-
-
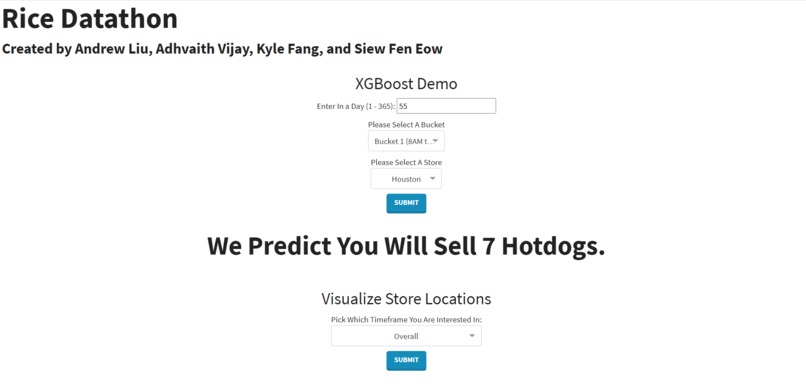
Model Deployed on a Web App
-
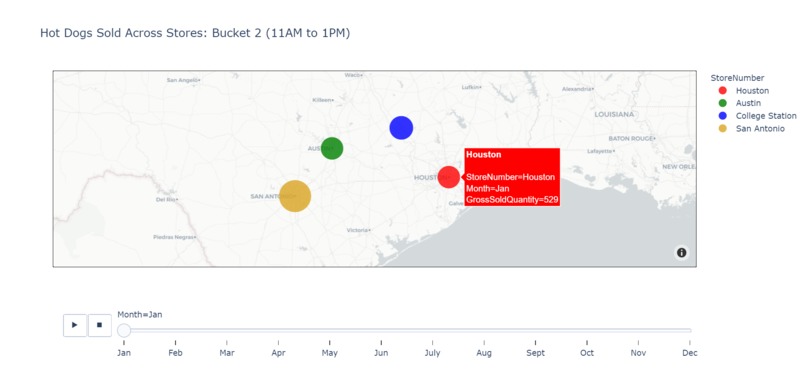
Interactive Visualizations
-
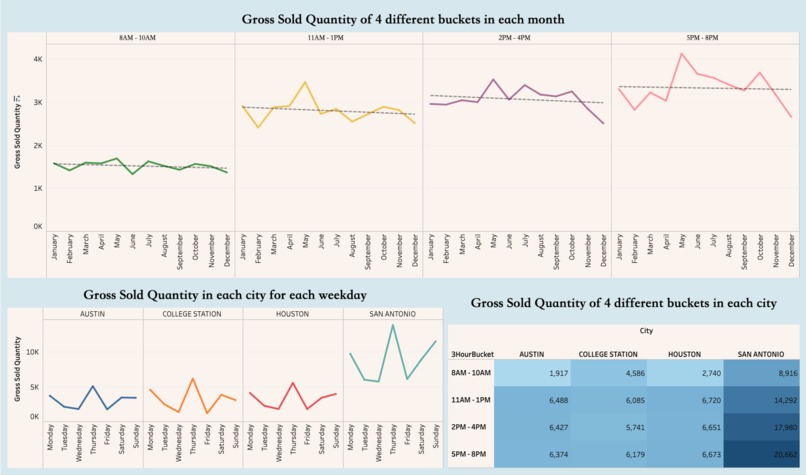
Tableau Visualizations
Submission File:
https://github.com/Andrewl7127/RiceDatathon/blob/main/final_submission_file.xlsx
Abstract
Every year, thousands of hot dogs go to waste due to the miscalculation of demand. We sought to help Chevron prevent this by extracting insights into consumer behavior and create a model that can accurately forecast sales. To do this, we utilized machine learning to create a cook plan for certain buckets of time, saving Chevron money and preventing food waste.
For the sake of user-friendliness, we hosted all of our deliverables on a web application (https://rice-datathon.herokuapp.com/) built through Dash and Heroku - a development-friendly cloud platform. On this web app, users can explore visualizations of our initial findings on consumer behavior, discover how hot dog sales per city changes over time through our interactive map, and read about our machine learning model, which predicts hot dog sales based on store, day, and time with a root mean squared error (RMSE) of 9.01. When tested against the scoring set, the RMSE was 3.55.
Methodology
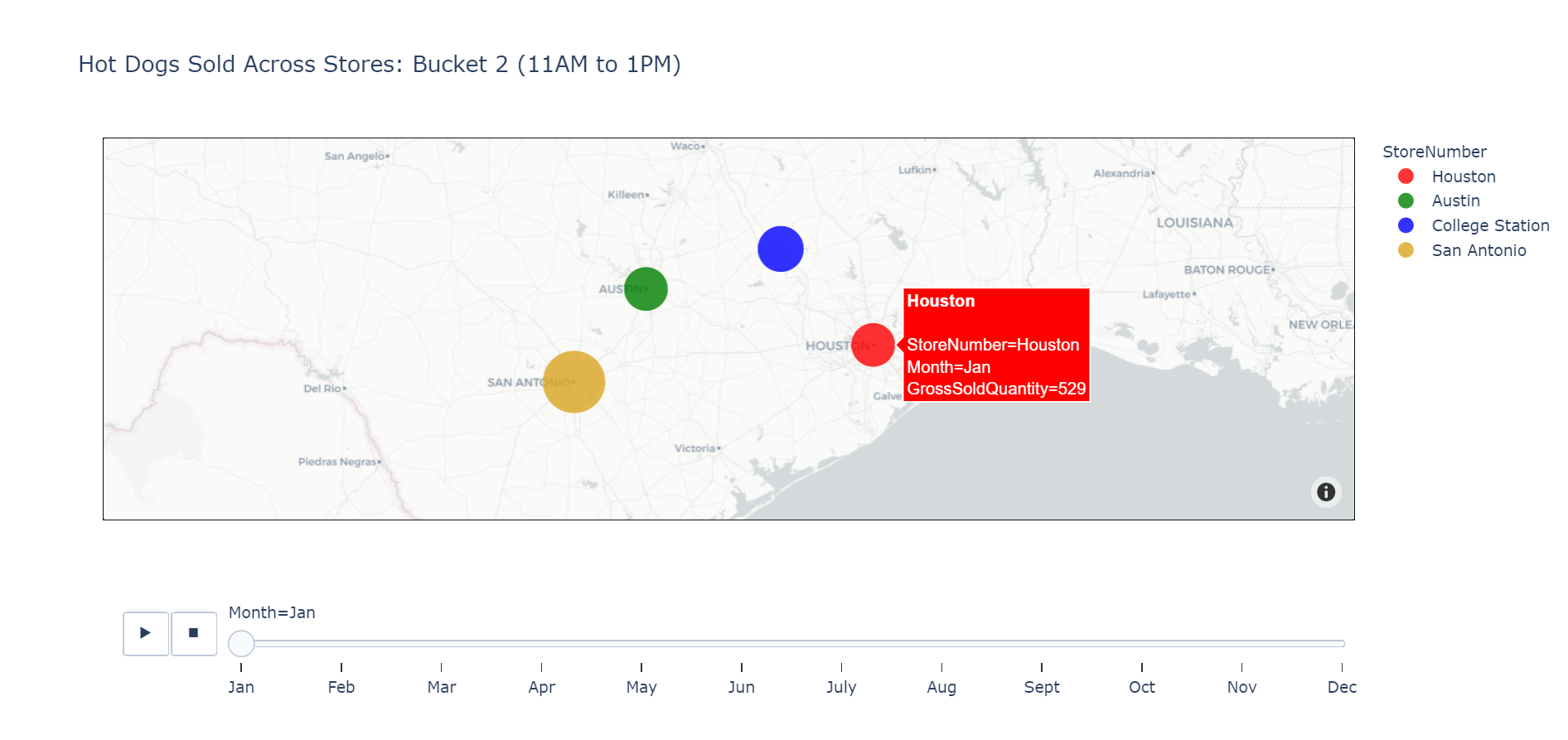
The time column in the provided data contains only the number of days after a starting point. We observed noticeable patterns in consumer behavior on certain days of the week or times of the year, so we added parameters to denote the day of the week, month, and season of each row. With these added parameters, we utilized the XGboost package to create a machine learning model that predicts the number of hot dogs needed for a certain time bucket for a certain store during a certain day. Additionally, we created an interactive python-based map that visualizes the sale quantity based on location, time bucket, and month. The map features a drop-down menu and slider to allow users to pick specific store locations and observe how the sales change as time goes on. Lastly, we created plots and a highlighted table through Tableau to illustrate our findings on consumer behavior.
Discussion
For our machine learning algorithm, we chose to use XGBoost, an optimized gradient boosting algorithm. We chose XGBoost because it is robust to outliers, overfitting, multicollinearity, missing values, and does not require normalization, encoding, etc. It is an optimized gradient boosting algorithm that is one of the best for small-to-medium structured/tabular data. After cleaning and preparing the data (encoding and discarding redundant variables or variables that only have one unique value), our final variables were the store number, day of the year, 3-hour bucket, EBT site, alcohol, carwash, and day of the week.
We chose to split the training and testing sets in accordance with a 70/30 ratio (70% training, 30% testing) as our data was not very large, which proved to give the best results. We also feature engineered a column for “day of the week.” This was inspired by our data visualization on Tableau, where we noticed a pattern between the days of the week and hot dog sales. Although this feature proved to be beneficial to our model, many other features that we engineered provided no gain. One example of this was a feature on season based on the day of the year. When added to the training data, such features proved to provide no additional benefit.
Another way we improved our accuracy was by removing outliers from the training data. When visualizing the dataset, we noticed certain extreme positive values. After filtering out positive outliers (there were no negative outliers), we noticed a stronger result. Finally, we improved our accuracy by hyperparameter tuning. Using XGBoost’s cross-validation, we tuned 5 different parameters (max_depth, min_child_weight, subsample, colsample_bytree, eta) to their optimal values, attempting to optimize both variance and bias. In the end, we achieved a root mean squared error (RMSE) of 9.01. When tested against the scoring set, the RMSE was 3.55.
Furthermore, we created a map to capture the big trends in sales per city over time. Through the map, we can see that San Antonio outsells all other cities in all buckets. In all the cities, January and February start strong with high relative sales. March and April see a decline. The rest of the months alternate between high and low sales, with November and December decreasing to finish off the year.
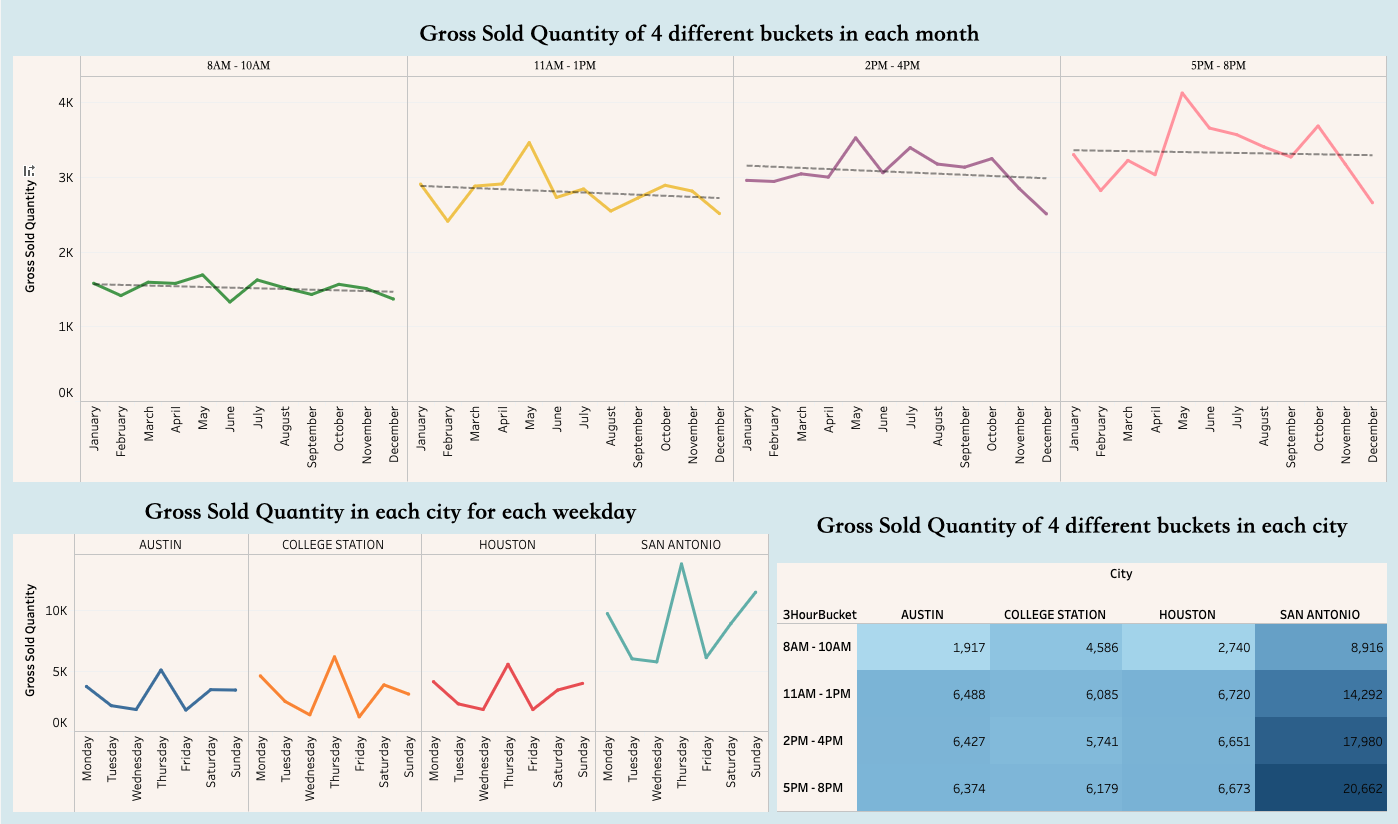
Our three Tableau visualizations focus on the smaller factors and general trends of consumer behavior. In our first visualization, we compare the gross quantity of hotdogs sold per month within each time bucket. In our first visualization, we learned that consumers tend to purchase hot dogs later in the day, favoring afternoons and evenings over mornings. Furthermore, we saw sharp declines in sales during the months of late Fall to early Winter (November through February), whilst in the spring, most notably April and May, we saw consistent increases in sales. In running a linear regression on each of the data sets, we observe that there is a general decreasing trend in hotdog sales in the whole year.
In our second visualization, we aggregated sales based on location and weekday to further dig into consumer behavior. We noticed sales consistently peaking on Monday, Thursday, and Sunday, with dramatic drops on Tuesday and Friday. This insight inspired us to feature engineer a column for “day of the week”, which proved very helpful in our model.
In our third visualization, we generated a highlighted table of the sales based on the daily time bucket and the location of the store. From this visualization, we can see that San Antonio has significantly higher sales compared to the other cities. Austin, College Station, and Houstin have similar sales across the board.
Conclusion
The map highlights that higher demand in San Antonio. The Tableau visualizations depict the trends per month, city, time bucket, and weekday. Our XGBoost algorithm can forecast sales accurately, saving. Combining our map, Tableau visualizations, and machine learning model, we created a powerful set of tools for Chevron stores.





Log in or sign up for Devpost to join the conversation.