-
-
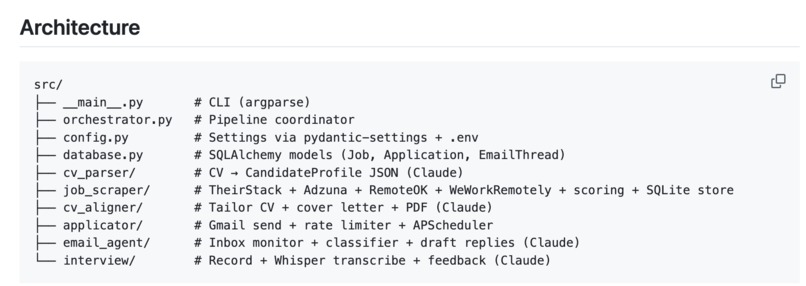
Modular project architecture — each pipeline step is an independent package with its own tests, connected through a shared database layer.
Reversed Recruiter
Inspiration
I'm a data scientist. I'm good at building models, writing pipelines, and making sense of data. But job hunting? That's a different kind of mess entirely.
A few months ago I found myself deep in the application grind — tweaking my CV for the 40th time, writing yet another cover letter that started with "I'm excited to apply for...", and toggling between LinkedIn, Indeed, and Gmail. One night, after spending three hours applying to six positions, I thought: I literally build automation systems for a living. Why am I doing this manually?
The job market has a strange asymmetry. Companies use ATS systems, automated screening, and AI-powered tools to filter thousands of applicants in seconds — but candidates are still expected to do everything by hand. Copy-paste your experience into yet another portal. Rewrite your summary for the 12th time this week. Refresh your inbox hoping for a reply.
Reversed Recruiter was born from a simple question: what if the candidate had an agent too?
What it does
Reversed Recruiter is an end-to-end AI agent that manages your entire job search pipeline. You upload your CV once, and the agent handles the rest:
- Parses your CV into a structured candidate profile — skills, experience, keywords, years in each role, education, certifications
- Scrapes job boards weekly and scores open positions against your profile using a matching engine that weighs keyword overlap, experience level, seniority alignment, and location fit
- Tailors your CV and cover letter per position — reshuffling emphasis, mirroring the job's language, highlighting the most relevant experience (without ever fabricating anything)
- Applies automatically to new matching jobs on a weekly cadence, attaching the tailored materials
- Monitors your inbox for recruiter replies, classifies them (interview invite vs. rejection vs. info request), drafts contextual responses, checks your Google Calendar for free slots, and books interviews for you
- Records and analyses interviews — transcribes the conversation, identifies strengths and missed opportunities, and generates a structured feedback report so you improve with every round
The goal is to turn job hunting from a draining, repetitive chore into a managed pipeline that works in the background while you focus on preparing for the interviews that actually matter.
How we built it
The stack is Python end-to-end, which made sense given my background in data science and the heavy LLM integration throughout.
CV Parsing combines traditional extraction with an LLM layer that does the semantic heavy lifting — understanding that "3 years at xxx as a Senior Analyst" .The parsed profile is stored as structured JSON that all downstream modules consume.
The matching engine went through an interesting evolution. My first instinct was to build a classical scoring formula — TF-IDF similarity, weighted feature vectors. But every job board structures its listings differently, and the parsed output varied wildly between sources. A rigid formula kept breaking on edge cases. So I pivoted. The matching engine now uses Claude as the evaluator — it reads the candidate profile alongside each scraped job description and makes a contextual judgment on whether the skills, experience, and seniority actually align. This turned out to be far more robust than any formula, because the LLM understands nuance that keyword matching misses. Critically, this isn't fully autonomous — every match the agent surfaces goes through a human approval gate. The agent proposes, you confirm or reject. This keeps you in control.
CV tailoring and cover letter generation are LLM-driven with strict guardrails — the system prompt explicitly forbids hallucinating experience. The agent can reorder, rephrase, and emphasise, but every claim must trace back to the original CV.
Email handling uses the Gmail API via OAuth2, with a classification step that routes recruiter replies into the right workflow. Interview scheduling integrates with Google Calendar to find open slots and propose times.
Testing and version control Every feature is built on a branch, then tests are written around it, and nothing gets committed until pytest is fully green. CI runs via GitHub Actions with conventional commit messages (feat:, test:, fix:) to keep the history clean and traceable.
Challenges we ran into
The "don't lie" problem. The hardest challenge by far. When tailoring a CV, the agent must never fabricate experience — only reshuffle and rephrase what's already there. I spent significant time on system prompts, validation logic, and structural tests to enforce this. It's a trust problem as much as a technical one.
Job board anti-scraping. LinkedIn really doesn't want you scraping their site (fair enough). I had to pivot from direct scraping to using API-based aggregators and designing the scraper module with a plugin architecture so new job sources can be swapped in without rewriting the pipeline.
The email tone problem. When your agent replies to a recruiter, it is you. Getting the tone right — professional but warm, enthusiastic but not desperate — required a lot of prompt iteration and a configurable "voice" setting so it doesn't sound robotic or generic.
Testing AI-generated output. Traditional unit tests assert output == expected, but you can't do that when the output is generated text. I had to develop a testing approach based on structural properties — does the cover letter mention the correct company? Does the tailored CV contain only skills from the original? Does the email reply address the recruiter by name? It's a different way of thinking about test coverage.
Scope discipline. This project could easily balloon into a full SaaS platform. Keeping it focused on the core six-step pipeline and resisting the urge to add "one more feature" before finishing the current phase was its own ongoing challenge.
Accomplishments that we're proud of
- The matching engine actually works. LLM-based approach handles the messy reality of inconsistent job board formats far better than any rigid formula could. Sometimes the best engineering decision is knowing when not to over-engineer.
- Zero hallucination in CV tailoring. After a lot of iteration, the tailoring module reshuffles and emphasises real experience without making anything up. Every generated bullet traces back to the original CV. This was the hardest thing to get right and I'm proud it holds up.
- The test suite is real. Not token tests written to check a box — actual meaningful tests that have already caught bugs before they hit
main. The test-first-merge workflow paid for itself within the first week. - Clean, modular architecture. Each step of the pipeline is an independent module with clear inputs and outputs. I can swap the job scraper, change the LLM provider, or replace the PDF generator without touching anything else. That kind of separation felt like the right investment early on.
- It actually saves time. Even in its current state, the pipeline has cut my weekly application effort from hours to minutes. That's the whole point — and it works.
What we learned
- That the best automation doesn't replace your judgment — it amplifies it. Reversed Recruiter still has approval gates. The agent proposes, you confirm.
- That LLMs need strict boundaries when working with personal data. "Be helpful" isn't enough of a system prompt — you need explicit constraints about what the model cannot do, and you need to test those constraints.
- That testing AI features requires a mindset shift. You can't assert on exact output, but you can assert on structure, presence, absence, and constraints. It's more like property-based testing than traditional unit testing.
- That good commit hygiene pays off fast. When something breaks, being able to
git bisectthrough clean, descriptive commits and find the exact change is worth every extra second spent writing a proper message. - That job hunting is, at its core, a data pipeline problem — and once you see it that way, the engineering becomes surprisingly natural.
What's next for Reversed Recruiter
- A visual dashboard so users can track their application funnel: applied → response → interview → offer, with conversion rates at each stage. Job hunting is basically a sales pipeline, and it should look like one.
- Browser automation via Playwright for jobs that require filling out application forms directly, rather than just email-based submissions.
- Multi-provider support — Outlook and other calendar systems beyond Google, and more job board integrations.
- Open-sourcing the project so other job seekers can run their own Reversed Recruiter and contribute modules back.
If this agent saves even one person from the soul-crushing monotony of the application grind, it was worth building.
Built With
- alembic
- apscheduler
- claude-api-(anthropic)
- fastapi
- google-calendar-api
- google-gmail-api
- httpx
- openai-whisper
- pdfplumber
- pydantic
- pytest
- python
- python-docx
- sqlalchemy
- uvicorn
- weasyprint

Log in or sign up for Devpost to join the conversation.