


💡 Inspiration $80 Billion. That’s how much money vanishes into thin air every year due to insurance fraud in the US alone.
When we started researching this, we realized a massive flaw in how insurance works: Traditional systems look at claims individually ("Does this car crash look real?"). But fraudsters work in teams.
We thought: "What if we stopped looking at the trees and finally looked at the forest?"
We wanted to build a system that doesn't just read a claim—it acts like a digital detective, finding the invisible connections between strangers that prove a conspiracy. We built RiskChain to catch the "Fraud Rings" that everyone else misses.
🕵️♂️ What it does RiskChain Intelligence is a full-stack fraud detection engine that analyzes claims in real-time using three distinct "brains":
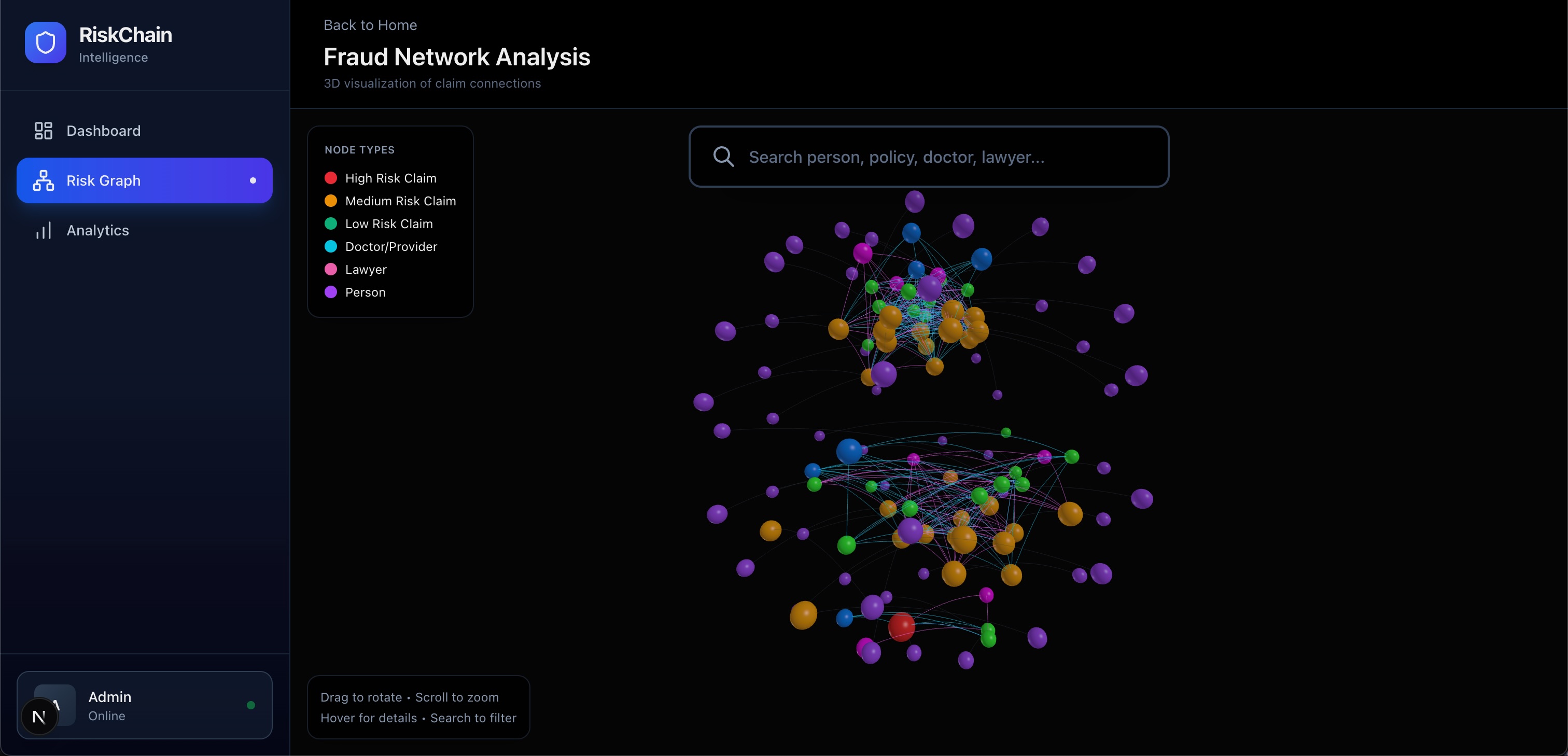
The Graph Brain (NetworkX): It builds a dynamic "spiderweb" of connections. If 5 random people all use the same chiropractor ("Dr. Chen") and file claims from the same IP address, RiskChain instantly flags it as a "Fraud Ring."
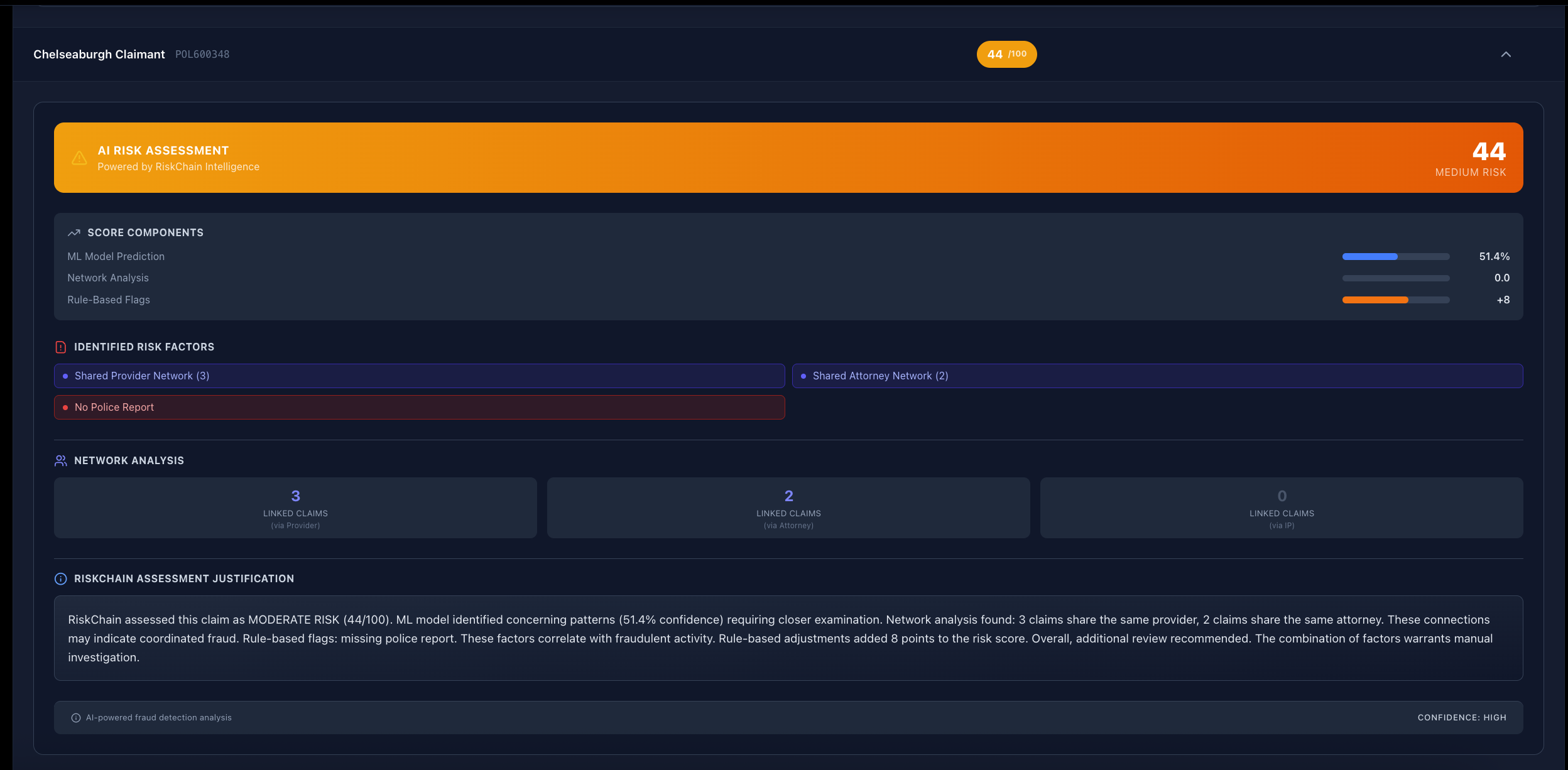
The Semantic Brain (OpenAI GPT-4o): It reads the accident description text to detect subtle red flags—like urgency ("I need cash fast"), vague details, or conflicting stories that rule-based systems miss.
The Statistical Brain (Random Forest): It analyzes structured data (policy age, claim amounts) to find statistical anomalies.
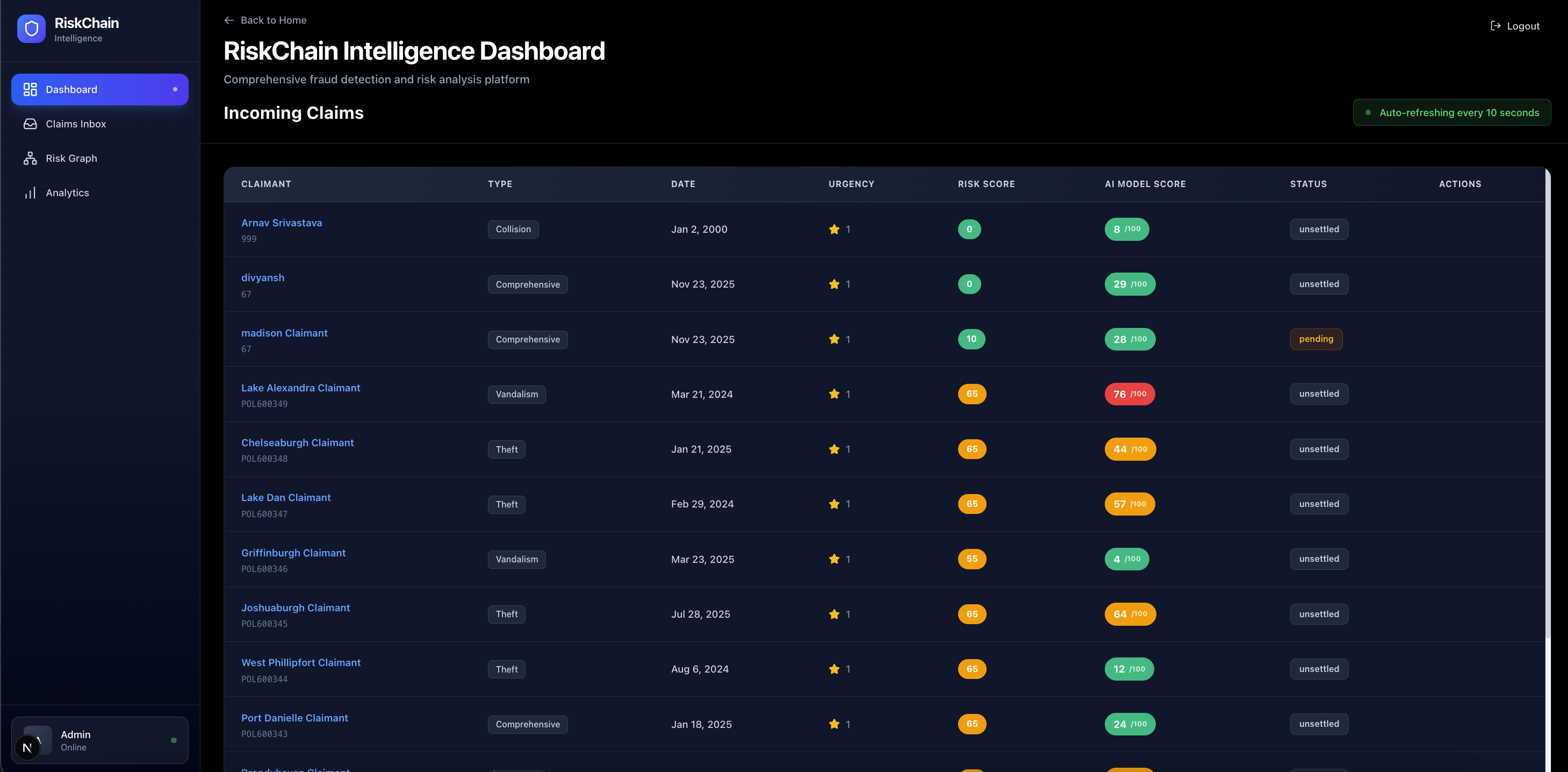
The result? An interactive Dashboard where insurance agents can visualize the fraud ring and stop the payment before the check is mailed.
⚙️ How we built it We went for a high-performance, hybrid stack:
Frontend: Built with Next.js 14 and Tailwind CSS. We used React Flow to build the interactive node-graph visualization (the coolest part of the UI!).
Backend: FastAPI (Python). We chose this for its raw speed and native support for Python's data science libraries.
The Intelligence Layer:
NetworkX for graph theory and clique detection.
Scikit-Learn for our Random Forest classifier.
OpenAI API for NLP analysis.
Database: SQLite with SQLAlchemy for rapid relational data handling.
🤯 Challenges we ran into The "Version Mismatch" Nightmare: Our ML model was trained on a different version of scikit-learn than our backend server. We spent hours fighting a cryptic _RemainderColsList error before realizing we had to retrain the brain locally!
Merge Conflict City: Combining a complex Python backend with a Next.js frontend in a Monorepo led to some... intense Git moments. (We learned to love git reset --hard).
The "Judge Judy" Test: Creating fake data that was subtle enough to be realistic but obvious enough for our demo was surprisingly hard. We had to write a script to "inject" fraud patterns into our dataset.
🏆 Accomplishments that we're proud of The "Aha!" Moment: Seeing the graph visualization light up RED for the first time when we fed it our "Smith Family" fraud ring scenario.
True End-to-End Flow: We didn't just mock the frontend. We have a working submission form that feeds a real backend, runs 3 different AI models, updates a database, and pushes the result to the dashboard in sub-second time.
Making it "Smart": Tuning our AI so it can tell the difference between "I hit a deer" (Low Risk) and "Dr. Chen said I need cash for my back" (High Risk).
📚 What we learned Graph Theory is powerful: It turns abstract data into obvious visual patterns.
Full-Stack Integration: Connecting a React frontend to a Python backend taught us the importance of agreeing on JSON schemas before we start coding.
Fraud is sophisticated: We gained a weird amount of respect for how creative fraudsters can be (and how fun it is to catch them).
🚀 What's next for RiskChain Intelligence Geospatial Analysis: Integrating Google Maps to flag if accidents happened suspiciously far from home.
Shadow Profiles: Tracking repeat offenders across different insurance carriers.
Voice Analysis: Analyzing the audio sentiment of recorded claim calls.











Log in or sign up for Devpost to join the conversation.