-
-
photo of our workflow
Inspiration
This project is founded on the utilization of Clinical Pharmacogenetics Implementation Consortium (CPIC) medication recommendations from pharmacogenomics (PGx) data. We aimed to integrate such information into the healthcare workflow, aiding clinicians in regular prescribing of medications. The field of pharmacogenomics (PGx) has been rapidly evolving, due to the necessity of optimizing treatment for patients. Clinicians are tasked with providing the optimal medication to patients. However, without a way to predict patient response beforehand, it can result in trial and error, high medication costs, delays in finding sufficient treatment. PGx has the capability to predict pharmacologic treatment. Genetic variation has been hypothesized to be a major influence in the drug metabolism between individuals, as well as a contender in reducing adverse reactions (ADRs).
Antidepressants, specifically SSRIs (Selective Serotonin Reuptake Inhibitors), are one of the most over prescribed and highly fluctuating between individuals. Dosage and medication type is usually prescribed in a trial and error manner. This can cause unnecessary ADRs, and costs for patients. It becomes vital to create an application to help reduce these negative effects with the help of PGx data and KNIME.
We will utilize data from the Clinical Pharmacogenomic Implementation Consortium CPIC database. CPIC provides gene-drug interactions, variant frequencies, and dosing guidelines.
Clinically, this application will allow providers to access an integration of PGx into clinical workflows.
**It is important to note that at this point in time PGx should be used in conjunction with other factors such as personal or environmental variables, such as concomitant medications, ethnicity, gender, smoking status, comorbidities, as well as provider discretion.
What it does
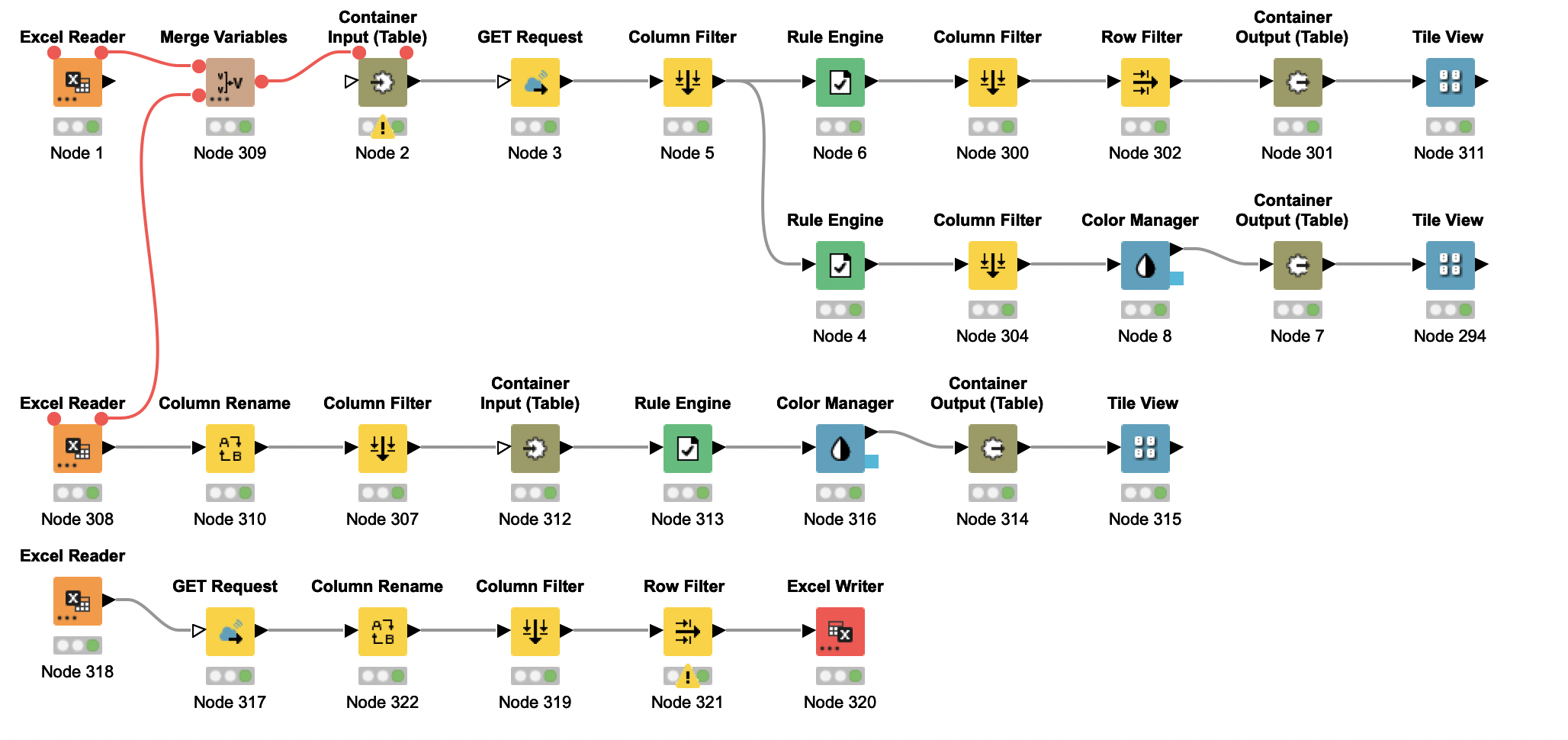
Given a list of medications and relevant PGx data, we could then deliver recommendations to providers on optimal dosages and medications for a particular patient. For the acquirement of such data, lab testing and clinician input would also be required respectively. As only some guidelines have been deemed as "1A" or clinically robust, we color codes relationships between drugs and genes. Most relevant, a "green" color signals a robust relationship and actionable decision-making by a physician. Our hope is that this relieves the burden on physicians while also delivering them accurate and relevant information. We also showed the relationship of a specific Gene involved in the metabolism of many SSRIs, these are then put into categories of high risk of adverse reactions or low risk based on Activity score provided by CPIC. Specifically, we were able to isolate the gene of interest: CYPD6 which is a well known metabolizer for SSRIs. We matches this gene to drugs and gave the condition of "TRUE" if these matched. Furthermore, we linked this match to the activity score produced by CPIC and it allowed us to produce a color coded alert of phenotype as well as "High Risk" and "Low Risk" to indicate the likelihood of ADRs.
How we built it
We first incorporated PGx data, specifically genotypes and their associated metabolic phenotypes. Then, we utilized a series of GET queries to the CPIC restAPI, where we pulled information such as drug-gene relationships and guideline recommendations.
Challenges we ran into
Throughout the course of this project our recurring issues materialized into two broad categories, data acquisition and file compatibility. Whether it was finding the exact CPIC guidelines per drug, the API links, or even just converting from an excel to a table to an index to a tile. There was a lack of KNIME modules where we thought they would exist or help, such as a search bar.
What we learned
As mentioned it was difficult to work around some obstacles and compatibility issues. Throughout we learned that sometimes the shortest path is not always the correct one- creative solutions were our best allies.
What's next for Retrieval of CPIC guidelines from PGx and medications
Going forward the next step would be to build on providing guidelines to be used in conjunction with patient metabolizer levels as we already have done by providing drug alternatives that are linked to genes that the patient is a high metabolizer for. These could be further synced with EHR information to flag for contraindications, and Adverse reaction warnings or predictors.
Accomplishments that we're proud of
We are proud of our ability to work for hours on end, come up with creative solutions to at-first-impossible obstacles, and above all remain lighthearted and flexible for change throughout. Our team is most proud of the fun and friends we made, but we’re pretty proud of our project as well. We hope you enjoy.
Built With
- api
- excel
- knime
Log in or sign up for Devpost to join the conversation.