-
-
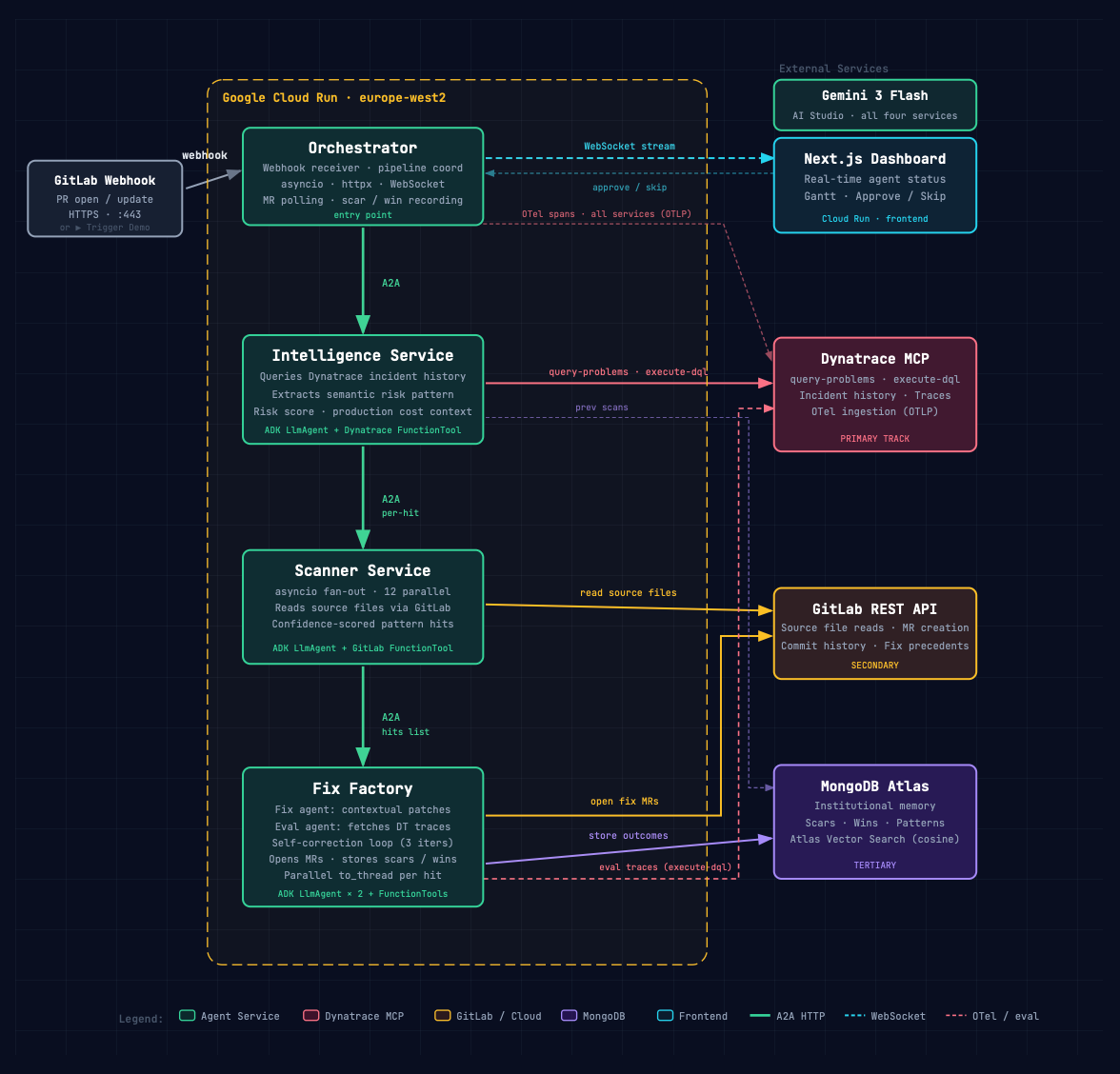
Architecture Diagram
-
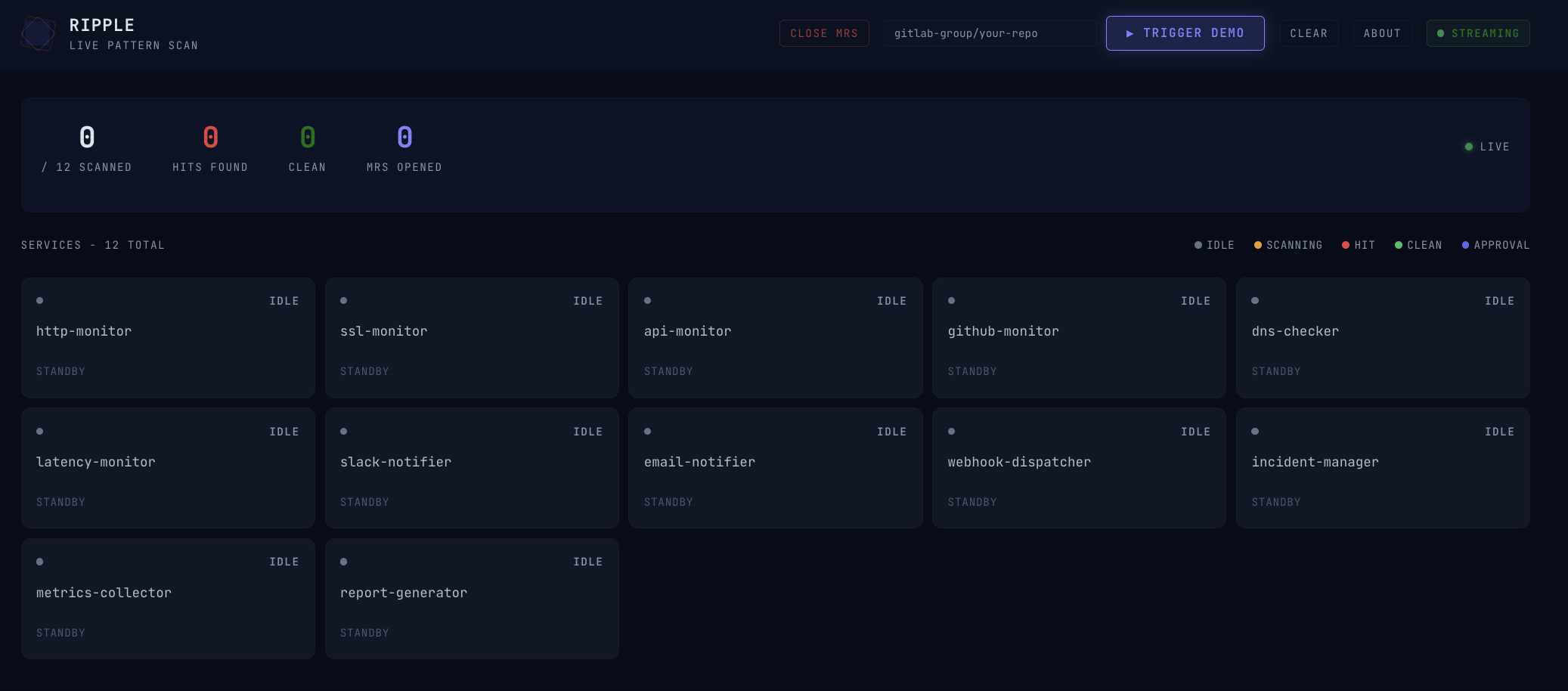
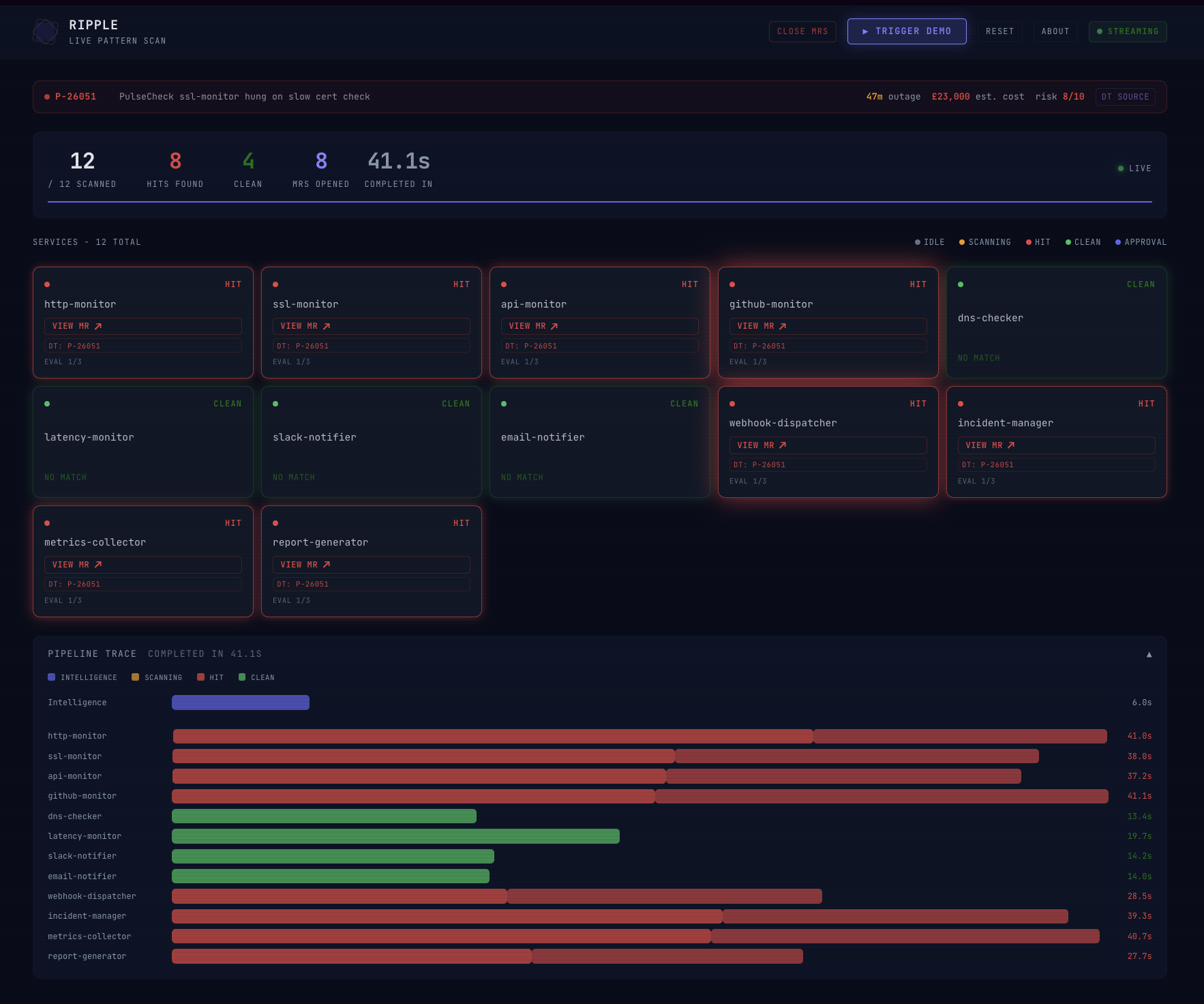
Dashboard pre-run
-
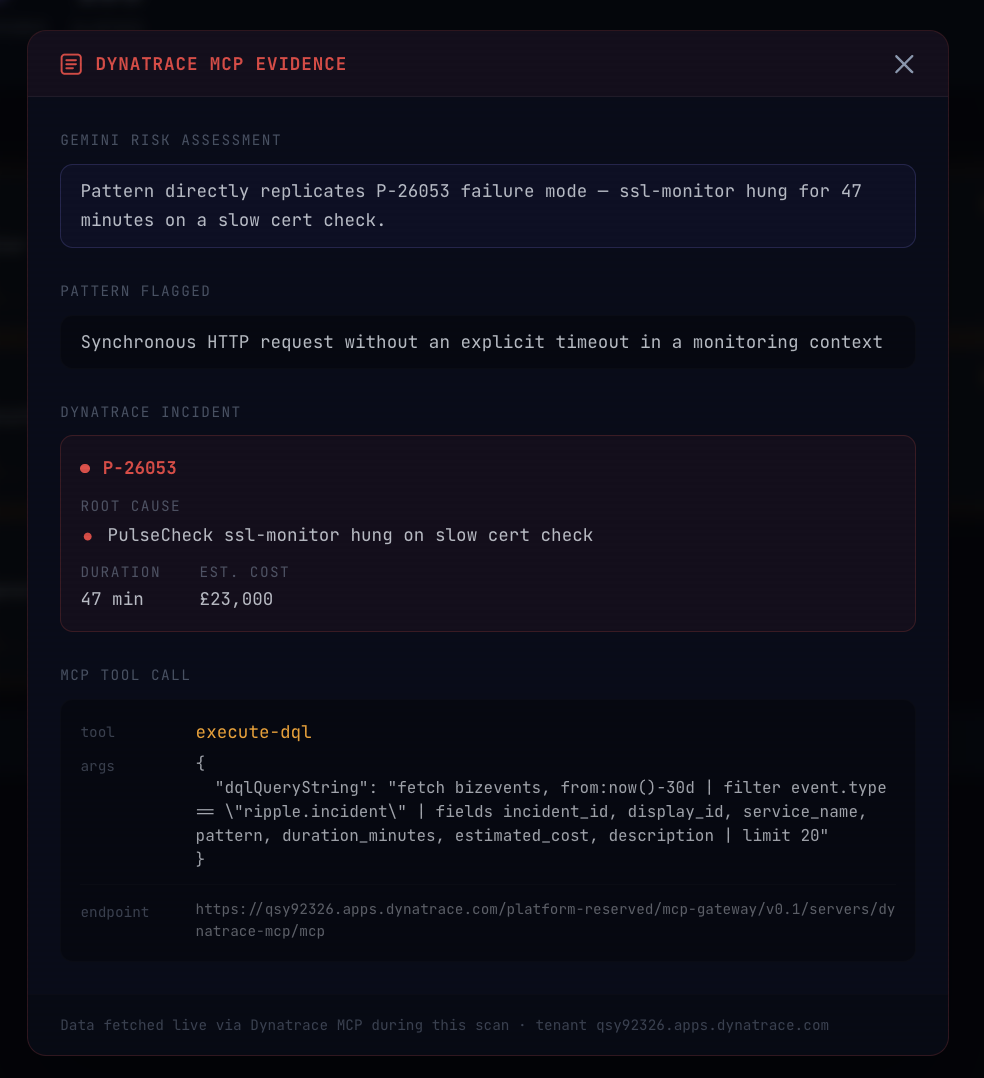
Live Dynatrace MCP evidence, included in every scan decision
-
Dashboard post-run
-
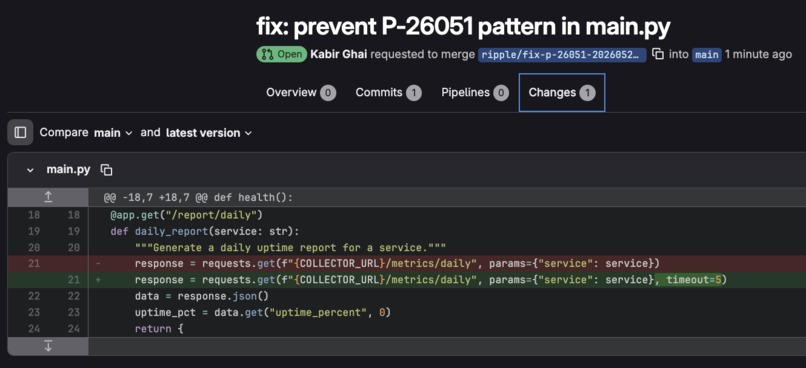
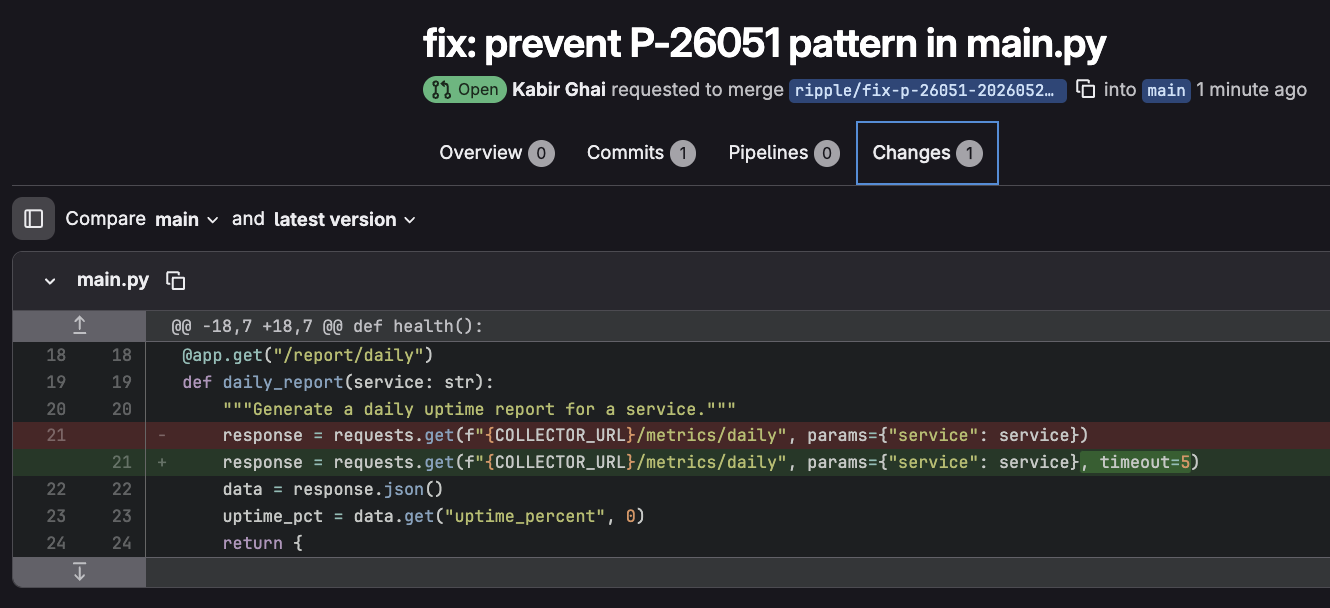
GitLab MR generated with context from Dynatrace
Inspiration
I was thinking about what code review fundamentally can't tell you. Tools can flag known vulnerabilities, simulates failure scenarios and learn from Git history. But none of them connect directly to production incident data at the PR stage.
That gap seemed clear once I saw it. Dynatrace has the incident history. GitLab has the code. Nobody knew that this pattern in the code caused this issue. That's shift-left observability in practice: production incident data used in the PR review stage, before anything reaches production. Ripple is what that connection looks like.
What it does
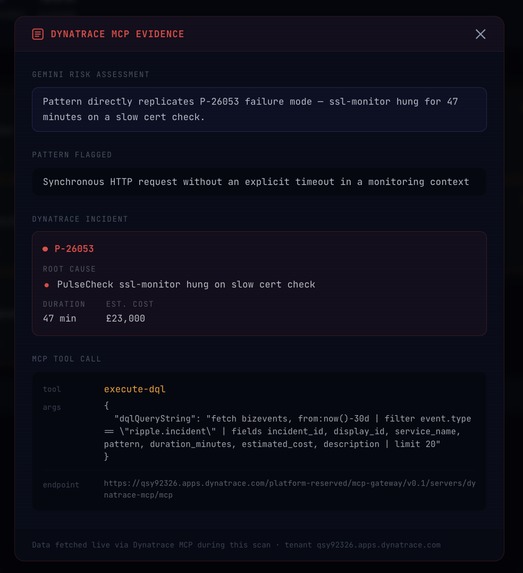
Ripple intercepts GitLab PRs, checks them against real Dynatrace production incident history, fans out across every service in the codebase simultaneously, and opens targeted fix MRs, each citing the specific incident that proved why the pattern is dangerous.
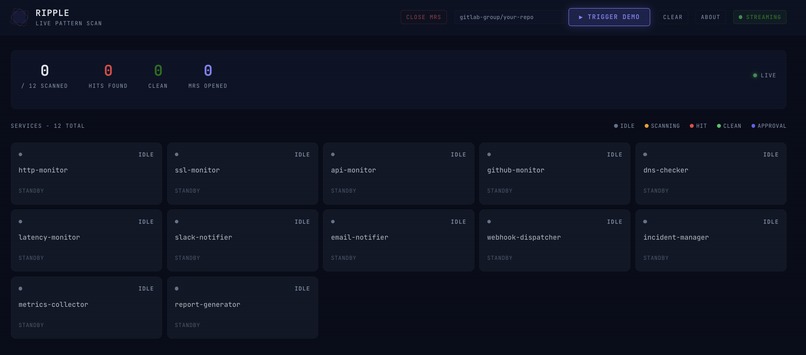
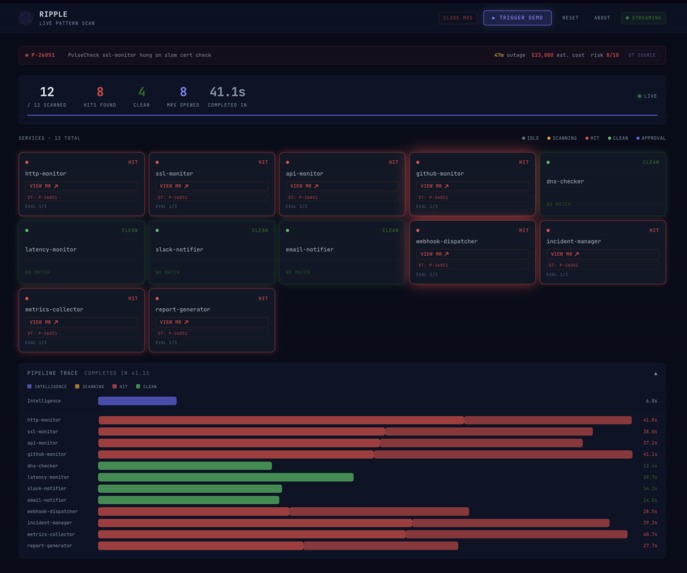
One PR triggers the pipeline. In the demo, twelve services scan in parallel. Fix MRs appear in GitLab within moments, each with the Dynatrace incident ID, duration, and estimated cost embedded in the description.
This is shift-left observability in practice: production incident data pulled into the PR review stage, before anything reaches production. The dashboard is a developer tool, not just a monitoring screen. You open it during code review. Tiles show each service scanning in real time, which file triggered the match, which self-correction iteration the fix passed on, and a direct link to the Dynatrace trace that grounded the fix.
How we built it
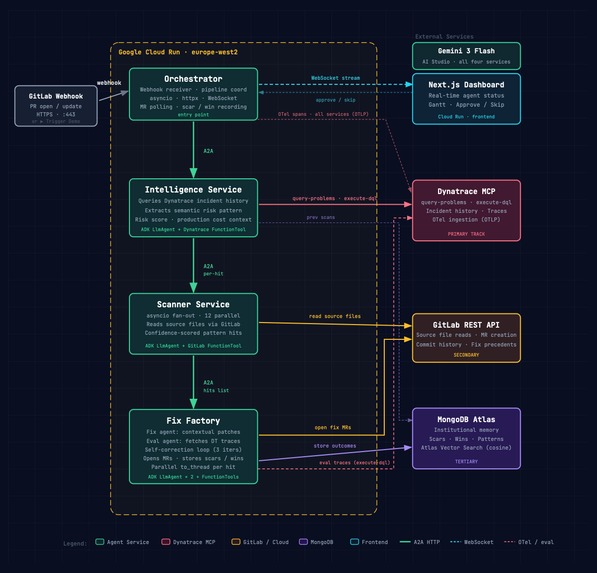
Four FastAPI microservices on Google Cloud Run (europe-west2), communicating via A2A HTTP calls. All four are powered by Gemini 3 Flash via AI Studio. Intelligence and Scanner use Google ADK LlmAgent with FunctionTool as their primary execution path; Fix Factory and the Orchestrator use direct Gemini API calls.
Orchestrator receives the GitLab webhook, coordinates the pipeline, streams real-time updates to the Next.js dashboard via WebSocket, polls open MRs for developer feedback, and records the final outcome: merged fixes become Wins (confidence, +1), rejected fixes become Scars (risk, −2).
Intelligence queries Dynatrace via execute-dql, extracts the semantic risk pattern, scores it with production cost context, and checks MongoDB for previous scans of the same pattern before passing results downstream.
Scanner fans out across the services in parallel, fetching source files via GitLab and returning confidence-scored pattern hits.
Fix Factory runs parallel threads per hit. A fix agent generates contextual patches informed by GitLab commit history; an eval agent re-fetches Dynatrace traces to validate the fix against the actual failure. Self-correction loop runs up to 3 iterations. On pass, opens the MR and stores the outcome in MongoDB as a pending scar or win. If accumulated scars push the risk score below a configurable threshold, Ripple skips the auto-fix and shows Approve / Skip buttons on the dashboard instead for manual fixes.
Three MCPs were used: Dynatrace (primary), GitLab (secondary), MongoDB Atlas with vector search (tertiary). All four services ship OpenTelemetry spans back to Dynatrace via OTLP.
Challenges we ran into
Fix Factory has ADK implementations for both the fix agent and eval agent (call_fix_adk, call_evaluator_adk), but ADK makes two Gemini round-trips each time it's invoked: one for the tool call, one for the final response. In a self-correction loop running up to three iterations per service, across eight hit services in this demo in parallel, that latency compounded and pushed the pipeline past the time limit. We couldn't find a way to bring it within the amount given in time, so Fix Factory falls back to direct Gemini calls while the ADK path remains in the codebase. We have left the complete, working ADK implementation in the code for evidence of use.
Another challenge we faced was to do with parallelism. The fix factory starts on hit services before scanning finishes. Keeping WebSocket tile state coherent while twelve services complete at different times required careful event ordering.
Accomplishments that we're proud of
The self-correction loop works against real data. The evaluated_on: incident_context span in Dynatrace proves every fix was validated against actual incident traces before the MR opened, not just assessed in theory.
Also, every pipeline run is traced in Dynatrace, meaning you can see exactly what Ripple decided and why in the same place you'd investigate a real incident. Each run contains structured OpenTelemetry spans viewable from Dynatrace, including which iteration the self-correction loop passed on and that the fix was grounded in real incident data.
What we learned
The institutional memory angle matters more than it looks. A system that lowers its own risk score when a team has deliberately chosen not to fix a pattern is fundamentally different from one that flags the same thing on every scan. Every developer interaction makes the next scan more accurate. That compounding behaviour is what separates a tool from a product.
AI-assisted development is making this problem worse, not better. AI coding agents reintroduce optimistic, happy-path code that only fails in production. A system grounded in real incident history is the natural corrective, which is what is done here.
What's next for Ripple
GitHub support is the natural next step. The Intelligence service is also not coupled to Dynatrace specifically: any observability platform that exposes incident history over MCP could ground the same pipeline.
Built With
- dynatrace-mcp
- fastapi
- gemini-3-flash
- gitlab
- gitlab-rest-api
- google-adk
- google-cloud-run
- mongodb-atlas
- next.js
- opentelemetry
- python

Log in or sign up for Devpost to join the conversation.