-
-
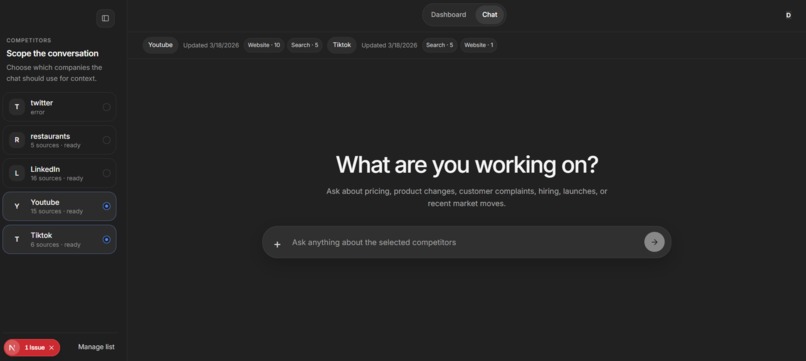
chat
-
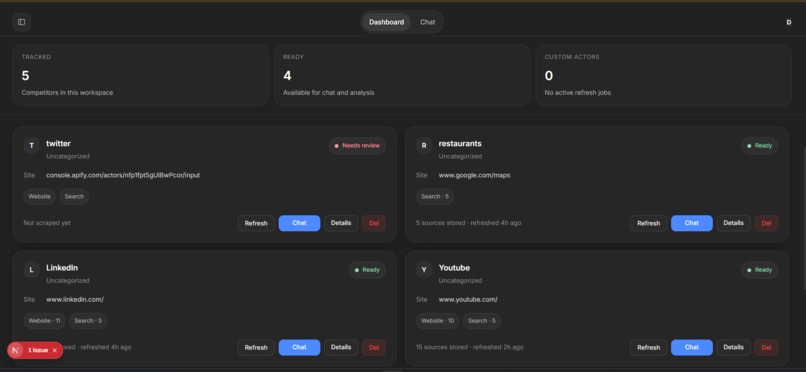
Dashboard
-
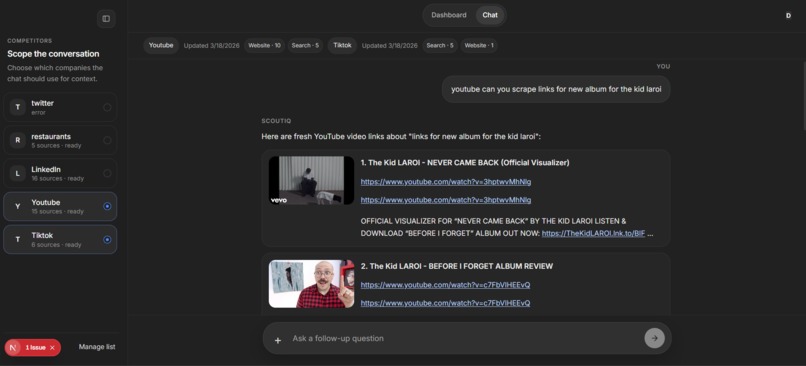
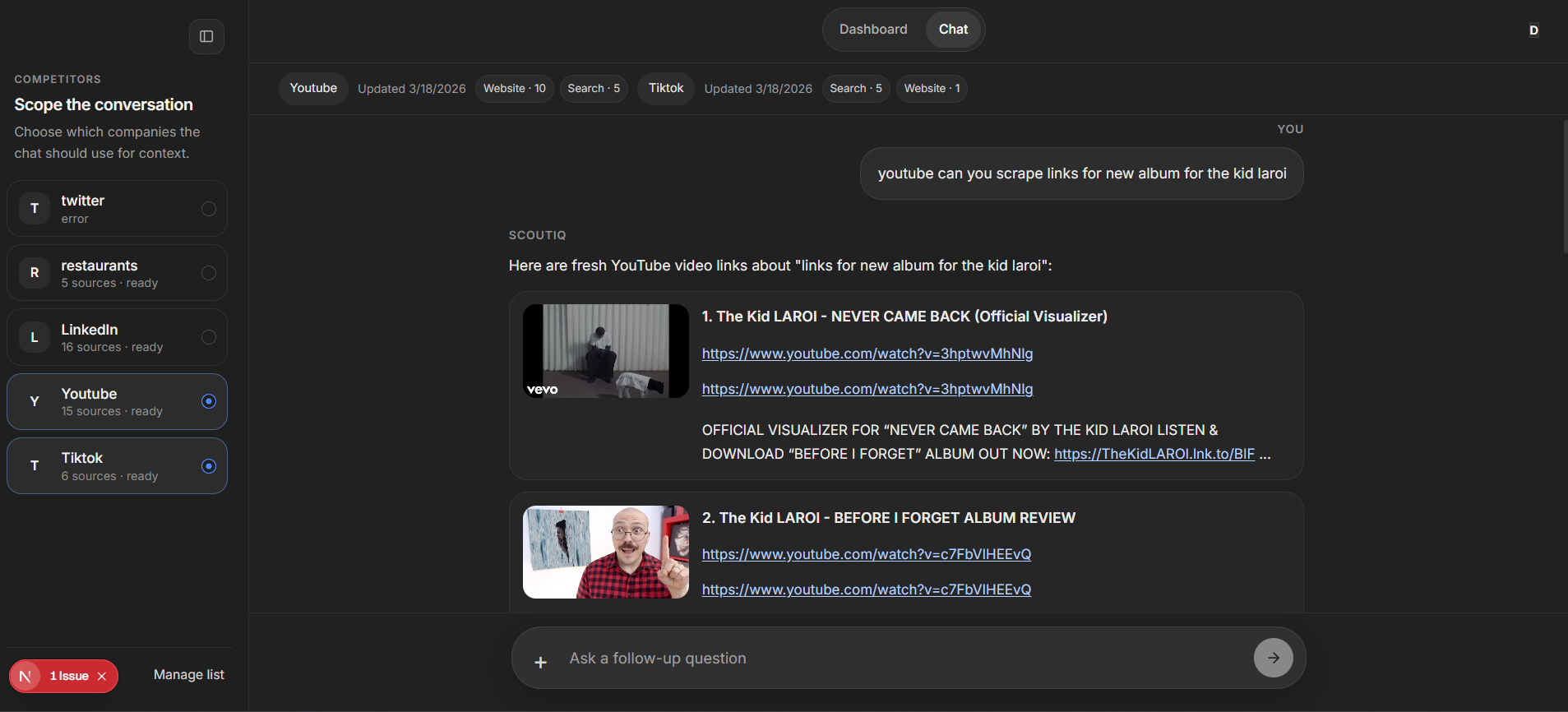
chat: scraped the links of the kid laroi album
Inspiration
AI applications are only as useful as the data they can access. I wanted to build a product that shows the value of live web data in a clear business workflow: track competitors, collect fresh public information from the web, and turn it into usable intelligence inside one interface. The Apify challenge was a strong fit because ScoutIQ depends on live collection rather than static datasets.
What it does
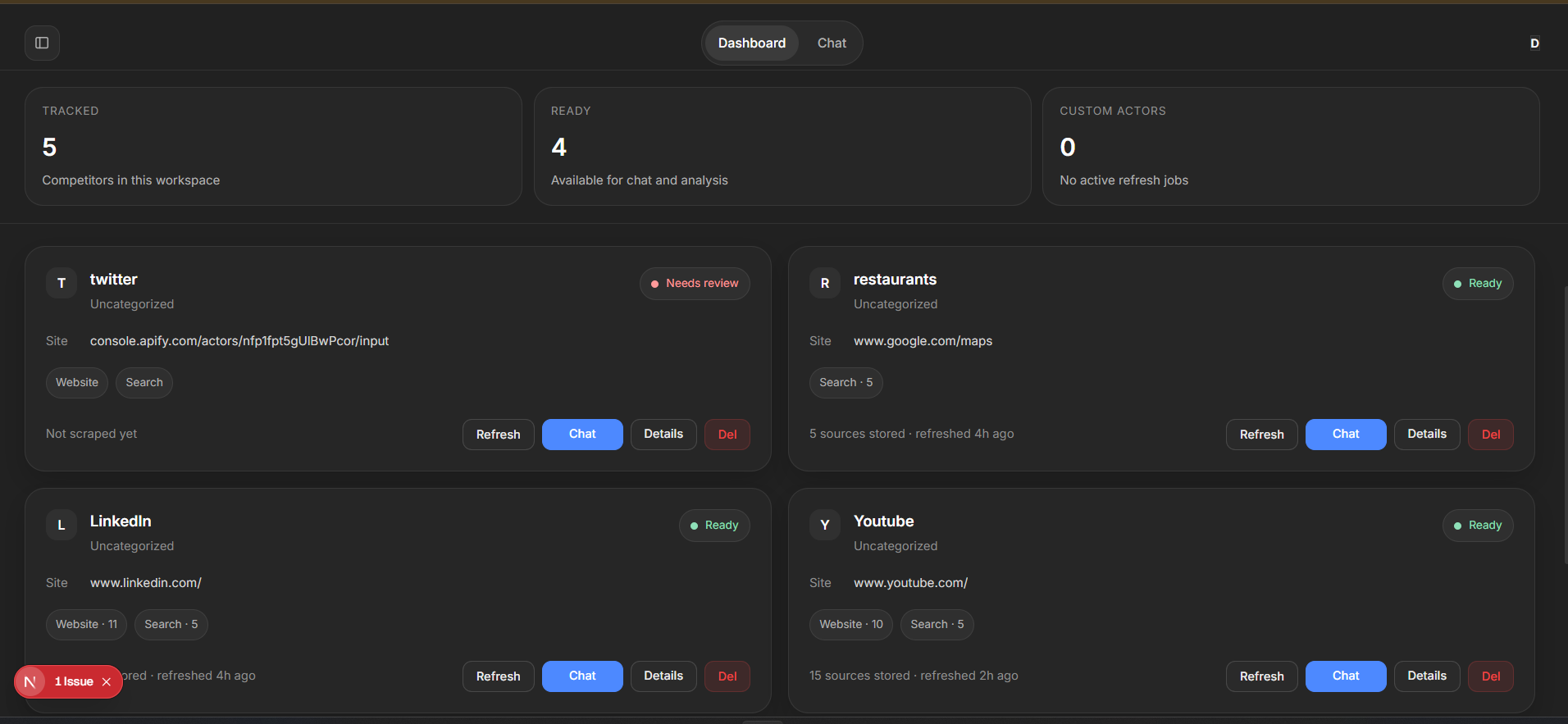
ScoutIQ is a competitive intelligence workspace powered by Apify. Users add competitors, connect their websites, and collect live data through Apify Actors. That data is stored, organized, and made available inside a dashboard and chat workflow. Users can refresh competitors, inspect source coverage, review recent collected pages, and ask focused questions about a single competitor or a selected group. For link-heavy queries, such as YouTube video searches, ScoutIQ can return fresh links in a structured format instead of generic summaries.
How we built it
I built ScoutIQ with Next.js, TypeScript, Better Auth, Drizzle ORM, and PostgreSQL. Apify is the core live data layer of the system. I use Apify Actors for website crawling, search-based collection, and domain-specific scraping paths where generic crawling is not enough. I added support for default crawlers, per-domain Actor routing, per-competitor custom Actors, and search fallback when a website crawl is blocked or fails. On top of the collected data, I use an OpenRouter-backed Mastra agent to answer questions in chat. The system can also fall back to keyword-based retrieval if embeddings are unavailable, which keeps the product usable under real hackathon constraints.
Challenges we ran into
One major challenge was handling the reality of live web-data systems: different websites require different collection strategies. A single generic crawler is not enough, so I had to support domain-specific Actor routing and fallbacks. Another challenge was reliability under API quota limits. I ran into OpenRouter and OpenAI quota constraints, which forced us to harden the product, reduce generation budgets, improve failures, and support fallback retrieval paths. I also spent time improving trust and usability by showing real source coverage, scrape status, and structured output instead of opaque AI responses.
Accomplishments that we're proud of
I are proud that Apify is not just “used somewhere in the backend” but is central to the product itself. ScoutIQ clearly demonstrates live collection through Apify, domain-specific Actor usage, fallback search collection, and a workflow where collected web data directly powers analysis. I are also proud of the product polish: a responsive dashboard, a clean chat interface, structured outputs, YouTube-specific link retrieval, source transparency, and competitor detail views that show real collected records and source breakdowns.
What we learned
I learned that building with live web data requires strong orchestration and fallback behavior, not just scraping. The product needs to remain useful even when a site is difficult, when quotas are low, or when one retrieval path fails. I also learned that users trust results much more when the system makes collection visible: source types, refresh status, recent pages, and supporting links all matter. Apify made it possible to focus on product and workflow rather than spending the entire project building raw scraping infrastructure from scratch.
What's next for ScoutiQ
The next step is to deepen the Apify integration even further. I want to surface Actor-level run details directly in the UI, expand domain-specific Actor support, add exportable competitor briefs, and package the collection workflow as a stronger reusable Actor-style deliverable. I also want to improve answer-level citations and change tracking so users can see not just what was collected, but what changed over time.
Built With
- apify
- auth
- better
- drizzle
- mastra
- next.js
- openrouter
- orm
- postgresql
- react
- typescript

Log in or sign up for Devpost to join the conversation.