-
-
Landing Page
-
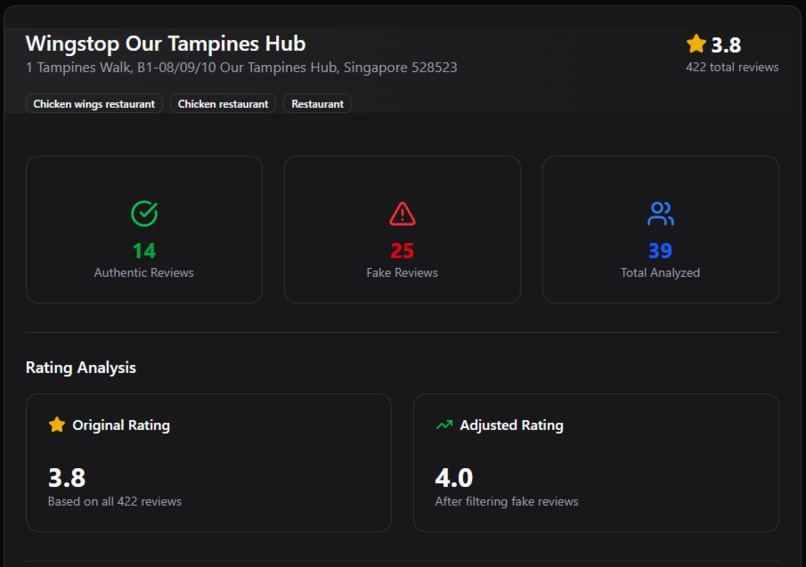
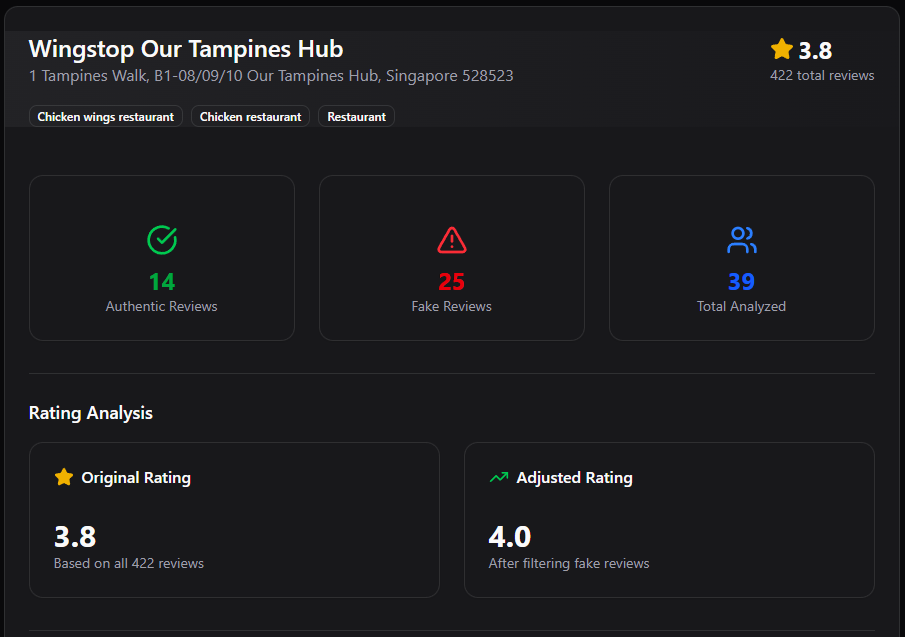
Review Results
1. Data Pipeline Setup & Initial Modeling
reviews² uses a sophisticated two-stage AI pipeline to improve review quality and relevancy:
Stage 1: AI-Powered Classification with DistilBERT
- Model Architecture: Fine-tuned DistilBERT with 6 transformer layers and 768 dimensions
- Training: 2,614 auto-labeled reviews with WordPiece tokenization (512 token limit)
- Performance: 90.1% overall accuracy
- Classification Categories:
- Authentic Reviews (92.5% F1): Genuine customer experiences
- Fake Reviews (91.9% F1): AI-generated/fraudulent content
- Low Quality Reviews (89.2% F1): Poorly written/unhelpful content
- Deployment: Containerized FastAPI service on Google Cloud Run with batch processing optimization
Stage 2: GPT-4 LLM Analysis
- Selective Processing: Only reviews classified as "Authentic" proceed to analysis
- AI-Generated Outputs:
- Condensed summary of authentic review insights
- Adjusted rating based on verified genuine feedback
- Overall sentiment analysis of authentic content
- Quality Assurance: Eliminates fake and low-quality content from final analysis
Stage 3: Consumer-Facing Application
- Input Method: Simple Google Maps URL paste-and-analyze workflow
- Results Dashboard: Comprehensive breakdown showing review quality distribution, authentic review counts, and AI-driven insights
- Accessibility: Responsive design optimized for desktop, tablet, and mobile devices
- Live Application: Available at https://reviewstwo.vercel.app/
This two-stage approach efficiently enforces quality policies at scale while providing consumers with reliable, actionable insights through a modern, accessible web interface.
2. Specific Problem Statement Tackled
The system was designed to directly address the first problem statement “Filtering the Noise: ML for Trustworthy Location Reviews” with the challenge prompt “Design and implement an ML-based system to evaluate the quality and relevancy of Google location reviews.”
3. Development Tools Used
- Code Editors: Cursor, Visual Studio Code, Claude Code
- Classification Model Development: PyTorch, DistilBERT, Scikit-learn, Pandas, NumPy
- Orchestration and Deployment: GCP, Docker, Vercel, etc.
4. APIs Used
The project integrates several key APIs to function:
- Apify API: Used for professional, real-time web scraping of Google Maps reviews and location data.
- OpenAI API: Utilized for two purposes:
- GPT-4o-mini for the intelligent auto-labeling of the training dataset.
- GPT-4 for the in-depth analysis and summarization of authentic reviews in the main application.
5. Libraries and Frameworks Used
The system is built on a modern, high-performance tech stack:
- Classification Model:
- PyTorch: Core deep learning framework
- Hugging Face Transformers: Pre-trained DistilBERT model and training pipeline
- Scikit-learn: Performance metrics and evaluation
- Pandas & NumPy: Data manipulation and processing
- Backend API:
- FastAPI: High-performance, asynchronous API framework
- Uvicorn: ASGI server for FastAPI applications
- httpx: Asynchronous HTTP client for external API calls
- OpenAI & Apify Client: GPT-4 integration and Google Maps scraping
- Frontend Application:
- Next.js: React framework with App Router
- TypeScript: Type-safe JavaScript development
- Tailwind CSS & shadcn/ui: Styling and UI components
- Data Collection:
- Selenium WebDriver: Automated web scraping
- Google Places API: Restaurant discovery and metadata
- OpenAI GPT-4o-mini: Automated review labeling
- Deployment:
- Docker: Containerization
- Google Cloud Run: Serverless API hosting
- Vercel: Frontend hosting and CDN
6. Assets and Datasets Used
The classification model's accuracy is built upon a diverse and carefully curated dataset comprising 2,614 labeled reviews from multiple sources:
- Enhanced Dataset (Latest): 2,614 total samples with improved class balance
- Authentic Reviews: 1,371 (52.4%) - Genuine customer experiences
- Fake Reviews: 535 (20.5%) - Generic, AI-generated language
- Low Quality Reviews: 601 (23.0%) - Poorly written/unhelpful content
- Irrelevant Reviews: 107 (4.1%) - Off-topic content
- Data Sources:
- Google Maps Scraped Data: Reviews from diverse Singapore locations
- UCSD Dataset: US-based reviews for global review pattern understanding
- Kaggle Fake Reviews Dataset: Computer-generated reviews for enhanced fake detection training
- Labeling Process: All data was programmatically labeled using OpenAI's GPT-4o-mini through a few-shot learning approach, ensuring high-quality and consistent classification across four quality categories.
- Performance Metrics: The enhanced dataset achieved 90.1% overall accuracy with 91.9% F1 score for fake review detection, representing a significant improvement from the original baseline.
Built With
- fastapi
- gcp
- huggingface
- python
- transformer
- typescript










Log in or sign up for Devpost to join the conversation.