-
-
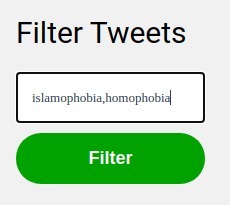
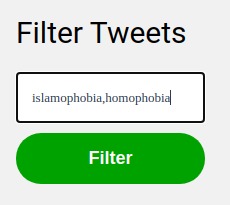
Adding Filters
-
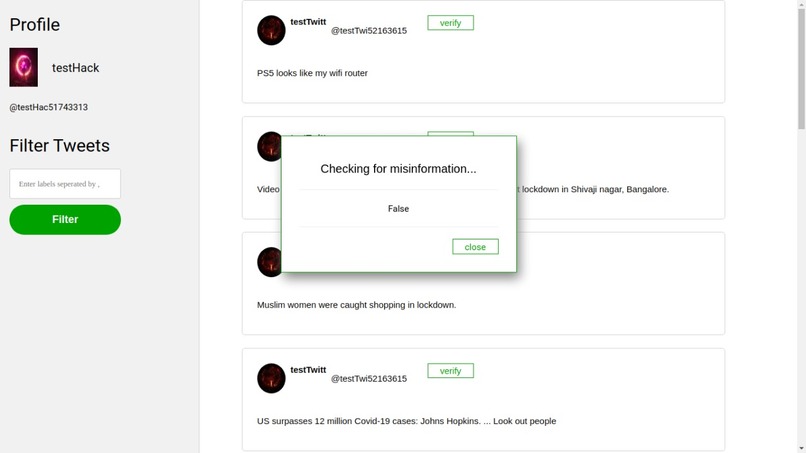
False Information
-
Home Timeline
-
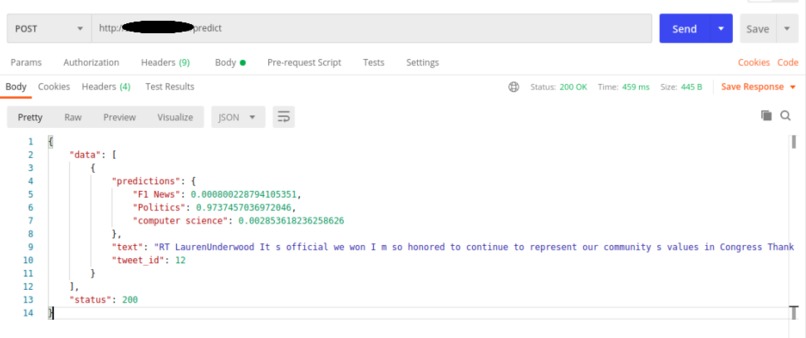
API Call for Elixr
-
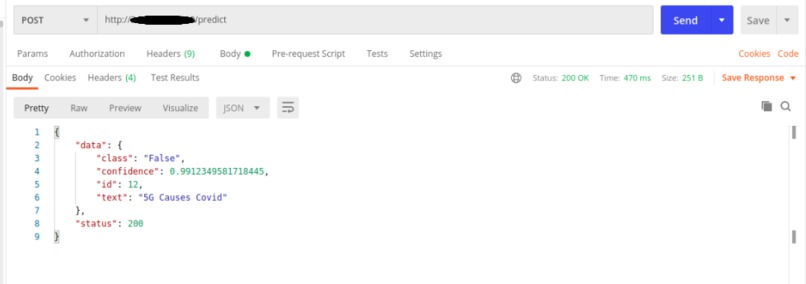
API Call for MisMatch
Inspiration
We were inspired to take up this project due to the recent events with respect to the current pandemic and certain local and international incidents with respect to violence and discrimination.
Twitter is the source of information used by millions all over the world and we saw a lot of fake news being spread related to the current pandemic and the US elections. False information can lead to severe consequences hence it is essential to build scalable systems that can handle the spread of false information and also provide a way for users to verify information on the platform
We also notice that certain posts can affect the state of mind of the users irrespective of the fact they were hateful or not. Everyone has their own personal triggers and hence should be allowed to filter what they see and don't see. Twitter allows users to do this based on keywords but we believe it can be even better if we are allowed to filter out tweets based on personalized labels given by users such as Islamophobia, Racism, and so on (can even be something nonhateful like F1 if someone is not a big fan of motorsports).
What it does
Our project essentially consists of 3 parts:
- Ribitter Webapp
- Elixr Server
- MisMatch Server
Ribitter Webapp
This is our Twitter clone like website in which a user can sign in using Twitter authentication and can see their feed. We have also added functionalities where the user can input topics that they don't want to see on their feed. No specific language model was trained on any category as we understand that it is impossible to train a model on every specific label that a user can think of. Instead, we built a zero-shot classification system that identifies the semantics of the labels and classifies the tweets to be displayed.
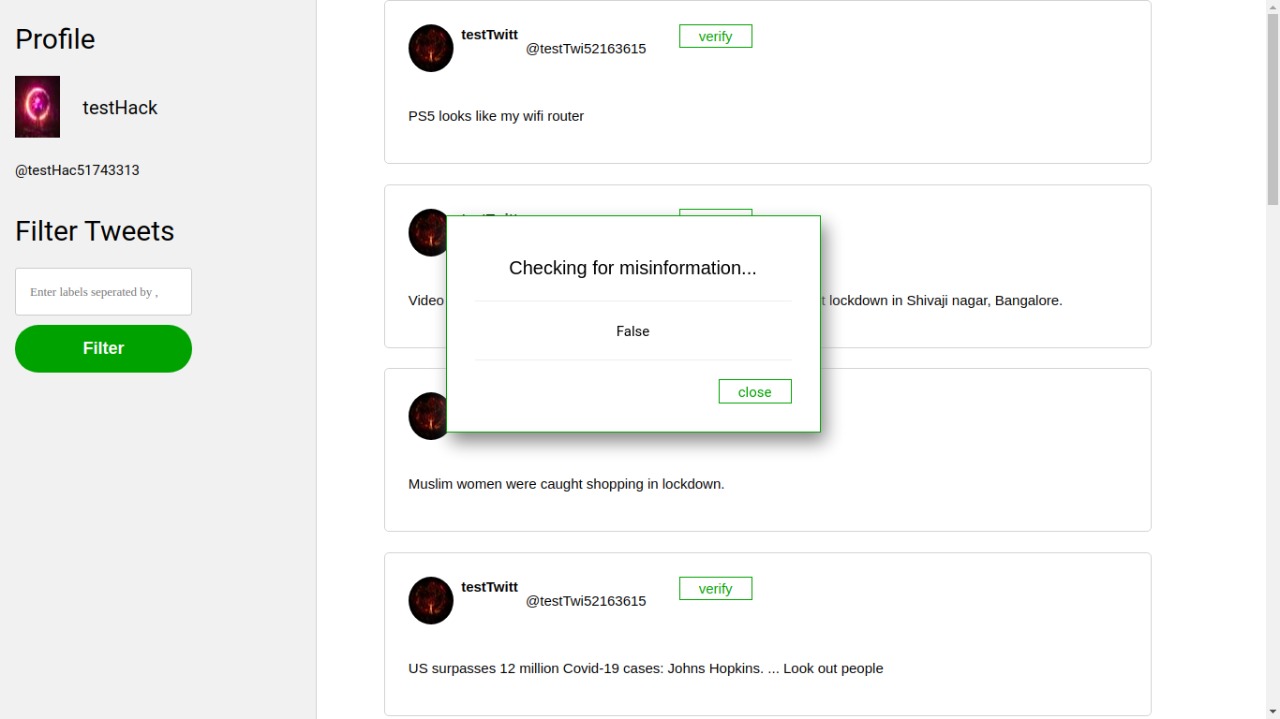
The user can also check if a certain tweet is a fake news. Again no specific language model was trained on any specific dataset as the challenge of fake news identification is not as simple as sentiment analysis. We built a system that given a tweet, retrieves similar tweets from the Index of labeled tweets, and compares them using a Transformer based NLP model that can output if two sequences of texts entail or contradict each other. Based on these scores we can tell with a high degree of certainty if a certain tweet is a variant of another tweet that has already been labeled as False or True.
Elixr Server
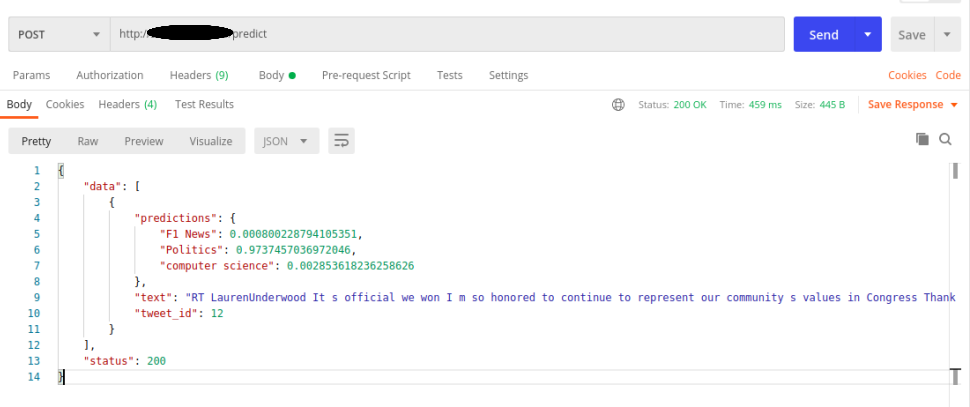
A Webapp that receives tweets and labels as input and outputs prediction score for every tweet, label combination.
We use Zero-shot classification and directly compare tweets and label inputs which are modified using a hypothesis template.
Example:
If a tweet input says "Biden won the elections" and one of the labels is "Politics" the inputs to the model would be the tweet and the modified input "This text is an example of Politics".
Now when we compare the 2 inputs ie the tweet and the modified input, we can say that they entail each other.
MisMatch Server
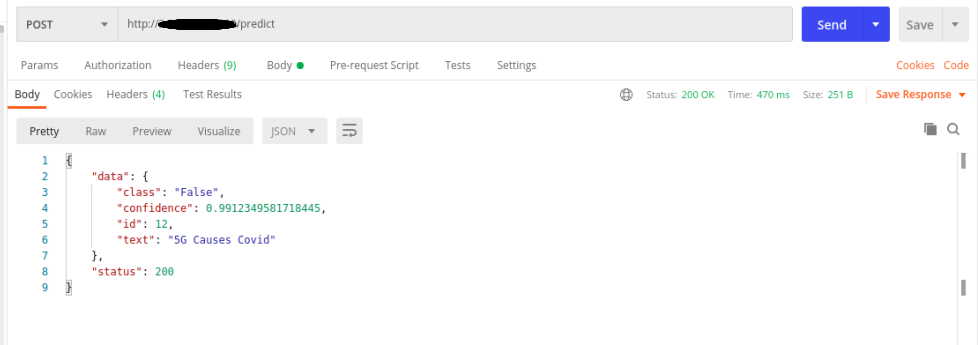
A Webapp that receives tweets as input and identifies if a similar tweet has been flagged as False or True.
We generate embeddings of all the previously flagged Tweets/Text data and create an Approximate nearest neighbor Index that we can use to retrieve similar embeddings, given an input embedding.
From the nearest neighbors, we can get similar tweets and we compare our input tweet with similar tweets using a model similar to the zero-shot classification model. The model tells us if the inputs contradict or not. If they do not and we have a high score, we can assume that the inputs are similar and can assign the same label to the query tweet. The label corresponding to the tweet combination with the highest score is returned.
How we built it
Python is the main language we used to build the project. We built the backend of all the 3 mentioned components using flask. We love Flask as it is really easy to develop servers.
We used Pytorch and the Hugging face library to implement the amazing language models. We used the Twitter API to perform authenticaton and get the tweets.
The Webapp is lightweight and hosted on Heroku. The Elixr and MisMatch servers are hosted on AWS with a GPU instance.
Challenges we ran into
We propose a zero-shot classification approach to classify tweets and filter feed. One of the problems that we might find in this approach is model bias. We need to address biases and ensure that no tweet is misclassified as this will directly impact a person's ability to convey his thoughts and be heard.
The model we are proposing to use was pretrained on XNLI corpus It works fabulously but we will be able to get better results if we pretrained the model based on a dataset-specific to twitter type of content.
The false information system had a few issues too but this was mostly because of the type of data we were indexing. Some data inputs did not give the whole context and were labeled as false hence the model was misclassifying. After cleaning the data and preprocessing the Twitter input, we were able to get better performance.
Accomplishments that we're proud of
We were really impressed with ourselves that we were able to work on topics that most social media companies face. We were proud that we were able to deliver the project at least to our level of satisfaction.
We think that it is a good base and can be made better with further development.
What we learned
We learned a lot tbh. We learned how to work as a team. We learned how to deploy on AWS. We learned all the things we could use the Twitter API for.
We also learned a lot from the workshop related to improving our resume, building products for the user, and so on.
What's next for Ribitter
We would now like to implement multimodal hate detection on Twitter to identify hate speech from images and texts jointly. We had been working on the Facebook AI challenge previously and placed 14th on the leaderboard getting a 0.07 increase in AUC compared to Facebook's state-of-the-art model. It would be interesting to have our solution for the challenge implemented as a service.






Log in or sign up for Devpost to join the conversation.