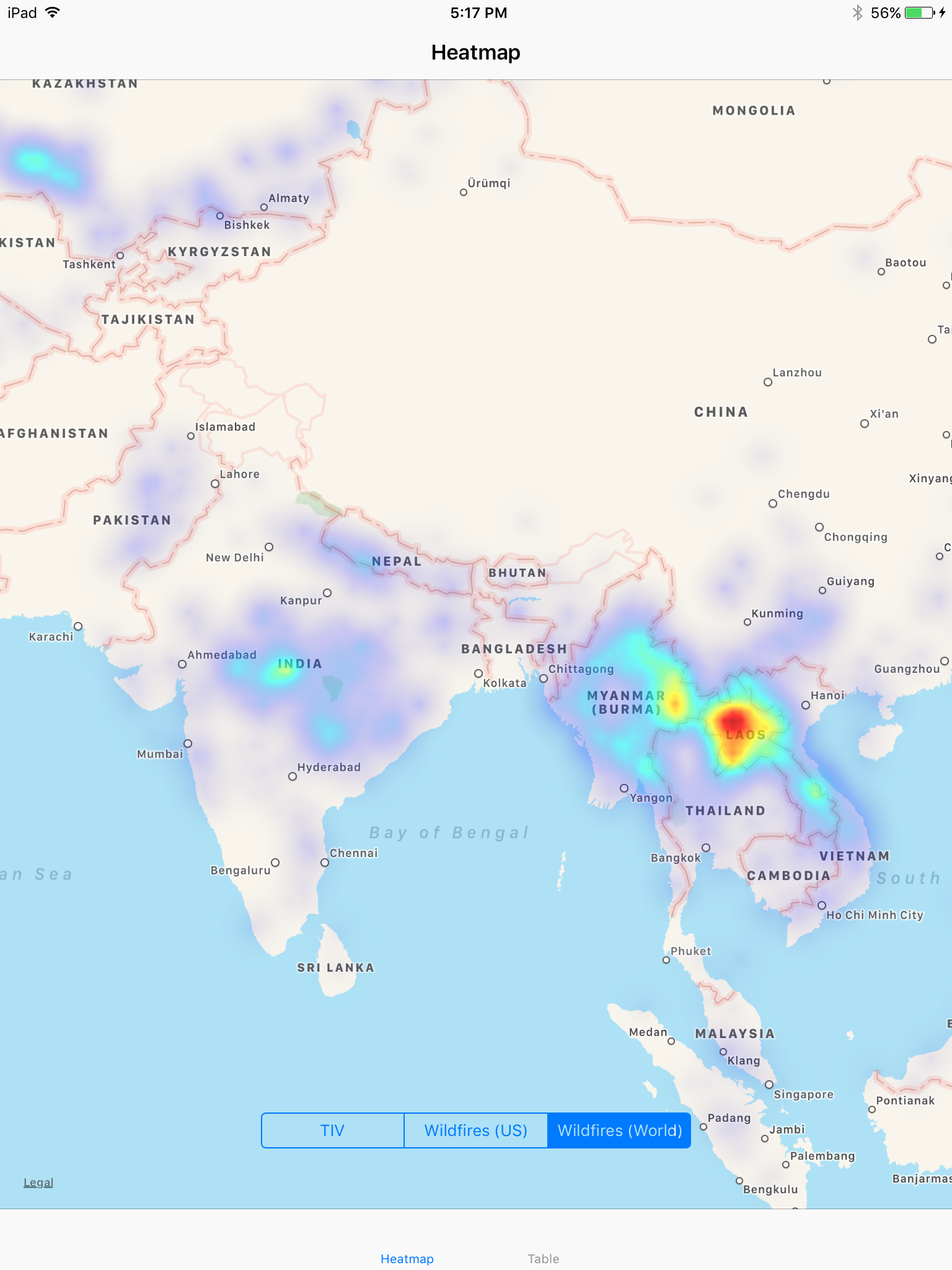
Wildfires in South Asia
-

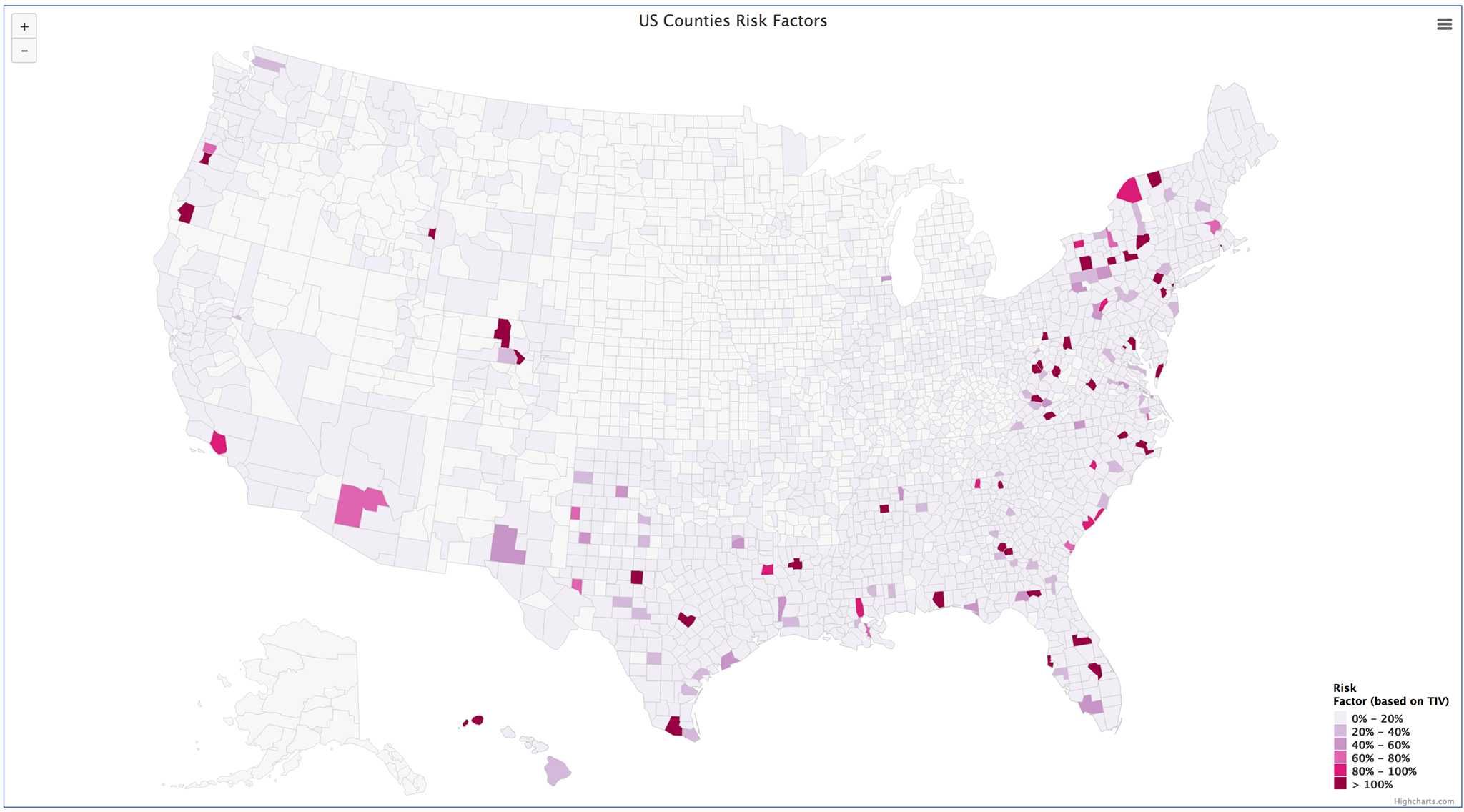
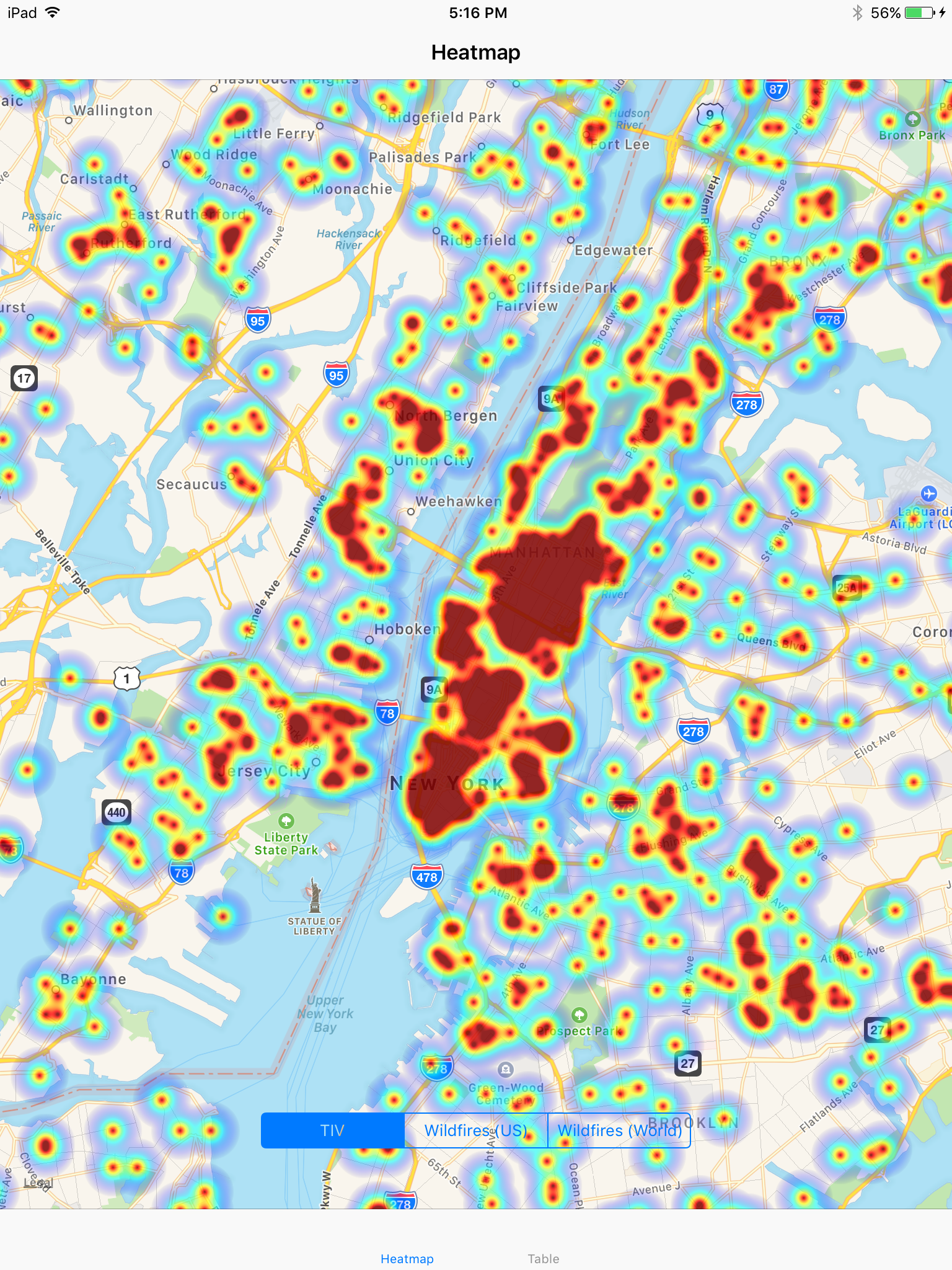
Total Insurable Value in New York
-

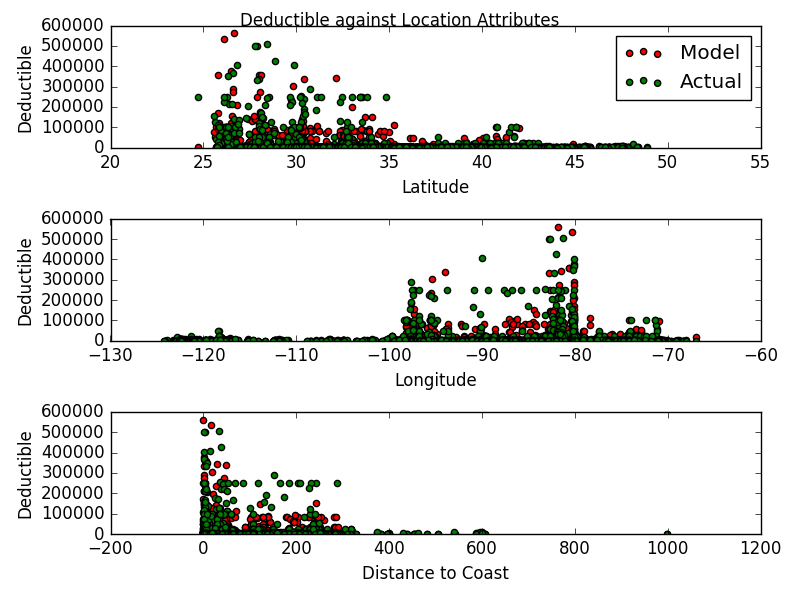
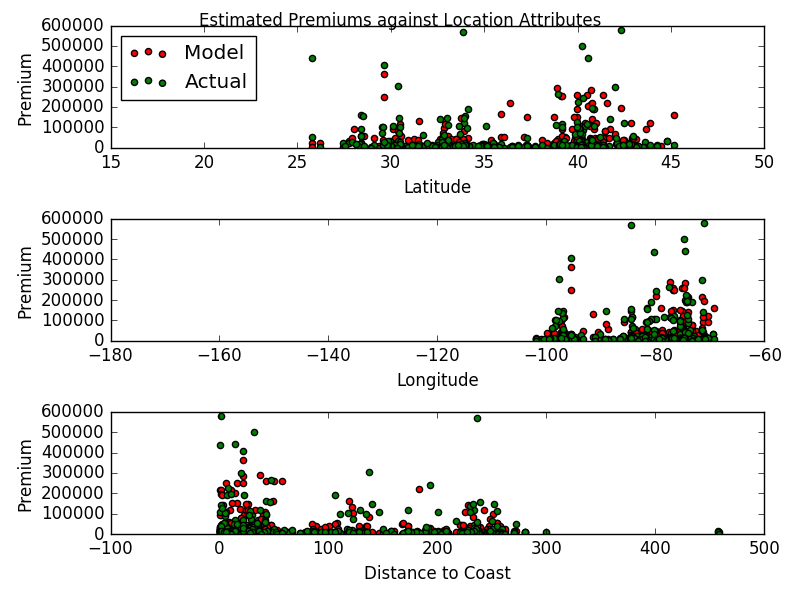
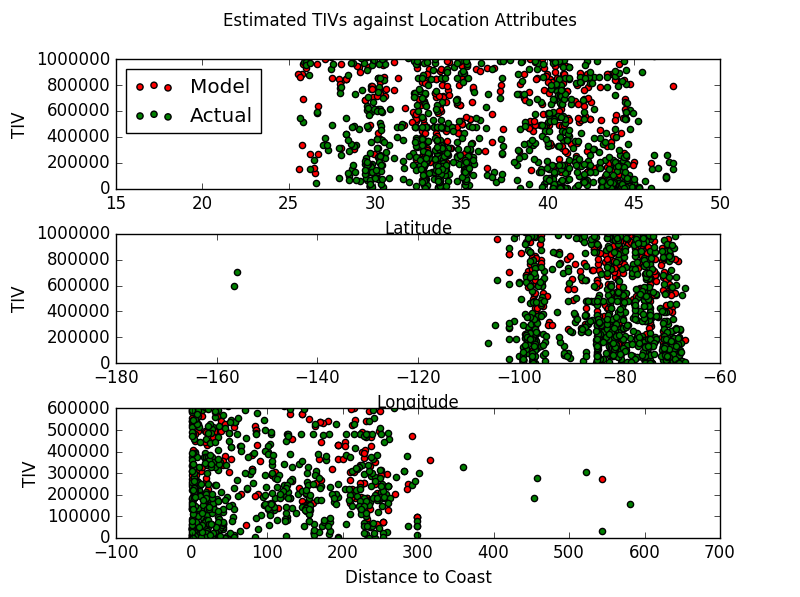
Model Performance on Withheld Test Set
-
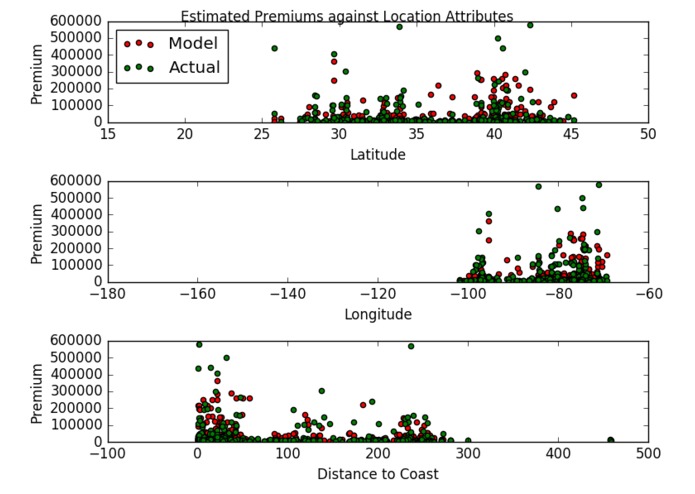
Model Performance on Withheld Test Set
-

Model Performance on Withheld Test Set
Inspiration
The insurance industry relies heavily on its data scientists and massive amounts of data. And in the modern age, number crunching should be left to computers.
What it does
Riskulizer also provides three different machine learning models to predict estimated property premiums, TIVs, and deductibles given input data such as latitude and longitude, distance to the coast, the year the property was built, and more! We created these predictive models via a k-nearest neighbors regression, which assigns properties with similar features approximately the same premium, TIV, and deductible values.
Our iPad app provides an intelligent and interactive interface for analysts to view past high-risk events like wildfires, hurricanes, tornadoes, as well as a prediction for where these dangerous events can occur in the future.
The Build
To prepare the regression model, we first had to cleanse the data, which was full of invalid entries. We decided to do a mixture of dropping data entries and interpolating missing values in the data to maintain a sizable dataset. After that, we faced the problem of what model to train on this high-dimensional data. We tried various models such as polynomial regressions with ElasticNets, support vector regressions with a RBF kernel, and finally our k-nearest neighbors regression. We also played around with what features to include in our model with r-squared and mean absolute error metrics. Using the DTMHeatMap framework, we were able to generate heat maps to provide a geographical representation of where these disasters have occured and could occur in the future.
Accomplishments that we're proud of
We're most proud of the fact that we were able to integrate machine learning algorithms and actually get a valuable insight about the world.
What's next for Riskulizer
We plan to try to expand our training data set to include more features in our algorithms to get more accurate and diversified predictions. Also, we plan to make our web and iPad applications more interactive.
https://cdn.rawgit.com/Salil999/AXIS-Hackathon/ef61677d/index.html






Log in or sign up for Devpost to join the conversation.