-
main page
-
posts
Inspiration
Our decisions today are driven by the views and experiences of those around us. When I decided I wanted to purchase a mechanical keyboard, I first looked to my friends and eventually online forums to make an informed decision. As more and more people come to share their interests with people online, entire communities with thousands of members are being built around the products and brands that they consume, making sites like Reddit and Twitter a premier source to learn about customer views and opinions. With this project, I wanted to make this process of learning from the thousands of voices online nearly instantaneous, by transforming qualitative data into holistic and aggregate information.
What it does
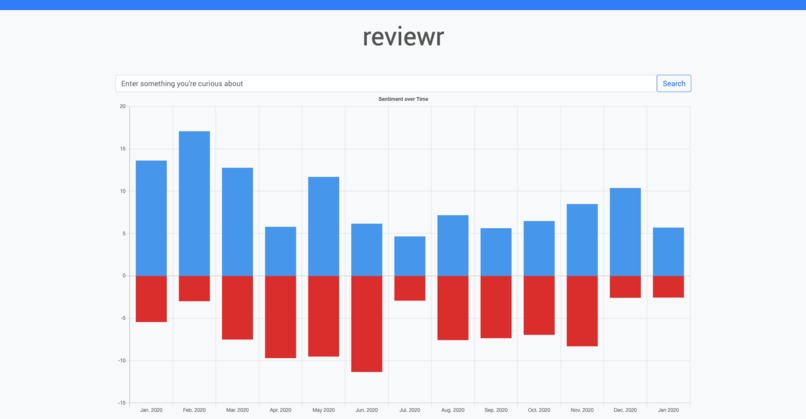
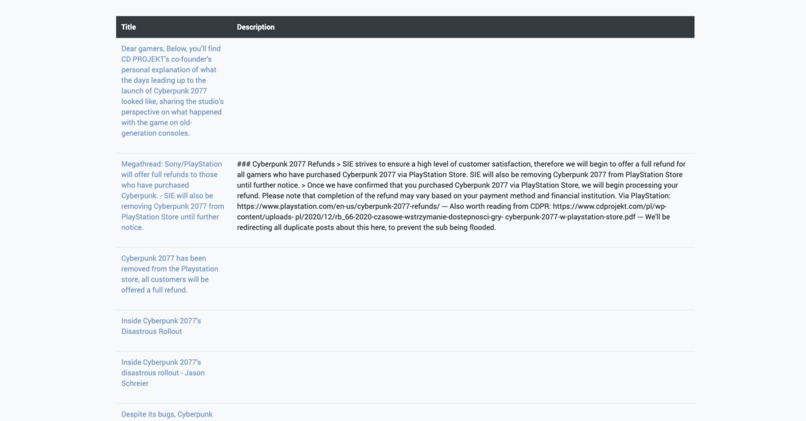
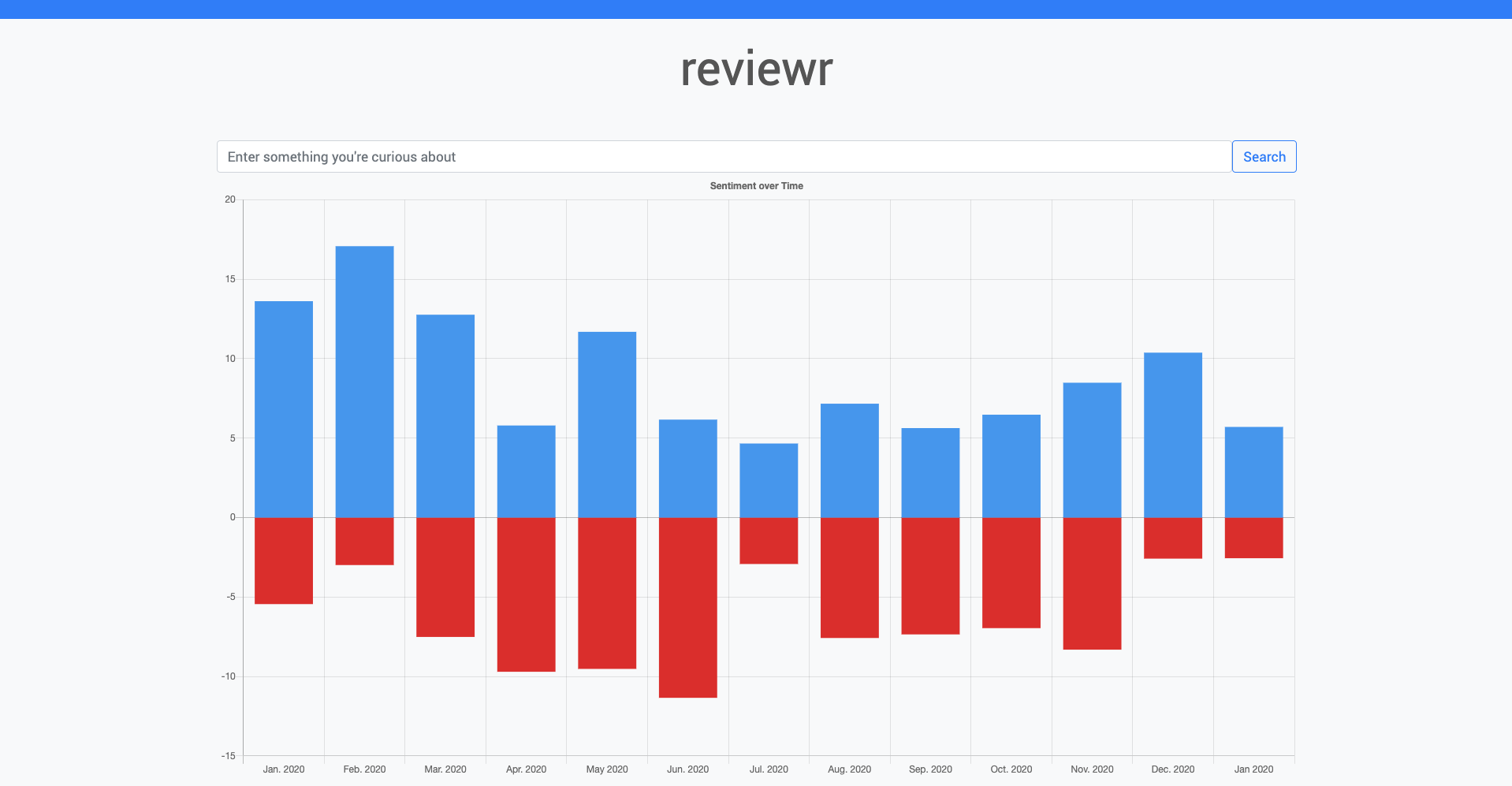
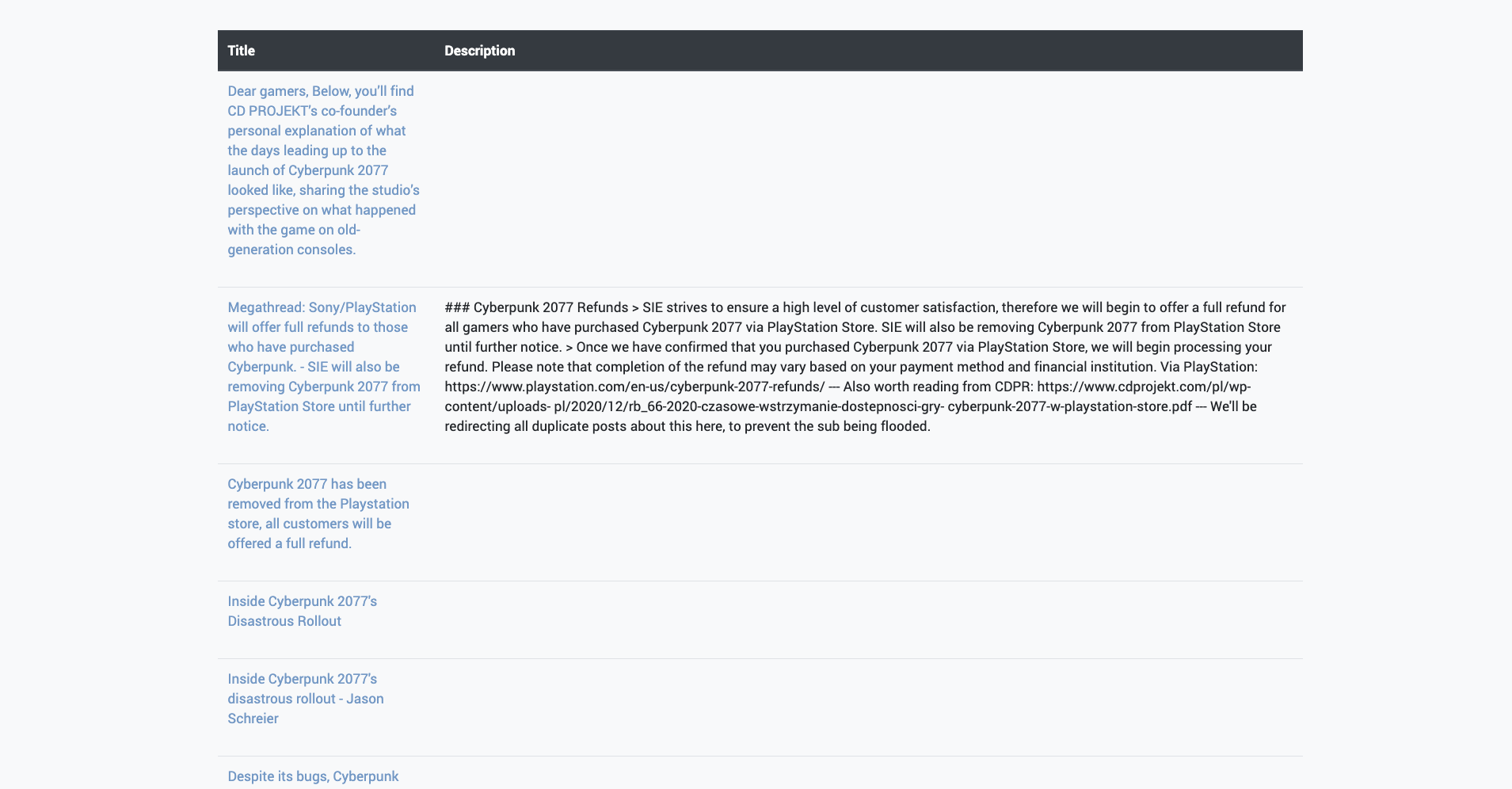
After entering a search term, reviewr scrapes the 2000 of the top posts mentioning your post each month. TextBlob is then used to determine the polarity of each post – how positive or negative it is. These values are then added together and passed into the frontend, which displays this data for the past year. This can be used to identify general brand perception, or trends that may have impacted its reputation. Scrolling down, several posts are then displayed and can be browsed through to identify current trends.
How I built it
This web app was built and designed with Flask and Bootstrap. I used the PRAW and Pushshift API to scrape data from different timeframes from Reddit. Chart.js was used for building the charts displayed in the web app. I fine tuned a model trained on a corpus of IMDB movie reviews for sentiment analysis using the NLTK.
Challenges I ran into
Near the end of the hackathon, I found out one of the features I needed from the PRAW API was removed two years ago, so I needed to make a quick switch to Pushshift. This new API was significantly slower, but luckily still provided the needed functionality.
Accomplishments that I'm proud of
I took on this project as a challenge for myself, and to quickly pick up on working with Flask. Getting the core functionality complete is something I’m very happy with, and I’m surprisingly content with the frontend.
What I learned
Optimizing API queries is hard.
What's next for reviewr
- Compare data between different search queries
- Train a model using datasets of social media posts
- Increase query size









Log in or sign up for Devpost to join the conversation.