-
-
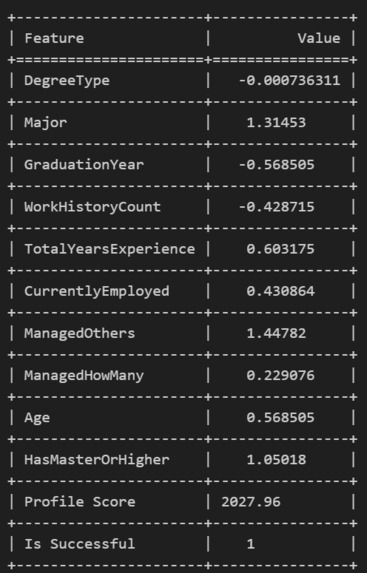
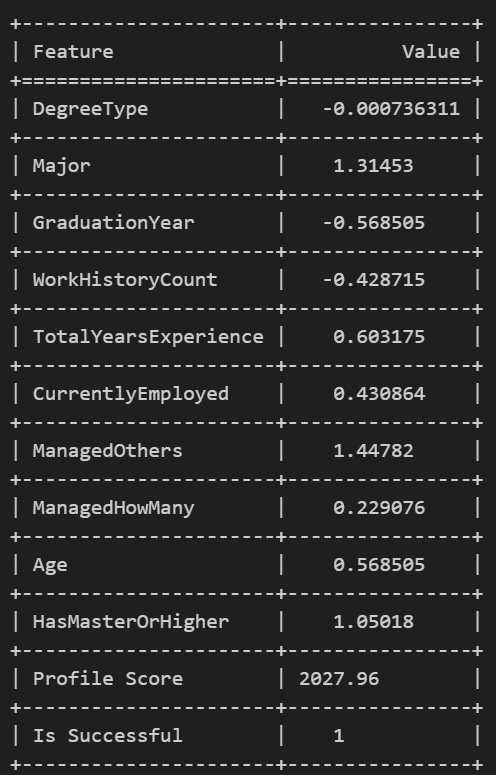
Feature Scorer
Inspiration💡
- Applying to Jobs today has still been following the traditional methods of applying on resume-shortlisting websites and receiving a cold reply or at most times no replies from the said organisations. The key problem that candidates face in such scenarios is the lack of tangible understanding the lackonas, pitfalls that cause them to be rejected at multiple job listing websites as there is generally less or no reviews upon their candidature.
- Secondly, Students are often confused about the type of job roles they are a fit for right after their graduation, or maybe even before. If they could be connected with the right kind of objective data understanding as to the careers pursued by other people at their age with similar profiles, they would be at a much better state of understanding what sort of career options are available to them.
What it does 🧭
Our Project aims to achieve a objective solution to these 2 growing problems:
- Giving candidates tangible profile scores based on their previous qualifications, achievements and extracurriculars.
- Connecting candidates to the right domains of jobs based on their profile to kickstart their careers.
How we built it 🔧
Our solution was built with techniques as data cleaning, feature engineering and modelling algorithms that can accurately rank candidates by comparing profiles of numerous other candidates. Dataset obtained through Kaggle, Coded with <3 using Python.
Tech Stack 🔨
- Data Science
- Python
- Jupyter Notebook
- Anaconda
- Git
- GitHub
Challenges we ran into 🏃♂️
- Implementing a scalable solution was difficult given the limited resources of our own local systems.
- The Dataset comprises of jobs from all possible domains ranging from truck drivers to accountants to developers, so the recommendations are based on an weighted average across categories.
Accomplishments that we're proud of 🏅
- We made the analysis to understand how the job market has evolved through the stages in different domains
- Implemented models for both problems with accurate enough results (based on testing with our very own profiles!)
What we learned 🧠
- ML techniques the non-traditional way - without the use of pre-defined models or complex techniques, we were able to derive substantial mathamatical equations using functions as cosine similarity, weighted averages, TF-IDF Vectorizer and K-means Clustering.
- For the same job, candidates could have widely ranging profiles; e.g. people could be working as SDE-2 at the age of 24 as well as 37, this wide variety led us to implement sampling within the dataset to avoid extreme differences between runs of the same candidate.
What's next ⏭
- For future additions we aim to take in a document which could be a candidate's own Resume and process the same without needing for additional inputs from the candidates, this in turn would be a better suited environment for candidates to test out their tangible strengths before presenting the same to a recruiter.
Built With
- anaconda
- jupyter
- kaggle
- python

Log in or sign up for Devpost to join the conversation.