-
-
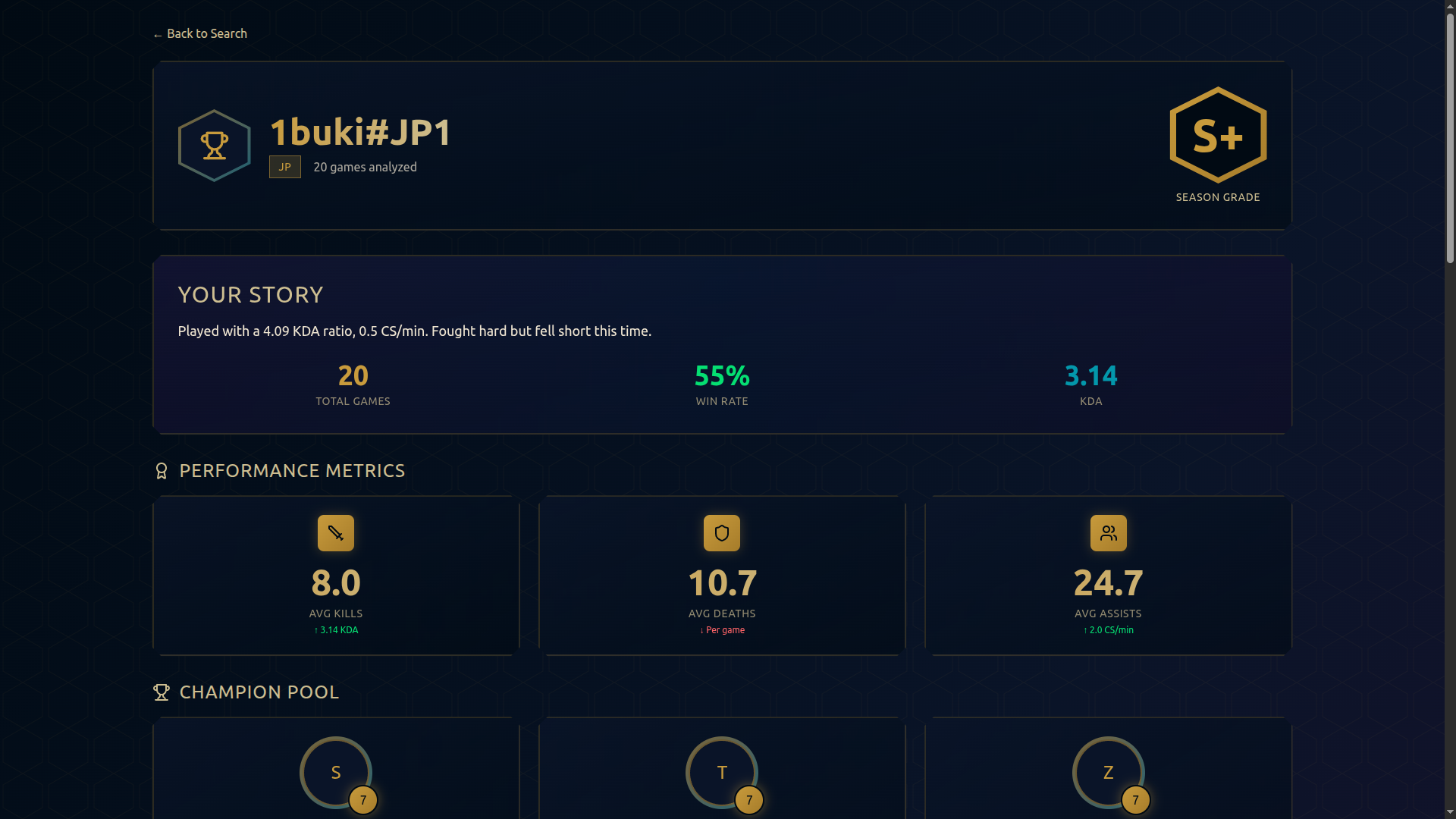
Player Stats
-
Dashboard
-
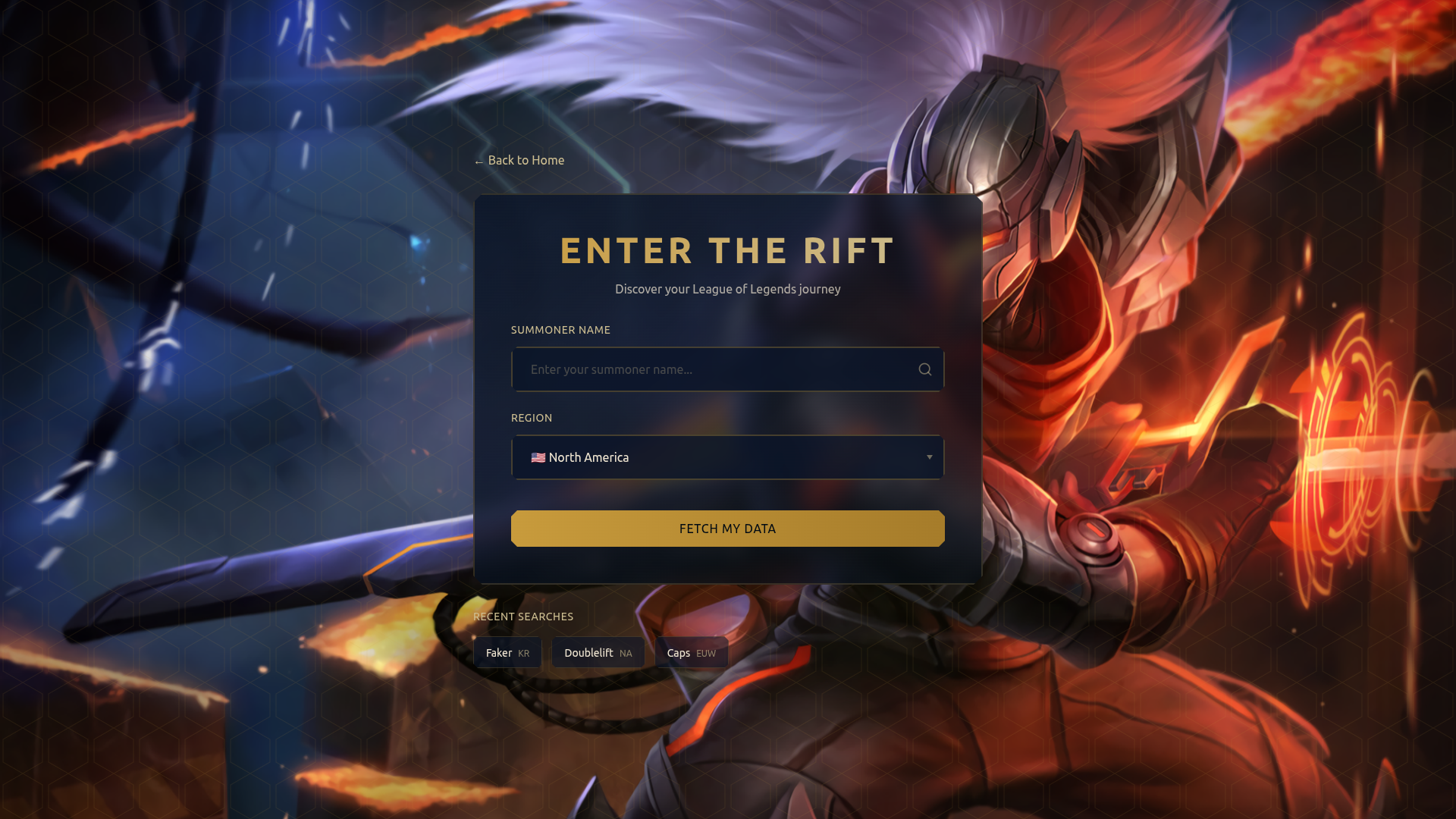
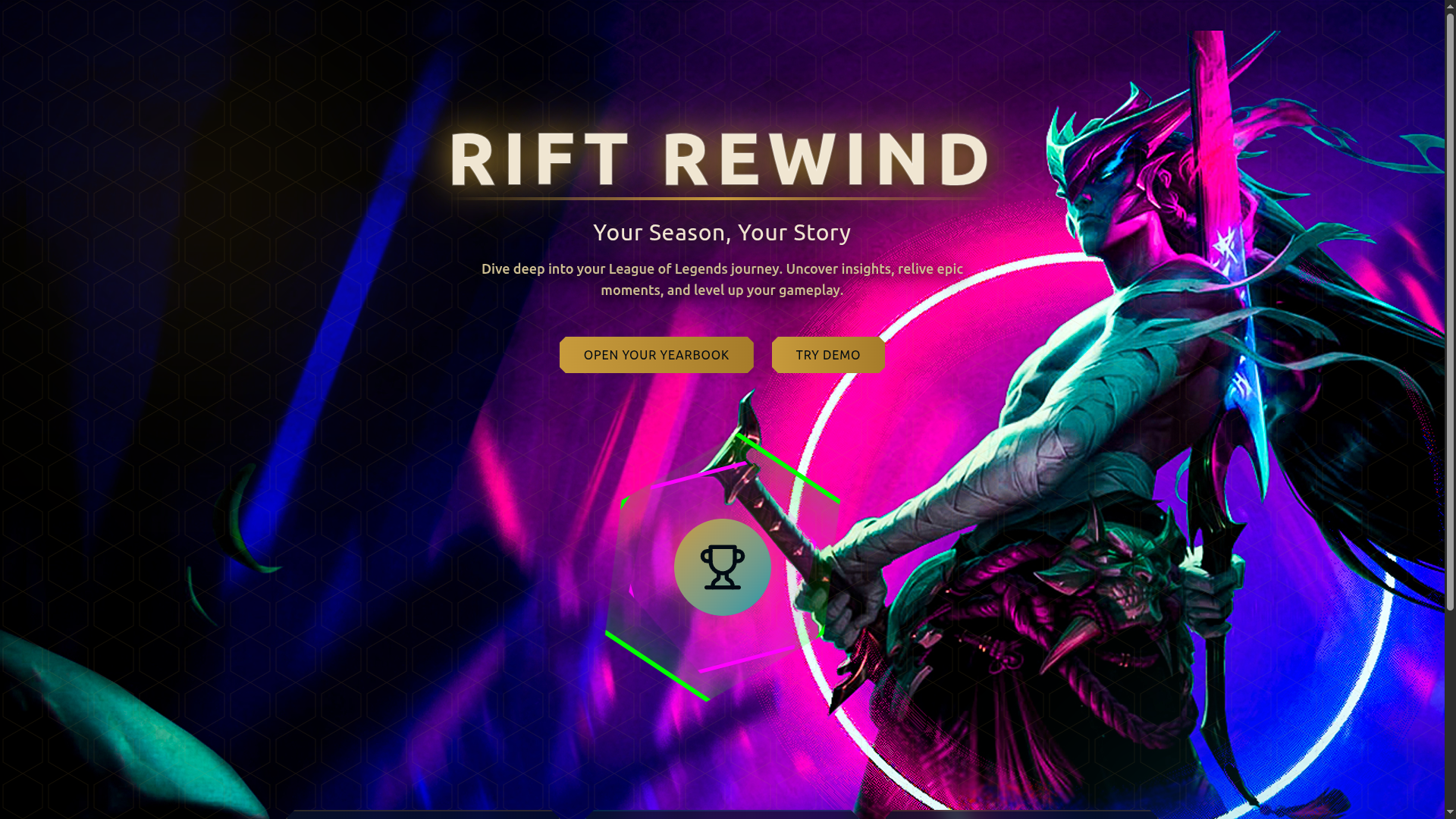
Landing Page
-
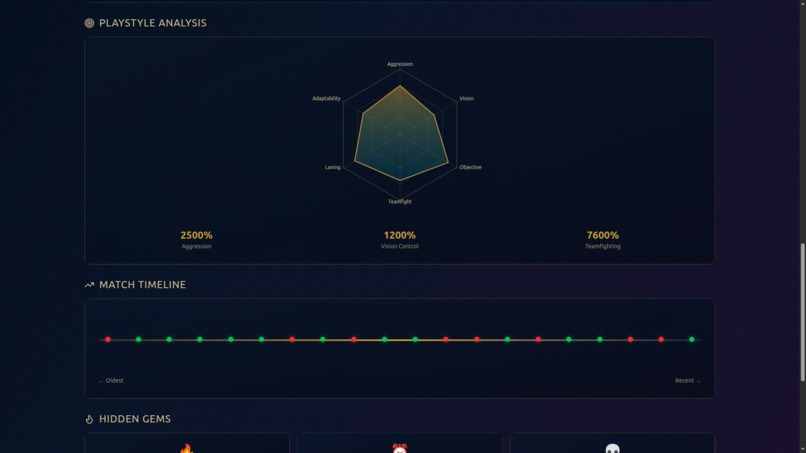
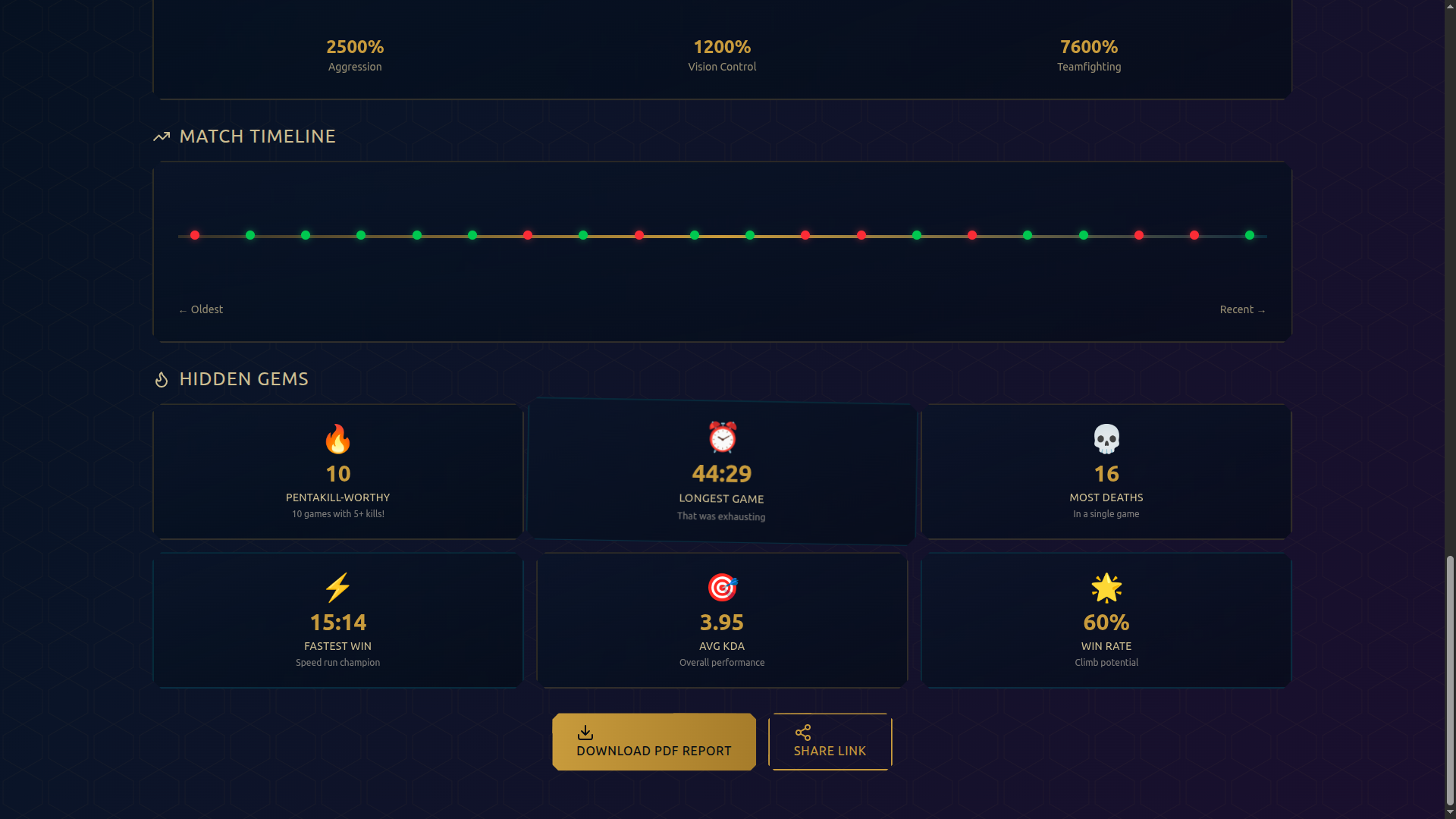
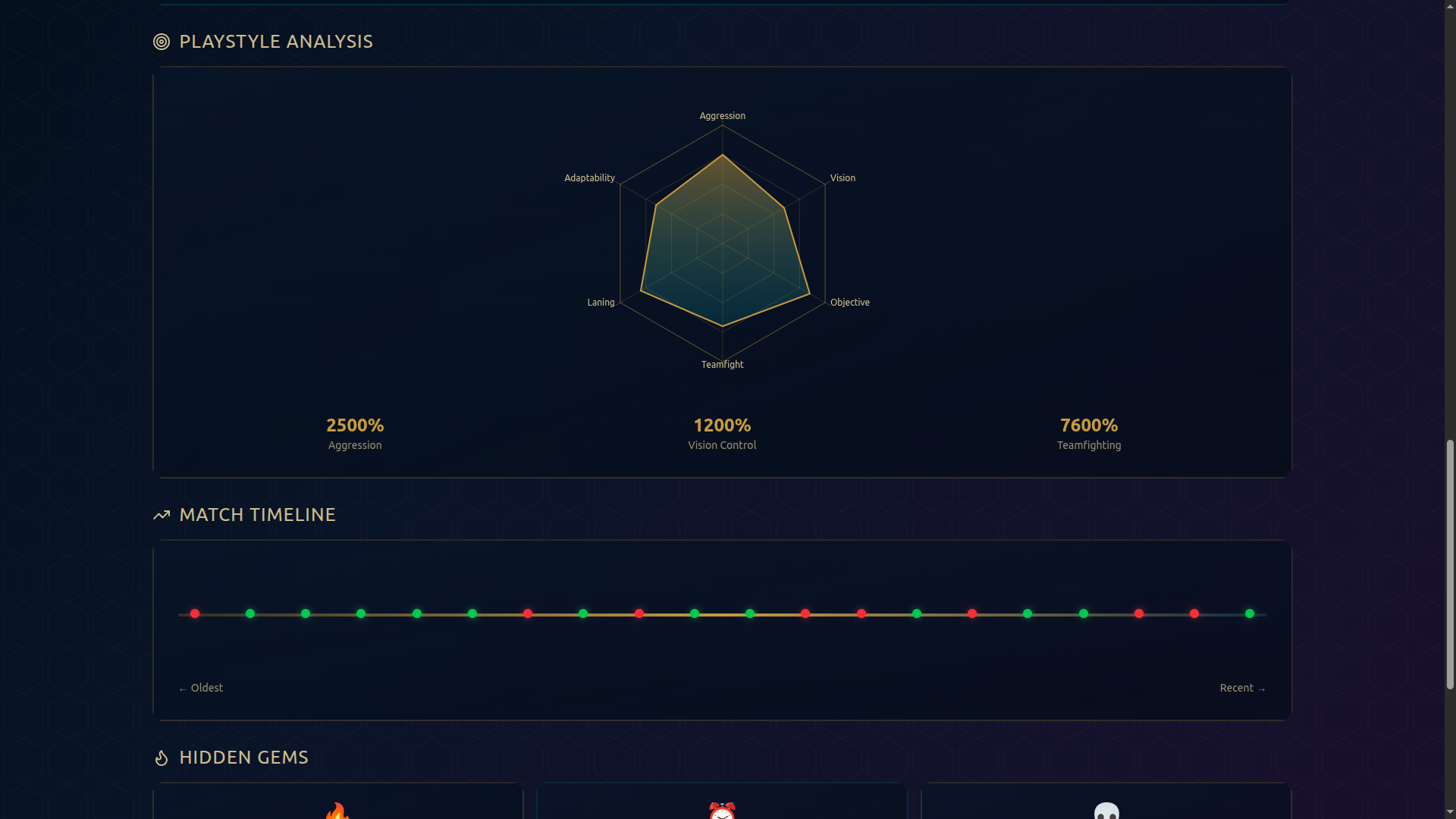
Interactive Timeline
-
Leaderboard
-
Graphical Analysis
Inspiration
As a League of Legends player, I always wondered: "How did my season really go?" Sure, we have match history and basic stats, but there's no way to see the story behind the numbers. Traditional stat trackers are dry and don't capture the emotional journey of climbing ranks, learning new champions, or those epic comeback games. I wanted to create something that feels like a personalized yearbook for League players—something that uses AI to tell your unique story and help you improve.
The AWS Rift Rewind Hackathon was the perfect opportunity to combine my passion for League of Legends with cutting-edge AI technology to build something truly meaningful.
What it does
Rift Rewind transforms your League of Legends season into an interactive, AI-powered yearbook with:
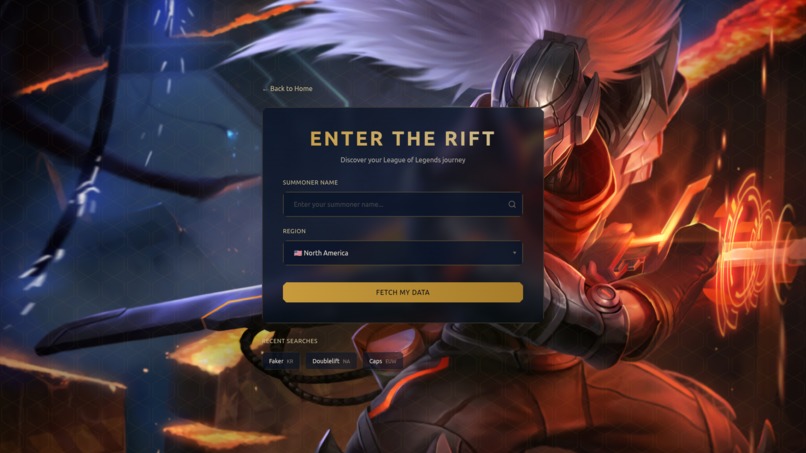
- 🎯 Smart Player Search: Enter any summoner name and region to instantly fetch match history
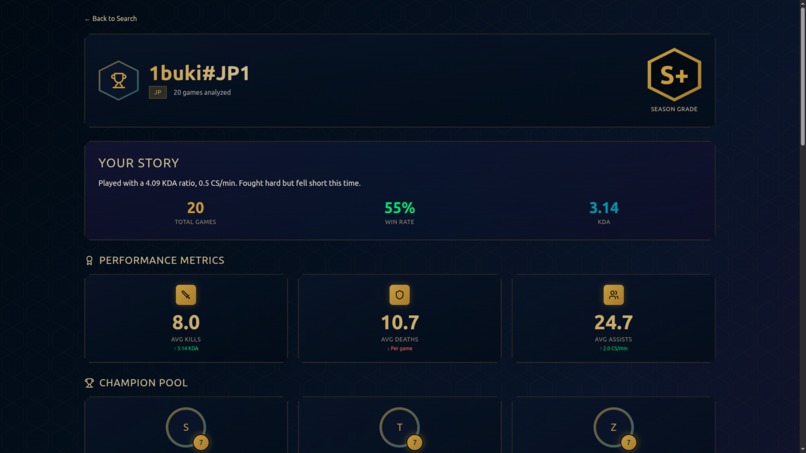
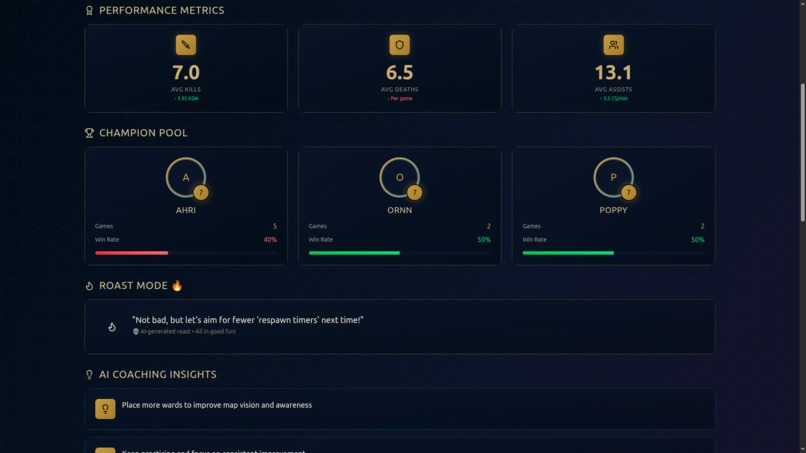
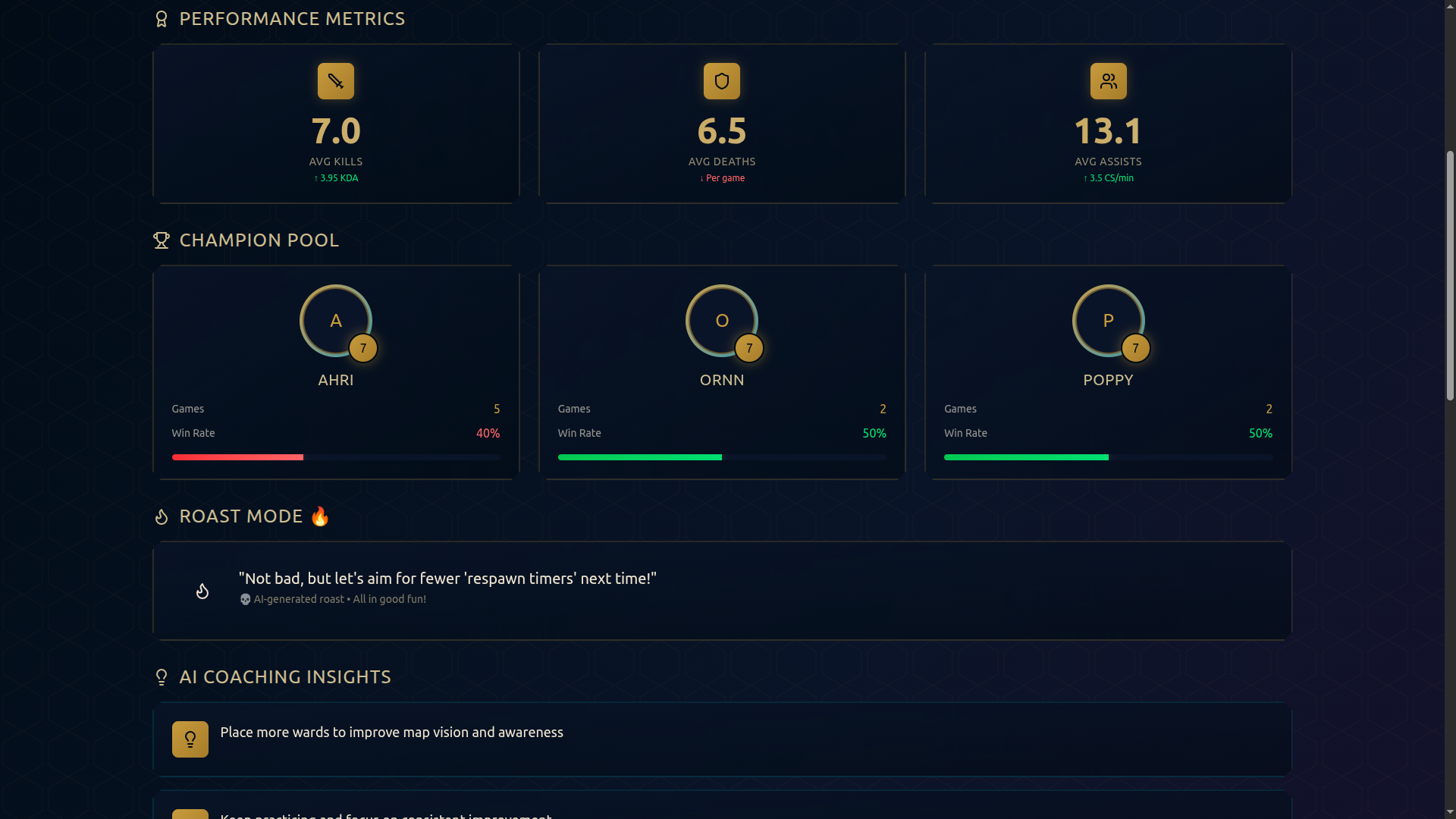
- 📊 Performance Dashboard: Beautiful visualizations showing KDA, win rates, CS, vision scores, and trends
- 🏆 Champion Analysis: See your most-played champions with detailed performance metrics
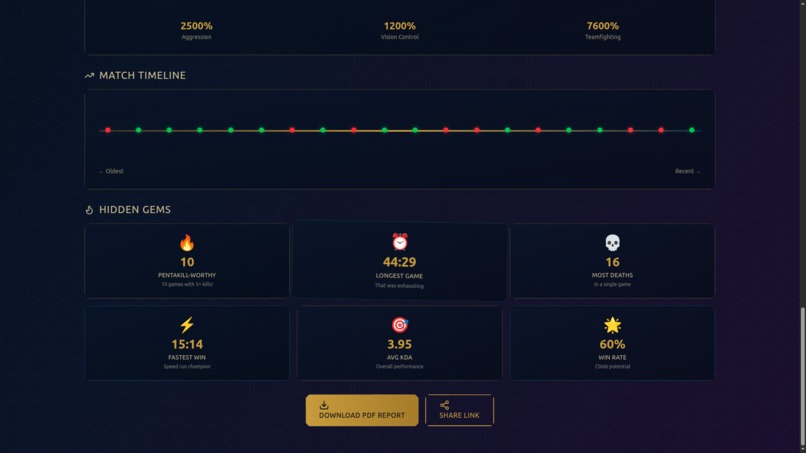
- 🎨 Playstyle Radar Chart: Visual breakdown of your strengths (Aggression, Vision, Teamfight, Farm, Objectives)
- 🤖 AI-Powered Insights (Amazon Bedrock):
- Season Summary: A personalized 200-word narrative of your journey
- Top 3 Achievements: Your best moments highlighted
- Top 3 Improvement Areas: Actionable coaching tips
- Detailed Analysis: Deep dive into your playstyle with specific recommendations
- 📥 Shareable Cards: Download beautiful PDF cards with your stats to share on social media
- ✨ Smooth UI: Glass morphism design with responsive animations
How I built it
Frontend (React + TypeScript):
- Built with React 18, TypeScript, and Vite for fast development
- Used Tailwind CSS and shadcn/ui for beautiful, accessible components
- Recharts for interactive data visualizations (radar charts, bar charts)
- html2canvas + jsPDF for generating shareable PDF cards
- React Router for smooth navigation
- Deployed to AWS S3 with CloudFront CDN for global delivery
Backend (AWS Serverless):
- AWS Lambda (4 functions in TypeScript):
- Ingestion Lambda: Fetches player data from Riot API
- Processing Lambda: Analyzes match statistics and computes aggregates
- AI Lambda: Generates insights using Amazon Bedrock (Claude 3 Haiku)
- API Lambda: Handles REST API requests
- Amazon DynamoDB: 3 tables for players, matches, and AI insights
- Amazon Bedrock: Claude 3 Haiku model for personalized narratives and coaching
- API Gateway: RESTful endpoints with CORS support
- Riot Games API: Real-time match data fetching
Infrastructure & DevOps:
- AWS CDK (TypeScript) for Infrastructure as Code
- GitHub Actions for CI/CD with automatic deployments
- Docker bundling for Lambda dependencies
- CloudWatch for monitoring and logging
Challenges I ran into
Riot API Rate Limiting: The Riot API has strict rate limits. I had to implement smart caching in DynamoDB to avoid redundant API calls and ensure smooth user experience.
Lambda Cold Starts: Initially, Lambda functions took 3-5 seconds to respond. I optimized by:
- Using Docker bundling to reduce package size
- Implementing efficient data processing algorithms
- Caching Bedrock responses in DynamoDB
CloudFront URL Generation: The CloudFront distribution ID doesn't map to the domain name directly. I solved this by:
- Using CloudFormation outputs to get the actual domain
- Updating GitHub Actions to fetch the correct URL dynamically
Lambda Dependency Bundling: The
axiosmodule wasn't included in Lambda by default, causing runtime errors. Fixed by:- Adding explicit
npm installin CDK bundling - Using Docker with proper permissions (
user: 'root',--cache /tmp/.npm)
- Adding explicit
AI Prompt Engineering: Getting Claude to generate consistent, actionable insights required multiple iterations:
- Structured prompts with clear examples
- JSON schema validation for outputs
- Temperature tuning for creativity vs. consistency
Cost Optimization: Staying within AWS credits required:
- Using Claude 3 Haiku (most cost-effective model)
- Aggressive DynamoDB caching to avoid re-processing
- On-demand pricing for DynamoDB instead of provisioned capacity
Accomplishments that I'm proud of
✅ Production-Ready Deployment: Fully deployed on AWS with a live CloudFront URL
✅ Real AI Integration: Not fake data—actual Bedrock-powered insights with personalized narratives
✅ Beautiful UX: Glass morphism UI, smooth animations, responsive design
✅ Complete Pipeline: End-to-end data flow from Riot API → Lambda → DynamoDB → Bedrock → Frontend
✅ Shareable Content: PDF generation feature for social media sharing
✅ Solo Build: Designed, developed, and deployed everything in hackathon timeframe
✅ Cost-Efficient: Entire stack running on ~$15 of AWS credits
What I learned
- Amazon Bedrock: First time using Bedrock for production AI! Learned prompt engineering, model selection, and cost optimization
- AWS CDK: Deep dive into Infrastructure as Code—much better than manual console clicking
- Lambda Optimization: Docker bundling, cold start reduction, memory tuning
- DynamoDB Design: Single-table design patterns, GSI strategies, on-demand pricing
- CloudFront + S3: Static site hosting with CDN distribution
- Riot API: Working with external APIs, rate limiting, regional routing
- End-to-End AWS: Connected 10 AWS services into a cohesive application
What's next for Rift Rewind
🚀 Feature Roadmap:
- Timeline View: Interactive match-by-match timeline with animations
- Comparison Mode: Compare yourself to friends or high-elo players
- Rank Prediction: ML model to predict end-of-season rank
- Video Highlights: Integrate Riot's match replay API for video clips
- Multi-Season Support: Compare season-over-season growth
- Discord Bot: Share insights directly in Discord servers
- Mobile App: React Native version for iOS/Android
🔧 Technical Improvements:
- Add AWS Secrets Manager for API key management
- Implement Step Functions for complex data pipelines
- Add OpenSearch for semantic search across matches
- Cognito for user accounts and saved searches
- X-Ray for distributed tracing and debugging
Built With
- amazon-bedrock
- amazon-cloudfront
- amazon-dynamodb
- amazon-web-services
- api-gateway
- aws-cdk
- aws-cloudwatch
- aws-lambda
- claude-3-haiku
- docker
- github-actions
- node.js
- react
- recharts
- riot-games
- shadcn/ui
- tailwind-css
- typescript
- vite

Log in or sign up for Devpost to join the conversation.