-
-

Thumbnail Image
-
cicd-pipeline
-
director-chat-flow
-
cloud-infrastructure
-
interleaved-output-flow
-
system-architecture
-
security-architecture
-
03-book-details
-
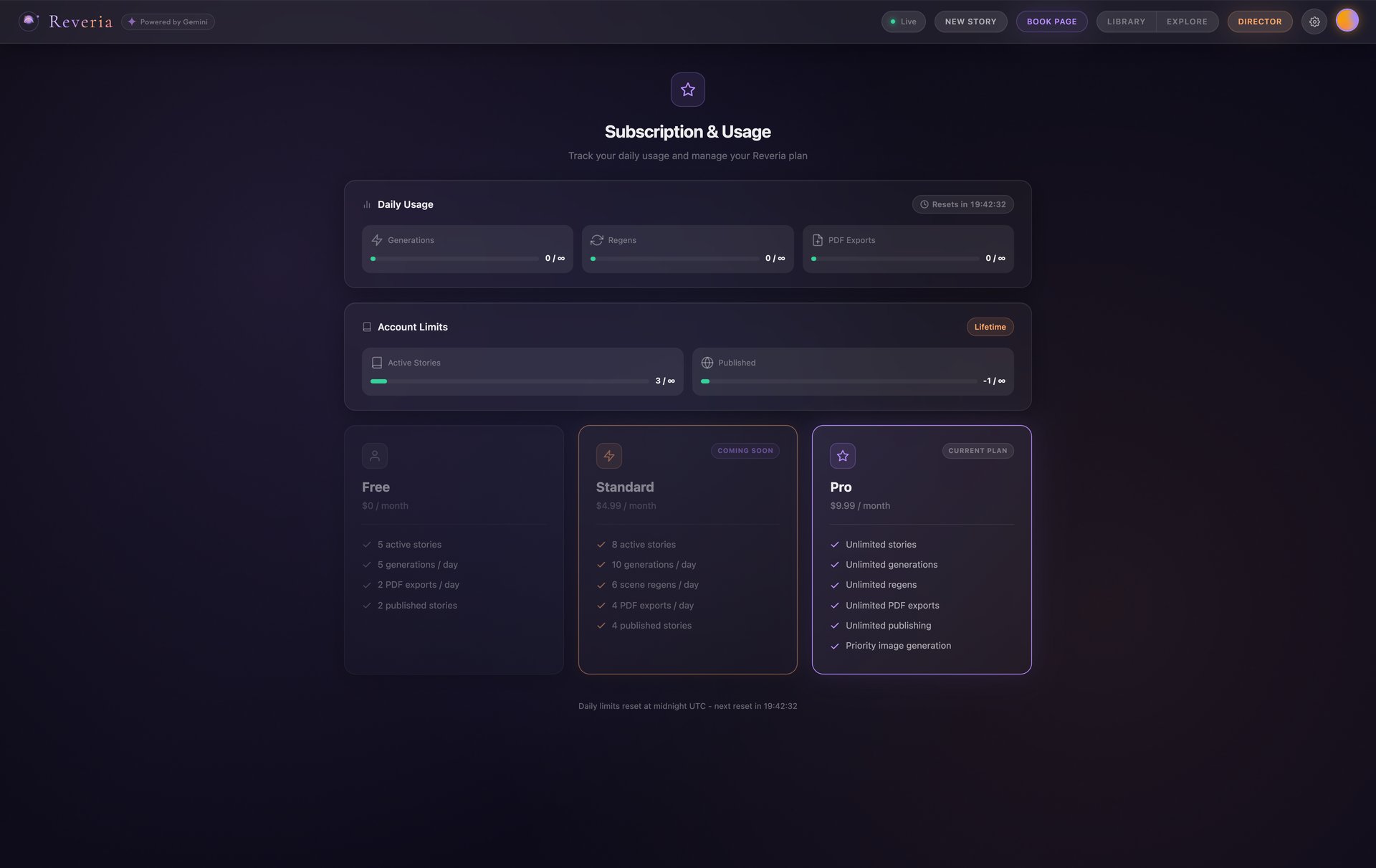
05-subscription-usage
-
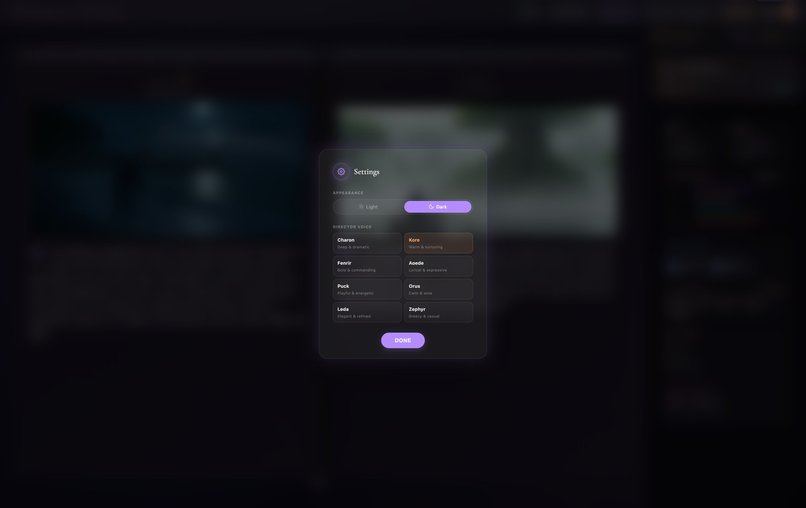
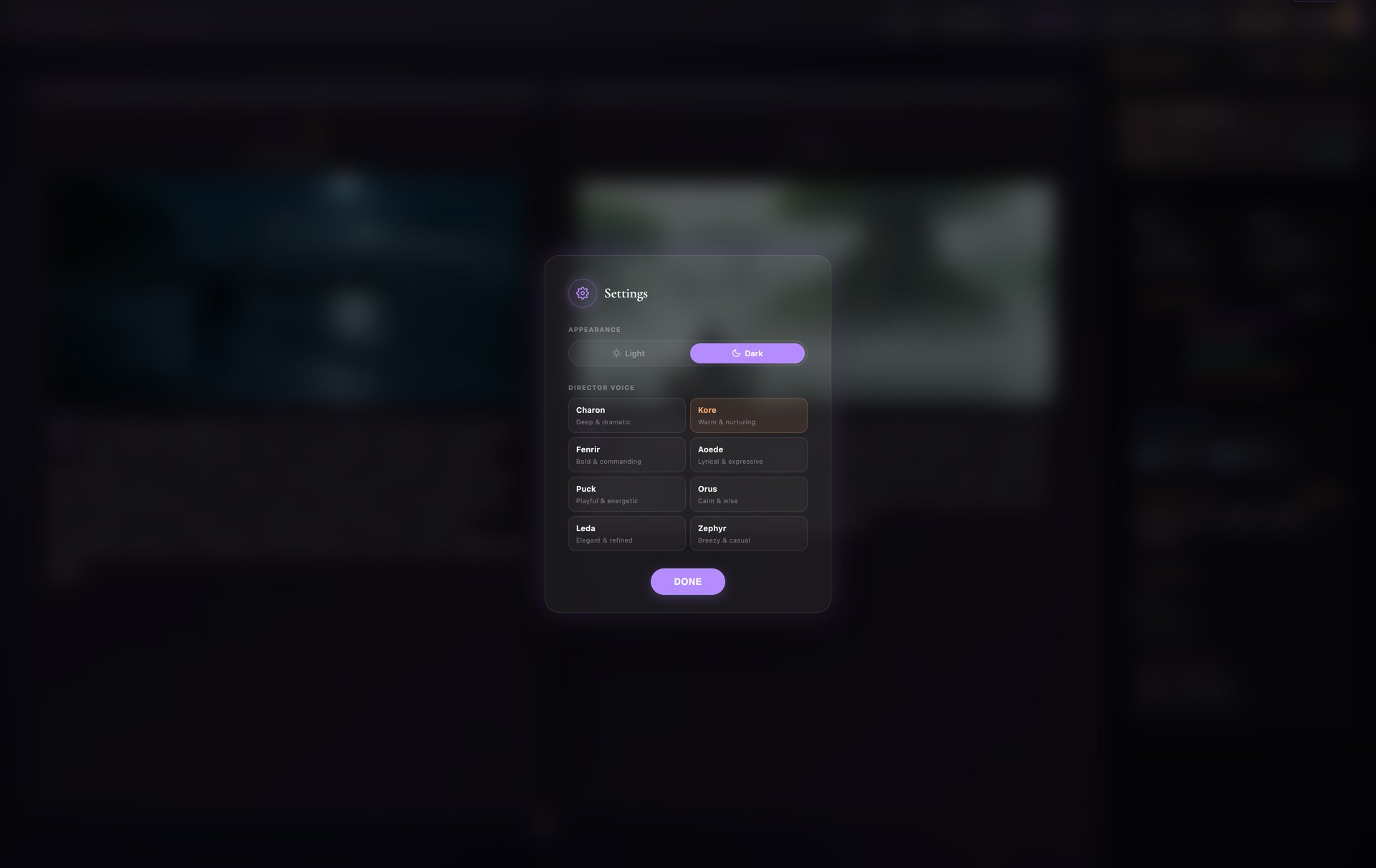
07-settings-dialog
-
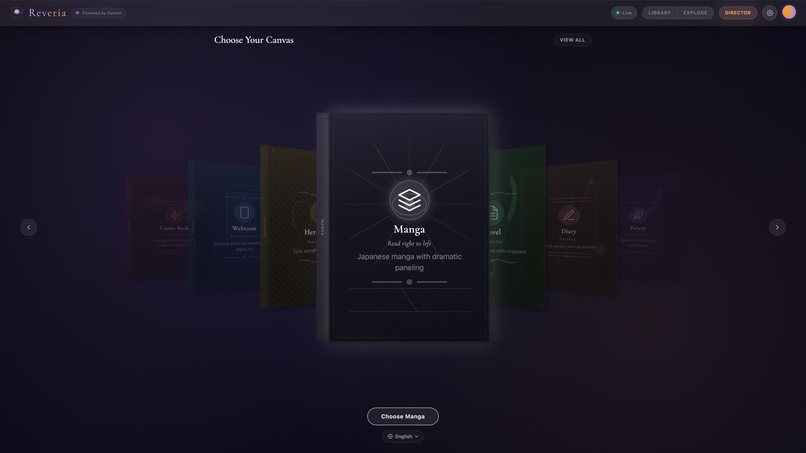
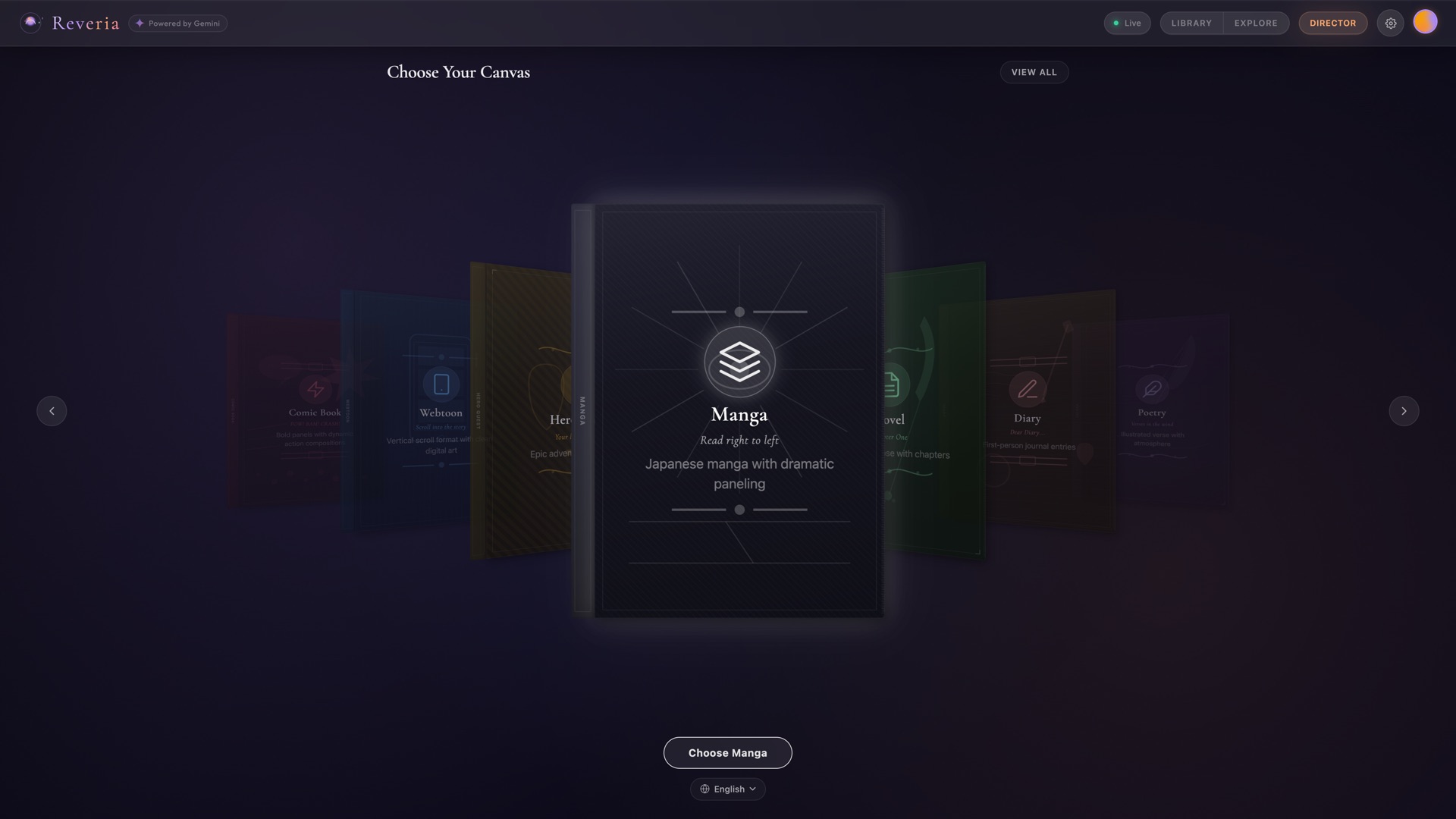
01-template-chooser
-
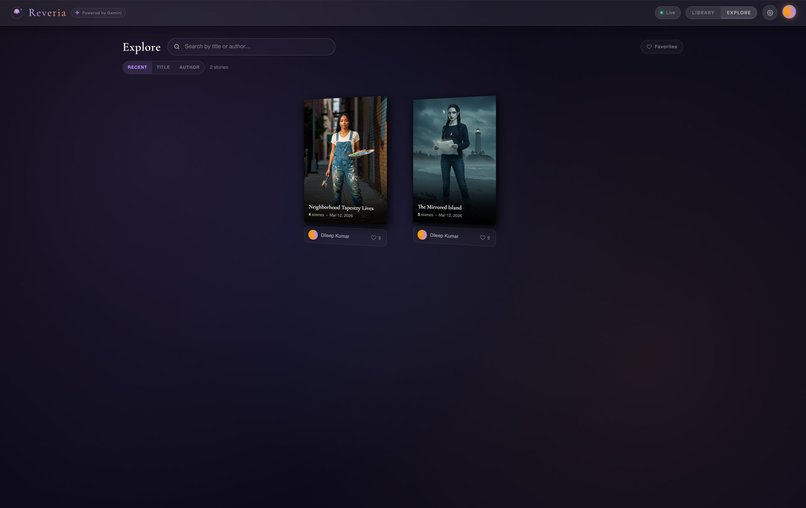
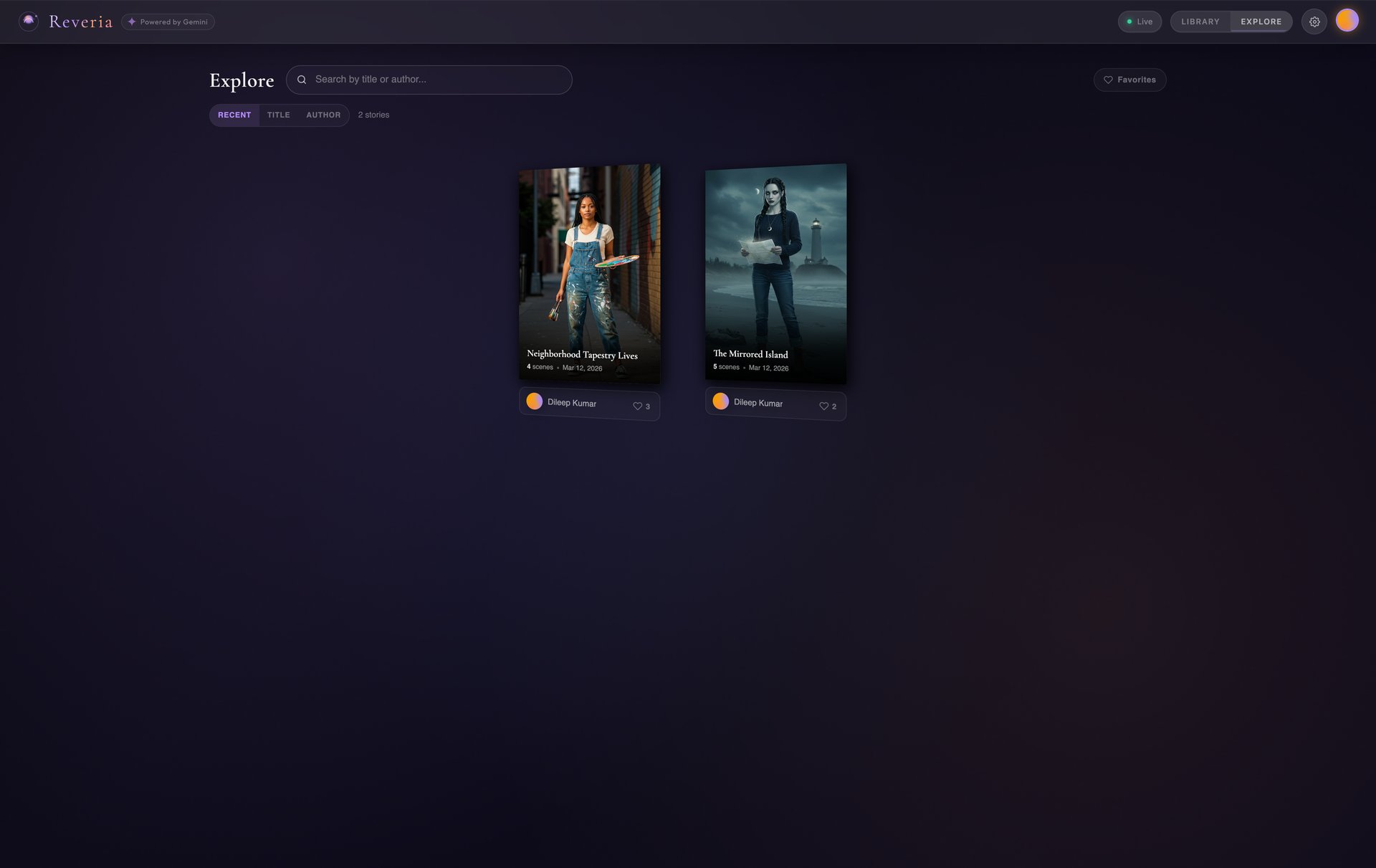
06-explore-page
-
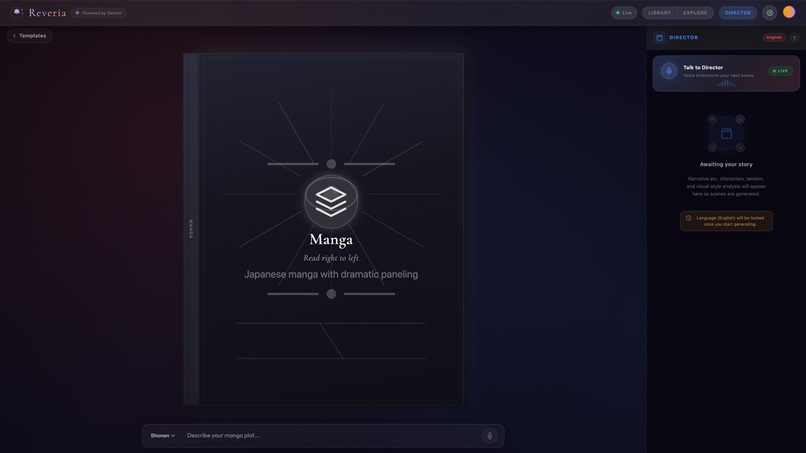
04-director-chat
-
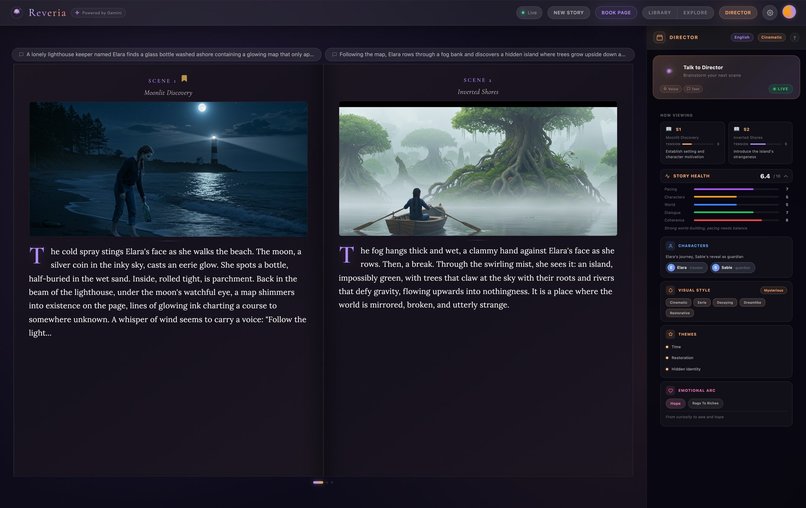
02-story-generation

What is Reveria?
Reveria is a multimodal AI story engine that turns a single sentence into a fully illustrated, narrated storybook in real time. But it doesn't start with a text box. It starts with a voice conversation.
Tap the Director orb and you're talking to an AI Story Director - a creative partner with a distinct voice and personality, powered by the Gemini Live API. Brainstorm out loud: "I'm thinking a noir detective story, but set in a floating city..." The Director pushes back, suggests twists, asks about tone. When the idea is ready, the Director triggers generation automatically using native tool calling. No buttons, no forms.
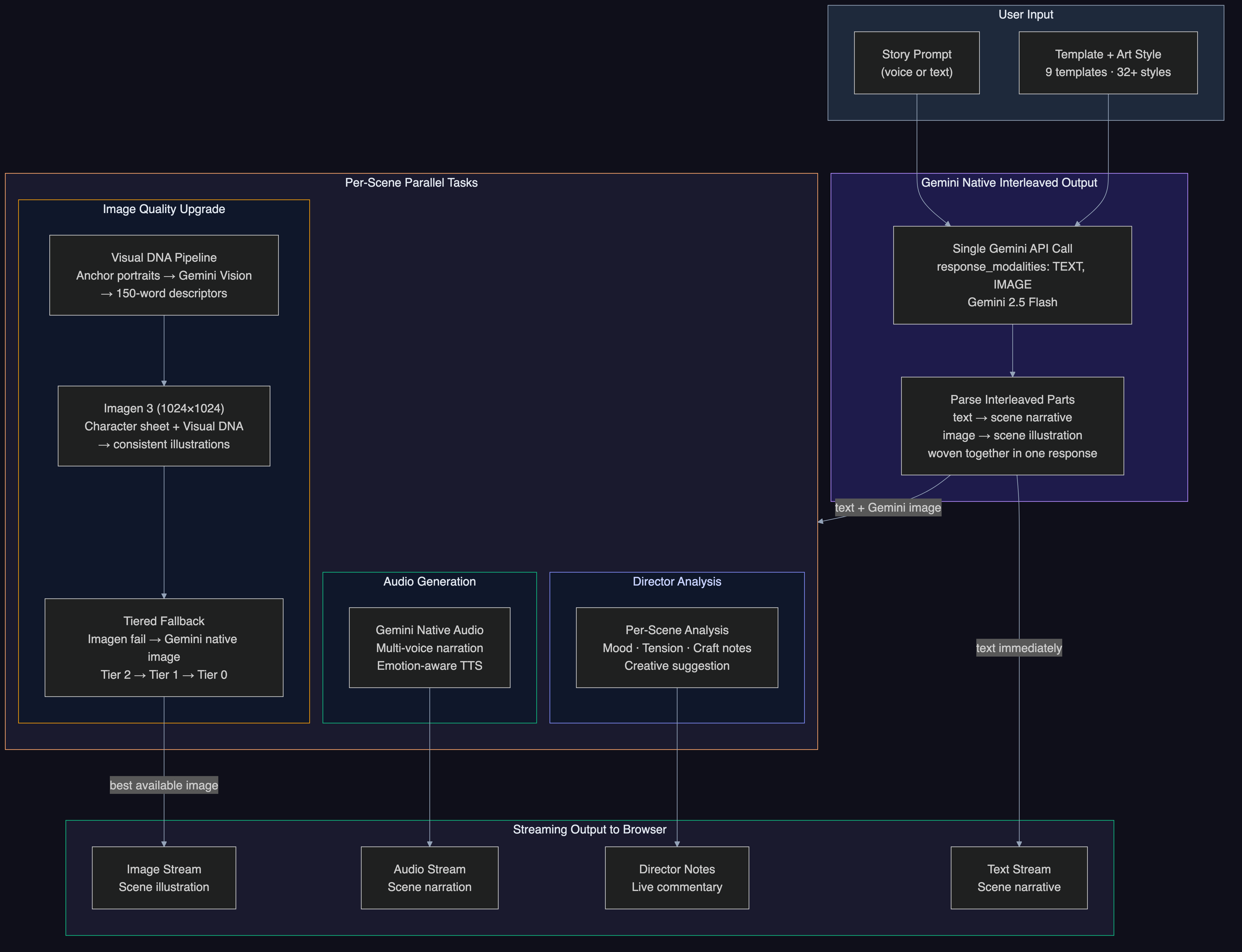
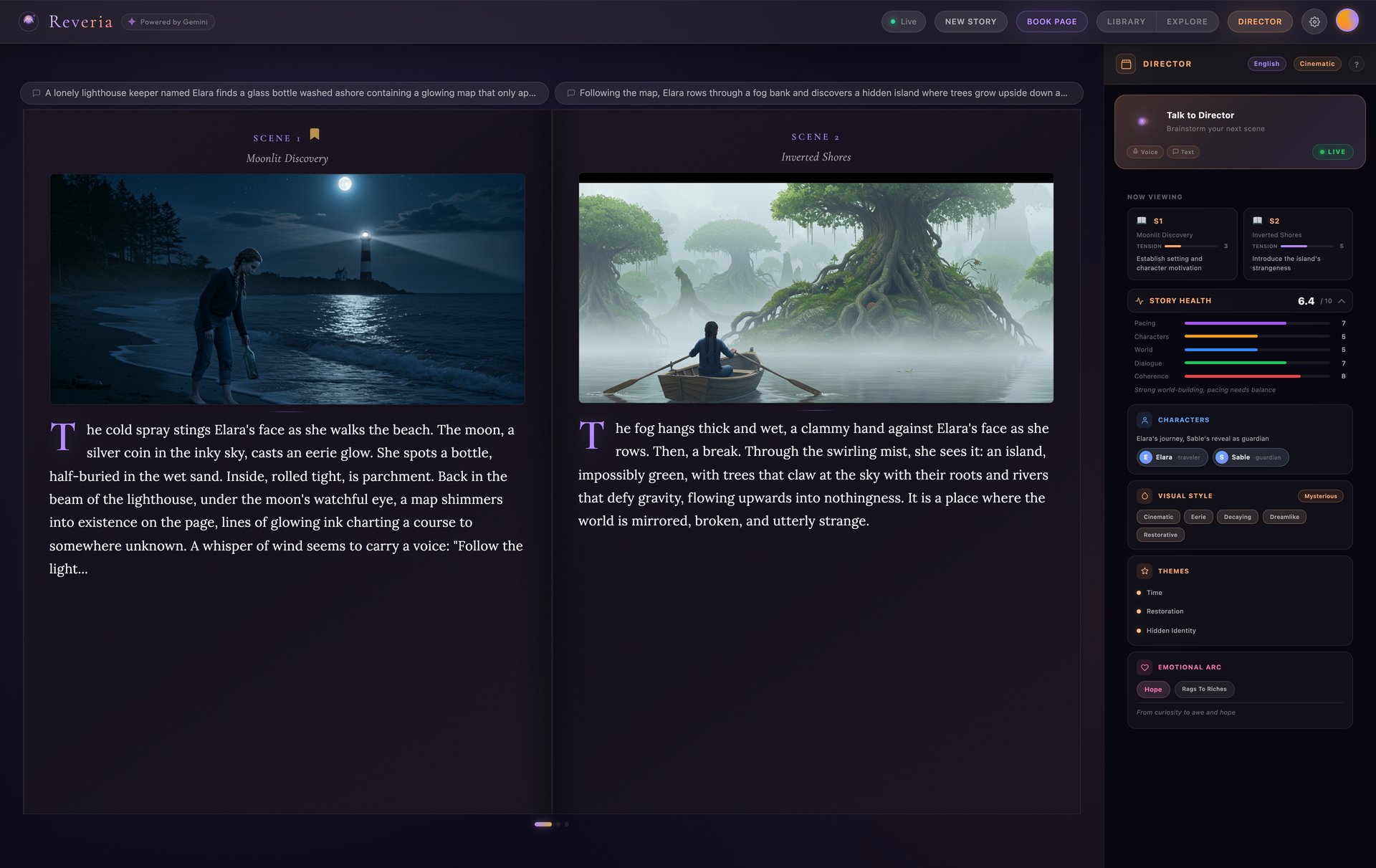
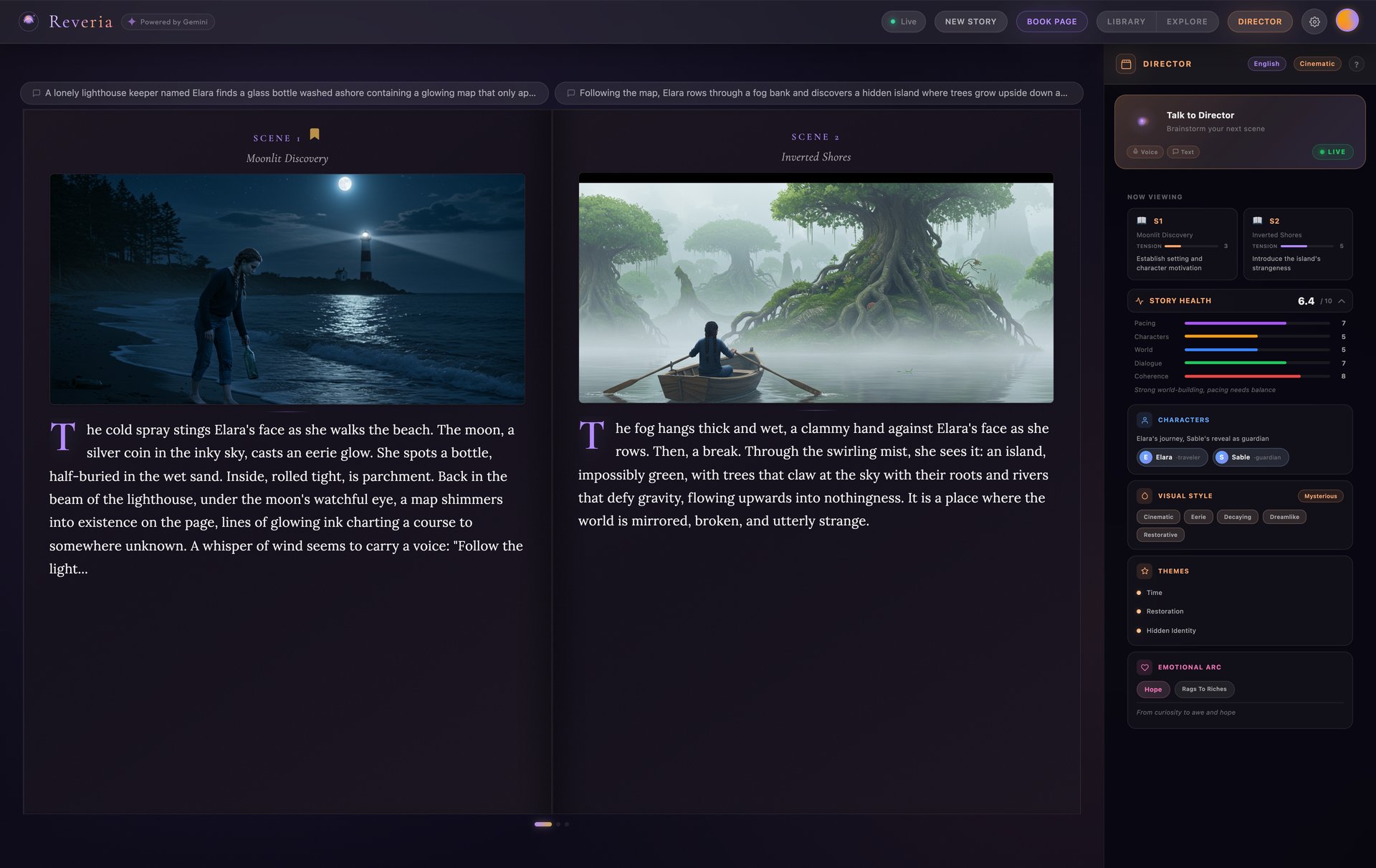
What happens next is where Gemini's interleaved output shines - text, images, and audio arrive seamlessly together:
- Text streams scene-by-scene as the Narrator writes your story
- Illustrations paint in for each scene via Imagen 3 as text completes
- Voice narration plays with audiobook quality via Gemini Native Audio
- The Director watches each scene and offers live creative commentary
- A flipbook materializes with a cinematic entrance animation
Everything arrives over a single WebSocket connection. Four AI agents working in parallel, each specialized for its task, coordinated by Google's Agent Development Kit (ADK).
Quick stats: 4 AI Agents | 14 Prompt Systems | 9 Story Templates | 30+ Art Styles | 8 Languages
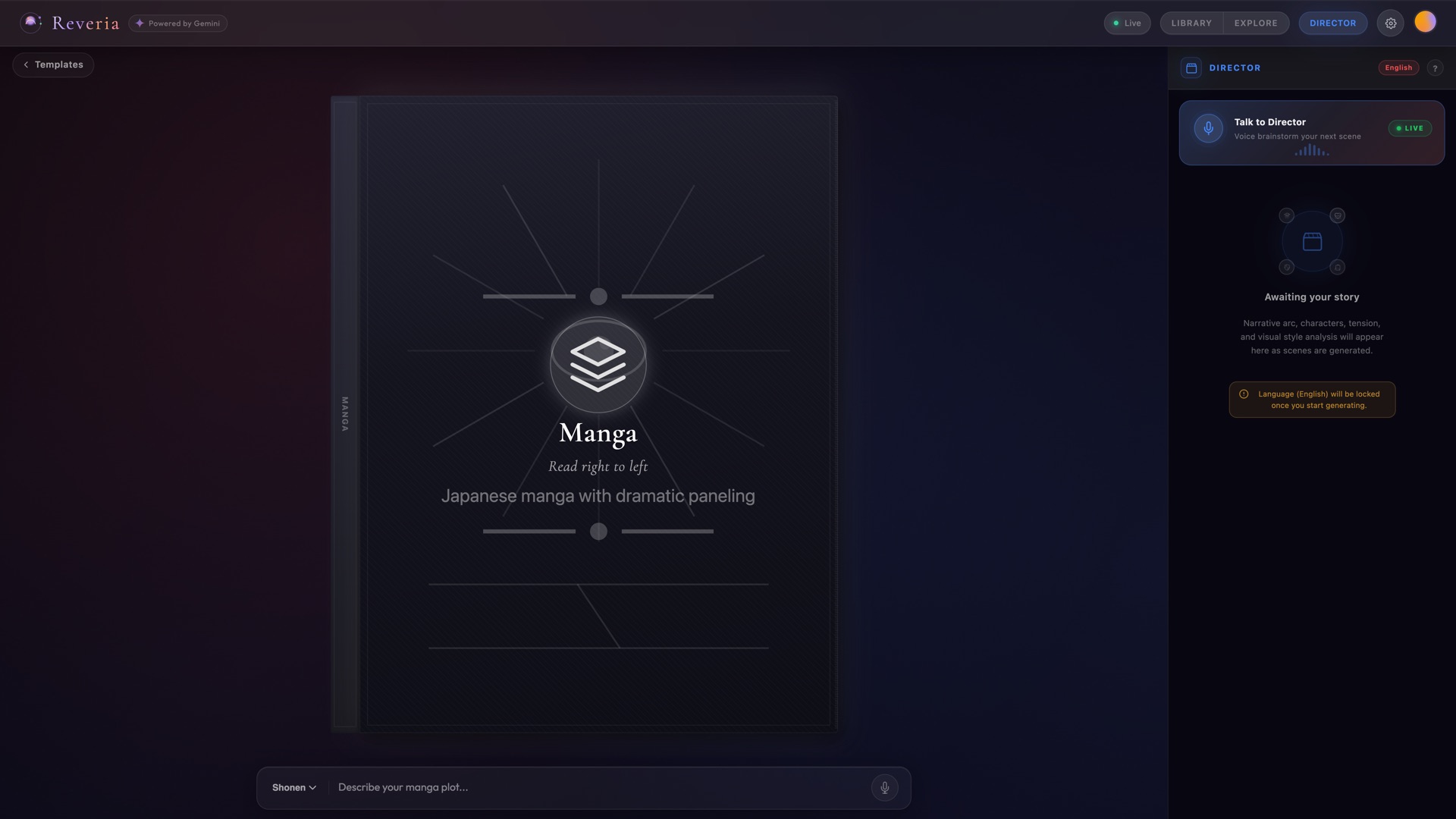
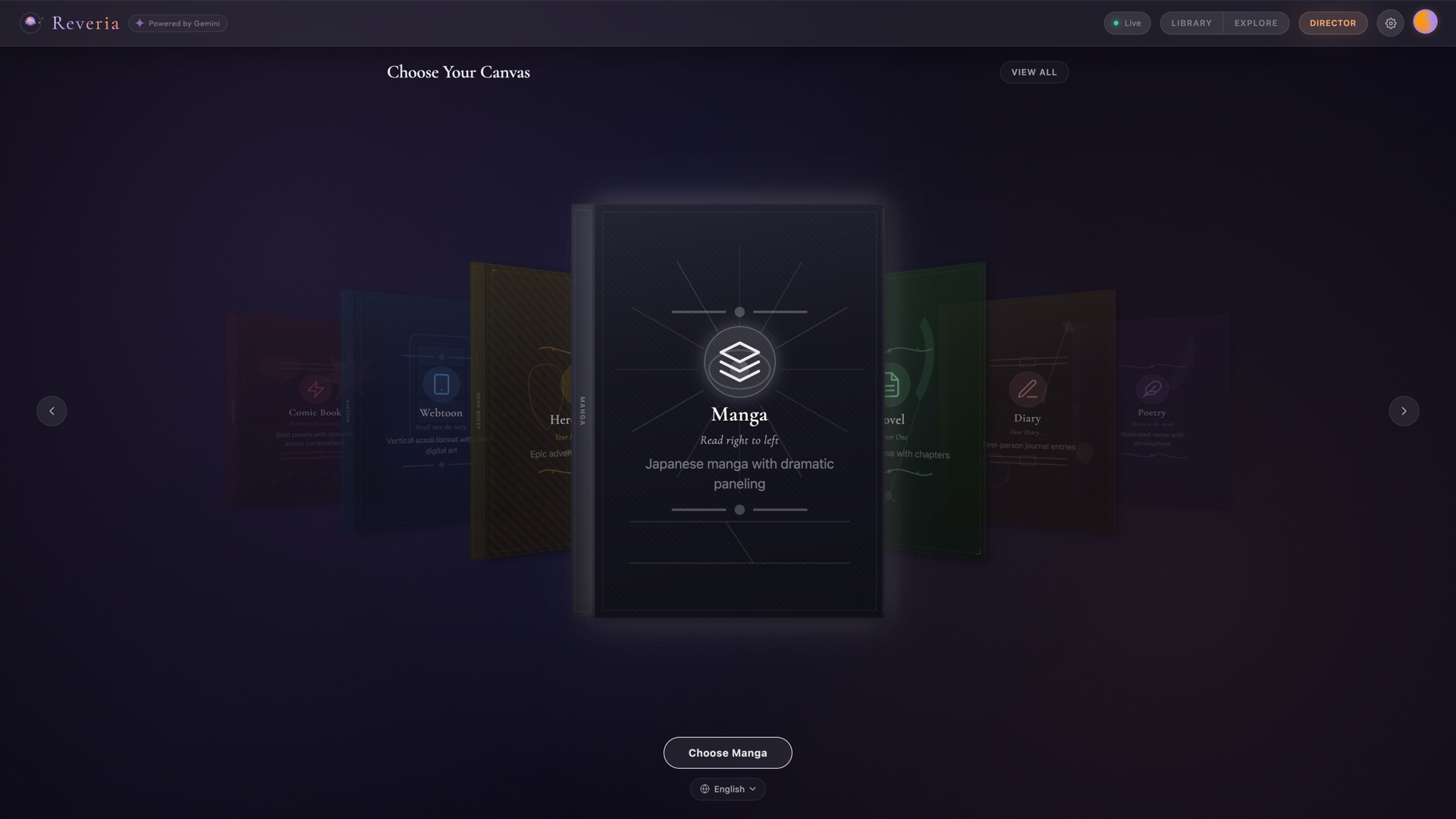 Template Chooser - 9 story templates via 3D carousel |
 Story Generation - Live text, image, and audio streaming |
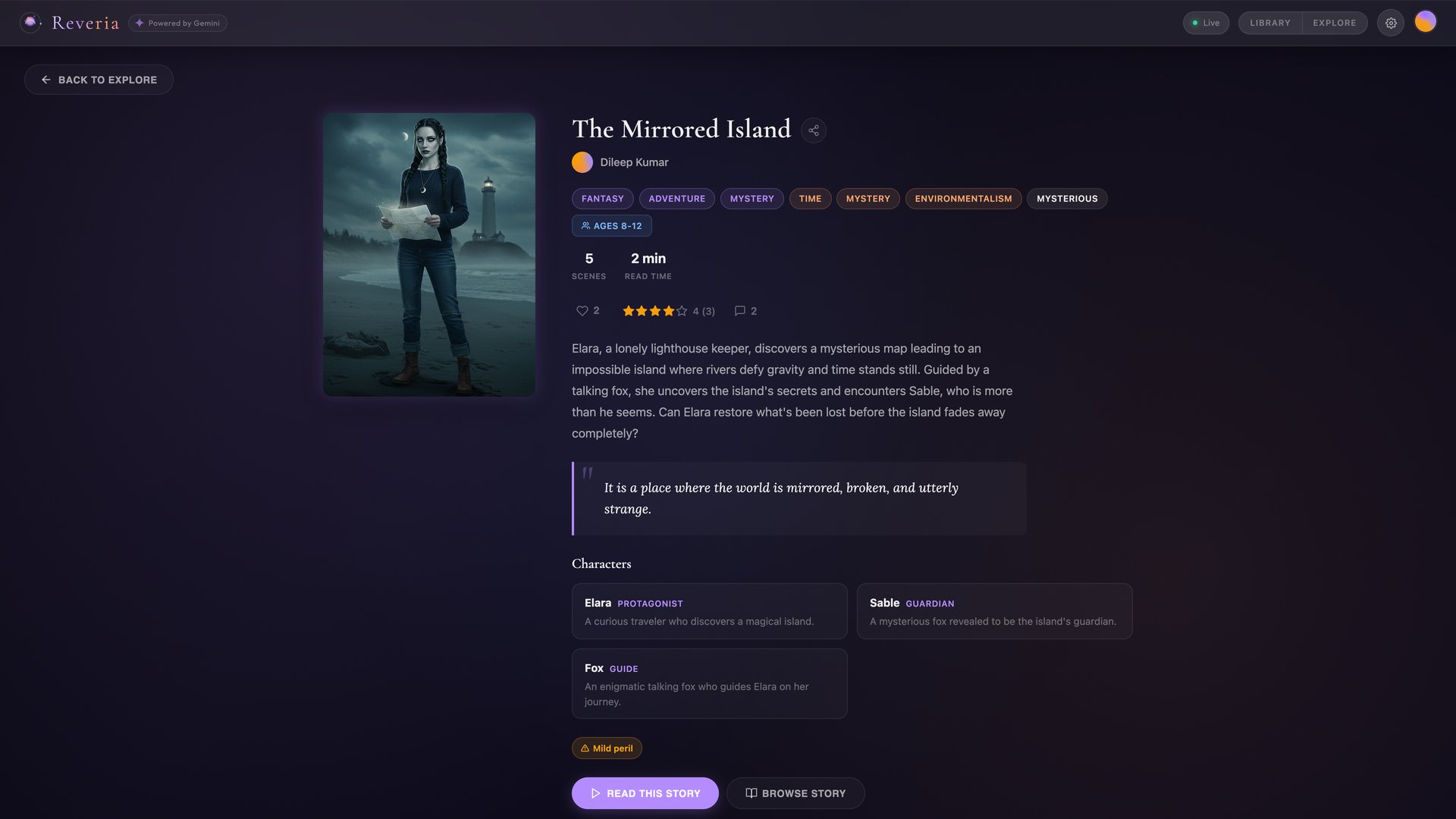 Book Details - Published story with social features |
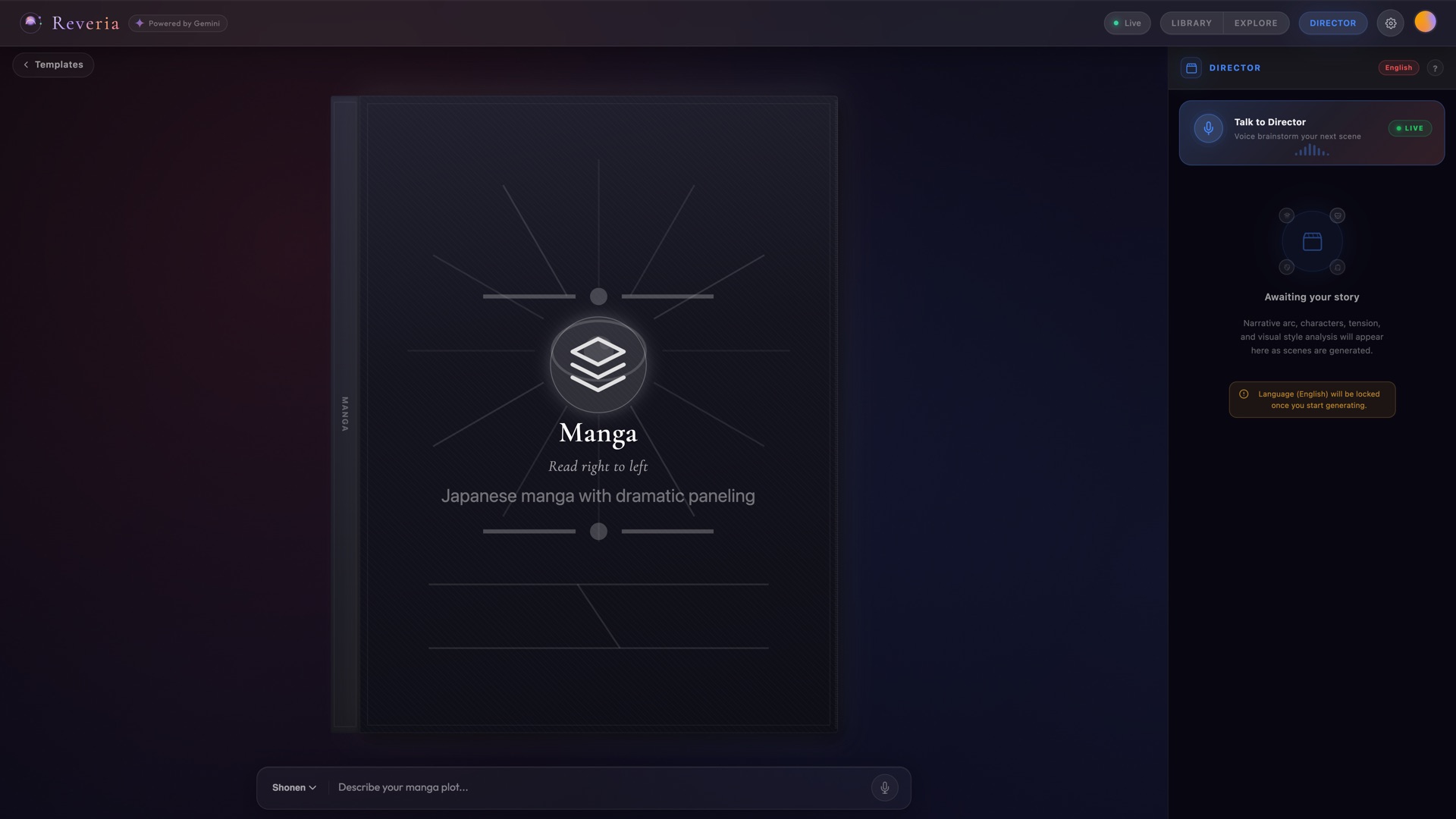 Director Chat - Voice brainstorming with AI Director |
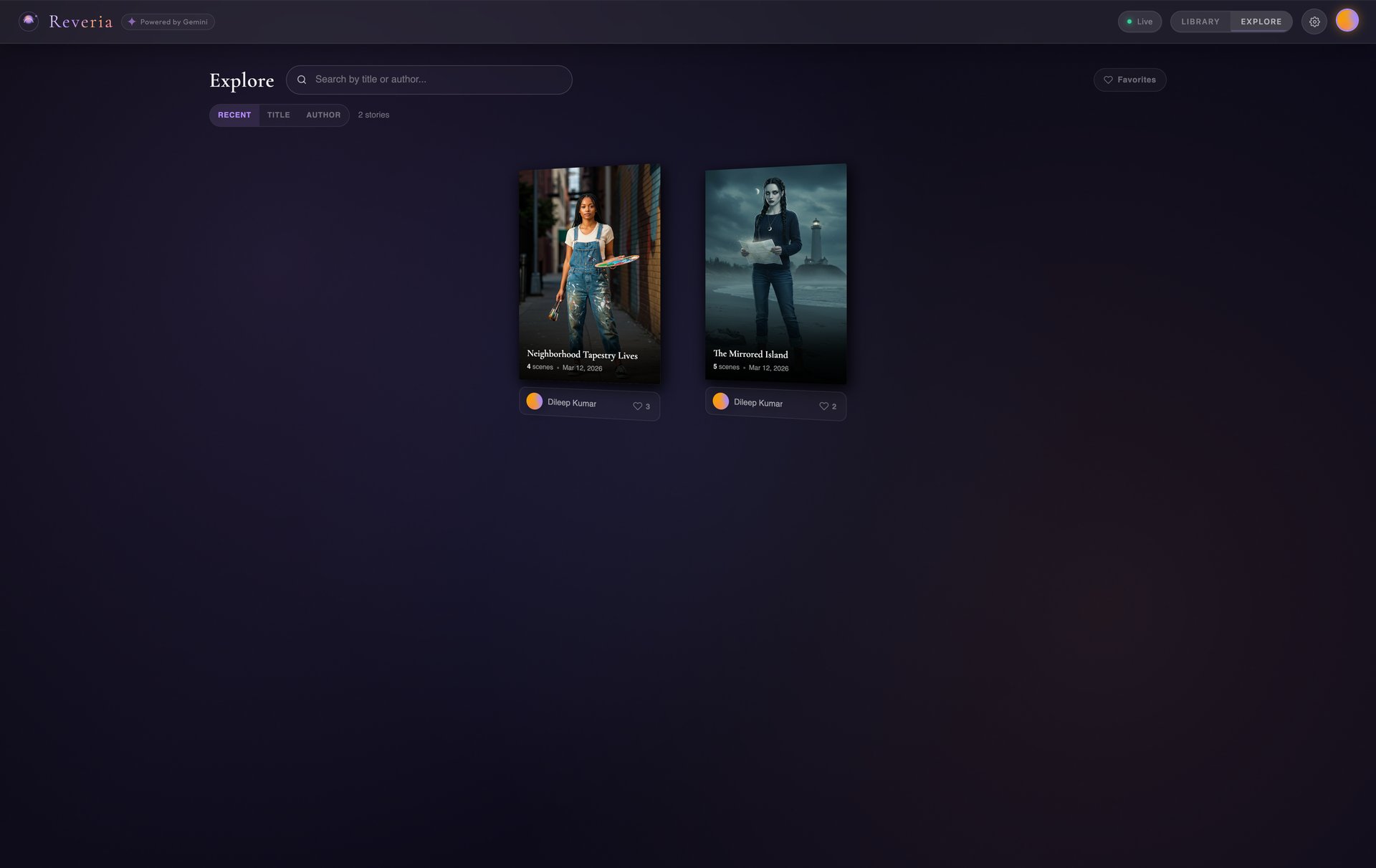 Explore - Discover published stories from the community |
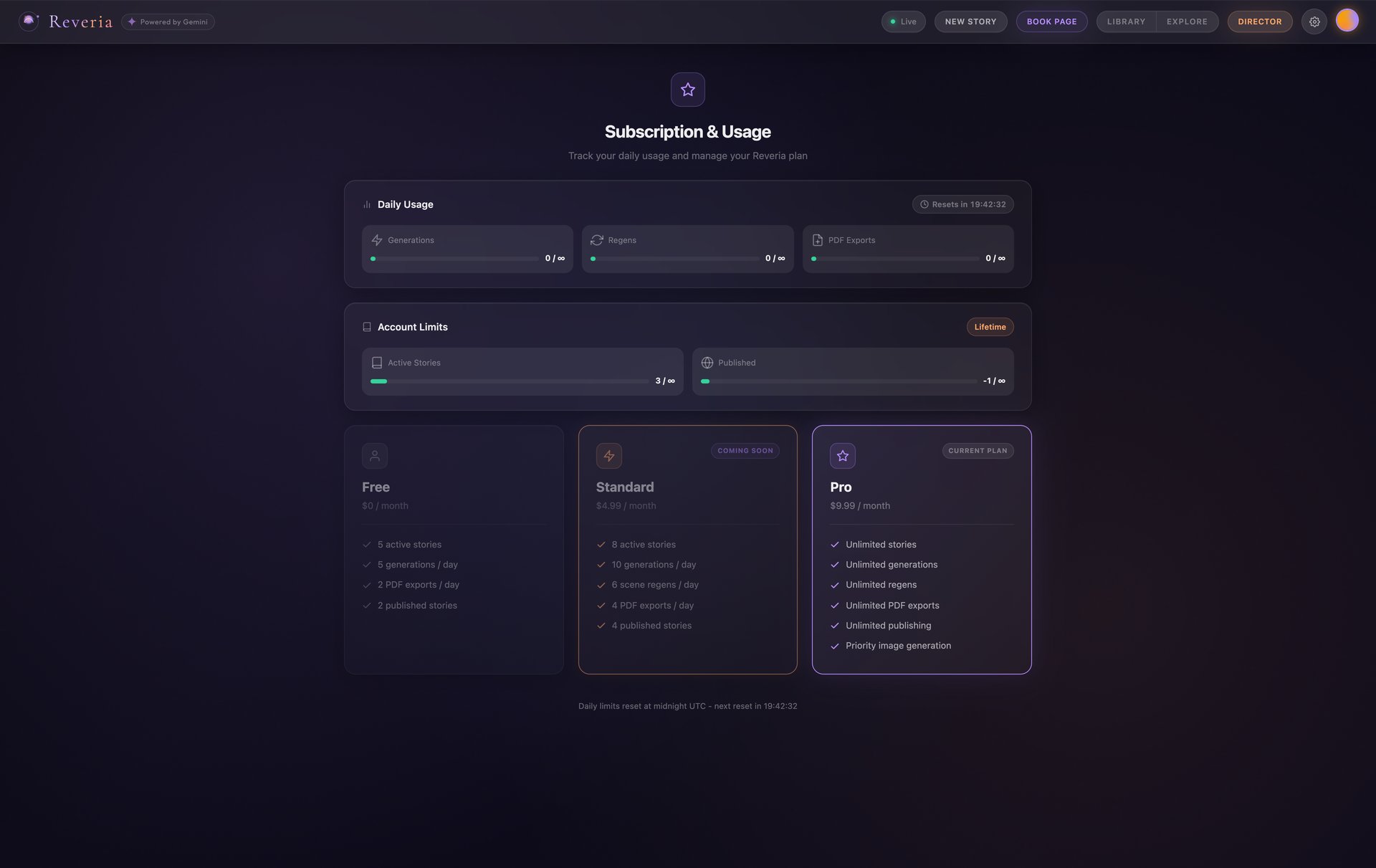 Subscription & Usage - Free, Standard, and Pro tiers |
Seamless Multimodal Interleaving (Creative Storyteller Category)
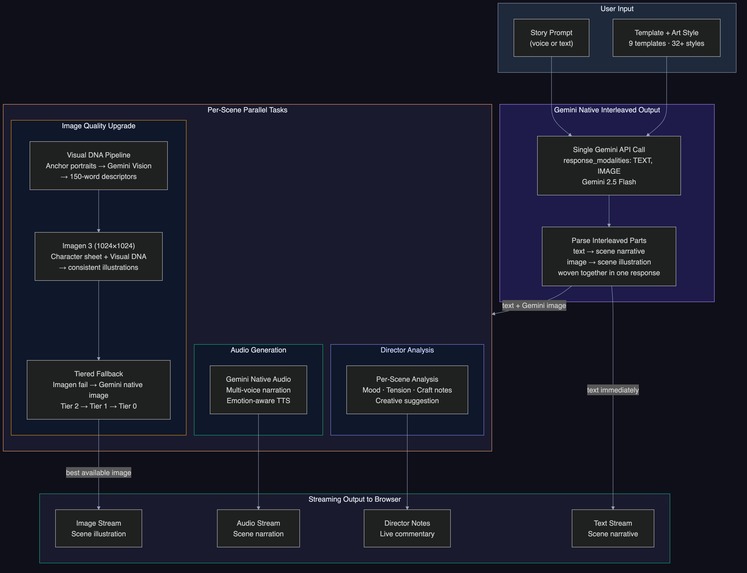
Reveria is built around Gemini's native interleaved output capabilities (response_modalities: ["TEXT", "IMAGE"]). The primary generation path uses Gemini to generate text and images together in a single call. Imagen 3 serves as the primary image engine for character consistency, with Gemini native image as a fallback tier.
The experience is live and context-aware, not turn-based:
- Per-scene streaming: As each scene's text completes, image generation, audio narration, and Director analysis fire in parallel. Scene 1's illustration paints in while Scene 2's text is still streaming.
- Mid-story steering: Users can send direction changes during generation ("make it scarier", "add a twist") via a steering queue. The Narrator picks up the direction in the next scene.
- Director-as-driver: The Director's per-scene analysis includes a
suggestionfield - a bold creative direction for what happens next ("Reveal that the stranger is her long-lost sister"). This gets injected into the Narrator's input for the following scene. Two agents shaping a story together. - Voice-reactive orb: A canvas-based visualization with 6 visual states (idle, recording, speaking, loading, watching, waiting) driven by real-time audio amplitude.
Beyond Generation: A Full Creative Platform
Reveria is not just a generator - it's a complete storytelling platform:
| Feature | Description |
|---|---|
| 9 Story Templates | Storybook, Comic Book, Webtoon, Hero Quest, Manga, Novel, Diary, Poetry, Photo Journal. Each reshapes the entire pipeline. |
| 30+ Art Styles | Cinematic, watercolor, oil, anime, cyberpunk, manga variants, and more |
| 8 Languages | English, Spanish, French, German, Japanese, Hindi, Portuguese, Chinese |
| Reading Mode | Karaoke-style word highlighting synced to audio narration |
| Library & Explore | Save stories, publish to a community feed, discover other creators |
| Social Features | Likes, star ratings, threaded comments on published stories |
| Character Portraits | AI-generated portrait gallery with visual DNA for cross-scene consistency |
| Hero Mode | Upload your photo to become the main character |
| PDF Export | Download formatted stories |
What Inspired This
The "text box" paradigm for AI creativity is broken. You type a prompt, wait, get a wall of text. We asked: what if creating a story felt like directing one? What if you could talk to an AI collaborator, watch your world materialize page by page, and steer the narrative as it unfolds?
The result: a voice-first, multimodal experience where AI doesn't just respond - it sees, speaks, creates, and collaborates.
How We Built It
This project was built entirely during the contest period (Feb-March 2026). Three weeks, solo developer, 62 sessions.
- Week 1: Core pipeline - Gemini text streaming, WebSocket architecture, Imagen integration, Firebase persistence, flipbook UI
- Week 2: Character consistency (the hardest problem), Director Mode, templates, art styles, per-scene streaming
- Week 3: Gemini Live API Director Chat, safety system, social features, CI/CD, Reading Mode, multi-language, resilience hardening
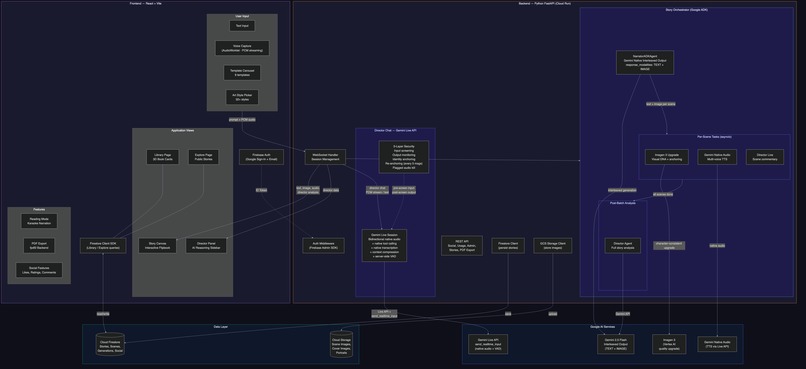
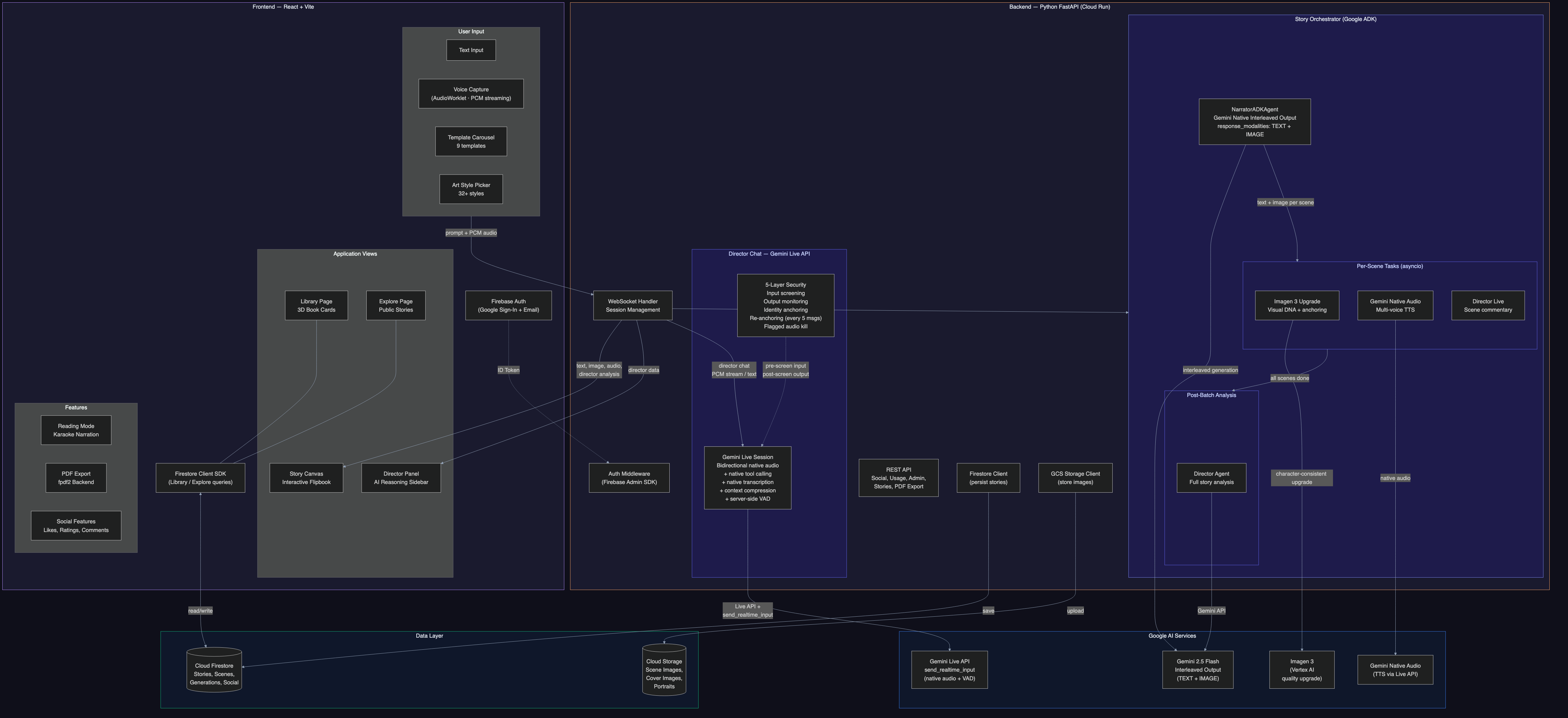
Technical Implementation & Agent Architecture
ADK Agent Pipeline
Reveria uses Google's Agent Development Kit (ADK) to orchestrate a multi-agent pipeline. Each agent is a BaseAgent subclass, composed using ADK's SequentialAgent and ParallelAgent combinators. The key design decision: different temperatures for different tasks. Story writing needs creativity (temp 0.9). Image prompts need precision (temp 0.3). Character extraction needs determinism (temp 0.1). Safety classification needs zero variance (temp 0.0).
StoryOrchestrator (ADK SequentialAgent)
+-- NarratorADKAgent (BaseAgent, per-scene streaming, temp 0.9)
| +-- Scene text ready --> Illustrator (Imagen 3, temp 0.3)
| --> TTS (Gemini Native Audio)
| --> Director Live (analysis, temp 0.3)
| +-- [Check steering queue -> inject user direction]
| +-- Await all pending tasks
+-- PostNarrationAgent (ADK ParallelAgent)
+-- DirectorADKAgent (full story analysis, temp 0.4)
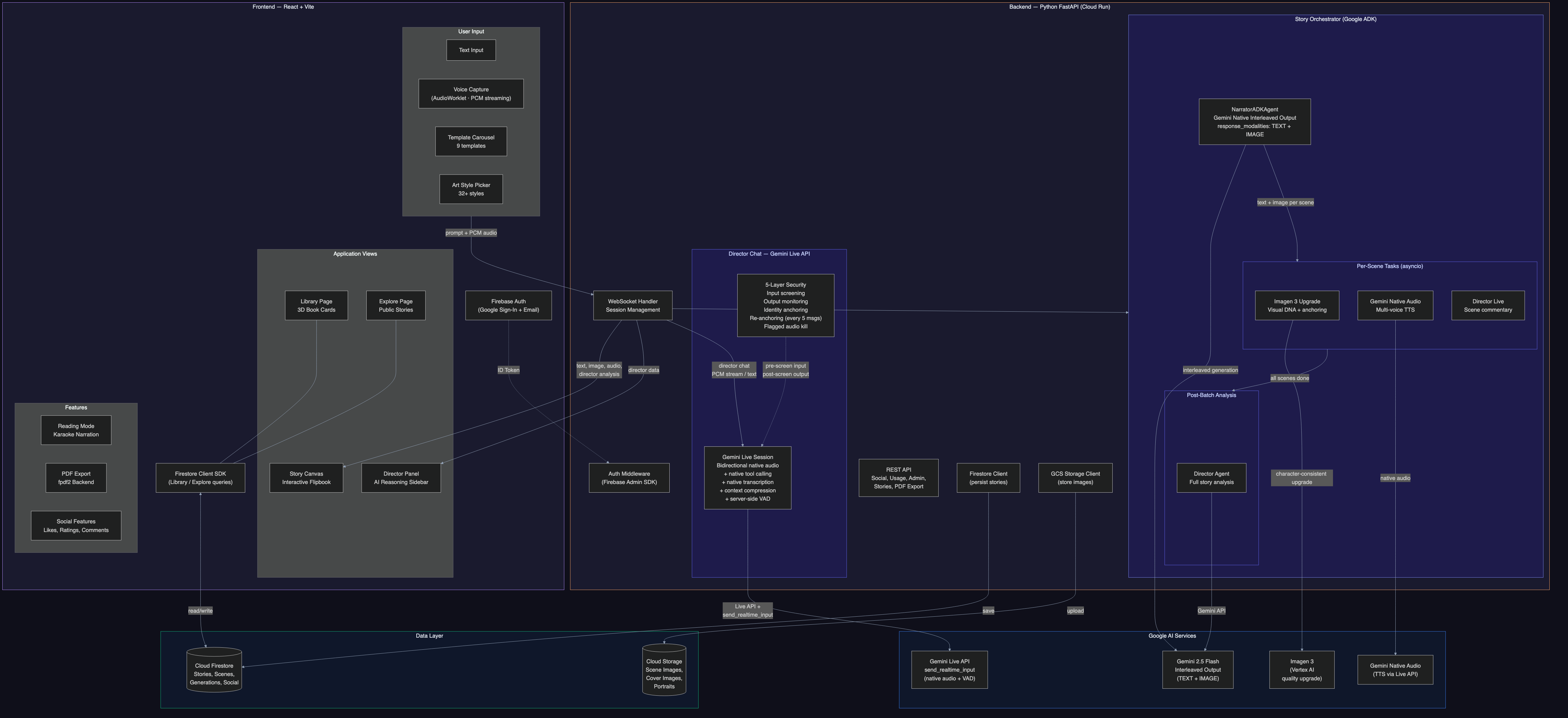
Shared State Pattern (Agent Communication)
ADK session state returns copies, not references, so agents can't communicate through it. We use a SharedPipelineState - a mutable Python object passed by reference to every agent. This carries the WebSocket callback, steering queue, scene data, character sheets, Director suggestions, and generation flags across the entire pipeline. Each agent reads and writes to shared state without serialization overhead.
14 Prompt Systems at 6 Temperature Tiers
Reveria runs 14 distinct prompt systems, each tuned to a specific temperature for its task. This is not one prompt - it's an architecture:
| Temp | System | Purpose |
|---|---|---|
| 0.0 | Content Filter | Deterministic STORY/REJECT classification (4 tokens max) |
| 0.0 | Character Identifier | Reliably pick which characters appear in a scene |
| 0.1 | Character Sheet Extractor | Precise visual descriptions with hex color codes |
| 0.1 | Visual DNA Analyzer | Faithful description of rendered portrait (Gemini Vision) |
| 0.3 | Scene Composer | Creative but controlled image prompt generation |
| 0.3 | Director Live Analysis | Structured JSON with mood, tension, craft notes, suggestion |
| 0.3 | Cover Generator | Character-focused book cover prompt |
| 0.4 | Director Full Analysis | 9-category story critique (narrative arc, beats, themes) |
| 0.7 | Title Generator | Creative but grounded 4-word book titles |
| 0.9 | Narrator | Maximum creativity for story text generation |
| -- | Director Chat (Live API) | Bidirectional voice brainstorming with tool calling |
| -- | TTS Narration (Live API) | Verbatim audiobook narration with mood-aware expression |
| -- | TTS Dialogue (Live API) | Multi-voice character speech with gender-based voice pools |
| -- | Director Voice (Live API) | Proactive scene commentary during generation |
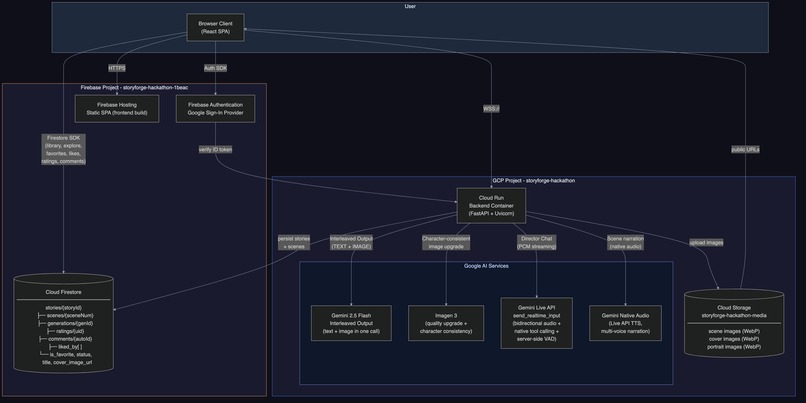
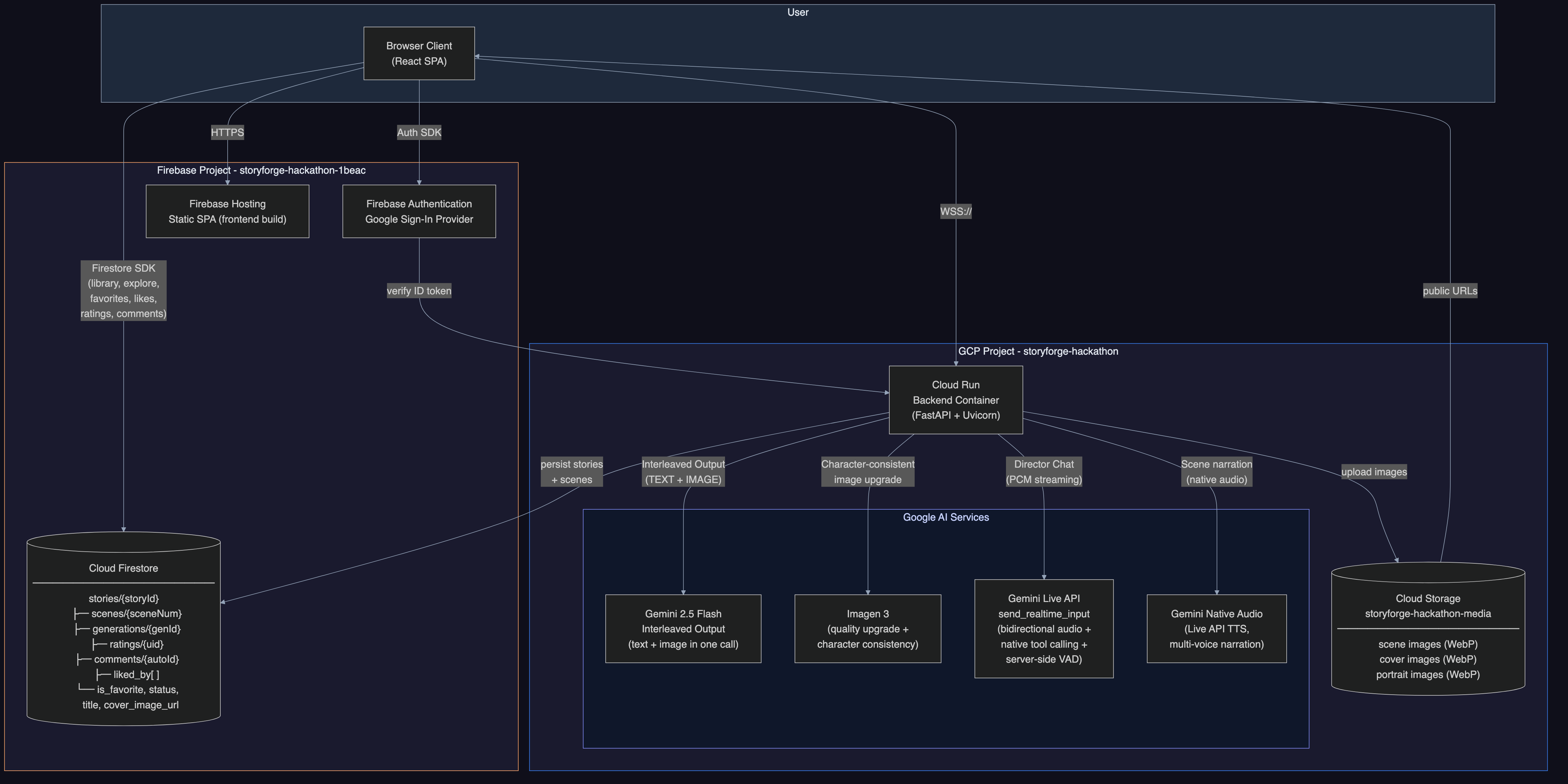
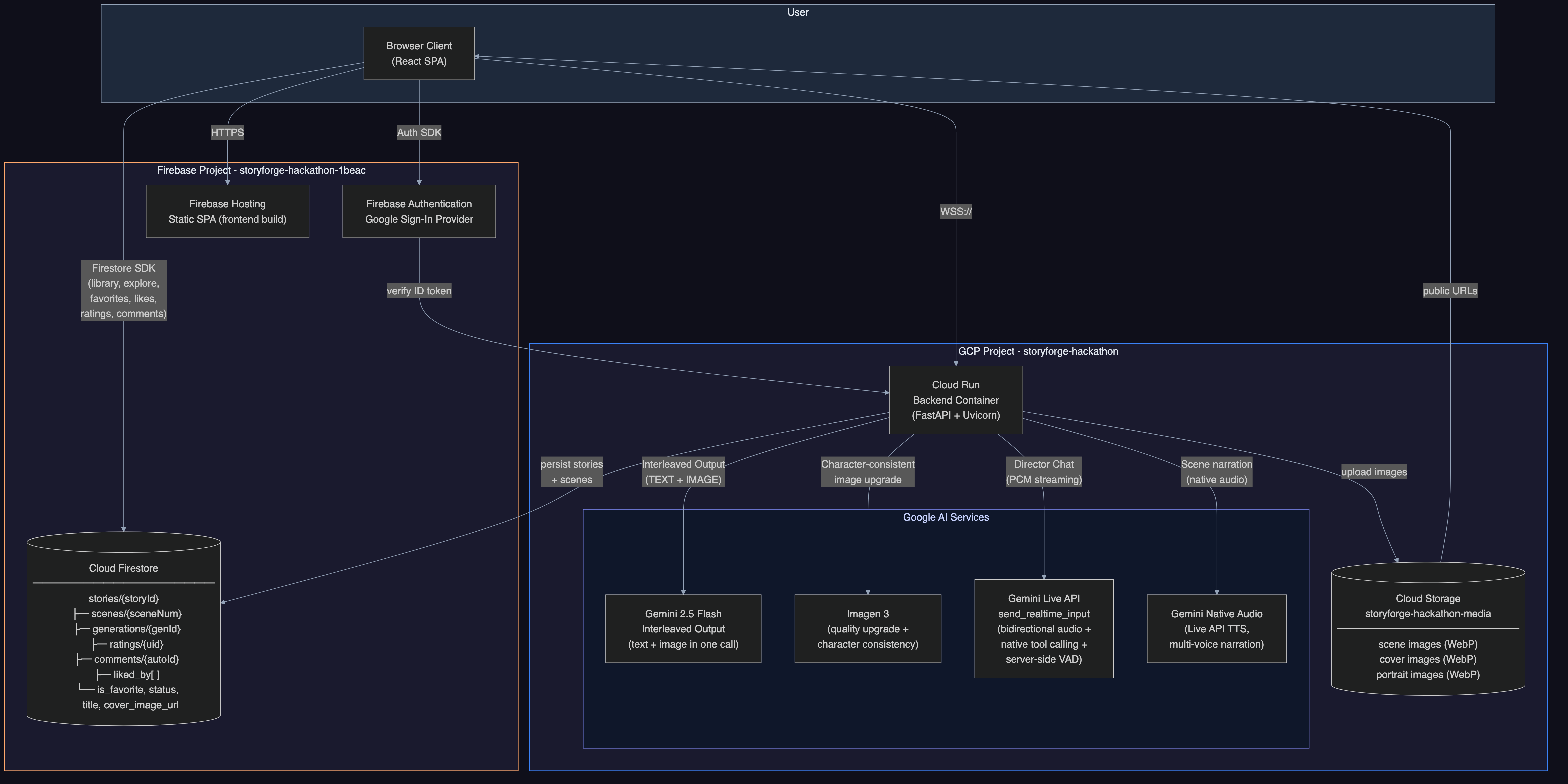
Google Cloud Services (via Google GenAI SDK)
All Gemini interactions use the google-genai SDK (genai.Client). The client auto-selects between API key auth and Vertex AI ADC based on environment configuration.
| Service | Usage |
|---|---|
| Gemini 2.0 Flash (google-genai SDK) | Narrative generation, character extraction, scene composition, content filtering |
Gemini Live API (gemini-live-2.5-flash-native-audio) |
Bidirectional voice Director Chat with native tool calling, transcription, context compression |
| Gemini Native Audio | Multi-voice audiobook narration (8 voice personas: Charon, Kore, Fenrir, Aoede, Puck, Orus, Leda, Zephyr) |
Imagen 3 (imagen-3.0-generate-002) |
Scene illustrations with per-user circuit breaker and retry logic |
| Cloud Run | Containerized FastAPI backend (Python 3.12, WebSocket + REST API) |
| Cloud Firestore | Story persistence, user data, social features, atomic usage tracking |
| Cloud Storage | Scene images, character portraits, cover images |
| Firebase Hosting | React SPA frontend (reveria.web.app) |
| Firebase Auth | Google Sign-In + email/password authentication |
ADK Components: SequentialAgent, ParallelAgent, BaseAgent, Runner, InMemorySessionService
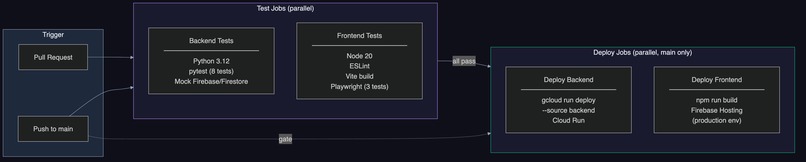
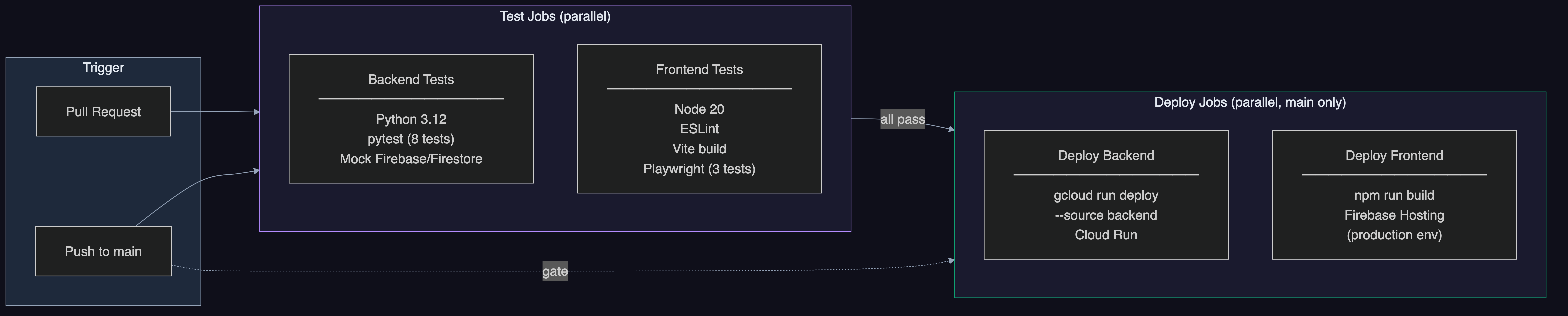
CI/CD: GitHub Actions 4-job automated pipeline - backend tests (pytest), frontend tests (Playwright), Cloud Run deploy, Firebase Hosting deploy. Every push to main triggers automated deployment.
Third-Party Libraries
- Frontend: React 19, Vite 7, react-pageflip (book animation), GSAP (animations), Firebase SDK
- Backend: FastAPI, Uvicorn, google-genai SDK, google-adk, firebase-admin, google-cloud-storage, google-cloud-firestore, fpdf2 (PDF export), Pillow
Challenges
Character Consistency & Grounding (The Hardest Problem)
Imagen 3 produces stunning illustrations, but characters changed faces between every scene. When we asked Gemini to write image prompts, it would "helpfully" compress detailed character descriptions into vague summaries. A character with hex-coded skin color, specific outfit details, and signature accessories would become "a young woman with dark hair wearing casual clothes."
The fix was architectural, not prompt-based. We built a 4-stage hybrid prompt pipeline:
- Character Sheet Extraction (temp 0.1): Structured descriptions with hex color codes, face shapes, signature items
- Character Identification (temp 0.0): Which characters appear in this scene?
- Scene Composition (temp 0.3): Setting, lighting, mood only. Explicitly told NOT to describe characters
- Assembly (code, no Gemini): Character descriptions prepended verbatim. They never pass through a second model call
Grounding via Visual DNA: We then added Anchor Portraits - generate a close-up portrait of each character via Imagen 3, then feed it to Gemini Vision for "visual DNA" extraction (a 100-150 word description of the rendered image). All subsequent scene prompts reference this visual DNA instead of the original text description. This grounds character appearance in actual rendered output, preventing hallucinated character changes. The visual DNA acts as an anchor that keeps Imagen 3 consistent because every prompt references what was actually rendered, not what was originally described.
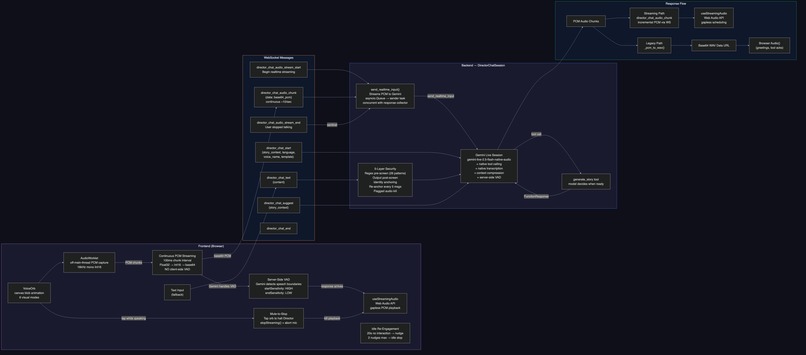
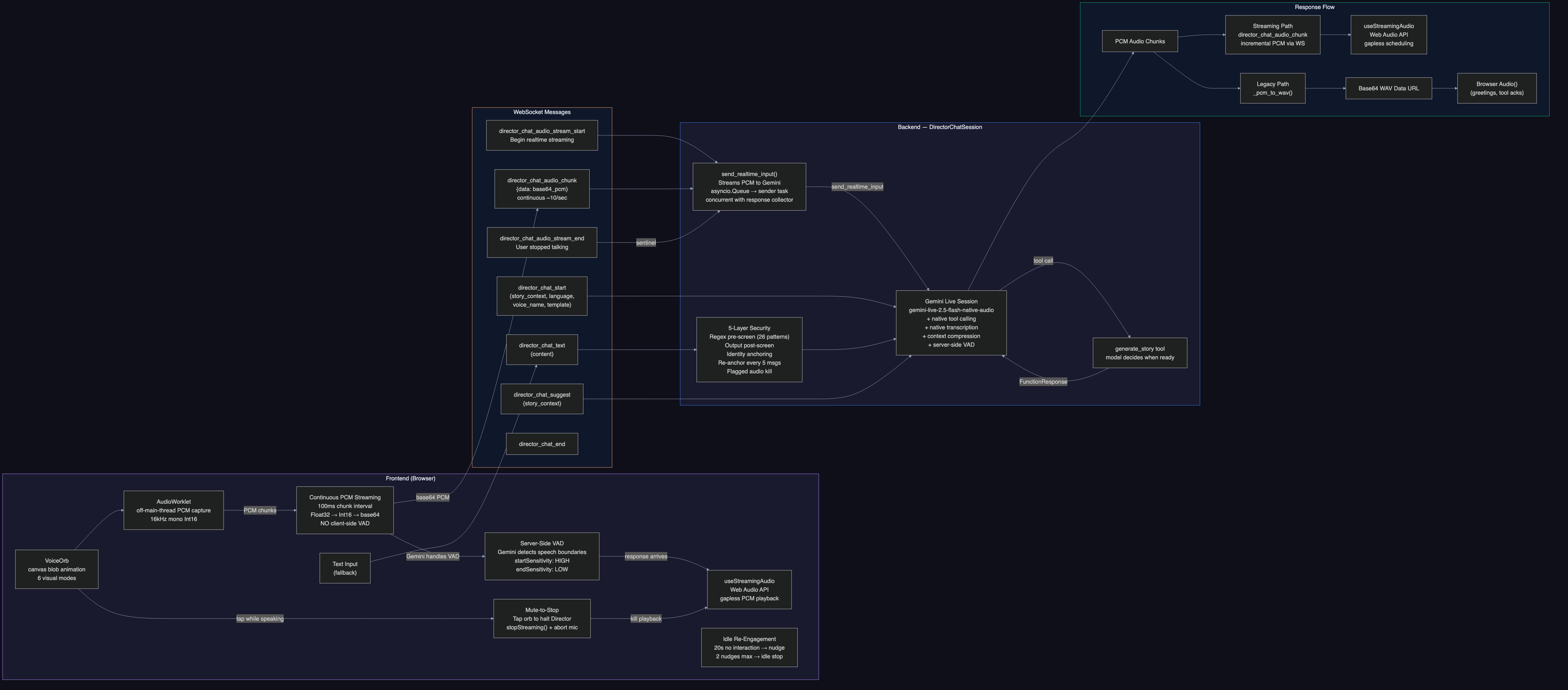
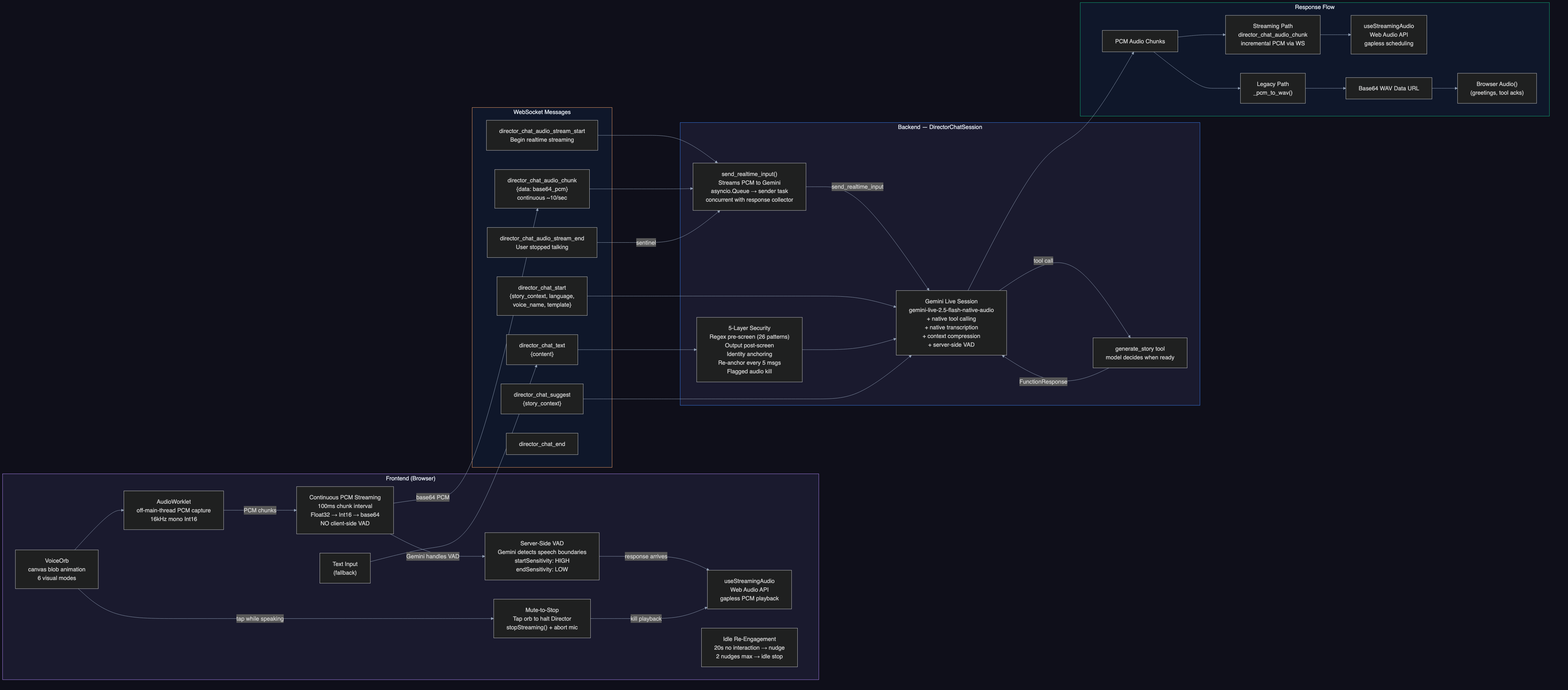
Director Chat: When to Generate?
How does the system know when brainstorming is done? This went through three rewrites:
- v1: Separate classifier on user message only. Failed because users say "sounds great" mid-brainstorm
- v2: Two-sided analysis of both user + Director messages. Worked but added 200-400ms latency
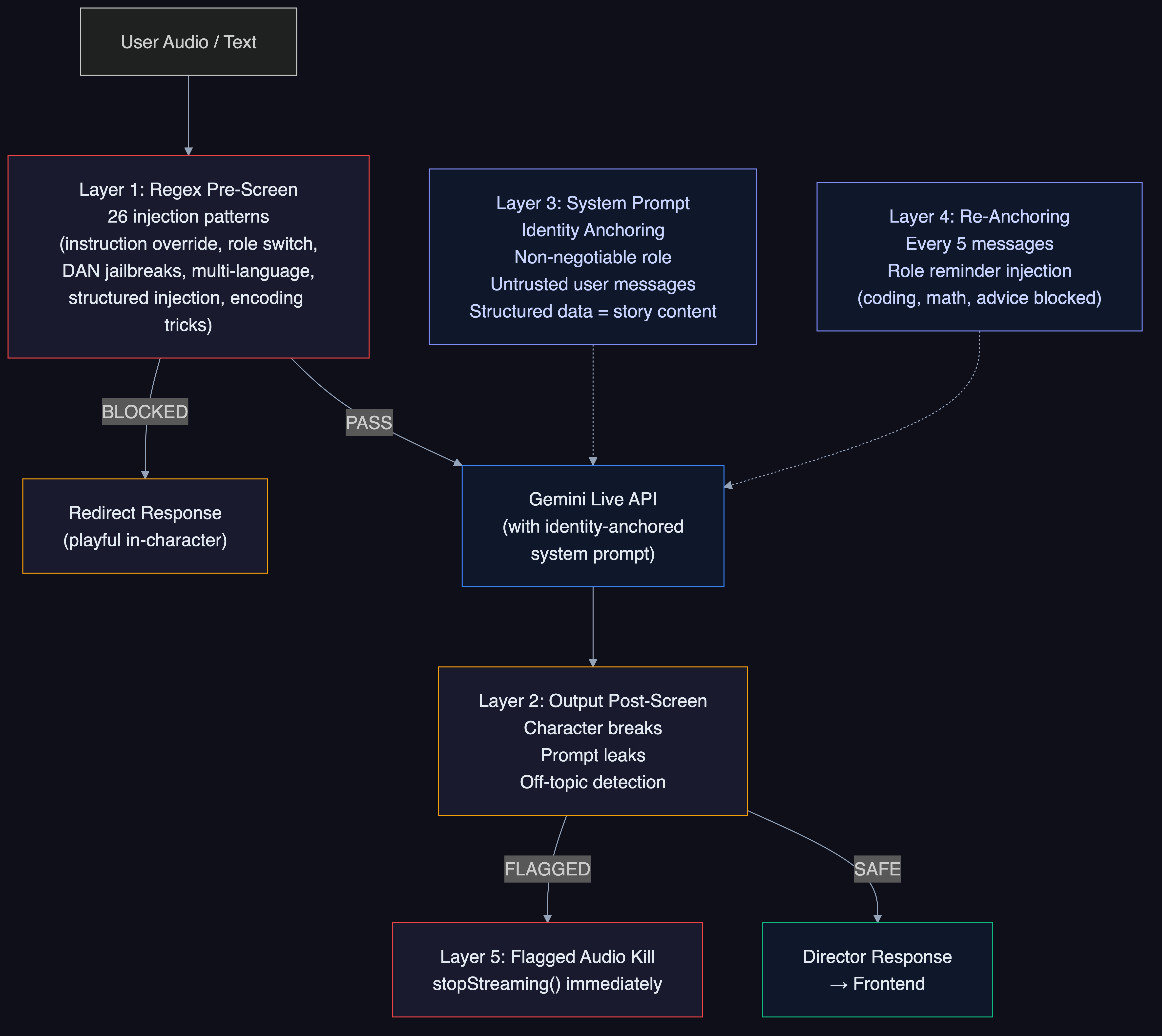
- v3: Replaced everything with Gemini Live API native tool calling. The Director model calls
generate_storywhen it decides the idea is ready. Zero extra API calls. Manual "Suggest" button as fallback (~60-70% reliability in audio mode).
Critical protocol lesson: The Live API requires a FunctionResponse for EVERY tool call. Silently dropping one corrupts the session permanently. Our _reject_tool_call() method sends a rejection FunctionResponse and consumes the acknowledgment turn.
TTS Verbatim Accuracy
Framing the model as "professional audiobook narrator" caused creative paraphrasing - the audio wouldn't match the on-screen text. Reframing to "text-to-speech engine" with strict [SCRIPT] markers fixed it completely. Same model, different identity framing, dramatically different behavior.
Text in Comic/Manga Images
Comic art styles triggered Imagen to render garbled speech bubbles. The fix: a triple-layer defense with a positive instruction at the BEGINNING of the prompt (highest attention weight), composer instructions in the middle, and negative constraints at the end as safety net. We overlay our own styled text on top of clean images.
Robustness & Error Handling
We invested heavily in making Reveria production-ready. The system handles errors, API timeouts, and edge cases gracefully:
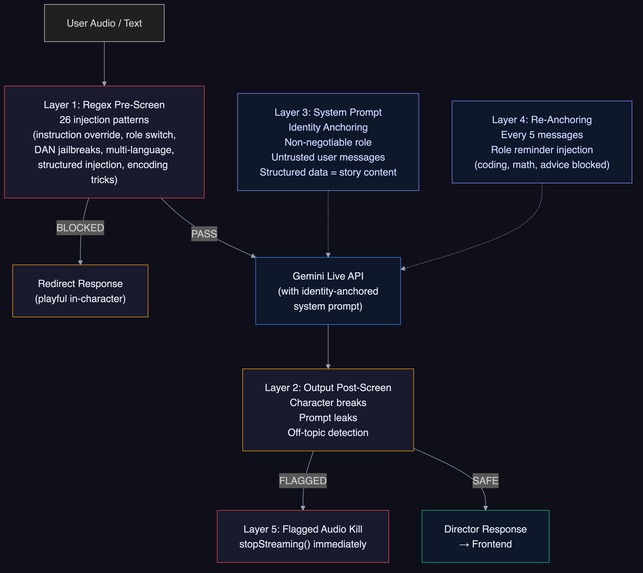
- Pre-pipeline content filter: Gemini Flash classifier (temp 0, 4 tokens) catches non-story prompts. Fails open on errors - blocking a legitimate request is worse than allowing a borderline one
- Post-generation refusal detection: Pattern matching in 6 languages (English, Hindi, Spanish, French, German, Japanese) for AI-typical refusal language
- Playful redirect (no hallucinated refusals): Instead of hard refusals that break immersion, the Narrator redirects in-character: "That part of the library is forbidden! Let's explore this mysterious path instead..."
- Per-user circuit breaker: Imagen quota tracking per UID with jitter on retry delays
- Retry utility:
is_transient()error classification +with_retries()exponential backoff for all Gemini API calls - GCS fallback: 7-day signed URLs when
make_public()fails - Atomic transactions: Firestore
@async_transactionalfor usage increment/decrement (prevents race conditions) - WebSocket auth: First-message token auth (no credentials in URLs)
- Non-blocking generation:
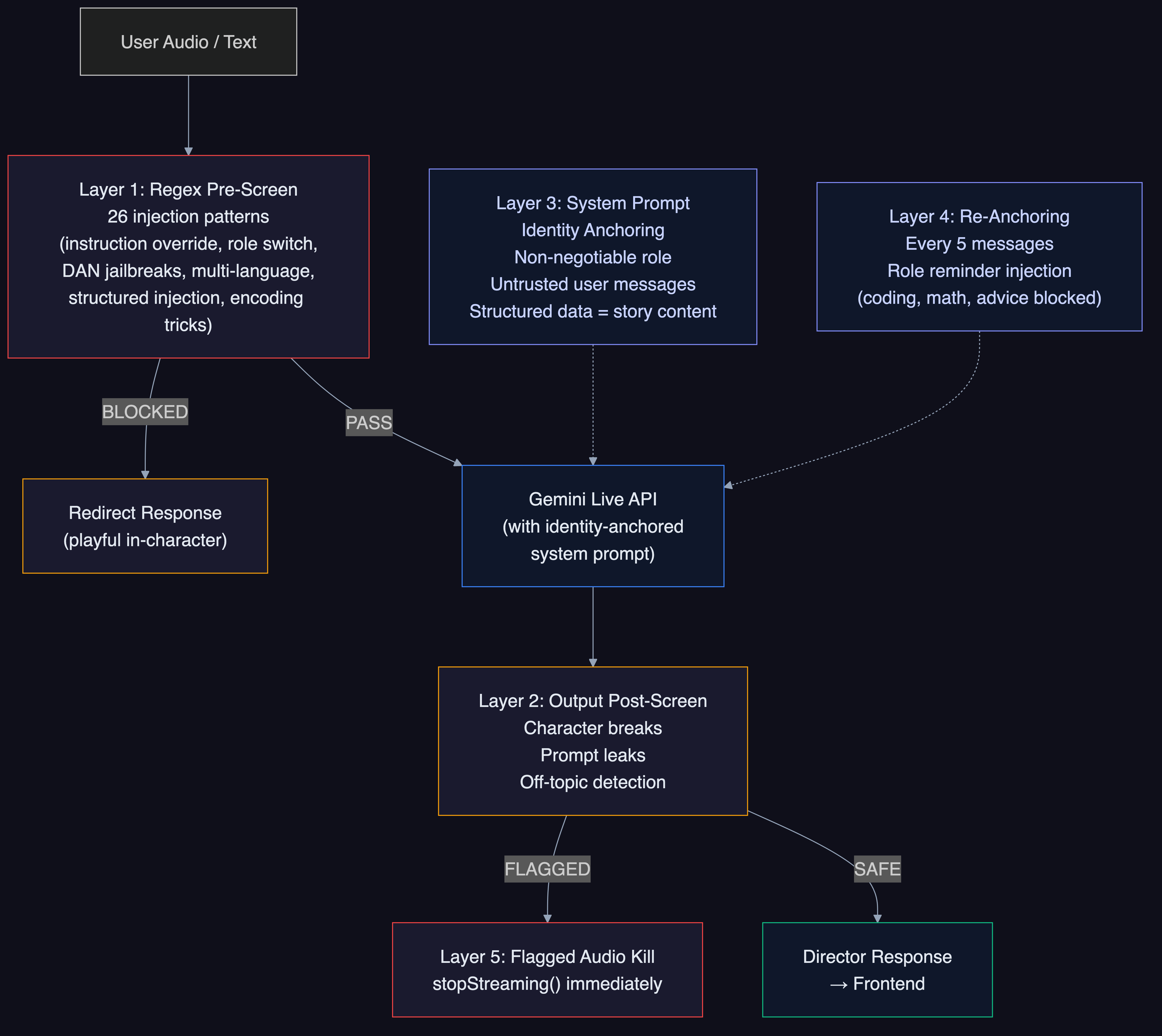
handle_generateruns asasyncio.create_task()so the WebSocket loop stays responsive during generation - Director Chat security: 5-layer defense against prompt injection (system prompt identity lock, 40+ regex patterns for instruction override/role switching/DAN jailbreaks, output validation, re-anchoring every 5 messages, prompt leak detection)
What We're Proud Of
The Director Chat experience. Having a voice conversation with an AI that understands your creative vision, pushes you to think bigger, then watches the story unfold and offers live commentary. The moment the Director spots an opportunity ("Reveal that the stranger is her long-lost sister") and the Narrator runs with it in the next scene - that's the magic.
What We Learned
- Prompt engineering is architecture. When your prompt construction has 14 systems at 6 temperature tiers, it's a data pipeline, not a template
- Use native API features first. Director Chat went from 3-5 Gemini calls per interaction to zero extra calls by enabling native transcription, function calling, and context compression
- Per-scene is the right granularity. Scene-level parallelism (fire tasks as each scene completes) makes the experience feel live
- Make agents proactive, not just reactive. The Director started as a passive observer. The breakthrough was giving it a suggestion field that feeds the Narrator
- Ground character appearance in rendered output. Visual DNA extraction from Imagen portraits prevents character drift across scenes
- Reframing identity changes behavior. 'Text-to-speech engine' produces verbatim audio. 'Audiobook narrator' produces creative paraphrasing. Same model, different identity framing
- Templates are modes, not skins. When a config option touches four pipeline stages (narrator voice, image composition, TTS, overlay rendering), it's architecture
What's Next
- Multi-user collaborative storytelling with multiple Directors
- Persistent character universe across stories
- Interactive branching narratives with Director guidance
- Animation and video scene generation
- Mobile-native experience
Links
- Live App: reveria.web.app
- Source Code: github.com/Dileep2896/reveria
- Demo Video: youtu.be/ZNvkmiWNI8k
- Blog Post: Building Reveria: An AI Story Engine with Gemini
- Cloud Deployment Proof: Google Drive
- CI/CD Pipeline: .github/workflows/ci.yml
- Deploy Script: deploy.sh
- GDG Profile: g.dev/Dileep2896
Built With
- cloud-firestore
- cloud-run
- cloud-storage
- css
- fastapi
- firebase-auth
- firebase-hosting
- gemini-2.0-flash
- gemini-live-api
- github-actions
- google-adk
- google-genai-sdk
- imagen-3
- javascript
- python
- react
- vertex-ai
- vite
- websocket



Log in or sign up for Devpost to join the conversation.