Inspiration
I moved to the United States 4 months back to start my master’s program and immediately felt the sting of America’s sky-high healthcare costs. With a family history of diabetes, every out-of-network price tag hit me a little harder. I wondered, if I ever end up in the ER, how likely am I to bounce back into the hospital just weeks later, and what could I do about it now? That worry sparked RiskTwin AI: a tool that not only predicts 30-day readmission risk but also shows me real patients who looked like me and what happened to them. By pairing classic risk scoring with AI-powered patient twins, clinicians and future-me get actionable, data-backed insight instead of a mysterious percentage.
What it does
RiskTwin AI turns a basic patient profile into three actionable insights delivered in one API call or click:
| Output | Purpose | How it helps clinicians |
|---|---|---|
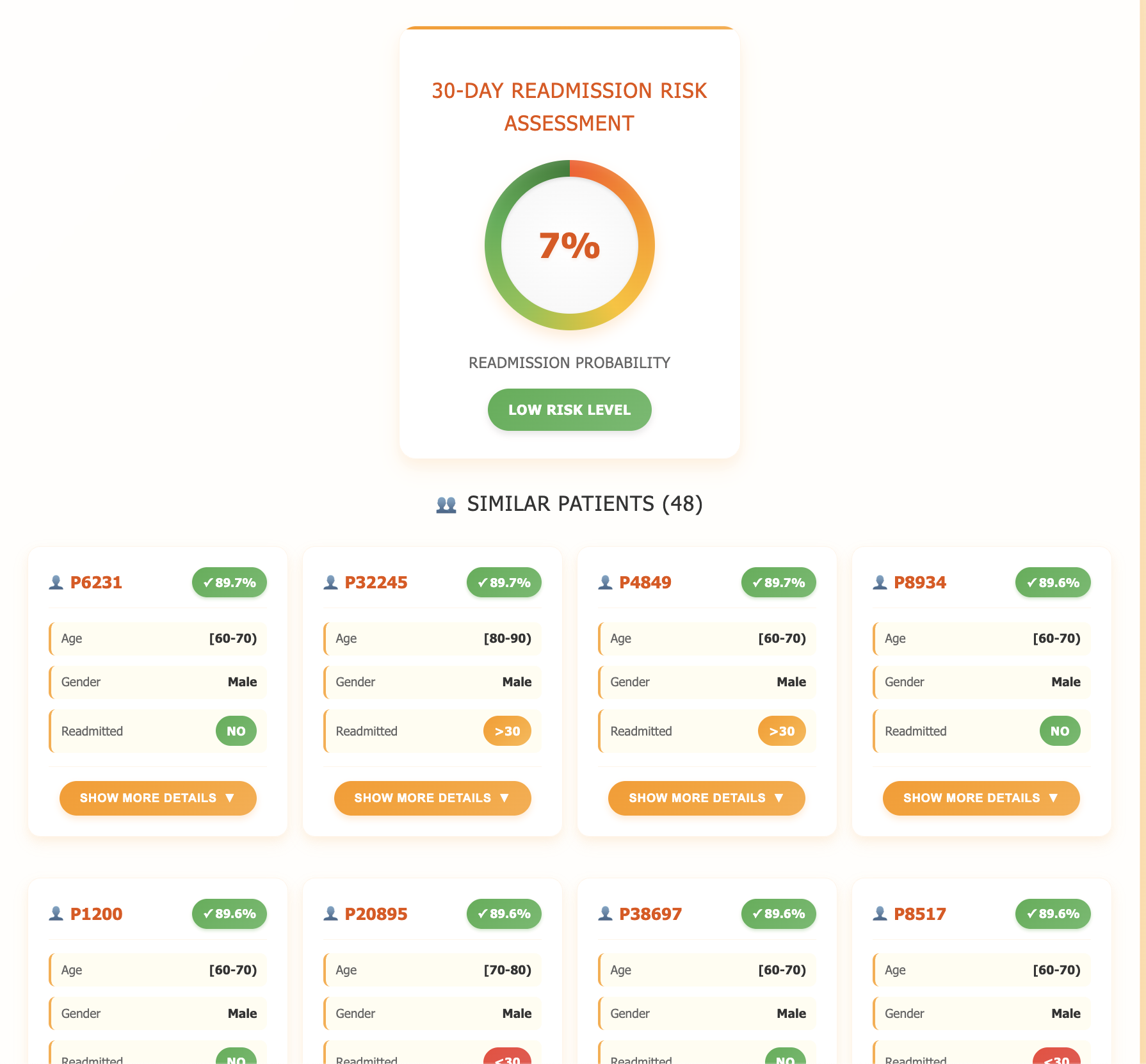
| Readmission probability | XGBoost model returns a 0-1 score for 30-day hospital readmission. | Flags high-risk patients early so care teams can plan follow-ups or extra monitoring. |
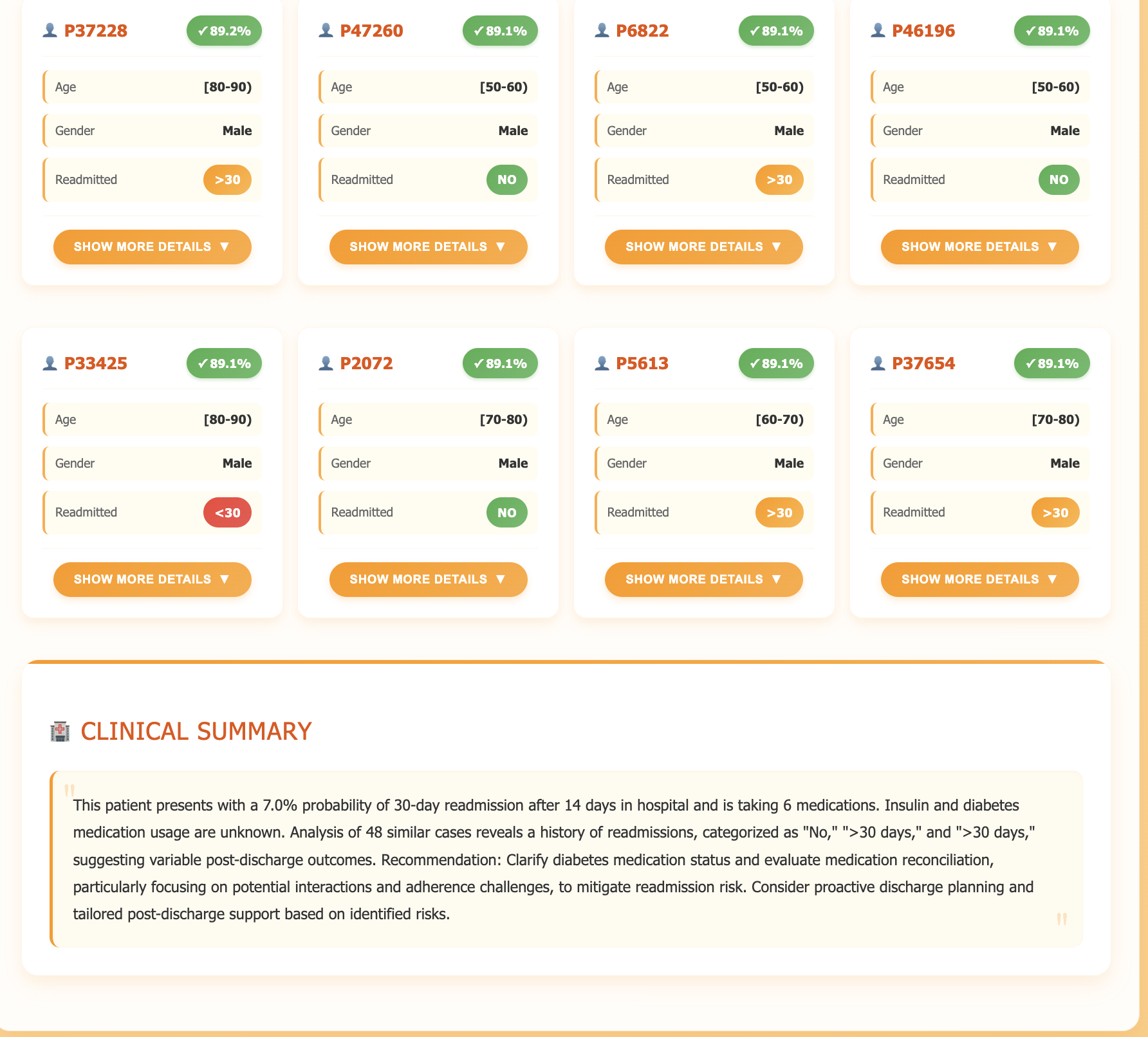
| Top-K “patient twins” | MongoDB Atlas Vector Search finds the most similar historical encounters (diagnoses, labs, meds, age, etc.). | Gives real-world evidence of what happened to comparable patients, treatments tried, length of stay, and outcomes. |
| LLM explanation | Gemini 2-flash condenses the risk drivers and twin comparison into ≤120 understandable words. | Provides transparent, clinician-friendly rationale instead of a black-box score. |
How I built it
• Data & Features
- Downloaded the public Diabetes 130-US Hospitals CSV.
- Created vector embeddings and stored them in a MongoDB collection
- Created a cosine similarity search index on MongoDB to fetch similar patients.
• Risk Model
- Trained an XGBoost model inside a scikit-learn pipeline; achieved AUROC ≈ 0.73.
- Uploaded the model artifact to Vertex AI using a dedicated staging bucket.
• Embeddings & Vector DB
- Generated 768-dim embeddings for each patient row with Vertex AI TextEmbedding-004.
- Inserted
{patient_id, features…, vector}into MongoDB Atlas; built a cosine K-NN index.
• API Layer
- Implemented a FastAPI service (Python 3.11) with async helpers:
predict_risk()→ calls Vertex endpoint.similar_patients()→ runs an Atlas aggregate pipeline.
- Added
generate_explanation()using Gemini 2-flash for concise rationale.
Challenges I ran into
• Noisy public data, 55 messy columns, feature pruning & encoding. • Embedding structured data, text models don’t love numbers, template sentences solved it. • Initial environment setup for Vertex AI was a little tricky, but nice official documents helped a ton.
Accomplishments that I'm proud of
• End-to-end AI pipeline in 48 hrs: cleaned a 100k-row public dataset, trained an XGBoost model on Vertex AI, embedded all records, and deployed everything. • Real-time vector search: proved that MongoDB Atlas Vector Search can surface patient twins in <400 ms even on a free M0 cluster. • Explainability on demand: crafted a prompt that turns raw patient features + KNN matches into a 120-word, clinician-friendly rationale via Gemini 2-flash.
What I learned
• Turning structured rows into meaningful embeddings - stringifying numeric + categorical data effectively with one-hot encoding. • How to create proper MongoDB vector search indexes based on the use cases. • Learnt about GCP's Vertex AI capabilities, specifically its model garden, using different models, deploying locally trained models over the internet, and using them with very low latency.
What's next for RiskTwin AI
• Expand to MIMIC-IV for richer vitals/notes. • Fine-tune a smaller open-weight LLM for on-prem hospitals. • Add a clinician feedback loop to refine similarity weighting.

Log in or sign up for Devpost to join the conversation.