-

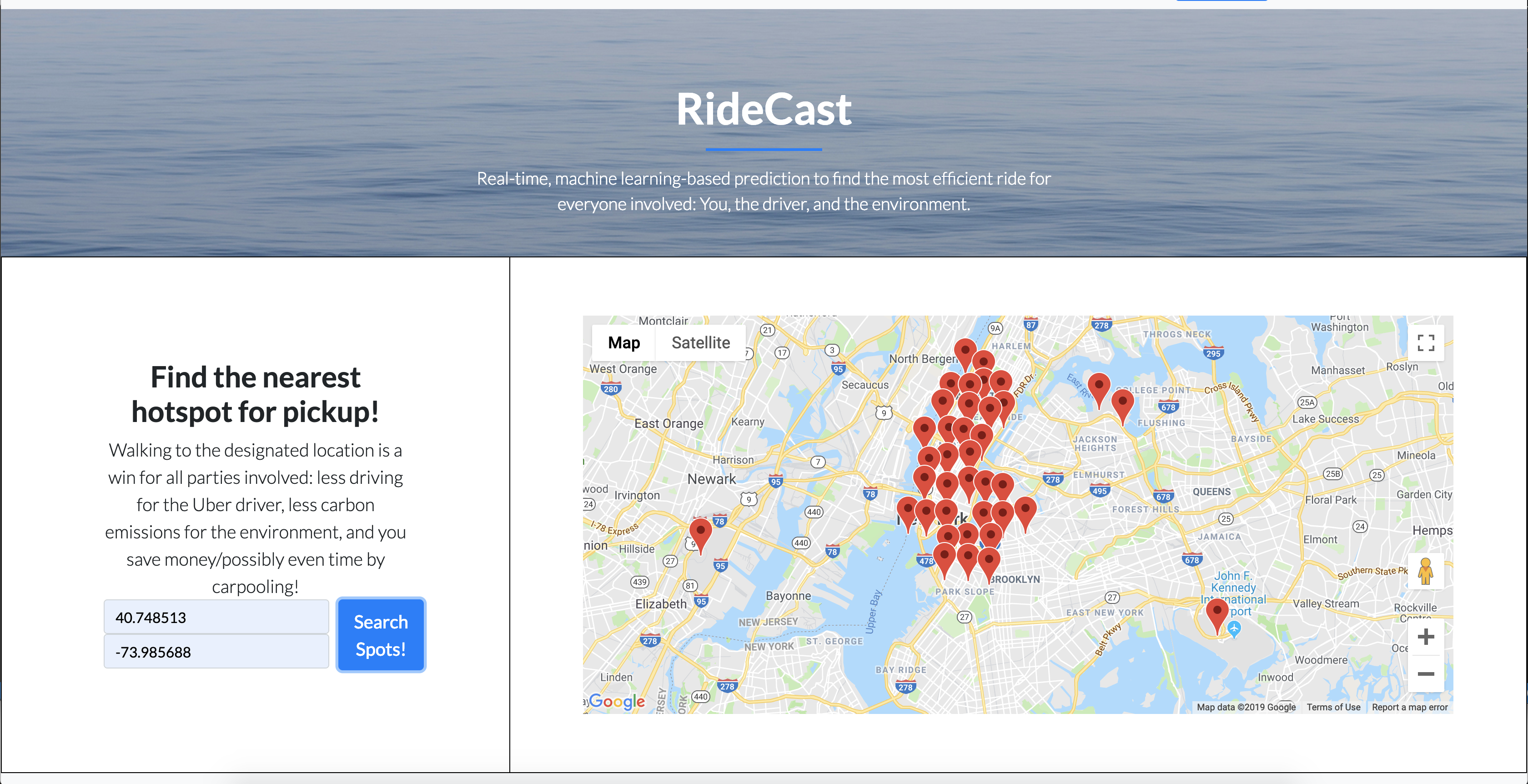
The UI displays the hotspots for a given time. The user enters their location...
-
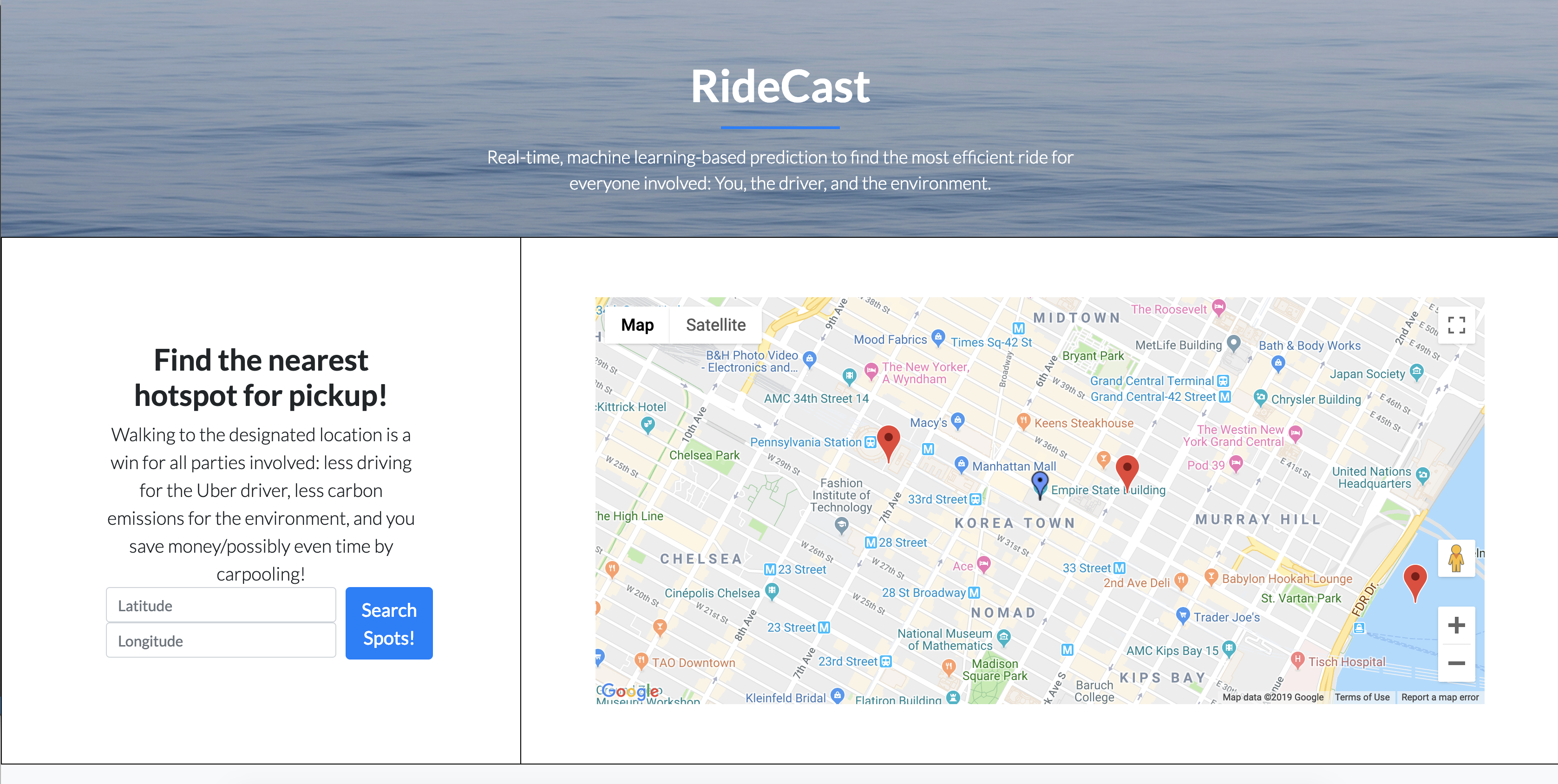
...and the UI zooms in so they can see the closest hotspots to them.
-
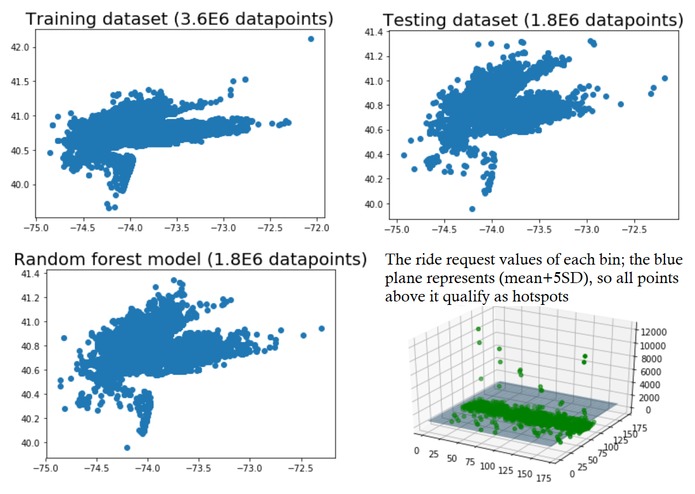
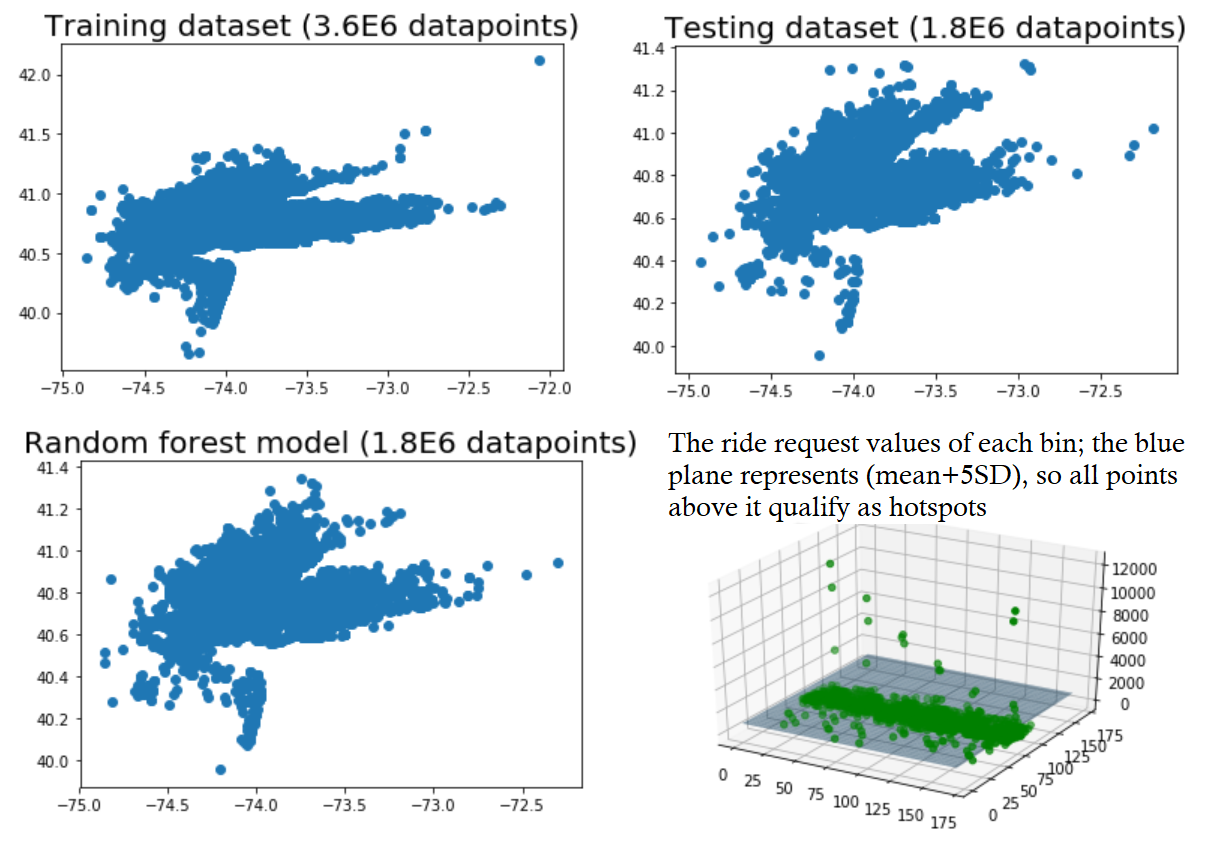
The results of using a Random Forest Regressor, along with a 3d visualization of the binning & hotspot selection process
-
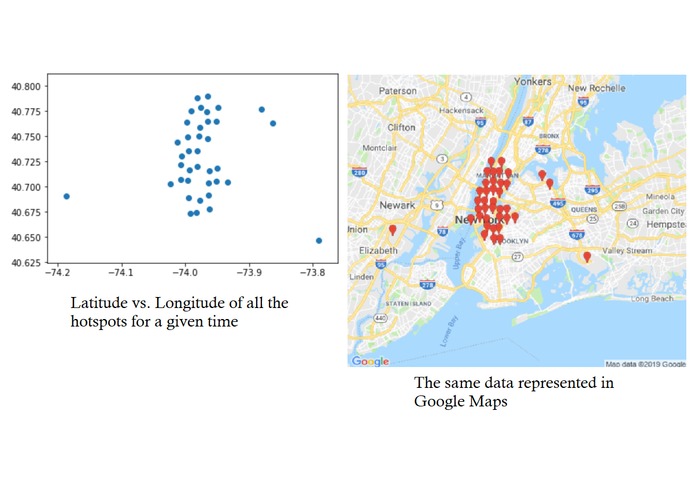
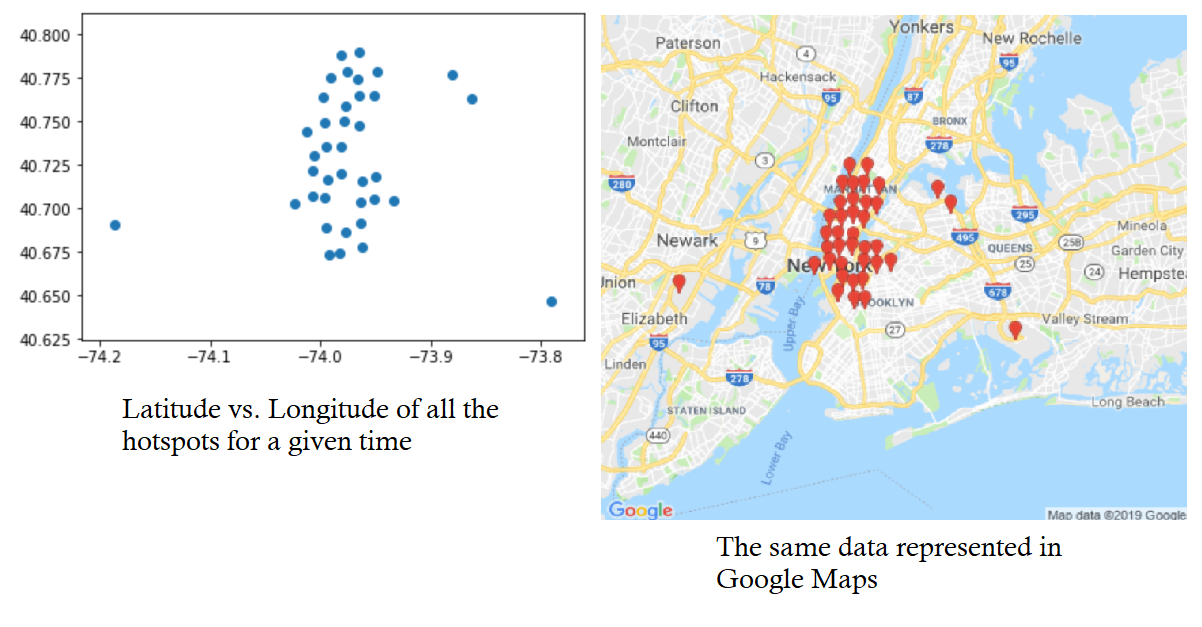
An example prediction of hotspots for a random time, and their projection onto a map. Newark airport is an expected notable outlier.
-
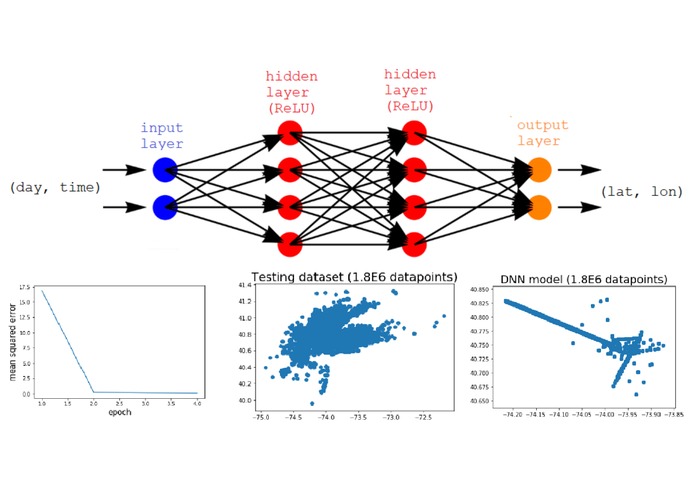
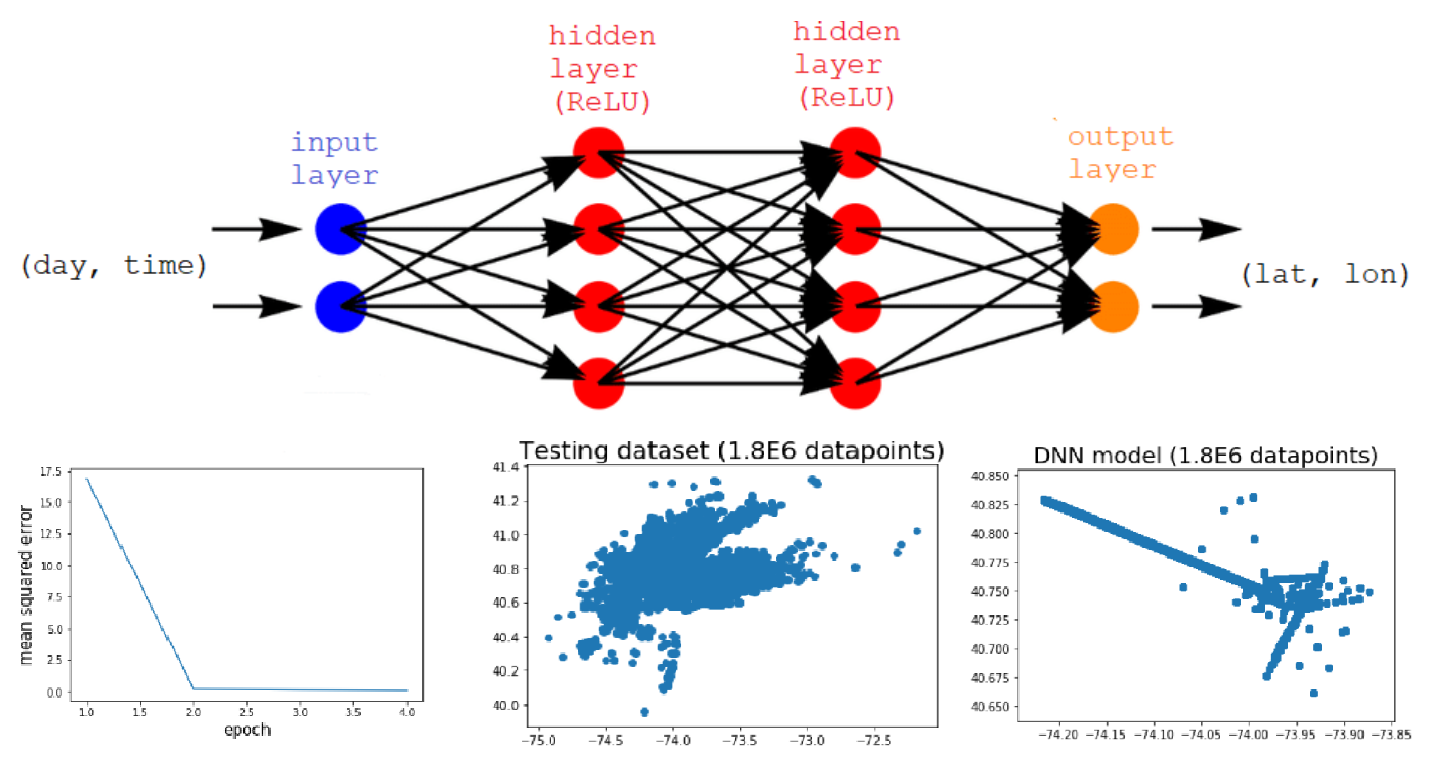
Our (failed) Deep Neural Network model
Inspiration
Uber has become an integral part of our lives over the past few years, but the implications of the ride sharing app, both in terms of environmental and social impact, cannot be overlooked. The core idea behind our project is that Uber data should exhibit characteristic patterns, and is therefore predictable by machine learning algorithms. Being able to predict Uber rides taking place at any point of time is extremely powerful--for instance, with carbon emissions on the rise, this kind of information can be directly helpful in improving gas use efficiency and encouraging ride sharing. Using publicly available Uber data from over from ~4.5 million rides in the Greater NYC area from April-September 2014 (most recent data available in that area), we constructed a machine learning model that predicted the likely ride requests given the time of day and the day of week and leverage it to optimize rider/driver interactions.
What it does
When the RideCast webpage loads, it automatically constructs and trains the machine learning model on the Uber dataset, taking into consideration the current time/day. The UI then displays all of the Uber “hotspots,” which are essentially areas with a very high frequency of rides, in a map. The user enters their location, upon which the map will zoom to their location, allowing them to better view the nearest hotspots to them.
How we built it
We constructed a random forest regression model using Keras on top of TensorFlow that predicted the likely ride requests given the time of day and the day of week. The model correctly predicted latitude and longitude to within a mean-squared error of 0.000842 and 0.00274 degrees, respectively (approximately 0.06 and 0.19 miles). With a model that could predict every likely Uber ride request in a given day, we were able to leverage the information in a way that would benefit the rider, the driver, and the environment. We subdivided the land area into 33,490 0.25-mile “bins” (170 latitude-wise by 197 longitude-wise). Then, given a time-of-day and day-of-week, we looked at which “bin” each predicted ride request within a 5-minute period would fall into, incrementing the bin’s ride count for each predicted ride. Bins with a ride count five standard deviations above the mean were designated as “hotspots” for the given 5-minute period, meaning they are highly likely to experience multiple Uber ride requests. On the web application side, the frontend was built using HTML/CSS with Javascript handling the logic for the Google maps and interactives on the website. The backend was built on Python flask, which integrated with our machine learning model directly and handled all the HTTP GET/POST requests to get real-time map visualization of hotspots in the area. With the information of the current/upcoming hotspots, the benefits are three-fold. The user can walk to the location of the nearest hotspot to them to minimize time waiting for the Uber, as well as the extra cost of driving that distance; the driver’s time and gas spent picking up the next rider is lowered, optimizing their service by maximizing time spent driving passengers; and most importantly, unnecessary carbon emissions are reduced by chipping off an auxiliary part of the Uber commute. On the scale of Uber, which handles millions of rides per year, this effect would accumulate manifold.
Challenges we ran into
-Because this was our first exposure to machine learning, TensorFlow came with a steep learning curve. Initially, we tried training a predictive Deep Neural Network, but it tended to create spurious trends within the data where none existed. After several hours of trial and error, we settled on the Random Forest Regressor. -Getting a useful model out of the Uber dataset required much data manipulation as well as research into which machine learning model would suit our needs the best. -In order to meet our interactive, personalized, and real-time portrayal of hotspots, we had to design middleware javascript middleware between our python backend and our frontend, as well as maintaining communication with our machine learning model/dataset.
Accomplishments that we're proud of
-Training a model to produce an accurate prediction (to within a fraction of a mile) on both latitude and longitude was a difficult, but rewarding challenge. -Completing a real-time interactive visualization of relevant hotspots in your area.
What we learned
-The basics of machine learning in Python with Google’s powerful TensorFlow tools
What's next for RideCast
-Extending it to other datasets than Uber/greater NYC -Making the interactive map more immediately useful by having different search criteria than simply latitude/longitude (currently stands as a proof of concept). -Incorporating directions into it/integrating more with the Uber app itself -Finding local attractions in the area of the hotspots to possibly create a travel app where you can efficiently bounce from venue to venue quickly but with more freedom than public transit.
Built With
- bootstrap
- css3
- flask
- google-cloud
- google-maps
- html5
- javascript
- jupyter-notebook
- keras
- python
- scikit-learn
- tensorflow
- uber-dataset


Log in or sign up for Devpost to join the conversation.