-
-
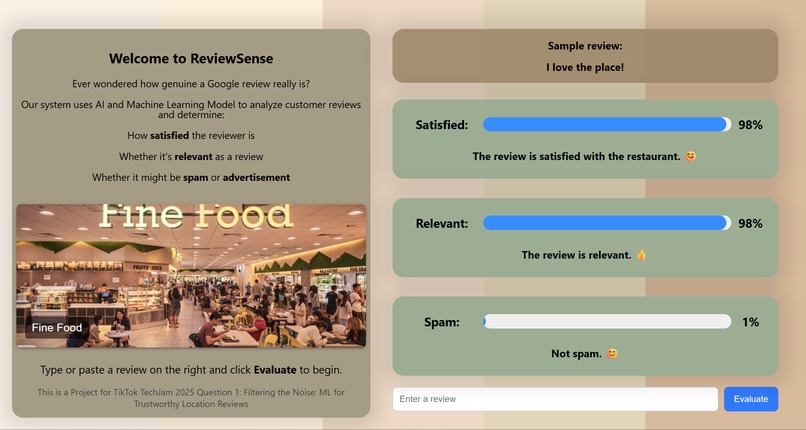
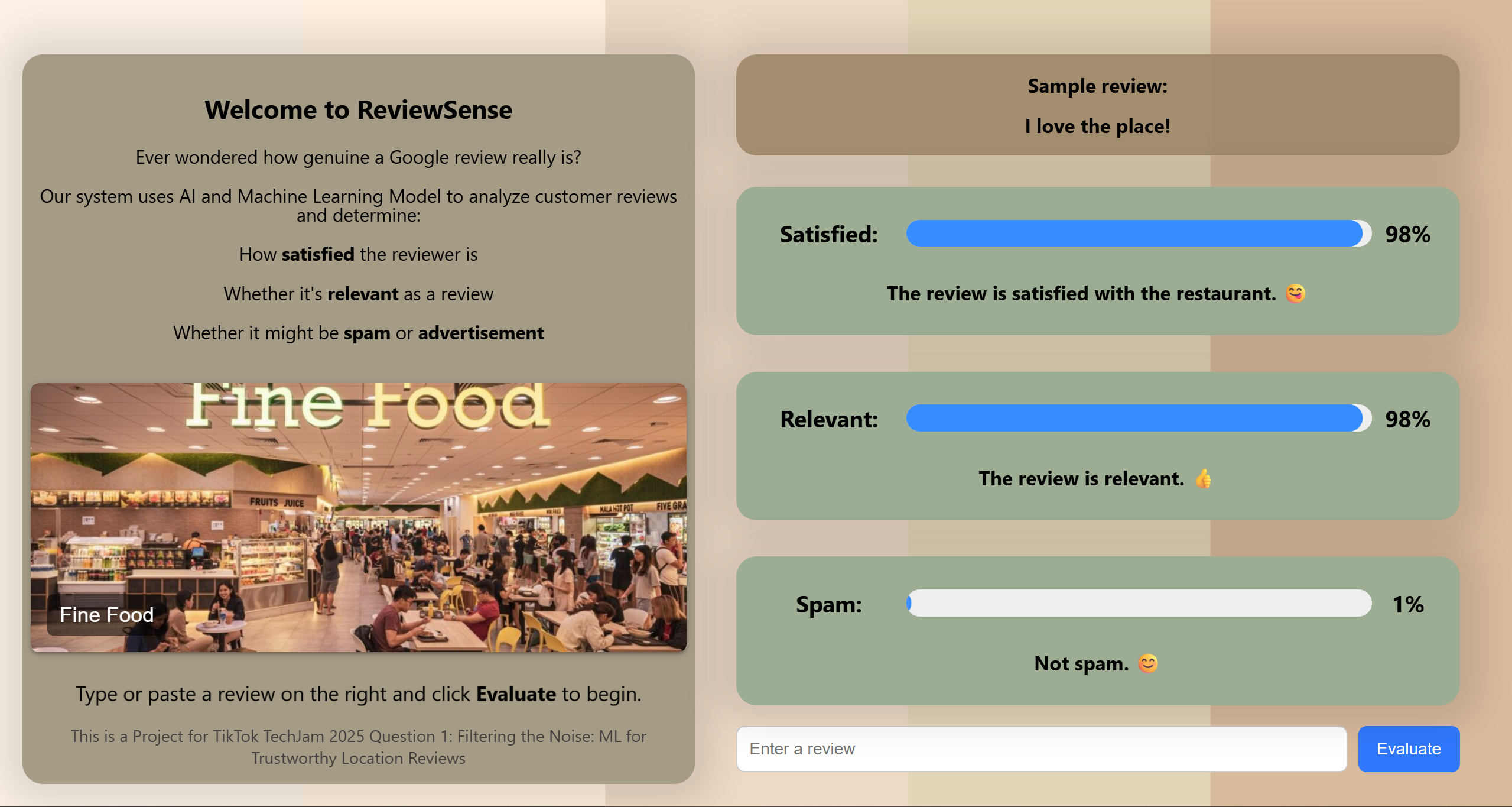
React.js UI design
-
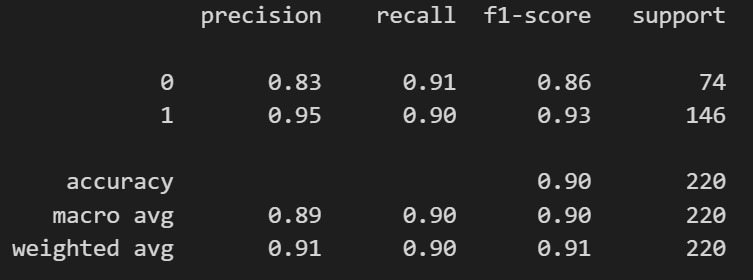
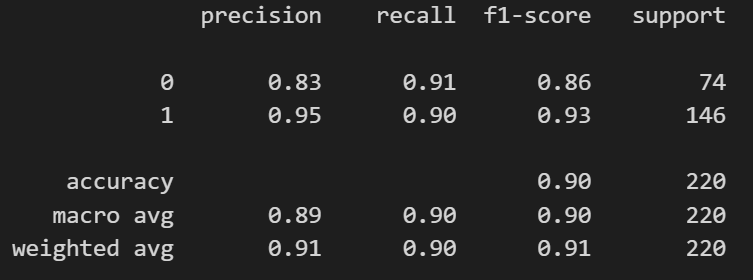
Validation Set Accuracy
-
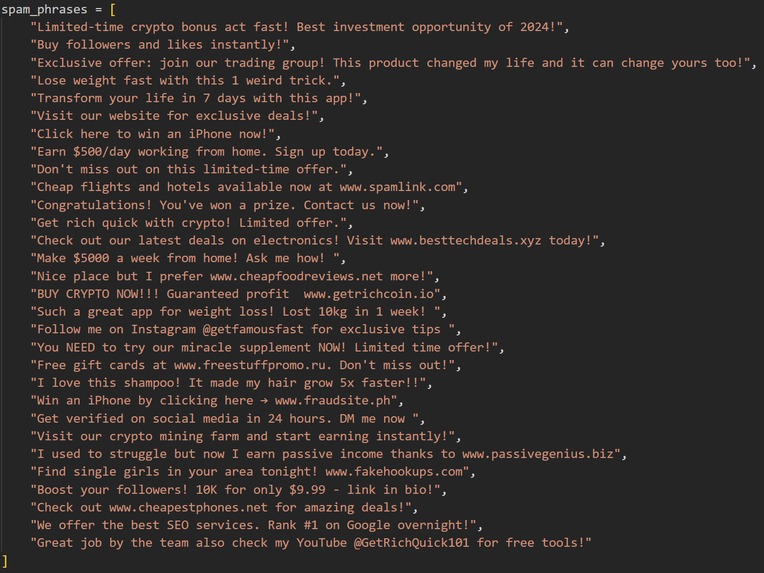
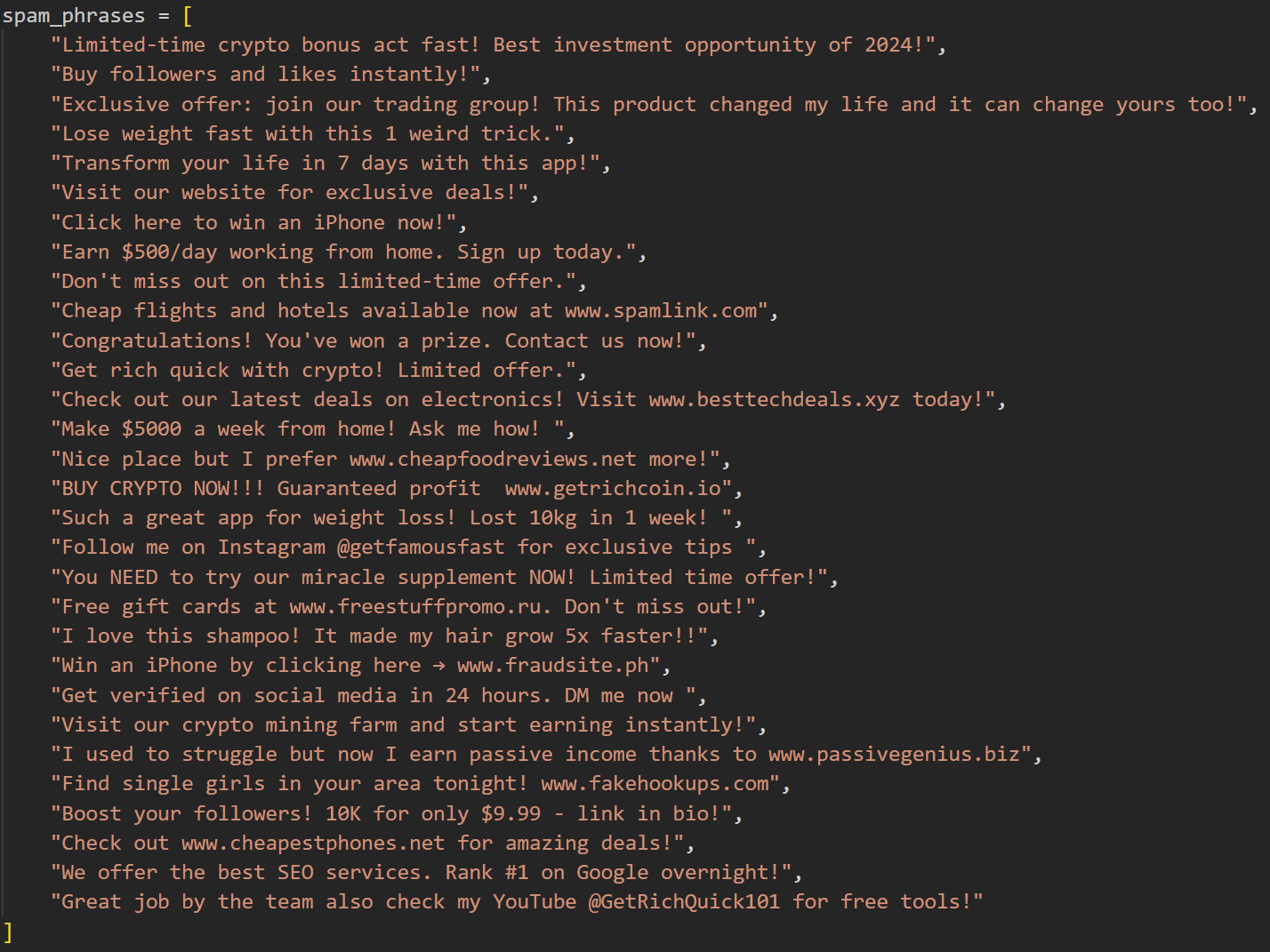
Generating Spam Reviews LOL
Project Story: Smart Review Classifier
About the Project
In today’s digital age, businesses are flooded with online reviews—many of which are valuable, but others may be irrelevant or even spam. Inspired by this challenge, we set out to build an intelligent web-based system that can automatically evaluate user-generated reviews across three key dimensions:
Satisfaction: Does the customer sound satisfied?
Relevance: Is the review actually about the business or service?
Spam Detection: Is the review genuine, or does it show signs of spam or advertising?
Our goal was to empower users and businesses alike with a tool that can instantly analyze feedback, improving trust and streamlining moderation.
What We Learned
Over the course of the project, we deepened our understanding of:
Natural Language Processing (NLP) pipelines using transformers and BERT.
Multi-label text classification, where each review can have multiple labels (satisfied, relevant, spam).
Data preprocessing and labeling, including the generation of realistic spam samples for training.
Deployment-ready ML models using PyTorch and HuggingFace Trainer.
Building full-stack web applications with Flask (Python) and React (JavaScript).
UI/UX design principles for a clean, interactive user interface.
How We Built It
Data Collection & Preprocessing:
We aggregated real Google reviews and manually labeled a portion of them.
We added synthetic spam reviews to balance the dataset.
Labels were assigned in a range between 0 and 1:
satisfied, relevant, spam∈[0, 1]
Model Training:
Used bert-base-uncased from HuggingFace as a base model.
Converted texts to token encodings with AutoTokenizer.
Implemented a PyTorch Dataset class for custom training.
Trained a multi-label classifier with 3 output neurons using sigmoid activation.
Evaluation:
Split the dataset into training and validation sets (80/20).
Trained the model with the Trainer API from transformers.
Saved the best model and tokenizer using .save_pretrained().
Frontend and Backend Integration:
React frontend with input box and evaluation UI.
Flask backend loads the model and tokenizer, receives review text via POST, and returns prediction.
Challenges Faced
Labeling Quality: Many real reviews are ambiguous—what counts as spam or irrelevant can be subjective.
Imbalanced Classes: Spam reviews are rare, so we had to generate synthetic ones for effective training.
Multi-label Logic: Unlike single-label classification, our model needed to output independent probabilities for each label, requiring sigmoid activation and threshold tuning.
Web Deployment: Ensuring smooth communication between React (frontend) and Flask (backend) required careful CORS and async setup.
Key steps:
Preprocess the Data
By writing prompts to ChatGPT API like this and passing reviews 10 by 10 from the Original dataset Google Maps Restaurant Reviews
system_instruction = '''
I will give you 10 Google reviews with number labels.
For each one, return a JSON object with the following keys:
- "satisfied": 1 if the customer seems satisfied, 0 if not.
- "relevant": 1 if the review is relevant to the business/location, 0 if not.
- "spam": 1 if the review looks like spam or advertisement, 0 if not.
Return the result in this format:
[ { "review": <number>, "firstword" : <The first word>, "satisfied": 1, "relevant": 1, "spam": 0 }, ... ]
for example: given "Review 5: Generally good."
return { "review": 5, "firstword" : Generally, "satisfied": 1, "relevant": 1, "spam": 0 }'''
ChatGPT API will return a JSON-format file to be directly appended to combined_reviews.csv.
Data will be loaded and sliced by
df = pd.read_csv("combined_reviews.csv")
texts = df["text"].astype(str).tolist()
labels = df[["satisfied", "relevant", "spam"]].astype(int).values.tolist()
Tokenize
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
encodings = tokenizer(texts, truncation=True, padding=True, max_length=512)
Feed into transformer
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=2,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_dir="./logs",
logging_steps=10,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="eval_loss"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
trainer.train()
Save the trained model
model.save_pretrained("saved_multilabel_model/")
tokenizer.save_pretrained("saved_multilabel_model/")
Final Outcome
The final product is a deployable web app that allows users to input any review text and immediately see:
Whether the review is satisfied
Whether it's relevant
Whether it looks like spam
The model responds within seconds, and the UI is clean, intuitive, and informative.


Log in or sign up for Devpost to join the conversation.