About this Project
ArxLearn is an accelerated learning tool that distills complex topics to the essentials so researchers can contribute faster. Instead of hand‑curating a “perfect” reading list, we build a personalized learner profile, map the prerequisite concepts, and generate a custom learning path ordered by dependency. The system embeds sources directly into the lesson flow (papers, lectures, and problem sets), annotates them in context, and produces guided activities that help you build mastery without tab‑hopping.
Inspiration
Existing personalized learning platforms are designed for breadth, not for research-level mastery. Great for learning calculus in 20 hours or asking simple questions, but what if we wanted to reach competency in a research-level topic in an hour?
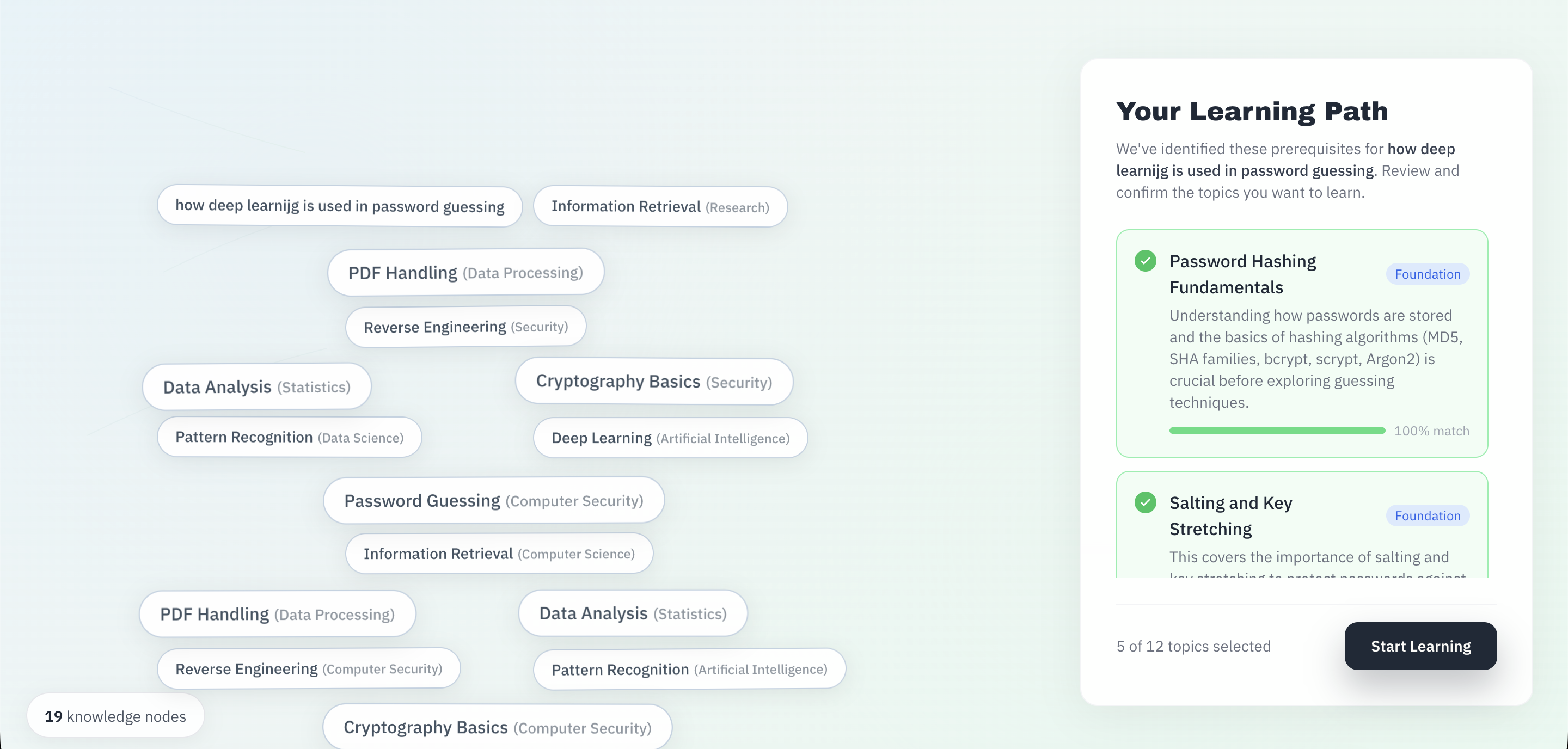
Understanding research papers depends on foundational knowledge. To learn about gradient descent, we need to know about partial derivatives and vectors/matrices. ArxLearn pinpoints these gaps and creates lessons in order of dependency.
We wanted a tool that treats learning like a dependency graph, not a pile of PDFs, so we can start contributing sooner rather than waiting to learn everything first.
How we built it
- Learning origin and knowledge graph: We ask for a central topic and background, then generate a topic concept graph with prerequisites and an initial “known concepts” set. This gives each user a tailored starting point.
- Adaptive lesson flow: The backend produces a next-activity plan with embedded sources and follow-ups, so learners can move through a guided sequence instead of wandering.
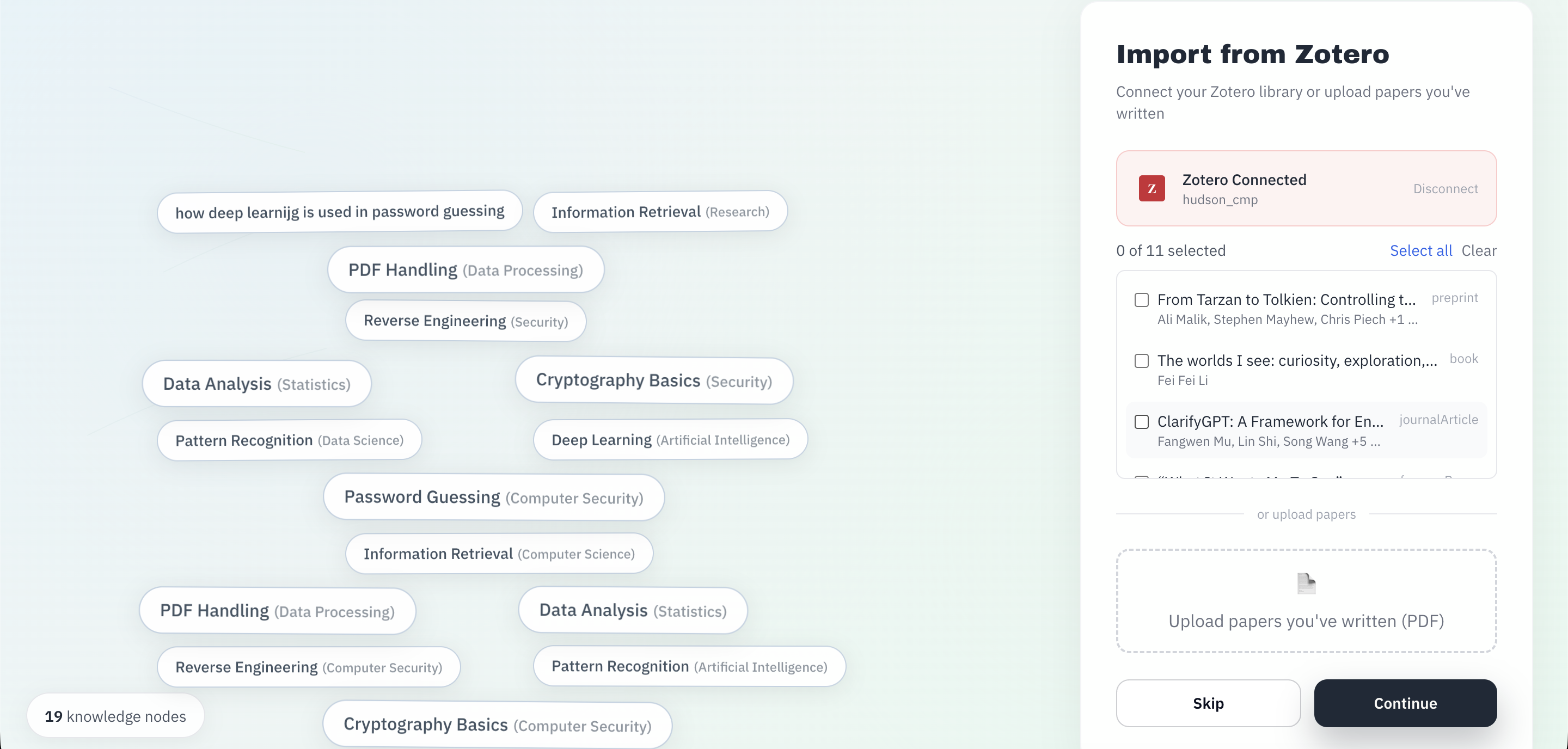
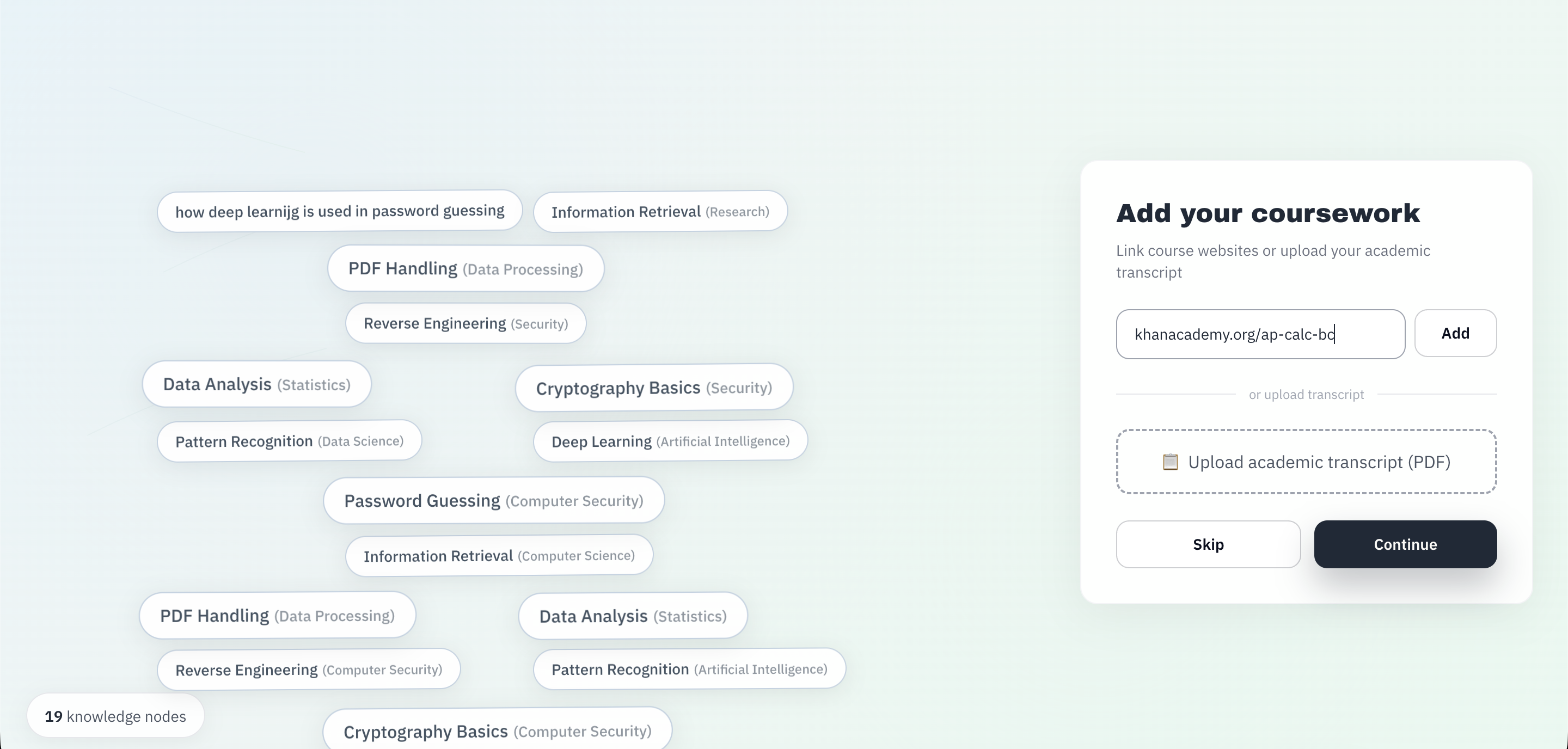
- Research ingestion: We built connectors for Zotero and Google Drive and a web‑scraping pipeline (Firecrawl) to pull in real materials.
- Document pipeline: PDFs are extracted (text + figures), compressed via The Token Company, and stored in Supabase for structured reuse. We also format compressed content for MCP/Claude consumption.
- Tech stack: FastAPI, Supabase, React + Vite, LangChain + OpenRouter/Gemini, and a token compression pipeline.
We prioritize the next concept by gap and dependency position, so time goes into the highest‑leverage nodes first.
Challenges
- Token limits and context overflow: Academic documents are long and redundant; compressing them safely while preserving math and technical detail was non‑trivial.
- Reliable ingestion: PDFs, web pages, and citation libraries all behave differently. We had to normalize formats and metadata without losing signal.
- Personalization: Translating a user’s background into a usable knowledge profile required careful prompt design and validation so the graph is both accurate and actionable.
What we learned
- A good learning path is a graph problem, not a list problem
- Keeping the user in the loop is critical. We make recommendations from data and let the user choose topics they need to work on.
- The best UX comes from reducing “research friction”, keeping sources, steps, and notes in one place.
Built With
- firecrawl
- flask
- gemini
- google-drive-api
- langchain
- open-router
- overshoot
- react
- supabase
- token-company
- typescript
- vite
- zotero-api




Log in or sign up for Devpost to join the conversation.