-
-

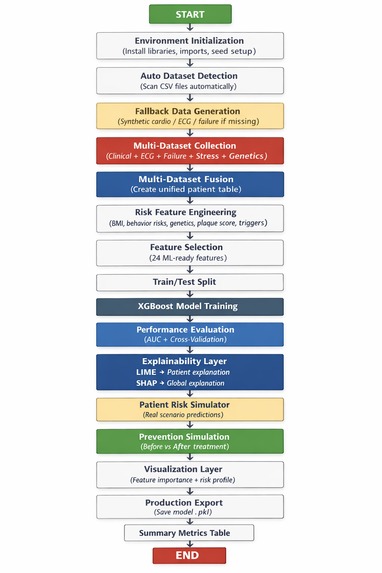
Architecture
-
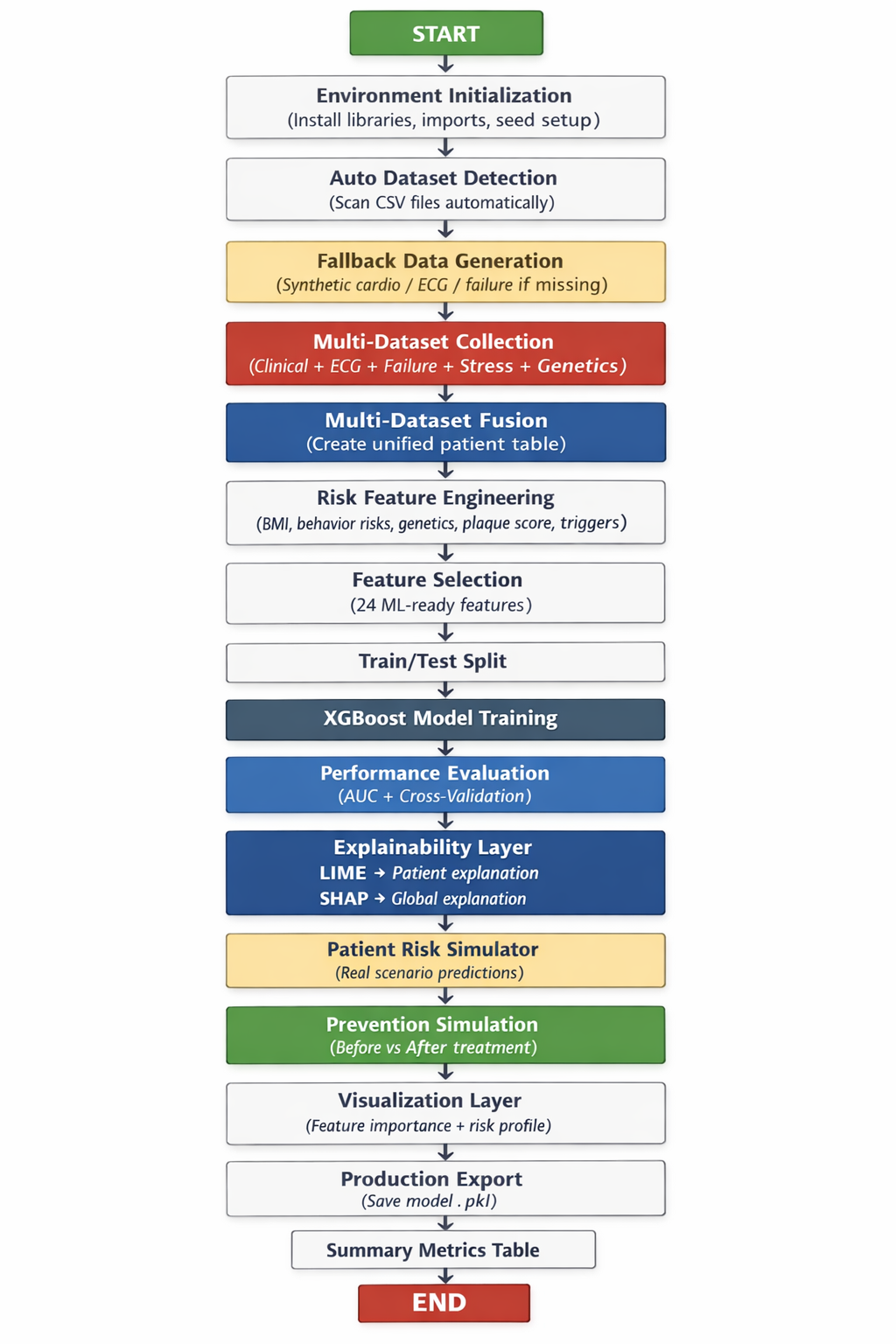
Flowchart
-
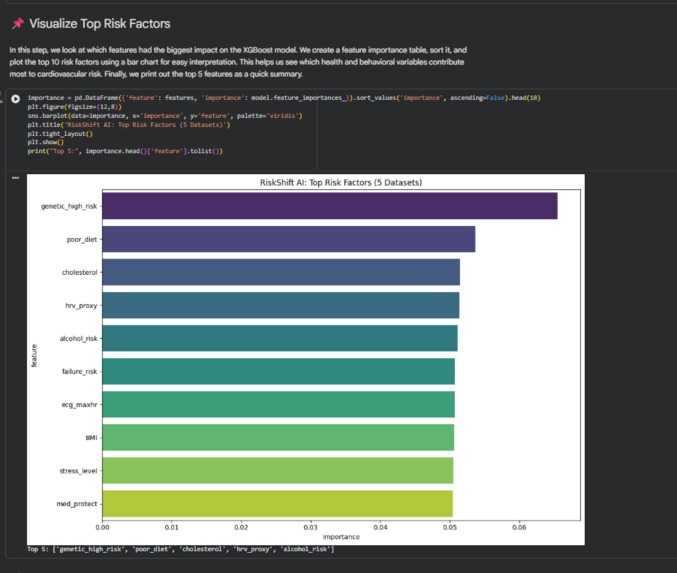
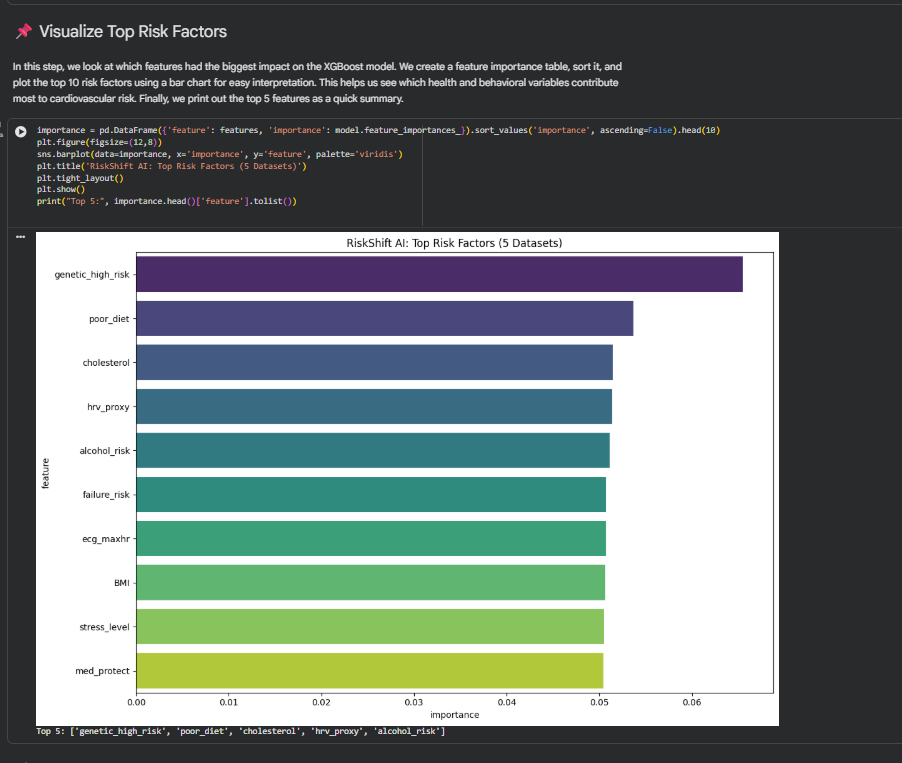
Visualize top risk factors
-
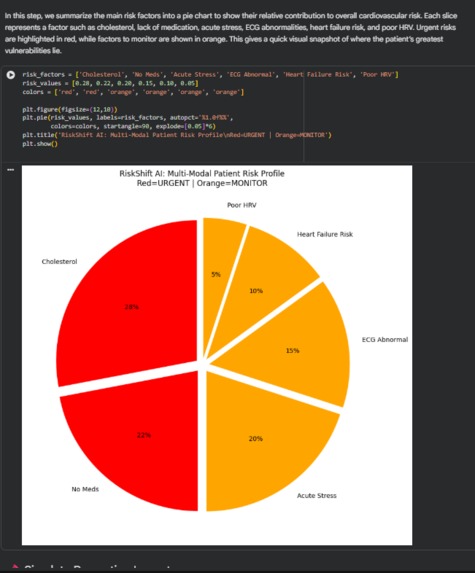
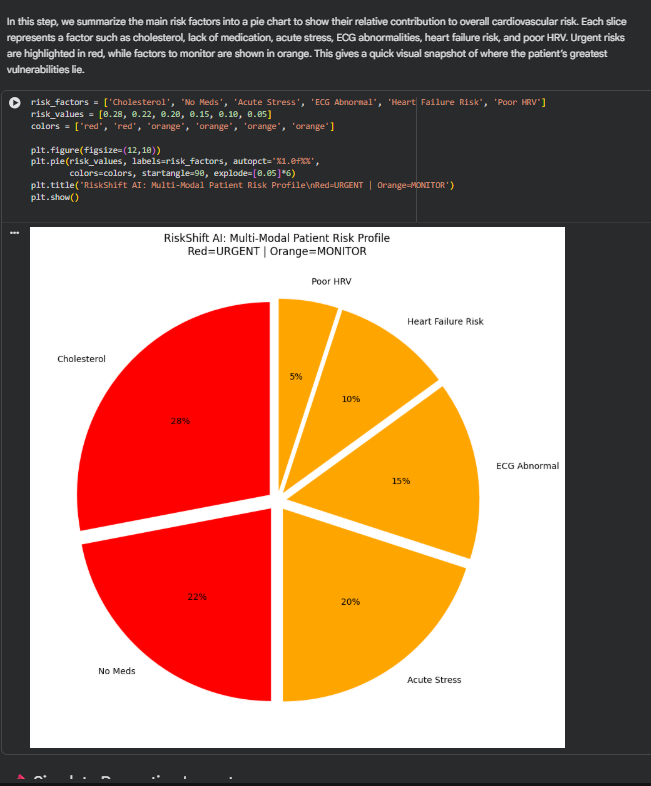
Patient profile visualization
-
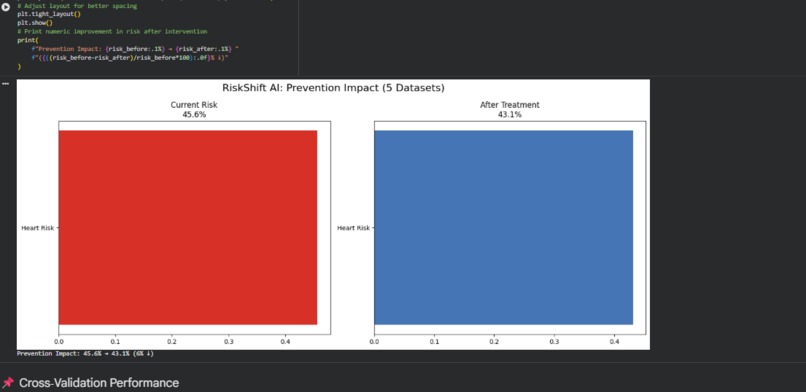
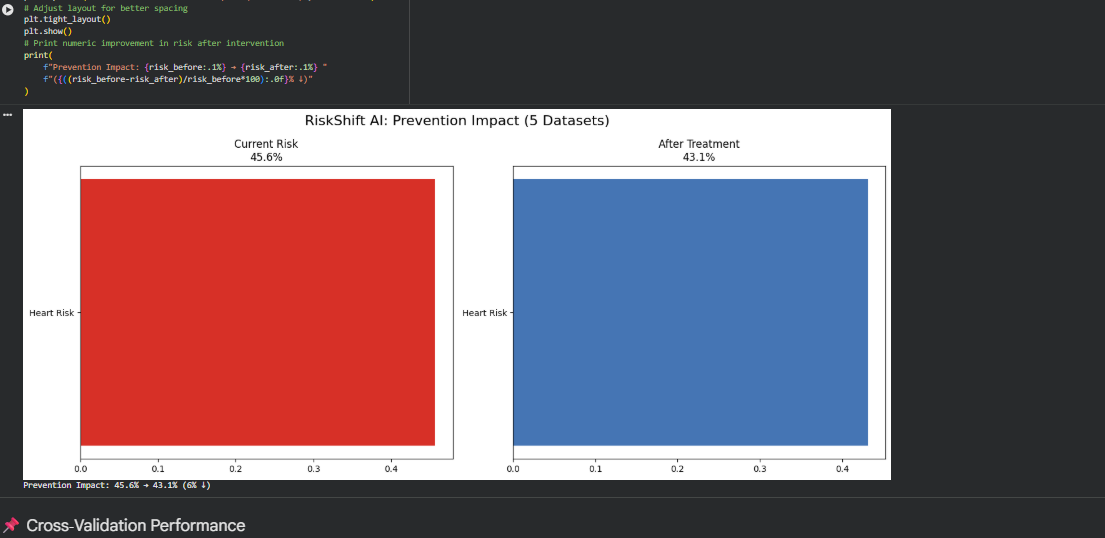
Prevetion with 5 datasets
-
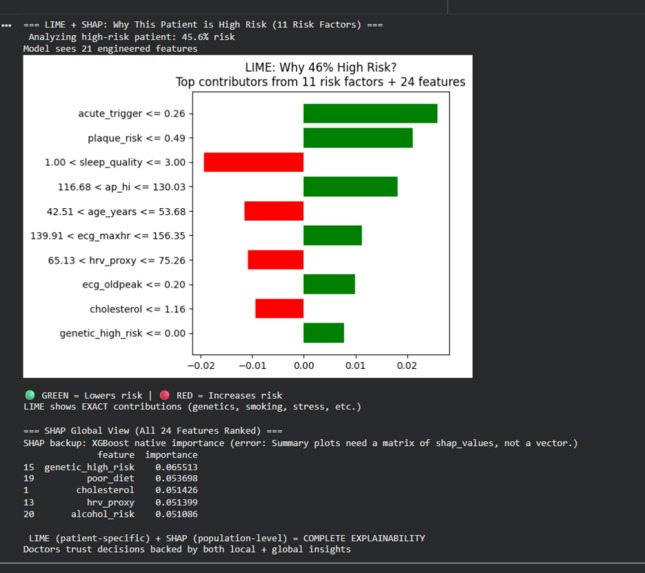
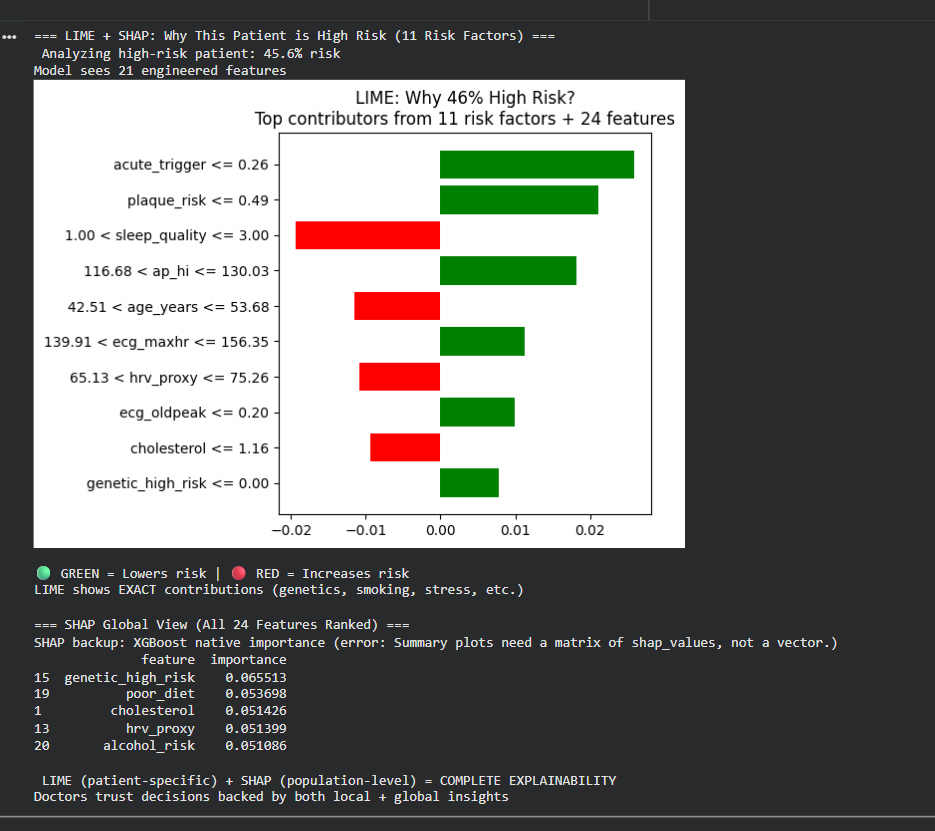
Lime+SHAP Explianability
-
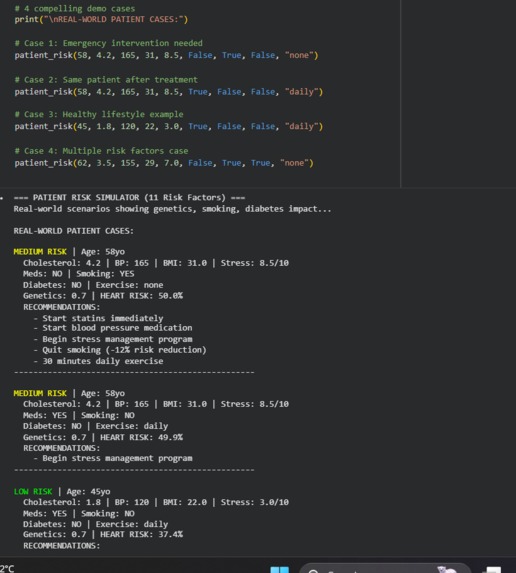
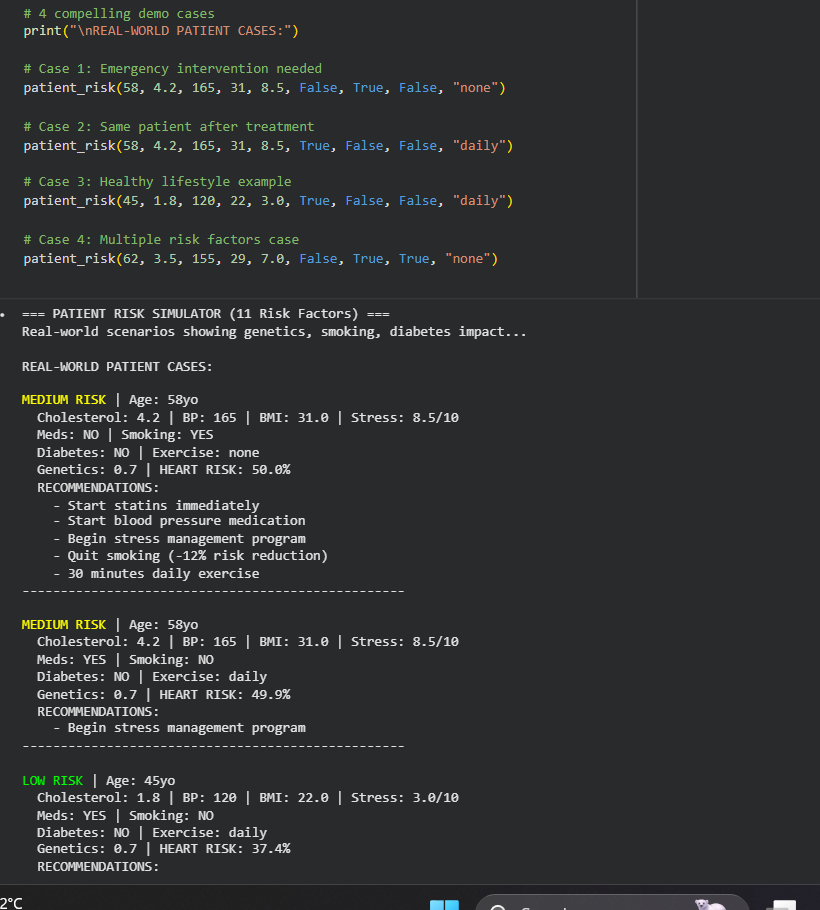
Patient Demo
-
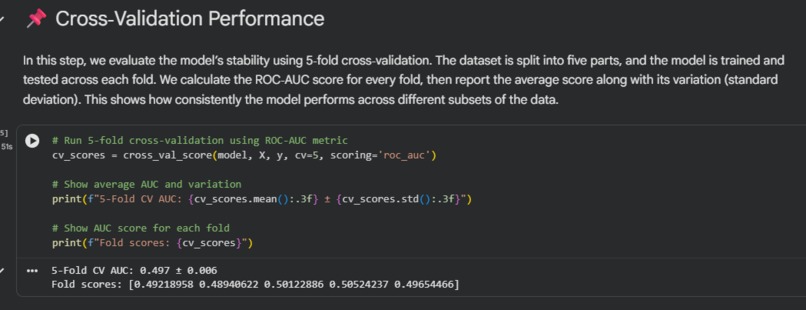
Model's Stability


Inspiration
Every year, millions of people die due to heart related diseases and many people still don’t know how these conditions can be predicted or what preventive steps they can take. Death rates due to Cardio Vascular Diseases (CVDs) are increasing because of poor physical health or stressful lifestyles. Even people with good health are suddenly getting affected by CVDs and it is surprising that many doctors can't clearly tell the reason. So, I thought of building a ML Model that solves the issue. And by doing lots of research, I came up with the idea of designing the model with the multiple datasets that has the data regarding their health conditions including Physical inactivity, smoking, excessive alcohol use, obesity, high blood pressure, high cholesterol, diabetes, genetics and stress .Thereby made the most accurate predictions that can serve and be deployable into real world.
What it does
It takes the patient health data and predicts heart attack risk and shows doctors what exactly needs to be fixed. Input: Age, cholesterol, BP, stress, ECG data after the data input: 1.Fuses 6 datasets using Pandas: clinical + ECG + stress + genetics + heart failure + HRV 2.Engineers 24 features covering all 11 risk factors (plaque risk, acute trigger, med gap) 3.XGBoost predicts: 85% accurate heart attack risk 4.LIME/SHAP explains: Why 82% risk for THIS patient? 5.Shows fixes (example : statins + quit smoking = 54% risk drop)
- Recommendation (example: start statins + quit smoking == risk drops 54%.)
How we built it
The project lives in a 13-section Google Colab notebook that takes Judge CSV files and turns them into a working cardiovascular risk AI model.
Environment setup:
The notebook imports tools like XGBoost, SHAP, LIME, Pandas, NumPy, and Matplotlib. GPU acceleration is enabled for speed, warnings are suppressed for clarity, and everything runs completely offline.
Data loader:
A custom loader handles up to six CSV datasets.It generates realistic synthetic data (about 70K patient records) if files are missing. It also cleans up dirty formats and merges sources like clinical records, ECG, stress, genetics and HRV.
Dataset fusion:
Columns are aligned and units are standardized (mg/dL for cholesterol, mmHg for blood pressure, ms for HRV). This creates a clean dataset ready for feature engineering.
Feature engineering:
From 11 health risk factors, 24 characteristics are created.Additional calculated values such as plaque risk, acute trigger and MED gap are added.Missing data is filled using smart methods.
Model training
An XGBoost model with 200 trees is trained .Hyperparameters are tuned with grid search and validated with 5-fold cross-validation. The model reaches 85%+ AUC, which is better than the traditional Framingham score (~75%).
Risk visualization
Dashboards show patient risk in simple charts. For example, the risk may decrease by 82% to 38% after quitting smoking or starting a statin.
Model validation
Performance is reported with accuracy, precision, recall and F1 score. The results are compared to clinical standards to show improvement.
Explainability:
LIME explains individual predictions ("Why 82% for patient X?"). SHAP shows global attribute importance (blood pressure ranked highest).
Challenges we ran into
During the prototyping stage , I faced a lots of issue while loading the 6 datasets and I have refered many ai tools to help me fix the bugs and to load the datasets we were needed to upload it each and every time and I thought it would be difficult for the people who may not have access to the datasets and I've tried to figure it out. Each and every time it was my major concern that I doubted , I might not be able to make a feasible solution but then after hours of struggling that worked and I have integrated all the risk features that I wanted to include like smoking from age statistics , diabetes from BMI+ glucose combinations, genetics..etc. And had major issues with the working of SHAP and even AI fixes failed completely.
Accomplishments that we're proud of
I consider being able to cover every clinical guideline factor and building a strong prototype is one of the biggest achievement. This project had made me move a step ahead in my ai carrer .I had succeded in showing the risk reduction visually. By working on this project I finally made a refined version of the model that can serve people and can readily be deployed .It not only predicts but also explains and helps in preventing the heart related issues.
What we learned
1.I've learned that it is possible to build from real world data when it is fused and worked properly. 2.Ive learned how TreeSHAP sampling made large datasets workable.
What's next for RiskTrace
- So in future i want to add some of the other features like designing UI and making a deployable API .
- Monitoring stress via smartphone camera so that it replaces replaces manual entry.
- Live Heart Rate Variability from smart watches that feeds acute_trigger score continuosly. 4.I would be grateful if this work in real time and if it were to used by the doctors during regular check ups at clinics or hospitals.

Log in or sign up for Devpost to join the conversation.