-
-
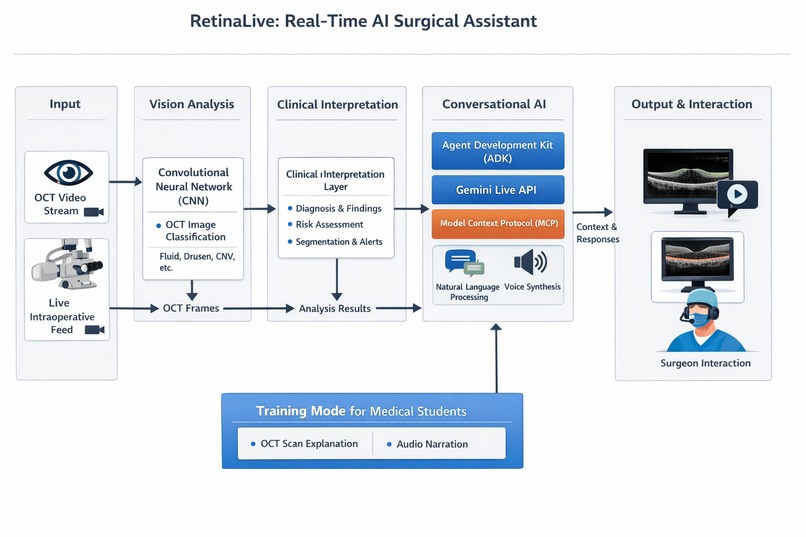
This is the overall system architecture.
-

This is the codebase level project architecture.

Inspiration
Retinal diseases are one of the leading causes of vision loss worldwide. During delicate retinal procedures, surgeons often rely on Optical Coherence Tomography (OCT) imaging to visualize the internal layers of the retina. However, interpreting OCT scans in real time while performing surgery can be challenging, especially when subtle abnormalities such as fluid accumulation or abnormal vascular structures are present.
We were inspired by the idea of creating an AI surgical co-pilot that could assist surgeons by continuously analyzing OCT scans and providing real-time insights. With the recent advancements in multimodal AI and real-time conversational agents, we saw an opportunity to build a system that not only detects abnormalities but also communicates them through natural voice interaction.
Our goal was to demonstrate how an AI agent can observe medical imaging, interpret clinical signals, and interact naturally with a surgeon, acting as an intelligent assistant in the operating room. By combining computer vision, real-time video streaming, and conversational AI, we envisioned a system that could enhance surgical awareness and support decision-making during retinal procedures.
This project explores how multimodal AI agents can move beyond simple chatbots and become context-aware assistants that see, understand, and communicate about the physical world in real time.
What it does
Our project, RetinaLive, is a real-time AI surgical assistant that analyzes Optical Coherence Tomography (OCT) scans and provides live insights to help surgeons identify retinal abnormalities during procedures.
The system continuously processes OCT frames from a video stream and uses a trained convolutional neural network (CNN) to detect patterns associated with retinal conditions such as fluid accumulation, subretinal deposits, or abnormal vascular growth. These findings are then interpreted into clinically meaningful explanations that a surgeon can quickly understand.
A key feature of the project is a multimodal AI co-pilot that interacts with the surgeon through natural voice conversation. Using a live AI agent, the surgeon can ask questions such as:
“Analyze the current OCT scan.”
“Do you see any abnormalities?”
“Where is the abnormal region located?”
The AI assistant analyzes the visual data in real time and responds with contextual explanations, warnings, or summaries of the findings. When abnormalities are detected, the system can also generate alerts and visually highlight suspicious regions on the OCT scan.
In addition to automated analysis, the AI agent acts as an interactive surgical assistant, allowing surgeons to quickly query the system without interrupting their workflow. This demonstrates how multimodal AI agents can combine vision understanding, medical reasoning, and real-time conversation to support clinical decision-making.
Overall, the project showcases how AI can move beyond traditional diagnostic tools and become an intelligent co-pilot that observes medical data, interprets it, and communicates actionable insights in real time.
The system also includes a Training Mode designed for medical education. In this mode, the AI agent analyzes OCT scans from the live streaming pipeline and explains the findings in simple terms through audio narration. Medical students can listen as the agent describes retinal structures, highlights abnormalities, and explains what the OCT scan reveals, turning the system into an interactive learning assistant for ophthalmology training.
How we built it
We built RetinaLive as a modular multimodal AI system that combines computer vision, real-time streaming, and conversational agents.
First, we trained a convolutional neural network (CNN) using a public retinal OCT dataset to classify scans into clinically relevant categories such as NORMAL, DRUSEN, DME, and CNV. This model acts as the visual analysis engine that processes OCT images and identifies potential retinal abnormalities.
Next, we implemented a real-time OCT streaming pipeline using Python and OpenCV. The system reads frames from a recorded OCT video stream and sends them through the trained model for continuous analysis. Each frame is evaluated and the model predictions are converted into clinically meaningful explanations using a clinical interpretation layer.
To enable interactive assistance, we built a conversational AI co-pilot using the Agent Development Kit (ADK) and the Gemini Live API. Multiple specialized agents coordinate tasks such as vision analysis, clinical interpretation, and alert generation. The system also integrates tools through the Model Context Protocol (MCP) so that the conversational agent can access the OCT analysis results as structured context.
The backend pipeline orchestrates these components in real time: OCT frames are analyzed by the vision model, interpreted by the clinical layer, and then communicated to the conversational agent. A simple dashboard displays the live OCT feed along with AI alerts and explanations.
Finally, we added a voice interaction layer, allowing a surgeon (or student in training mode) to ask questions about the scan and receive spoken explanations. This demonstrates how multimodal AI agents can combine vision understanding, medical reasoning, and natural conversation to assist with retinal analysis.
Challenges we ran into
One of the main challenges was integrating multiple components into a real-time pipeline. While training the CNN model for OCT classification was straightforward, connecting it to a live video stream and ensuring that each frame could be processed quickly enough for real-time analysis required careful optimization.
Another challenge was designing a meaningful clinical interpretation layer. The dataset labels represent ophthalmology conditions such as DRUSEN, DME, and CNV, but translating these predictions into explanations that would be useful for surgeons or students required additional reasoning logic.
We also faced difficulties while integrating agent orchestration and tool access using the Agent Development Kit and Model Context Protocol. Ensuring that the conversational AI agent could reliably access the latest vision analysis results and respond in a natural way required structuring the system into multiple cooperating agents.
Finally, building a smooth live demo experience was challenging. Streaming OCT frames, generating alerts, overlaying results on the video feed, and enabling real-time voice interaction had to work together seamlessly so that the system could demonstrate the concept clearly within a short hackathon presentation.
Accomplishments that we're proud of
One of our biggest accomplishments was successfully combining computer vision, real-time streaming, and conversational AI into a single working system. We were able to build a pipeline that analyzes OCT scans continuously and converts model predictions into meaningful clinical insights.
We are also proud of creating a multimodal AI surgical assistant that can both see medical imaging data and communicate findings through natural voice interaction. This demonstrates how AI agents can move beyond simple chat interfaces and become context-aware assistants for real-world scenarios.
Another achievement was implementing a training mode for medical students, where the AI agent explains OCT scan findings in audio form. This turns the system into not only a surgical awareness tool but also an educational assistant for learning retinal imaging.
Finally, we are proud that the project demonstrates a complete agent-based architecture, integrating vision models, real-time analysis, and conversational agents to showcase the future potential of AI-assisted healthcare tools.
What we learned
Through this project, we learned how to combine computer vision, real-time data streaming, and conversational AI agents into a single system. Building the OCT analysis pipeline helped us better understand how deep learning models can be applied to real medical imaging data and how their predictions must be carefully interpreted to provide meaningful clinical insights.
We also gained experience designing agent-based systems using the Agent Development Kit and integrating tools through the Model Context Protocol. This helped us understand how multiple agents can collaborate to handle tasks such as visual analysis, clinical interpretation, alert generation, and user interaction.
Another key learning was how important real-time interaction and system orchestration are when building live AI applications. Ensuring that video processing, model inference, and voice-based communication worked smoothly together required thoughtful system design.
Finally, this project gave us insight into the potential of multimodal AI in healthcare, showing how AI agents that can see, reason, and communicate could assist professionals and also support medical education.
What's next for RETINA LIVE - REAL TIME AI SURGICAL ASSISTANT
The next step for RETINA LIVE is to evolve from a prototype into a more advanced clinical decision-support system. We plan to improve the vision model by training it on larger and more diverse OCT datasets and incorporating segmentation models that can precisely highlight retinal layers and abnormal regions rather than only classifying images.
We also aim to integrate real intraoperative OCT streams so the system can operate in a realistic surgical environment. This would allow the AI co-pilot to provide continuous monitoring and more accurate guidance during delicate retinal procedures.
Another future direction is expanding the Training Mode into a full educational platform where medical students and ophthalmology trainees can interact with the AI agent to learn how to interpret OCT scans, ask questions, and receive step-by-step explanations of retinal structures and abnormalities.
Finally, we plan to enhance the multimodal AI capabilities by enabling deeper reasoning, richer visual annotations, and more advanced conversational assistance, ultimately moving toward an AI system that can act as a reliable clinical assistant for ophthalmologists and an intelligent tutor for medical education.
Built With
- agent-development-kit-(adk)
- google-cloud
- google-gemini-live-api
- jupyternotebook
- keras
- matplotlib
- model-context-protocol-(mcp)
- numpy
- opencv
- pandas
- python
- streamlit
- tensorflow


Log in or sign up for Devpost to join the conversation.