-
-

LLM Chatbot for VCT Hackathon
Inspiration
Our inspiration came from our early days of grinding League of Legends and Valorant. Being an esport player has been our dream since young, but we did not receive any supports from our parents to pursue our dream. However, we have atteneded AI Major in our Uni, hence we decided to particiapte in this hackathon to leverage AI skills with Esports knowledge to contribute in the Esport field speciacally Riot Games!
What it does
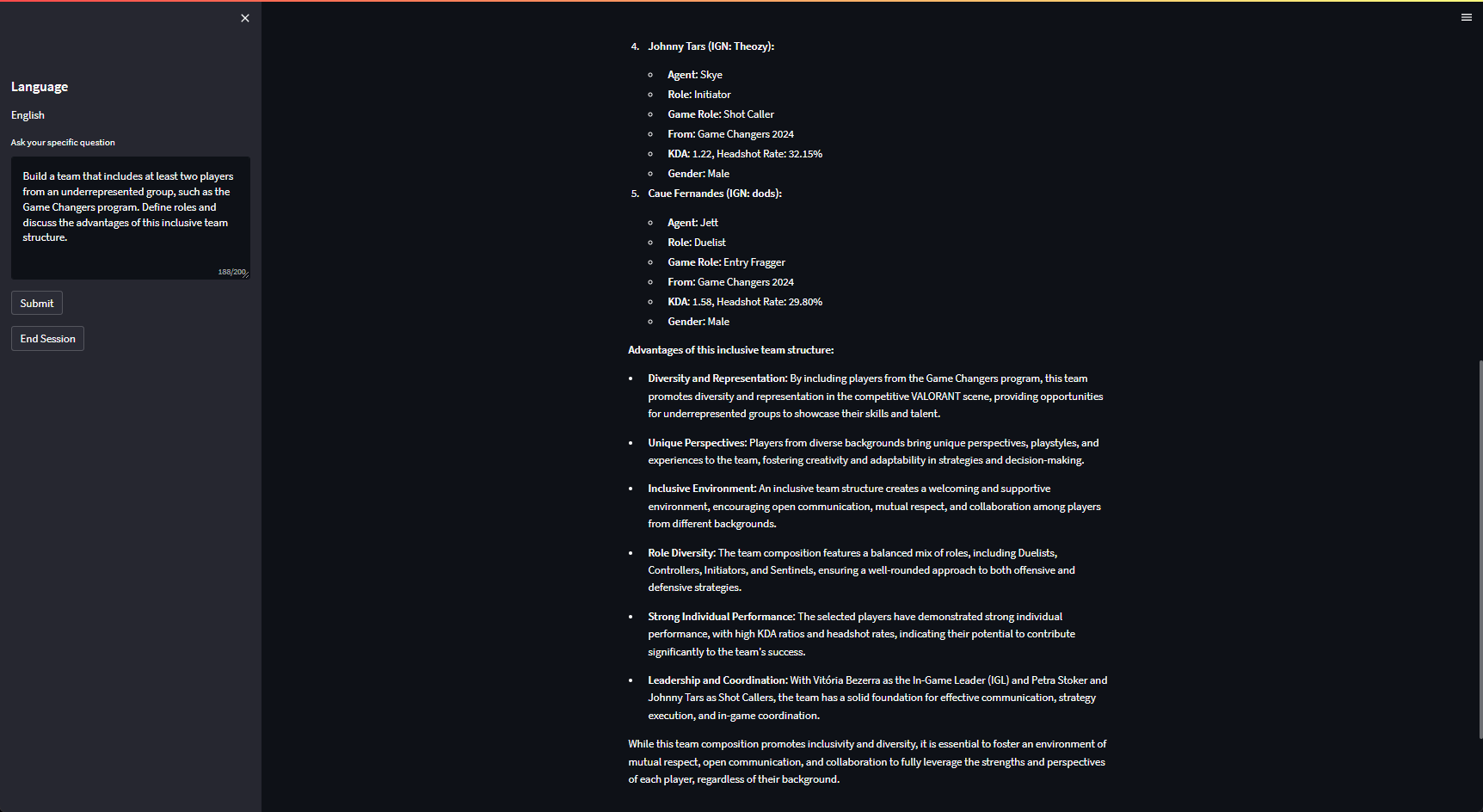
Our project involves creating a personalized LLM-powered digital assistant for scouting and recruiting VALORANT players. The chatbot uses AWS OpenSearch for data retrieval, SageMaker for embedding, and AWS Bedrock for generating AI-driven insights. Users can generate team compositions, assign player roles, and gain strategic insights based on in-game data. The assistant provides role suggestions, team leader assignments, and justifications for the team’s effectiveness based on past player performances. (LLM responses take around 30second to 1 minutes based on user query complexity)
How we built it
- Data Preprocessing: We used SageMaker to map data into readable events appended with Valorant-specific terminology.
- Data Retrieval: AWS OpenSearch KNN embeddings were used to retrieve relevant player data based on user queries.
- Team Composition: The assistant supports creating teams from different categories such as pro, semi-pro, or cross-regional setups.
- Player Role Assignment: In-game roles are assigned to players (e.g., duelist, sentinel) based on historical performance, agent choice, and playstyle.
- Strategic Insights: The assistant provides team strategy suggestions, explaining offensive and defensive roles, leadership assignments, and agent-specific contributions.
Challenges we ran into
- Data Processing: Handling large datasets from game histories required an efficient data pipeline, especially when converting raw data into actionable insights.
- OpenSearch Integration: Integrating OpenSearch's KNN for embedding and fast retrieval while keeping costs low was challenging.
- AWS Bedrock Utilization: Finding the most cost-efficient model for large language models (LLMs) required experimentation, particularly balancing cost and availability.
- LLM Uncertainty: The large language models (LLMs) is unable to follow our context even after tweaking the temperature.
- LLM Throttling Issues (Solved): The large language models (LLMs) in some region has this issues, we changed our model into Anthropic Claude 3.0 Sonnet in London Region (eu-west-2) after several try in AWS Bedrock's Playground, then it works perfectly fine without throttling issues.
Accomplishments that we're proud of
- Successfully building an end-to-end AI assistant that scouts VALORANT players and provides actionable strategic insights.
- Optimizing the pipeline to work within AWS's cost structure, utilizing services like OpenSearch, S3 and SageMaker.
- Implementing real-time, data-driven team composition recommendations and role assignment features, enhancing decision-making for coaches and managers.
- Provides the most cost efficient workflow without web scrapping from VLR.gg, Fine-Tuning and uses extensive agent.
- LLM has Generative AI capabilities to identify user prompt category and able to provide the most suitable response based on context.
- LLM has memory of previous conversation histories now, it can answers all the main and follow up prompt in the same session.
- LLM is able to answer majority of players outside of the team recommendation for recent statistic and performance.
- LLM is able to answer user query provided by devpost with difference sentence structure and synonyms for vocab, as it understand the semantic meaning of the sentence, instead of matching the keyword.
- LLM now answers in constance formatting and no duplicate agent or roles will appear when recommending the team as it is able to follow my predefined context and instruction.
- LLM is more user friendly with extra button for "end session" for starting a new session, with debug line of workflow being removed (you can view the debug line in our youtube demo for first prompt!)
- Cost: Sagemaker + LLM (Anthropic Claude 3.0 Sonnet) + OpenSearch (r7g. medium with 3 nodes), LLM Cost: Around $0.024 per 100 prompt (input + output tokens) OpenSearch Cost: Around $4 per day.
What we learned
We learned a lot about deploying scalable AI-driven applications in the cloud, especially when working within AWS's cost constraints. Integrating different AWS services like SageMaker, OpenSearch, and Bedrock taught us how to manage data efficiently while ensuring fast retrieval times and maintaining accuracy in LLM responses.
What's next for Riot Games LLM by Yan and Weng Hou
The next step would be to refine the LLM's understanding of VALORANT gameplay further by incorporating more diverse datasets, adding more complex query capabilities, and improving the strategic suggestions the assistant provides. We have already expanded the tool's scope to include more esports titles and features such as predictive analytics for player performance and team outcomes.
Built With
- amazon-web-services
- langchain
- opensearch
- python
- s3
- sagemaker
- streamlit



Log in or sign up for Devpost to join the conversation.