-
-

Rift Trivia Icon
-
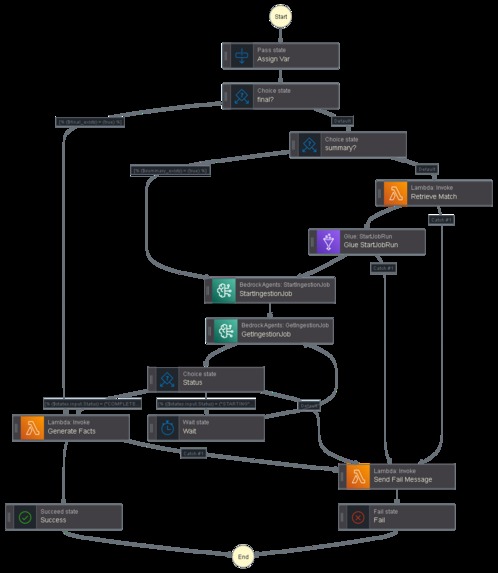
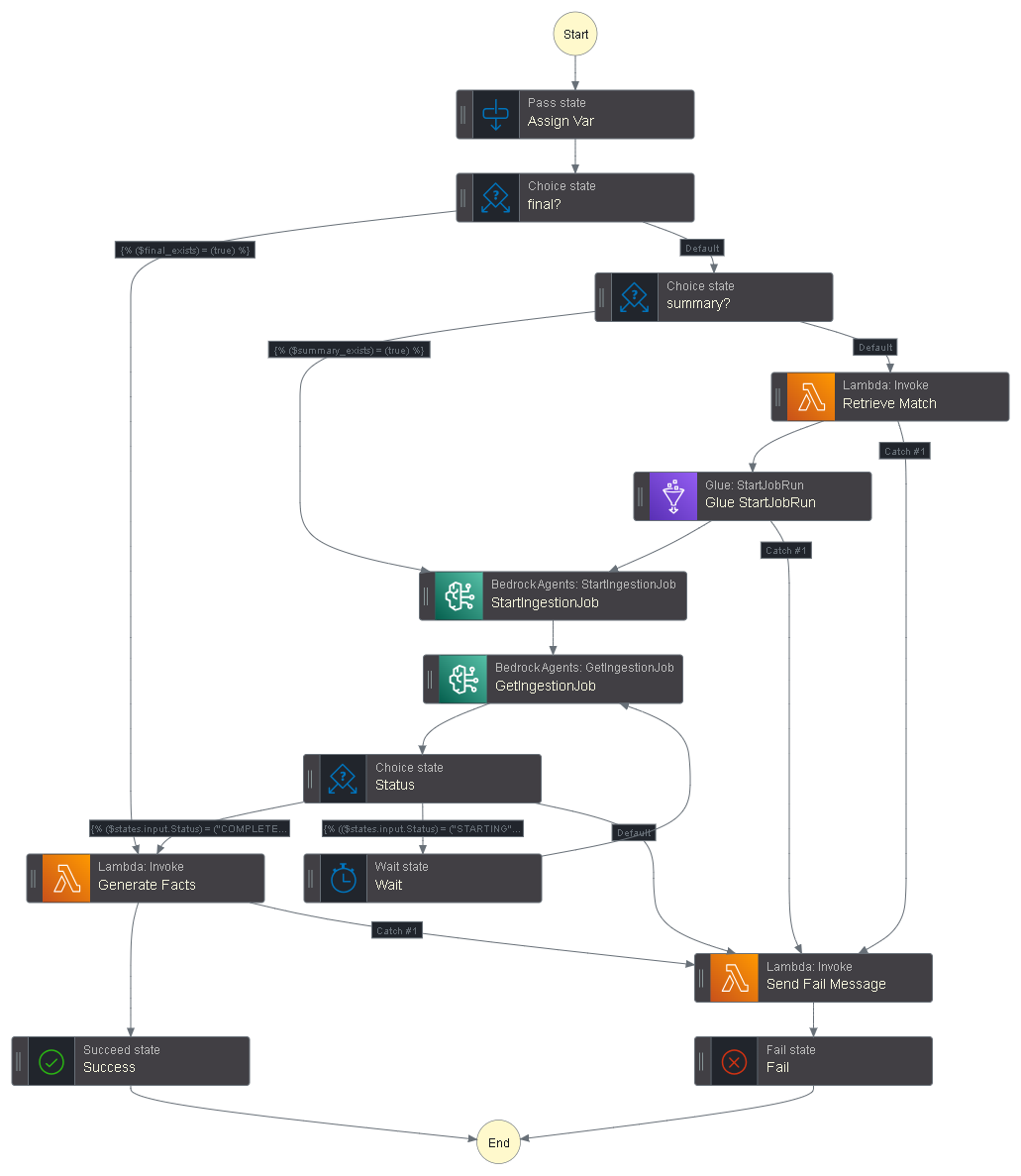
AWS Step Functions Graph

Inspiration
As a long-time League of Legends player, I’ve always enjoyed reflecting on my journey each year — from my best plays to the champions I’ve mastered. When I tried YearIn.LoL, I thought it was a nice way to relive my past games, but I noticed that most players received a very similar experience.
The summary followed a fixed format, with only a few variations, so my personal journey didn’t really feel unique — it felt like everyone was getting the same story.
That’s where the idea for Rift Trivia began — to create something more personal and interactive. I wanted a recap that didn’t just show stats but let each player engage with their own story through AI-generated trivia and insights tailored just for them.
By combining data analysis, storytelling, and interactivity, I set out to build a League of Legends “year-in-review” experience that truly feels like yours — one that celebrates each player’s distinctive journey on the Rift.
What it does
Rift Trivia transforms your past year of League of Legends gameplay into an interactive, personalized trivia experience.
Players simply enter their Riot ID, and the system retrieves and processes their match data. Then, using AI and knowledge base integration, it generates a series of custom trivia questions and fun facts that reflect the player’s own stats, habits, and highlights.
You can:
- Answer questions about your champions, win rates, and game trends.
- Reveal the real data and witty in-universe commentary written in a Runeterran-inspired voice.
- Share your “Rift Trivia Card” — a stylized summary of your quiz results — with friends.
It’s part analytics, part storytelling, and part game — designed to celebrate each player’s unique year on the Rift.
How I built it
I built Rift Trivia as a solo developer, handling everything from the backend data pipeline to the frontend experience.
This project was designed to demonstrate how AI storytelling can be combined with data engineering to create personalized player experiences.
🧠 Architecture Overview
I designed Rift Trivia as a fully serverless, event-driven application to handle the scale and complexity of processing thousands of matches per user while keeping costs low.
Frontend (React + Vite)
- Tech Stack: React 19, Vite, Tailwind CSS v4, React Router v7, Framer Motion
- Key Features:
- Single-page application with smooth page transitions and animations
- Real-time WebSocket integration for progress tracking
- Responsive design with custom Riot Games-inspired theming
- Share card generation using
html-to-imagefor social media - Session storage for seamless navigation between Landing → Progress → Insights pages
Backend (AWS Serverless)
- Lambda Functions (5 total):
call_riot_api: Resolves Riot IDs to PUUIDs, checks S3 for cached datatrigger_step: Initiates Step Functions workflow, prevents duplicate executionsretrieve_match_data: Paginates through Riot API to fetch and store match historygenerate_facts: Uses AWS Bedrock Knowledge Base for RAG-powered fact generationsend_fail_message: Handles error notifications via WebSocket
- AWS Glue ETL Job: PySpark script aggregates raw match data into player summaries
- Step Functions: Orchestrates the entire workflow (retrieve → process → generate → deliver)
- AWS Bedrock Knowledge Base: Vector search over player summaries using Amazon Titan embeddings and Claude 4 Sonnet for generation
- S3 Vectors: Serverless vector store (Bedrock-managed) for semantic search over player statistics without managing a separate vector database
- API Gateway WebSocket: Real-time bidirectional communication for progress updates
- S3: Data lake for match history, summaries, and generated facts
Data Flow Summary
User submits Riot ID → Lambda verifies player & triggers WebSocket connection.
Step Functions begin match retrieval and progress updates.
Once complete, Bedrock generates quiz data.
WebSocket returns final trivia results → rendered in the React dashboard.
Development Process
Initial Prototype: Started with a simple Riot API integration to fetch summoner data and champion mastery.
Data Pipeline: Built the ETL pipeline using AWS Glue to transform raw match JSON into structured player summaries with aggregated statistics (KDA, vision score, champion pools, role preferences, etc.).
AI Integration: Integrated AWS Bedrock Knowledge Base to enable semantic search over player summaries, allowing the AI to generate contextually relevant, data-backed trivia facts.
State Management: Implemented Step Functions to orchestrate the complex workflow, handling conditional logic (checking if data already exists, skipping unnecessary steps).
Real-Time UX: Added WebSocket streaming to keep users engaged during the long processing time, showing live progress as matches are retrieved and facts are generated.
Frontend Development: Iteratively refined routing/state flow, implemented resilient WebSocket progress streaming with staged percentage mapping, lazy‑loaded share card image export to shrink initial bundle, and designed the UX/UI and visual style.
Code Quality Refactoring: Replaced all hardcoded values with environment variables, and ensured the codebase is production-ready and shareable.
Challenges I ran into
Building this project solo meant learning and implementing many unfamiliar tools quickly.
Some key challenges were:
1. Riot API Rate Limits
Problem: Riot's API enforces strict rate limits (20 requests per second, 100 requests per 2 minutes). Fetching 200+ matches per player would frequently hit these limits.
Solution: Implemented exponential backoff and retry logic in the retrieve_match_data Lambda. Added incremental S3 storage so subsequent runs only fetch new matches, dramatically reducing API calls.
2. AI Output Parsing
Problem: Bedrock's model responses sometimes included markdown formatting, extra commentary, or malformed JSON, breaking the frontend.
Solution: Created a robust extract_json_array() function using regex to isolate JSON from model output, with fallback error handling. Also refined the AI prompt to explicitly request "pure JSON array only" output.
3. Step Functions State Management
Problem: The workflow needed to handle multiple conditional paths:
- If facts already exist → skip everything and return cached data
- If summary exists → skip match retrieval, only regenerate facts
- If nothing exists → full pipeline (retrieve → ETL → generate)
Solution: Used Step Functions Choice states with boolean checks against S3 existence flags passed from the initial Riot API call. This keeps the workflow logic declarative and easy to visualize.
Accomplishments that I'm proud of
- Successfully built a full-stack AWS-based AI application solo.
- Learned to integrate Lambda, Step Functions, Glue, Bedrock, and WebSocket API cohesively.
- Designed an engaging frontend experience that feels true to the League of Legends aesthetic.
- Delivered a complete, functioning system within the given timeframe.
- Created a truly personalized experience for every player using their own gameplay data.
What I learned
Technical Skills
AWS Step Functions
- Designed state machines for orchestrating distributed workflows
- Implemented error handling with Catch and Retry logic
- Learned when to use Step Functions vs. Lambda alone (long-running, multi-step processes)
AWS Bedrock & RAG Architecture
- Gained hands-on experience with large language models in production
- Learned vector embeddings, semantic search, and retrieval-augmented generation patterns
- Discovered prompt engineering techniques for structured JSON output
AWS Glue & PySpark
- Wrote distributed ETL jobs using PySpark for data aggregation
- Learned Glue's serverless model and DPU allocation strategies
- Understood partitioning strategies for S3 data lakes (
/year/month/day/structure)
WebSocket APIs with API Gateway
- Implemented bidirectional real-time communication
- Learned connection lifecycle management ($connect, $disconnect, $default routes)
- Handled WebSocket message routing and error cases
Riot Games API
- Navigated the Riot API's multi-region routing model (americas/europe/asia for accounts, platform regions for summoners)
- Implemented rate limit handling and pagination for match history
- Learned the difference between Riot IDs, PUUIDs, and summoner IDs
Advanced Frontend Engineering
- Structured React component state to minimize re-renders during high-frequency progress streaming
- Implemented lazy dependency loading (share card image export) for bundle optimization
- Leveraged CSS utility classes + transforms for performant progress animations
- Hardened WebSocket lifecycle management (connection gating, resend avoidance, JSON validation)
- Designed sessionStorage-based flow control resilient to manual reloads
Architectural Insights
Serverless Event-Driven Design
- Learned to decompose monolithic applications into single-purpose Lambda functions
- Understood when to use synchronous vs. asynchronous invocations
- Discovered cost optimization strategies (right-sized memory, timeouts, and concurrency limits)
Data Pipeline Best Practices
- Implemented incremental processing to avoid reprocessing existing data
- Used S3 key patterns for efficient data organization and querying
- Learned the importance of idempotency in distributed systems
API Design & Integration
- Designed RESTful and WebSocket APIs for different use cases (HTTP for requests, WS for streaming)
- Implemented proper CORS policies for cross-origin frontend requests
- Learned Lambda Function URLs as a simpler alternative to API Gateway for HTTP
Error Handling & Observability
- Added structured logging with CloudWatch for debugging production issues
- Implemented fail states and error notifications to surface issues to users
- Learned the importance of timeout configuration and retry logic
Soft Skills & Problem-Solving
Learning New AWS Services Quickly
- Gained confidence reading AWS documentation
- Learned to find examples in GitHub repos and Stack Overflow
- Understood when to use AWS-managed services vs. building custom solutions
Balancing Speed vs. Quality
- Learned when to take shortcuts (demo data, mocks) vs. when to do it right (security, error handling)
- Understood that premature optimization is real—focus on correctness first, then optimize
- Discovered that refactoring is easier with good test coverage (though I didn't write formal tests here—lesson learned!)
AI-Assisted Development
- Used AI tools to accelerate development
- Learned to verify AI-generated code and adjust for edge cases
- Discovered that AI is great for boilerplate and patterns, but domain knowledge is irreplaceable
What's next for Rift Trivia
Given more time, I plan to expand Rift Trivia with additional features such as:
- Custom prompts — let players choose trivia focus areas (favorite champs, playstyle, goals).
- Richer visual integration — use Riot’s API to fetch champion art or icons relevant to each trivia fact.
- More answer formats — add ranking, fill-in-the-blank, and open-ended questions for variety.
- Improved social engagement — let friends challenge or compare their results.
- Seasonal or thematic trivia events — e.g., “Arcane Edition” or “Worlds Recap.”
Rift Trivia is my step toward making AI-driven personalization in gaming both fun and meaningful — where data tells a story, and every player becomes the main character of their own League journey.
Built With
- amazon-web-services
- bedrock
- css
- glue
- html
- javascript
- lambda
- node.js
- pyspark
- python
- react
- riot-games
- s3
- tailwind
- vite
- websocket

Log in or sign up for Devpost to join the conversation.