-
-
Homepage
-
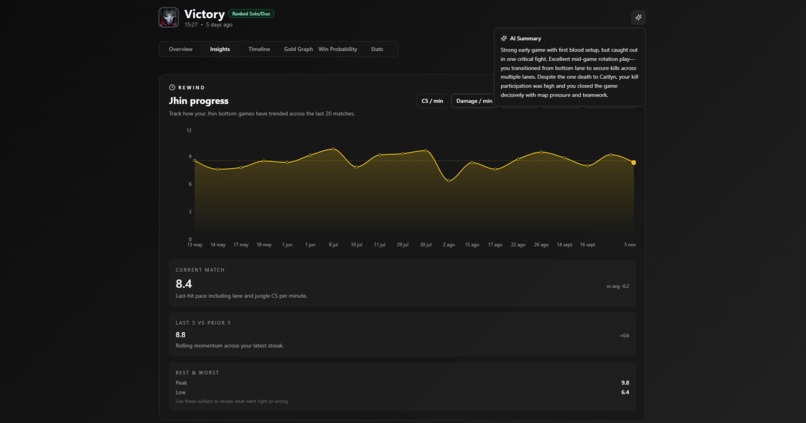
Match comparison
-
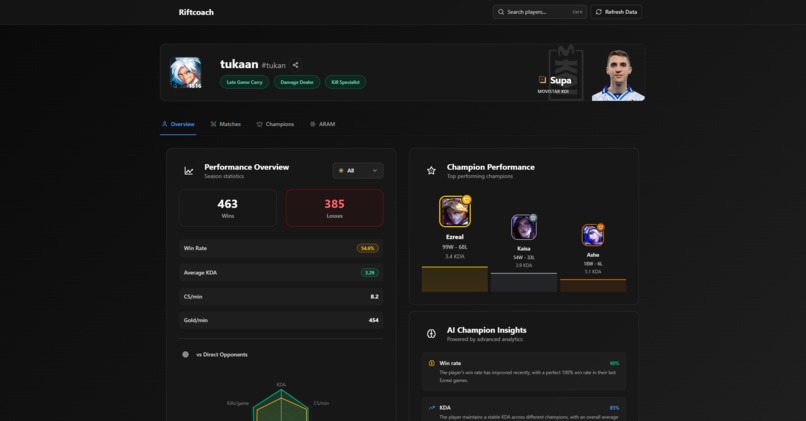
Profile
-
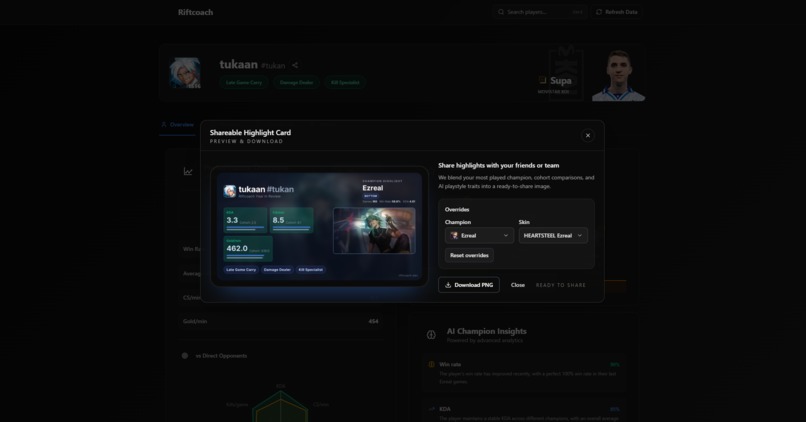
Share card
-
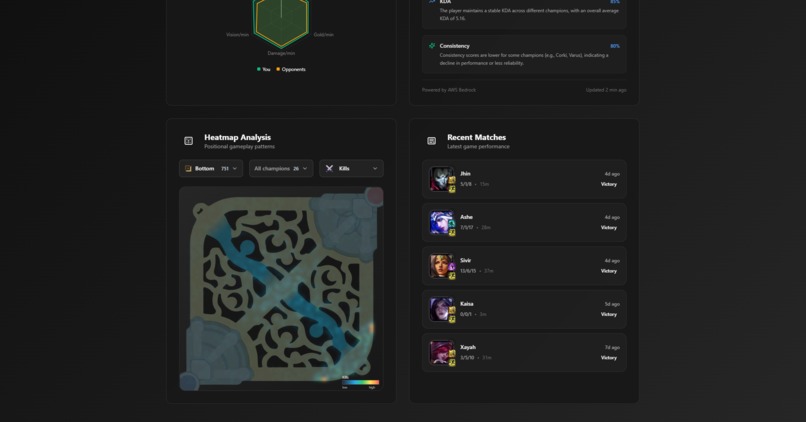
Heatmap
-
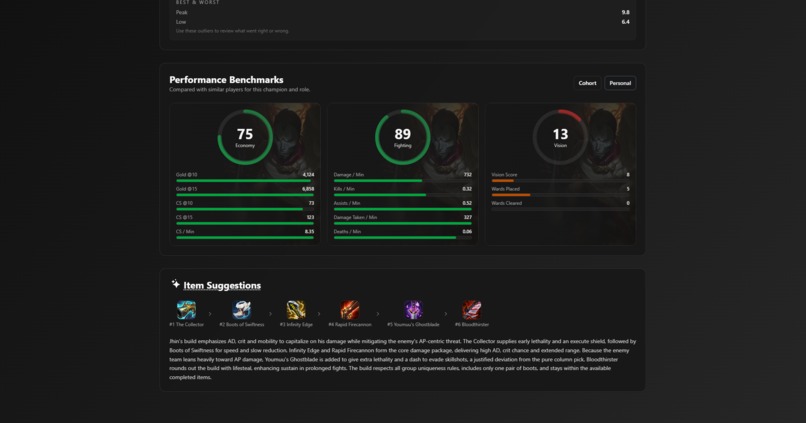
Match insights
-
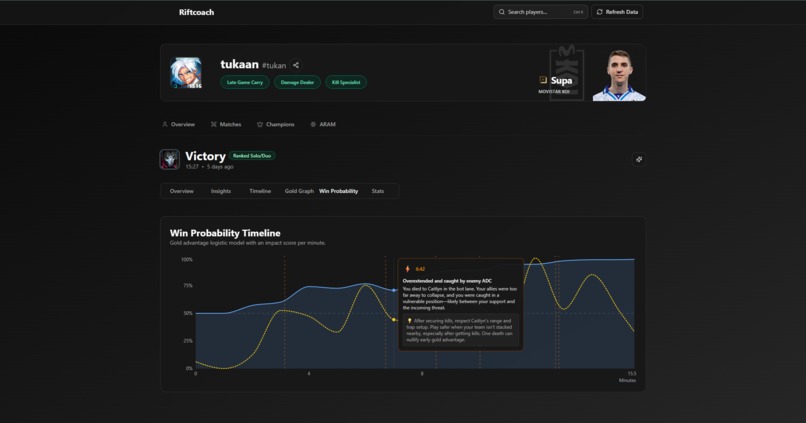
Win probability + key moments
-
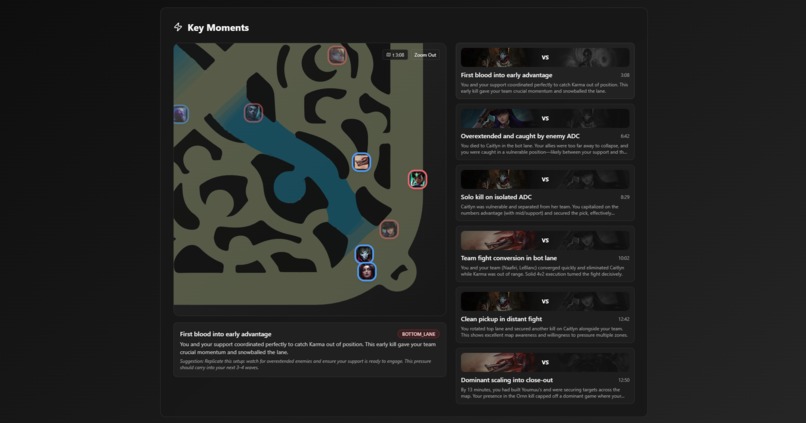
Match key moments
-
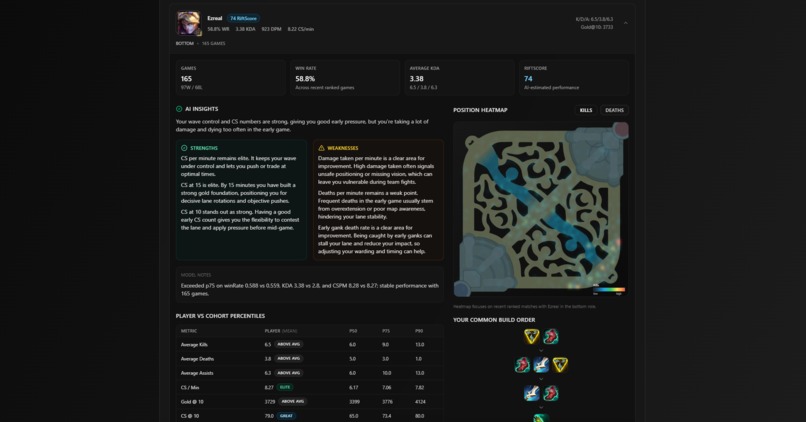
Champion insights
-
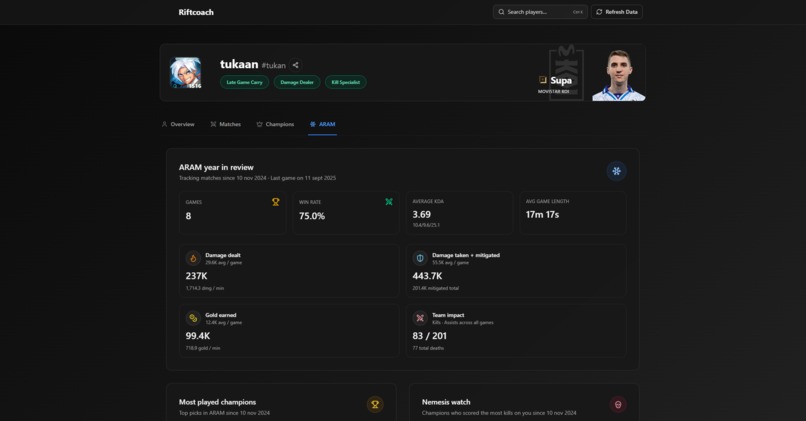
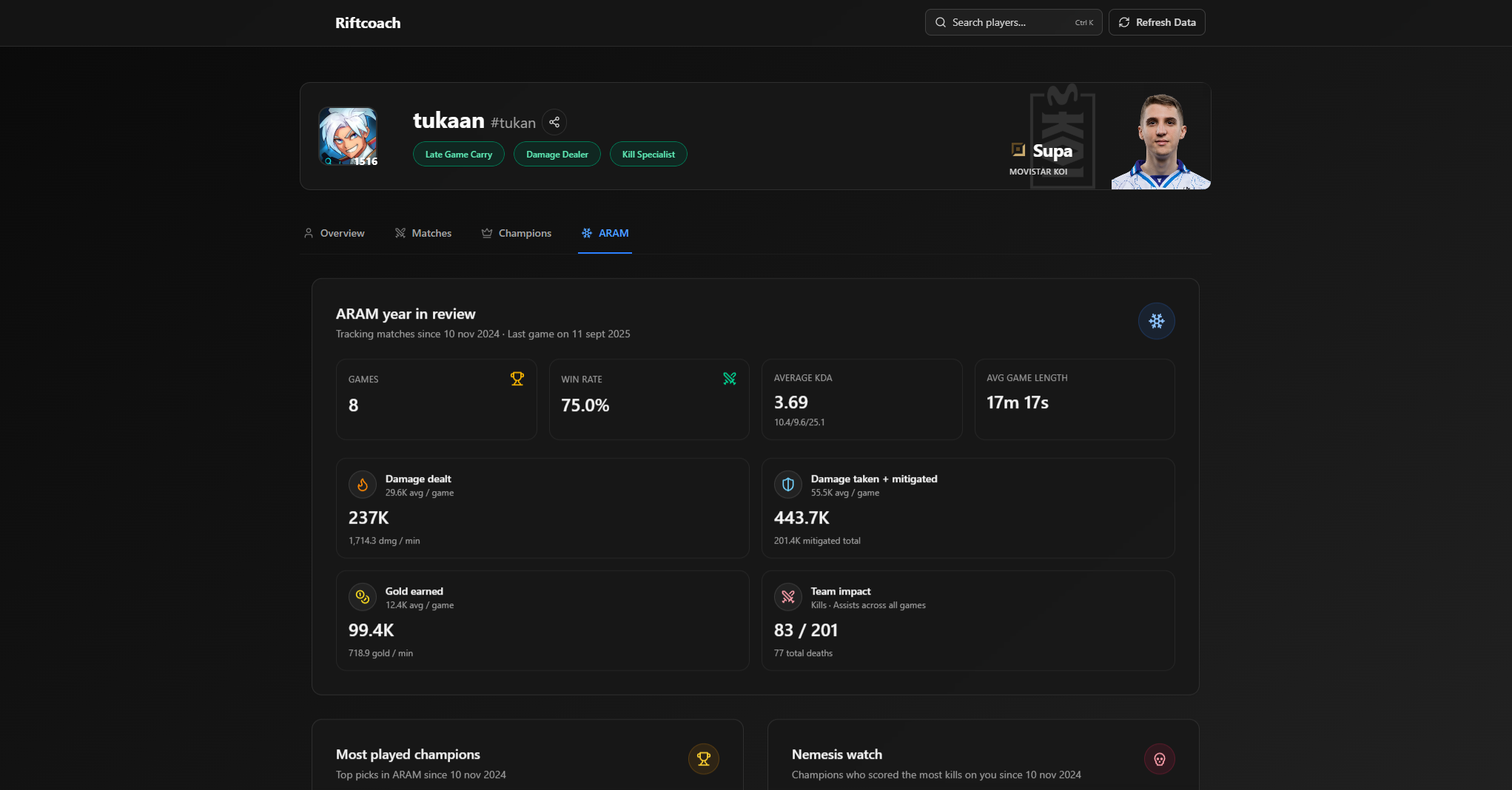
ARAM Stats
-
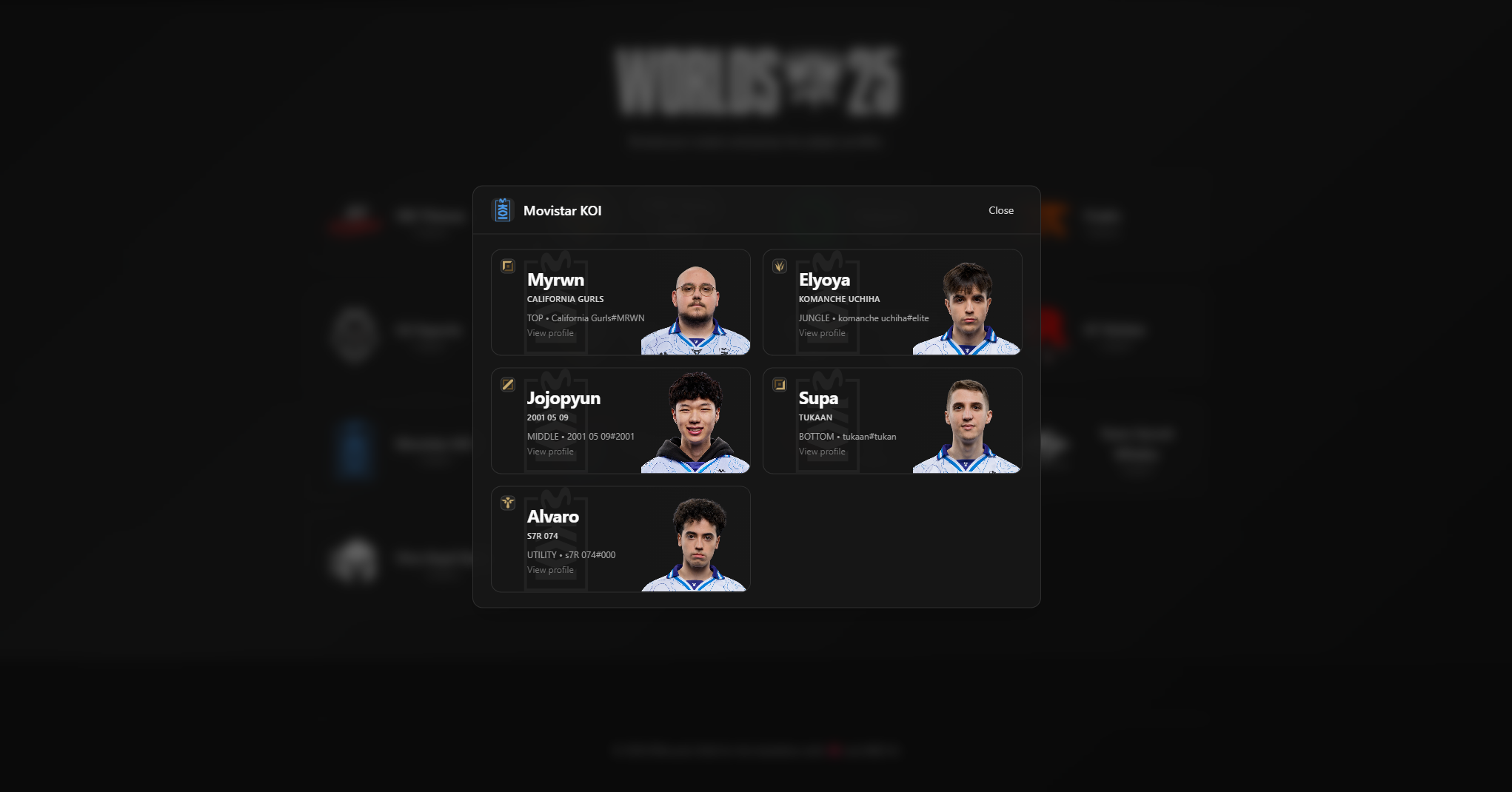
Worlds 2025 players popup
Inspiration
I drew inspiration from existing League of Legends analytics platforms like op.gg and dpm.lol. While using these tools, I often found myself wishing for additional insights or features—so I decided to build them myself. RiftCoach is designed to go beyond simple statistics, offering deeper analysis and personalized insights based on a player’s yearly data.
What it does
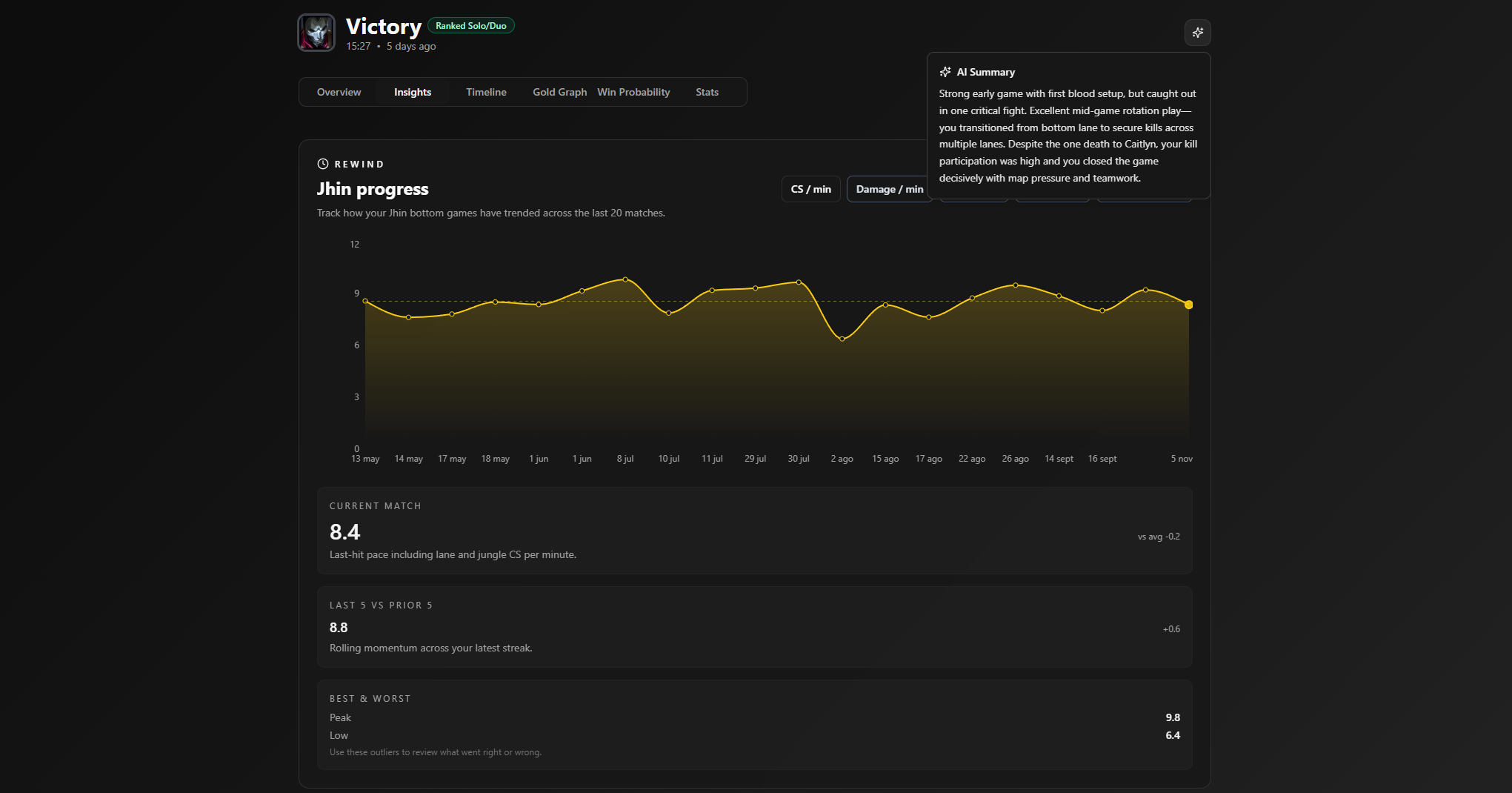
RiftCoach analyzes an entire year of match data for a given player and turns it into detailed insights about their playstyle, role performance, champion tendencies, and key match moments.
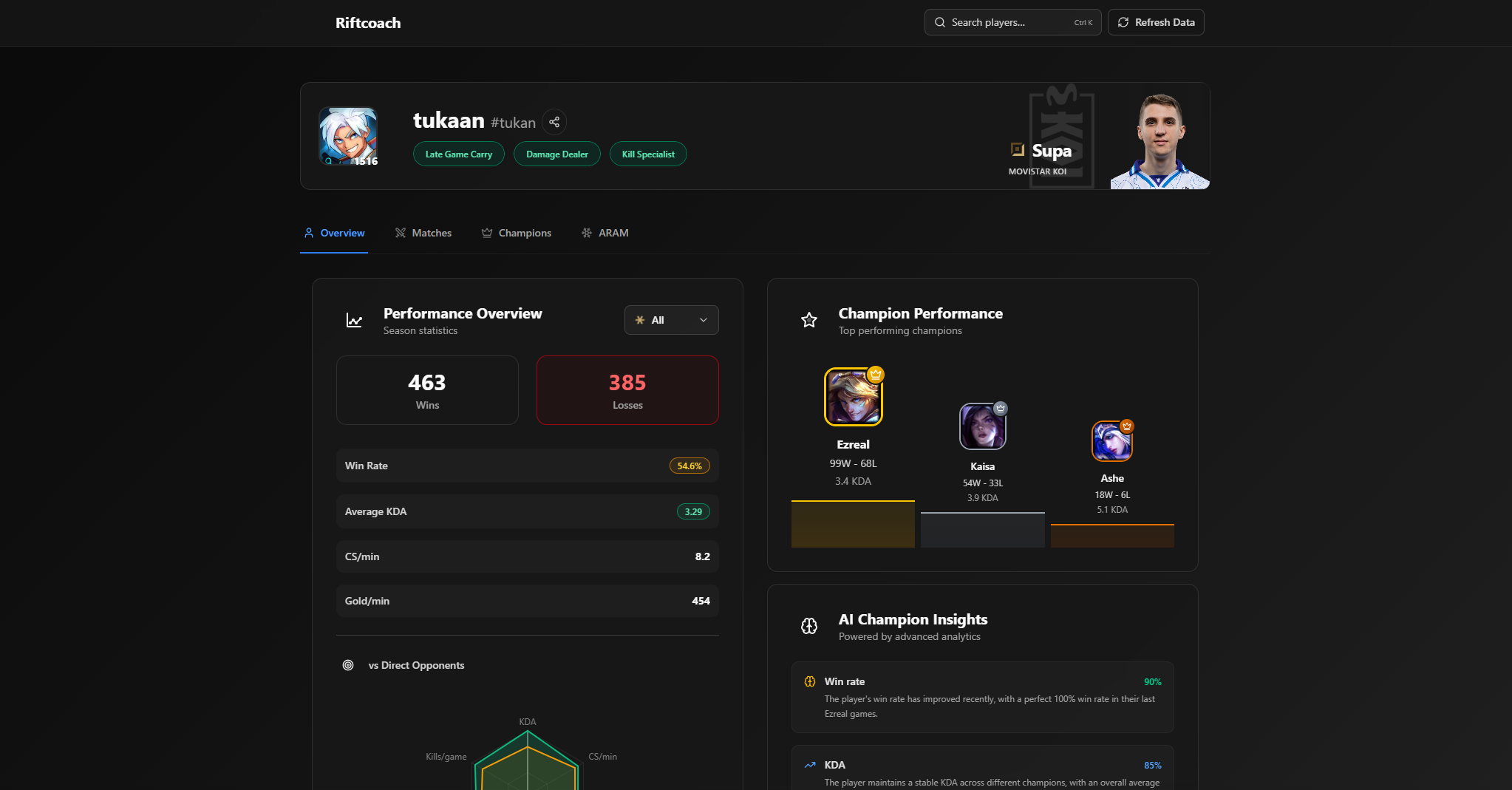
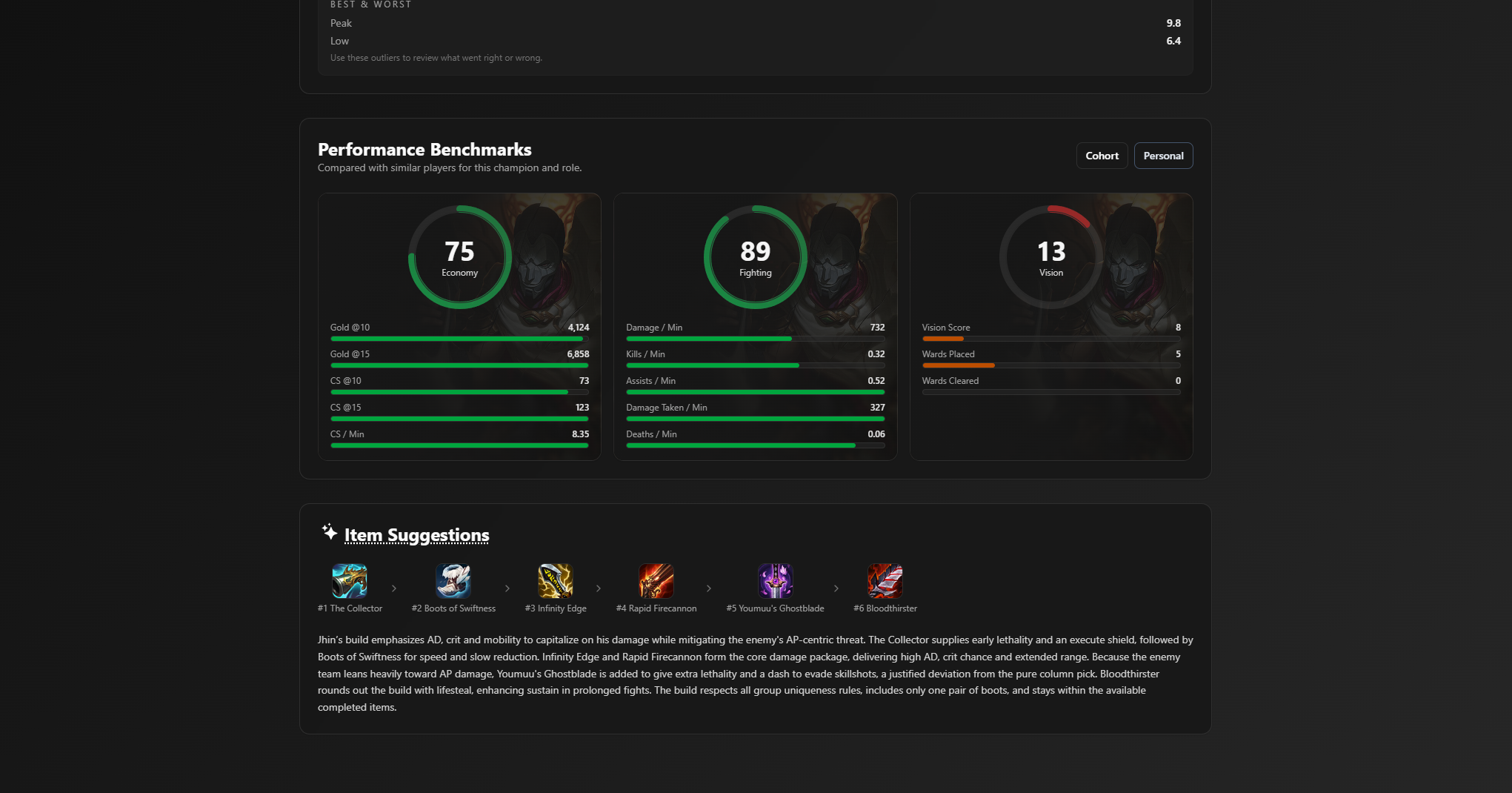
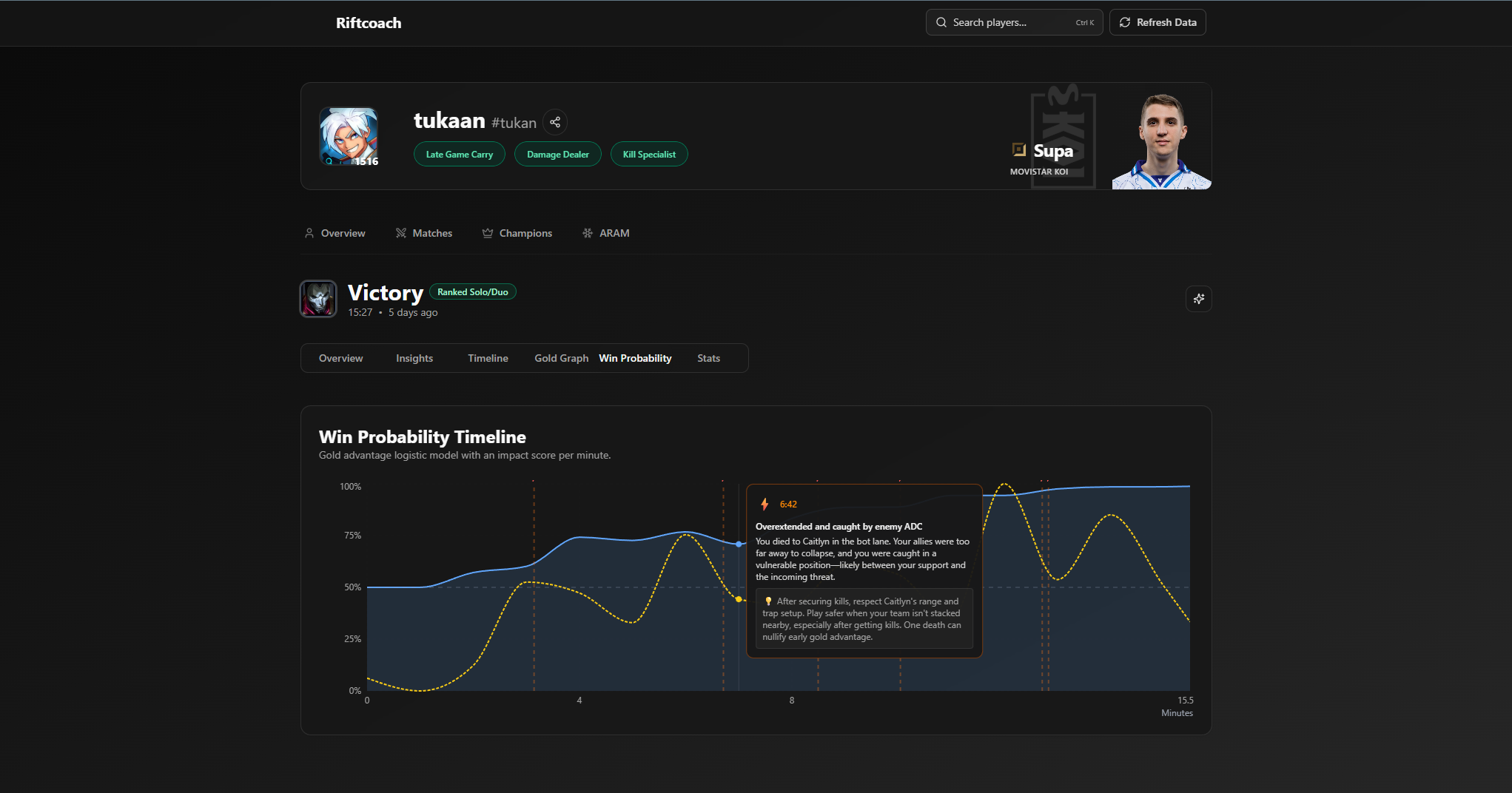
Profile Overview
- Playstyle badges that summarize a player's approach to the game
- Role-based comparisons against direct lane opponents
- Champion-specific insights and trends
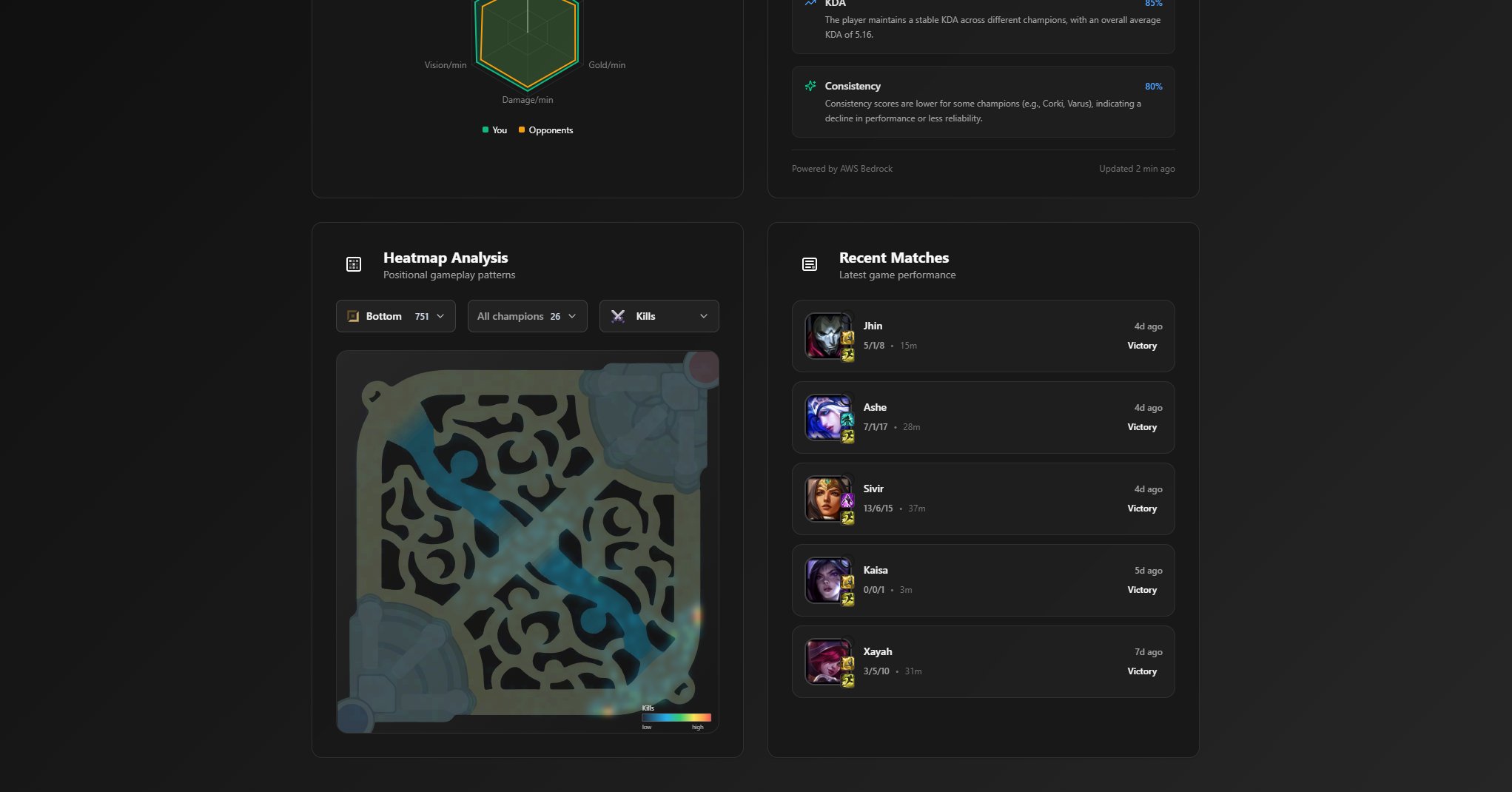
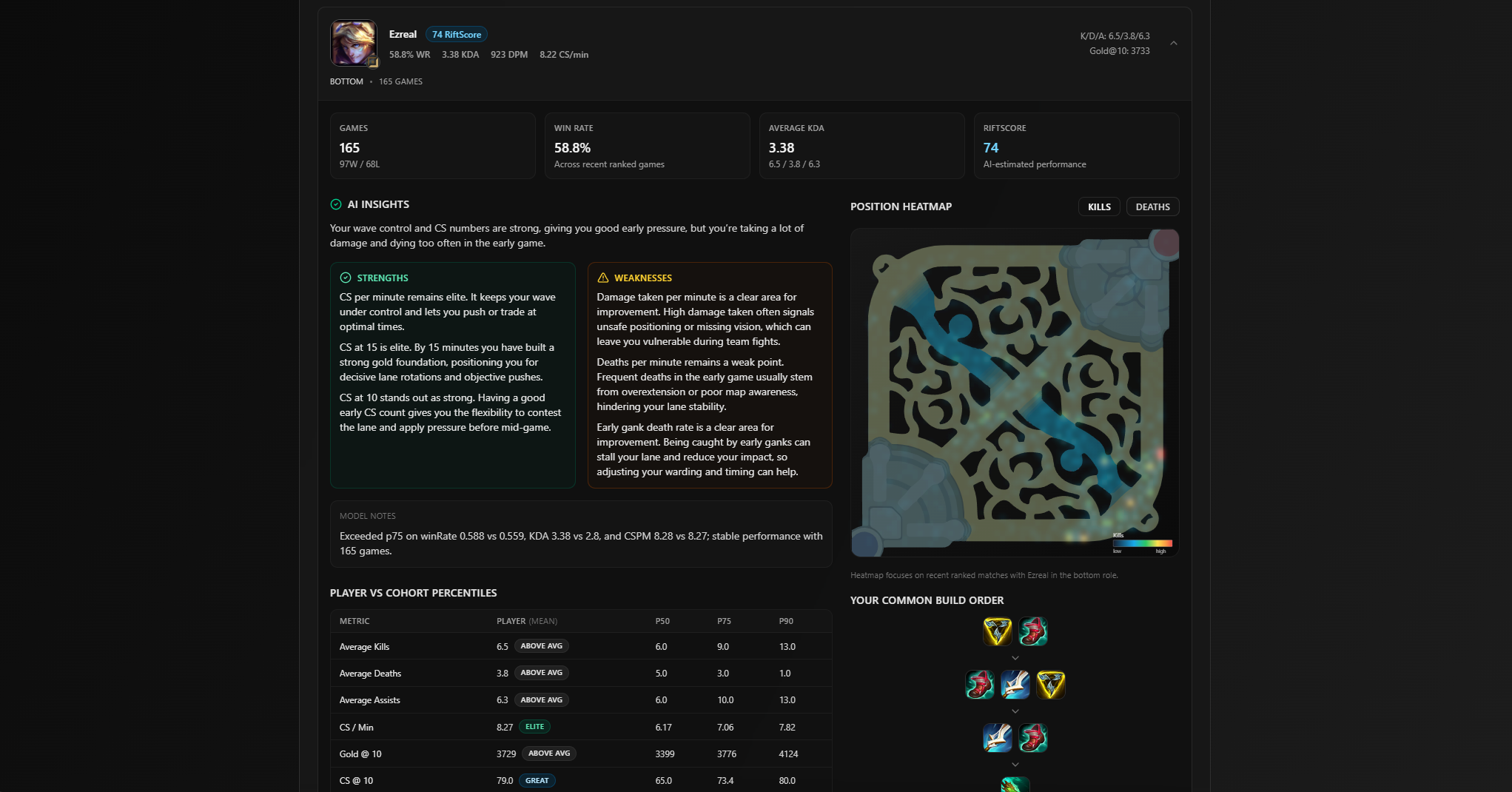
- Kills/deaths heatmaps for positional awareness
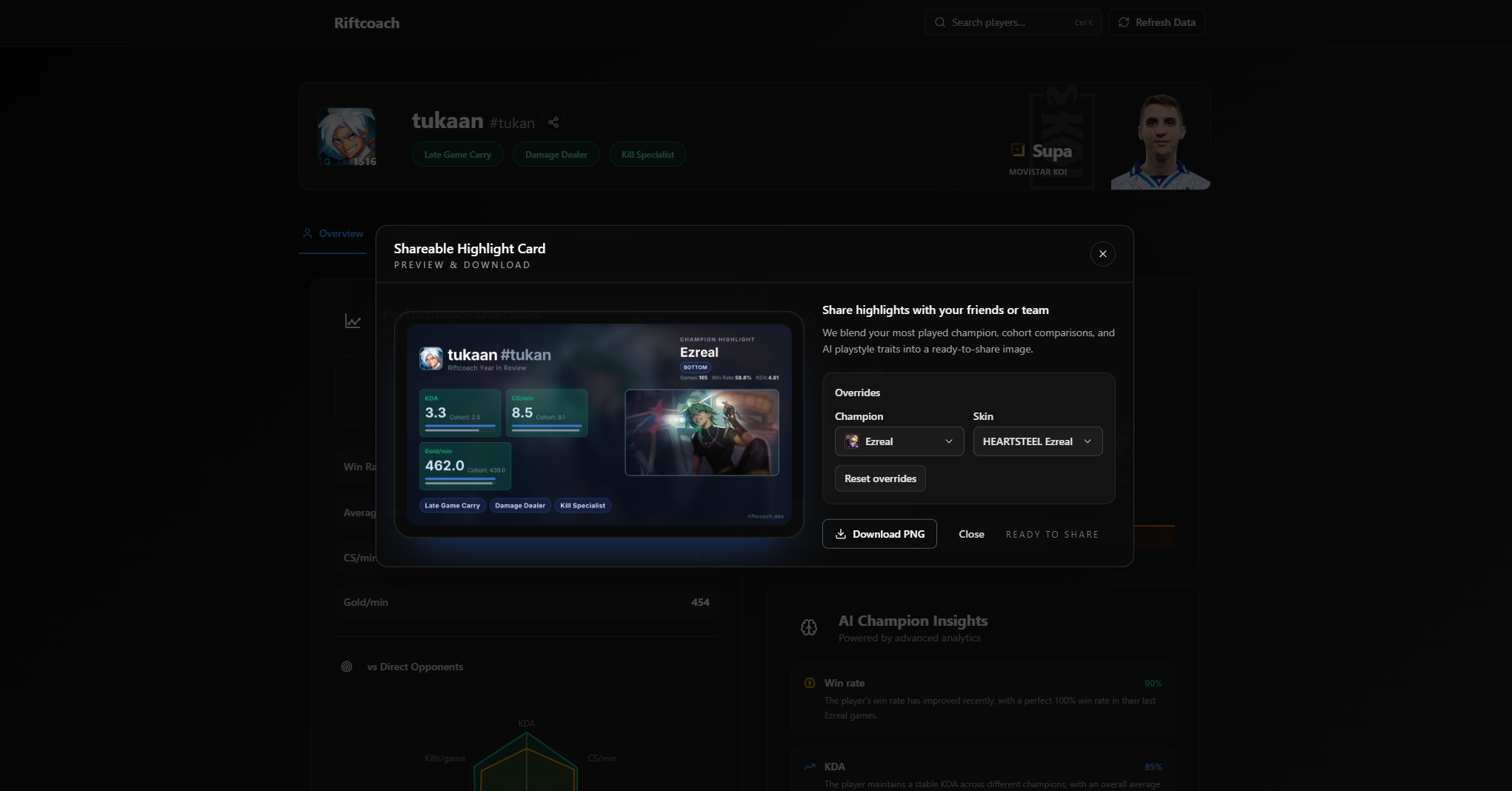
- Shareable profile cards with highlight stats
Champions
- Individual playstyle scores
- Strengths and weaknesses per champion and role
- Statistical comparisons using cohort-based percentile data
- Common and effective build paths
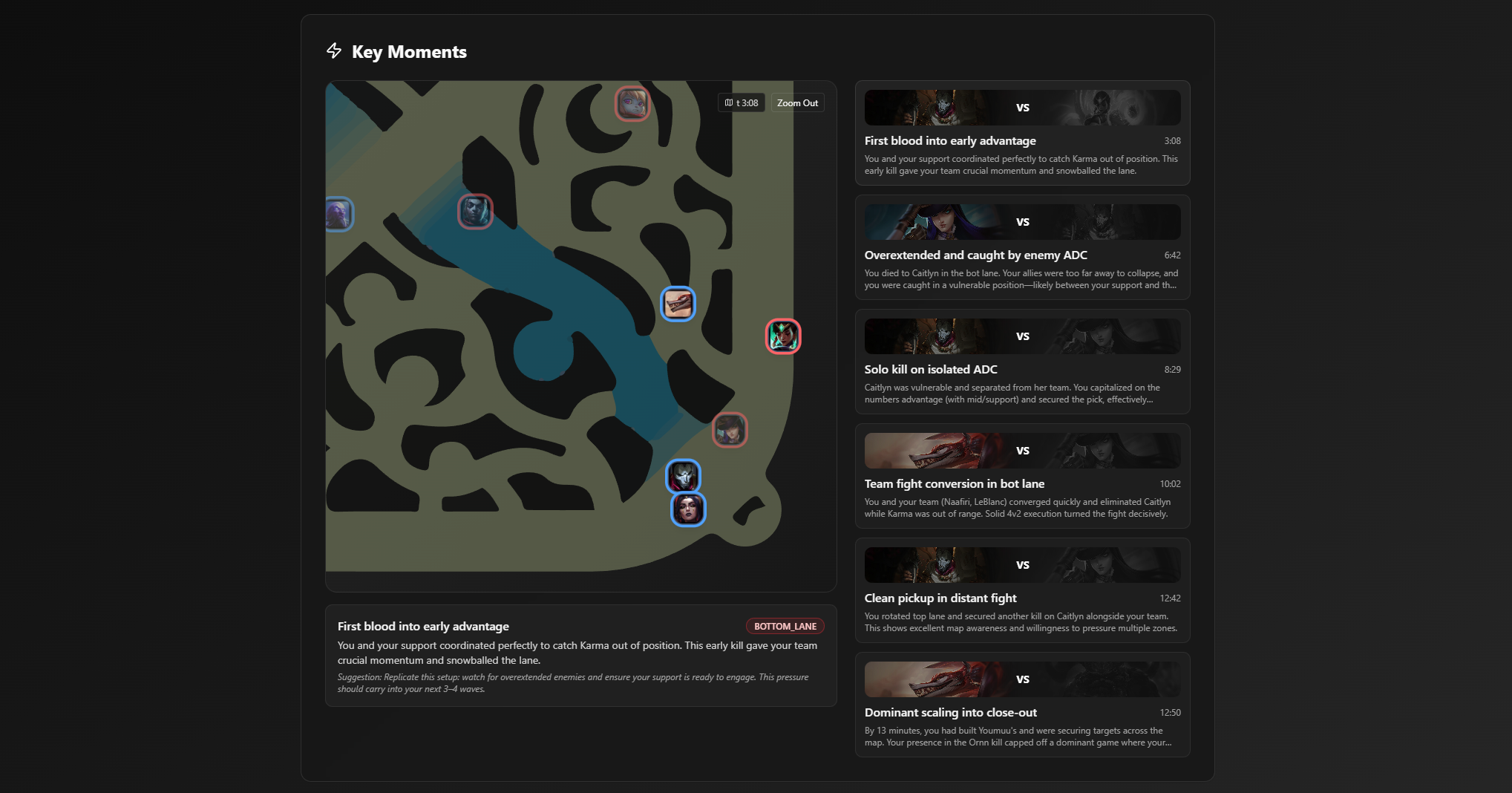
Matches
- Suggested build paths based on ally/enemy compositions and damage profiles
- Identification of key turning points and impactful moments
How we built it
- Processing architecture: The app is powered by BullMQ, with one queue per regional cluster to handle scans in parallel.
- Data layer: MongoDB is used for storing and querying matches and timelines efficiently through aggregation pipelines.
- API: Built with Hono for fast, lightweight routing.
- AI integration: Different models are used depending on complexity. Mistral models handle quick, structured insights, while Claude Haiku from AWS Bedrock powers deeper reasoning for match-specific analysis.
Challenges we faced
API rate limits: Each match and timeline requires multiple API calls, which can quickly hit rate limits. To manage this, I implemented a queue-based system that schedules scans per region to avoid overload.
AI precision and context: Working with AI models for the first time taught me that success depends heavily on well-structured prompts and context management—models only perform well when given exactly the right data.
Tool limitations: Initially, I tried using AI tools to automatically retrieve item data from DDragon for build recommendations. However, context window limits and API rate restrictions made this inefficient, so I switched to embedding item metadata manually into the model context.
Athena + S3 costs: In early experiments, I used Athena for large-scale data aggregation, but due to my limited SQL experience and high S3 query costs, I transitioned to MongoDB, which proved simpler and more cost-efficient for my use case.
Accomplishments
Per-cluster queue system
By distributing workloads per cluster using BullMQ, the app can scan multiple regions (e.g., EUW and KR) simultaneously without blocking. This design makes the system scalable and prevents bottlenecks across regional workloads.
Direct opponent comparisons
With limited time and data volume, I focused on comparing players to their direct lane opponents instead of rank-based cohorts. This approach still provides meaningful insights into player performance while keeping the system efficient.
What we learned
- Integrating AI models through AWS Bedrock
- Optimizing MongoDB aggregation pipelines for performance
- Designing effective AI prompts and managing contextual data
What's next for RiftCoach
After the hackathon, I plan to request a production-level API key to increase request limits and gather data more efficiently. This will allow me to expand the system with ranked-based cohorts, improving accuracy for champion and role comparisons, and making insights even more personalized.
Built With
- hono
- mongodb
- react
- tanstack
- typescript

Log in or sign up for Devpost to join the conversation.