-
-
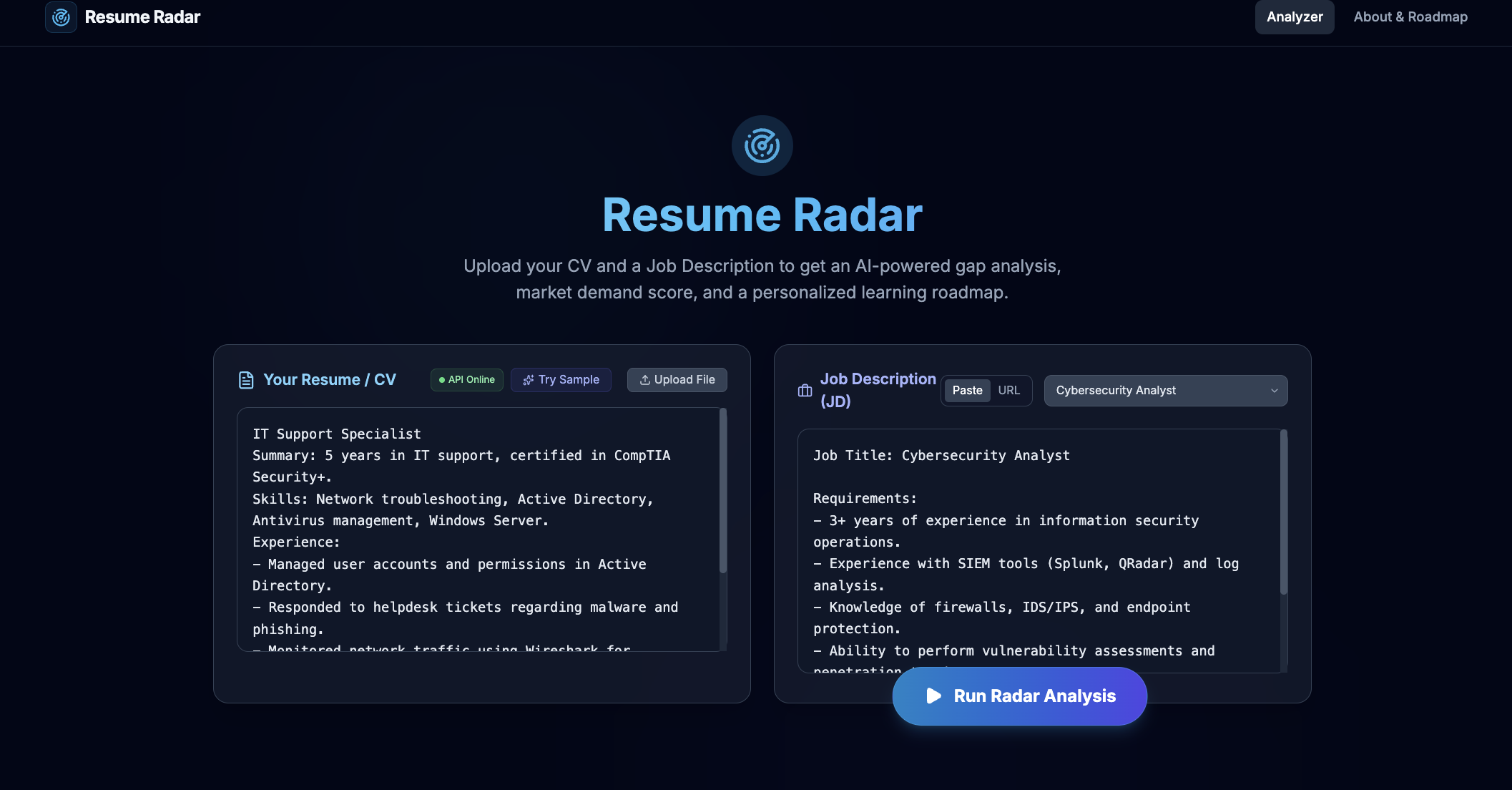
Home page
-
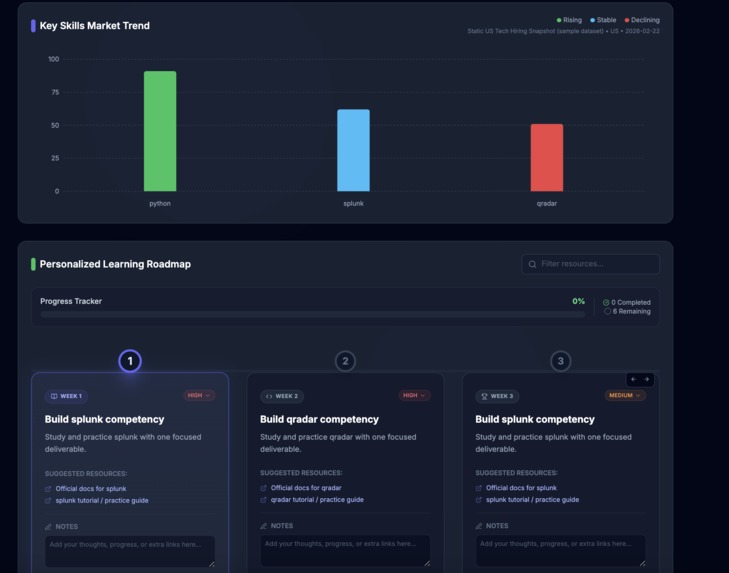
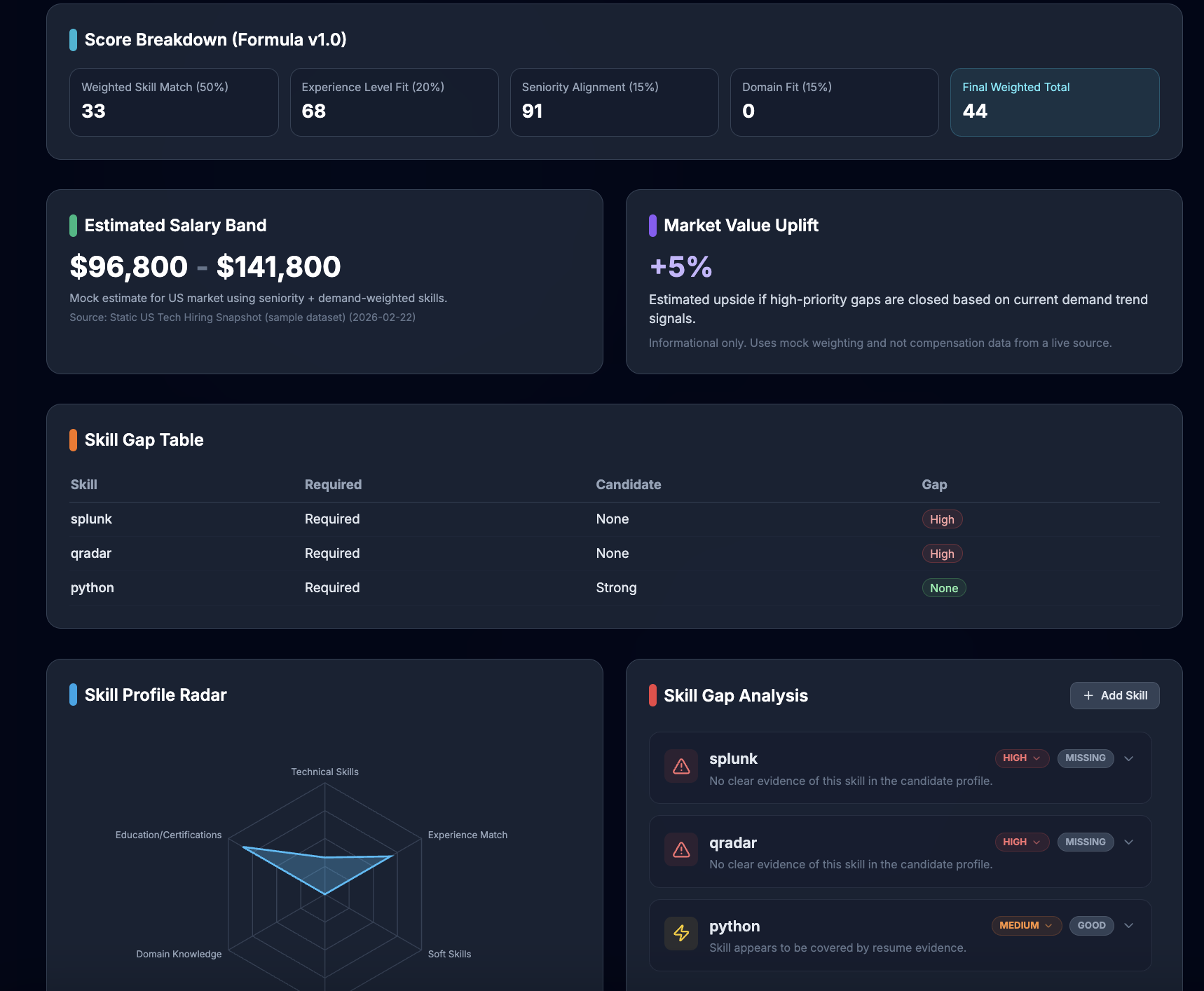
Result
-
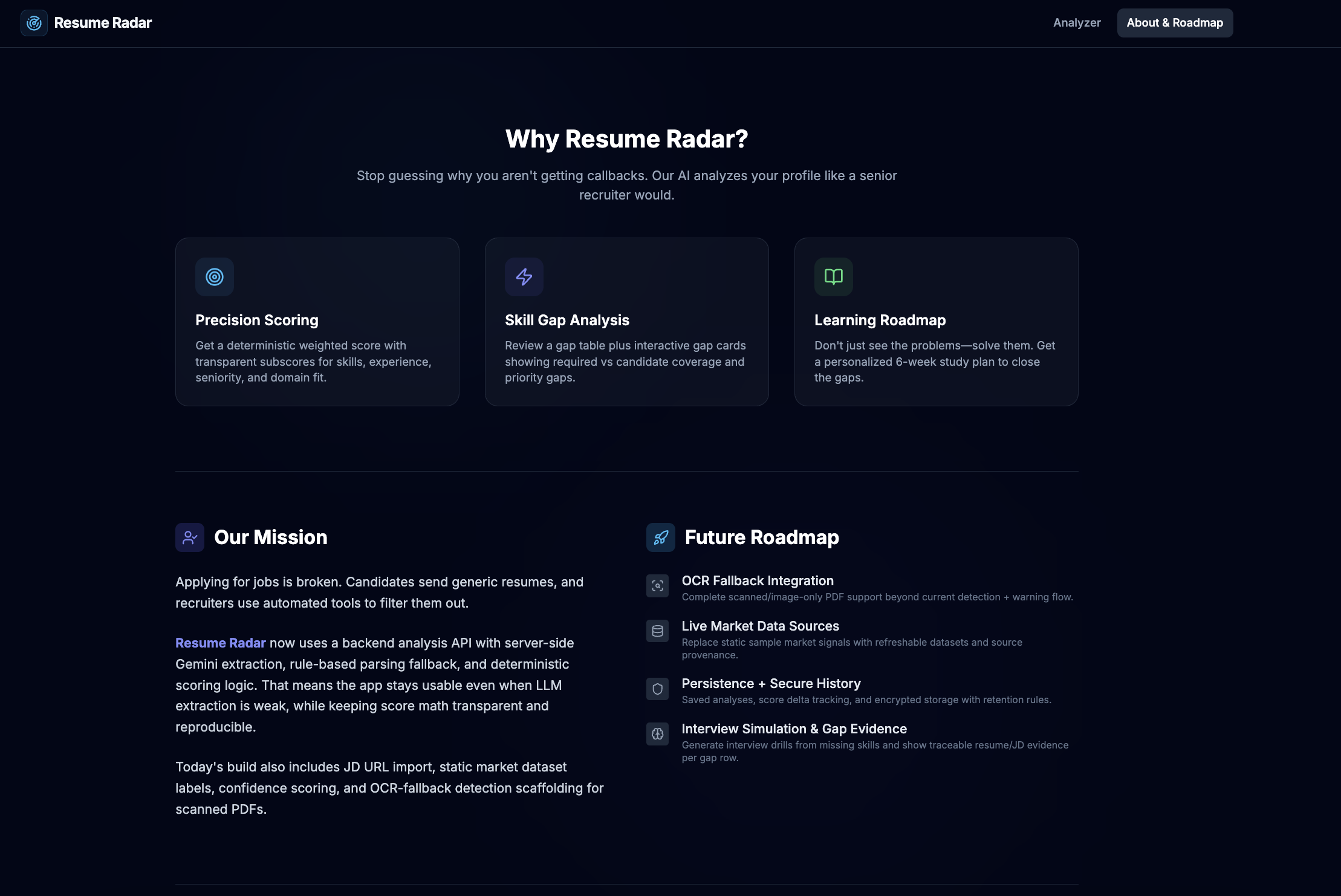
About
-
Query
-
Result
-
Result
-
Result
Inspiration
Job seekers often get rejected without knowing why.
Most resume tools rewrite content, but none quantify skill gaps against real job requirements.
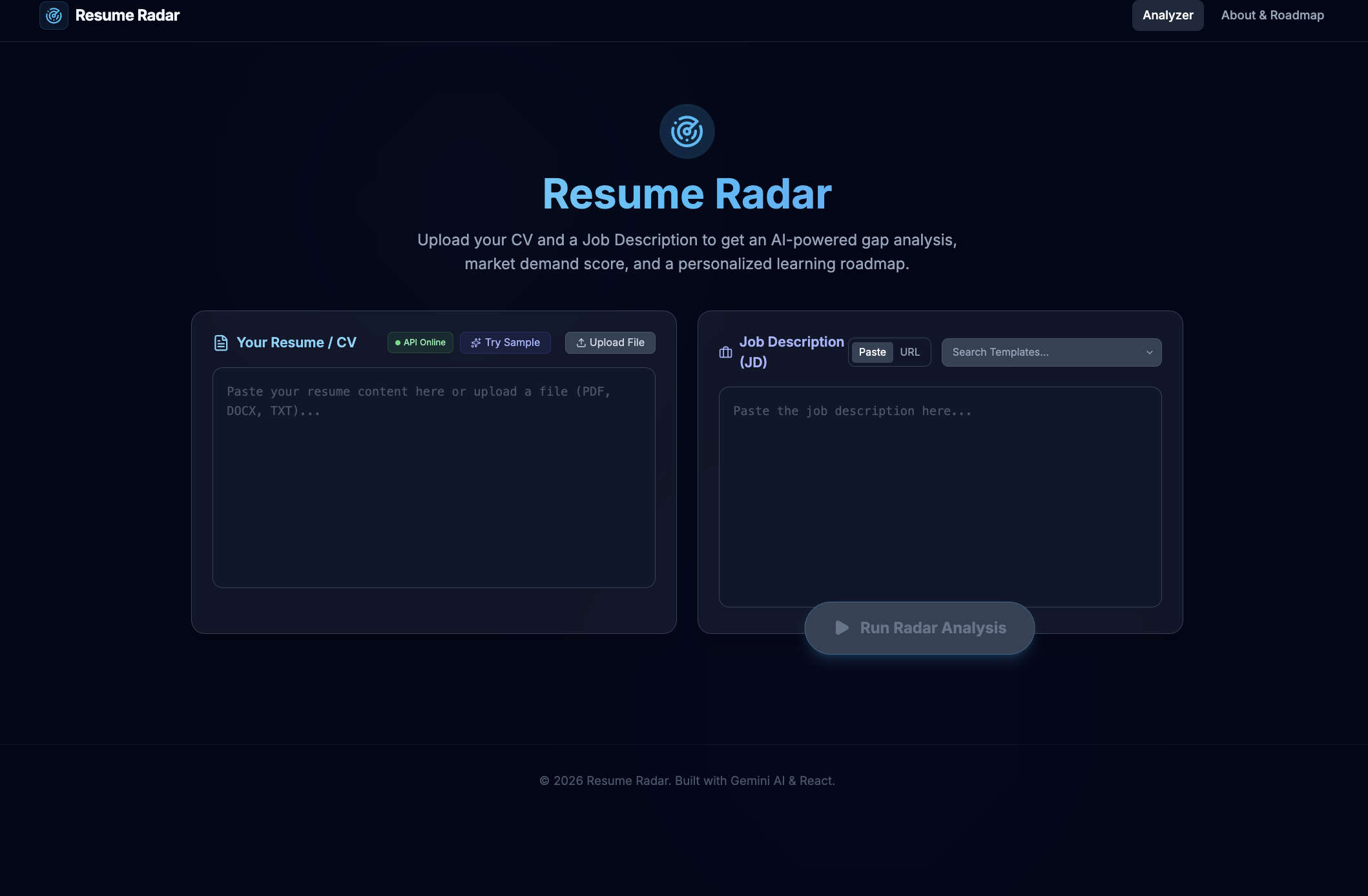
We built Resume Radar to turn resume screening from subjective feedback into measurable career intelligence.
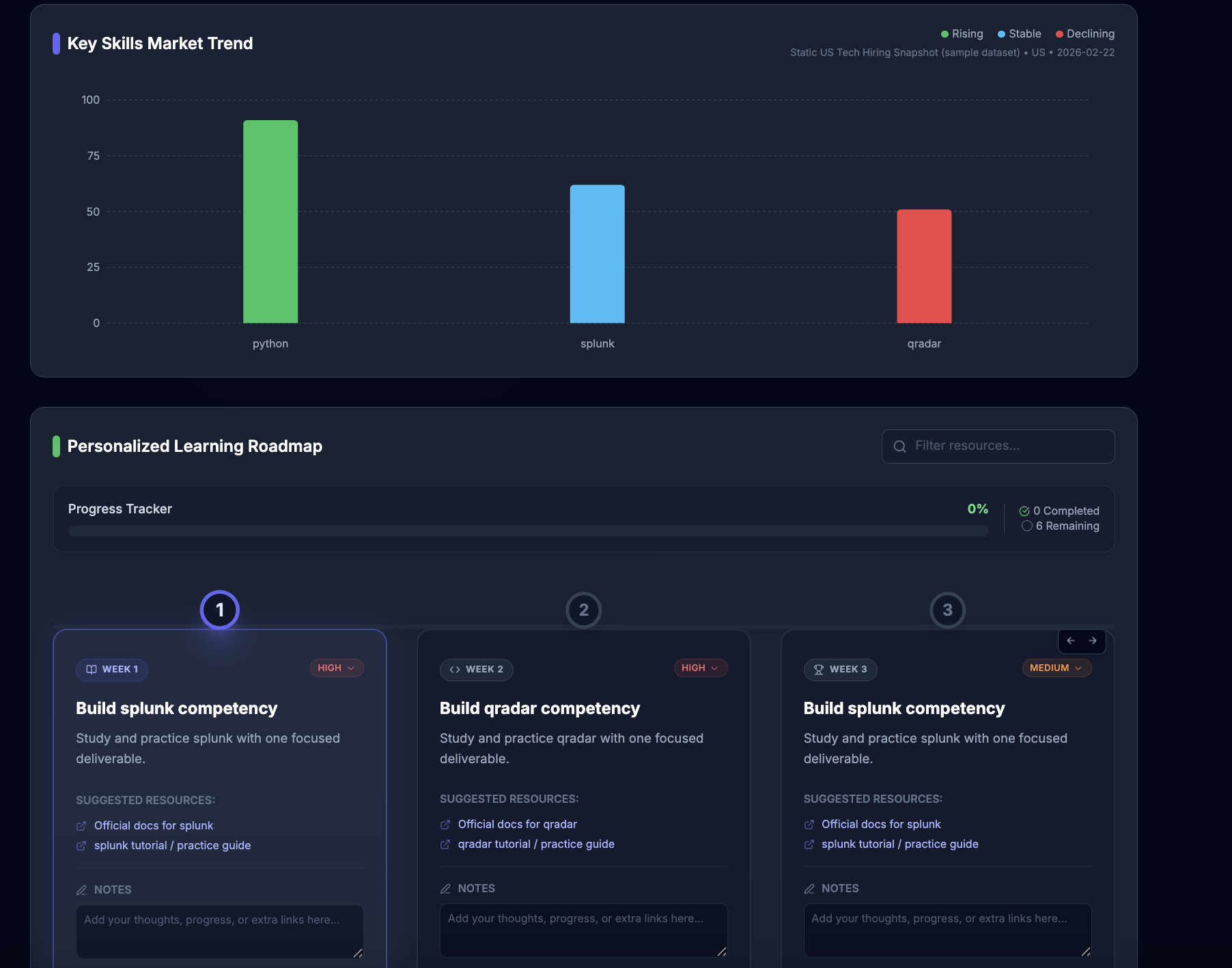
What it does
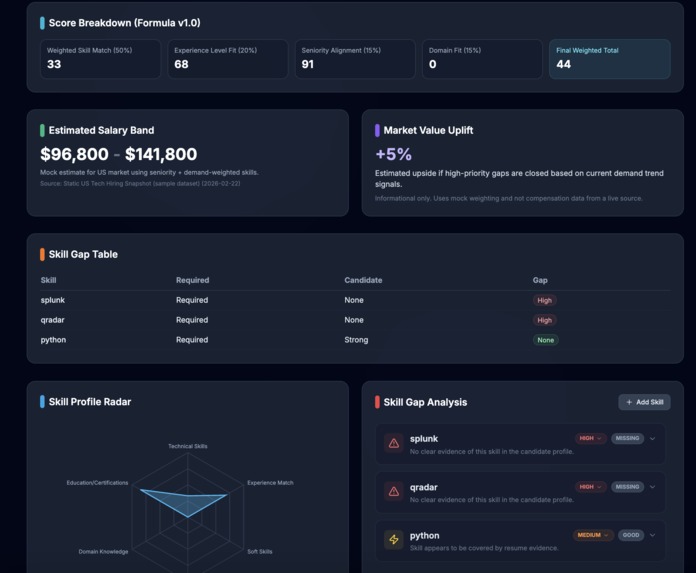
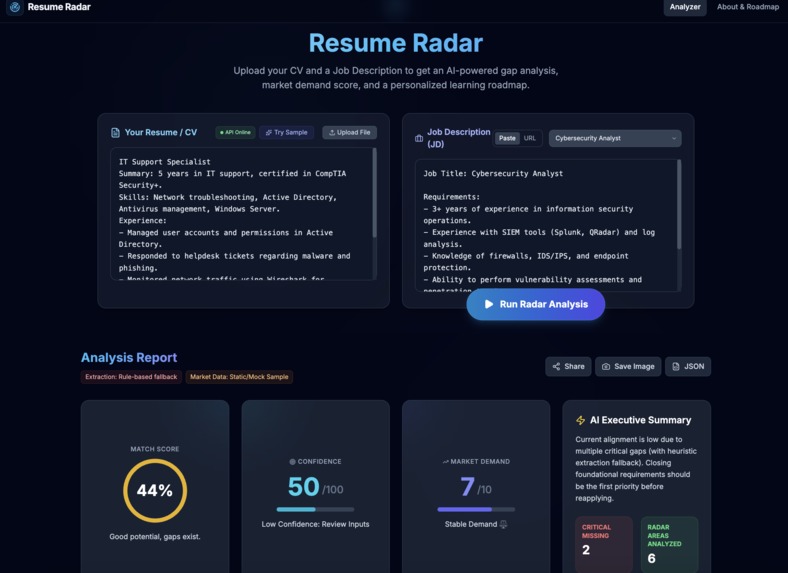
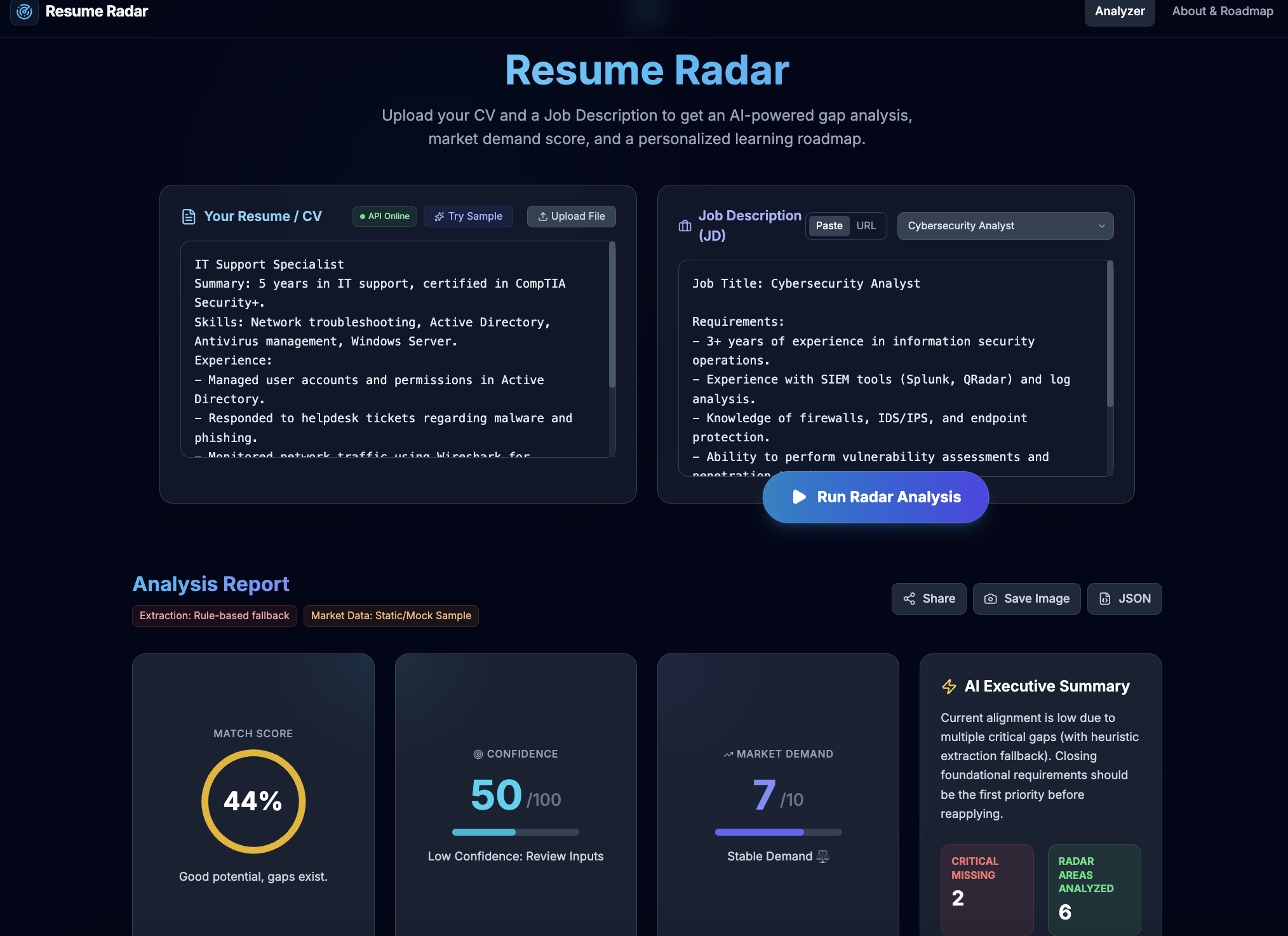
Resume Radar analyzes a candidate’s CV against a job description and generates:
- Overall match score (%)
- Confidence score (0-100)
- Transparent score breakdown (skills / experience / seniority / domain)
- Skill gap breakdown
- Missing critical competencies
- Gap table (
Skill | Required | Candidate | Gap) - Market demand insights (with source label/date)
- Estimated salary band + market value uplift (currently static sample market dataset)
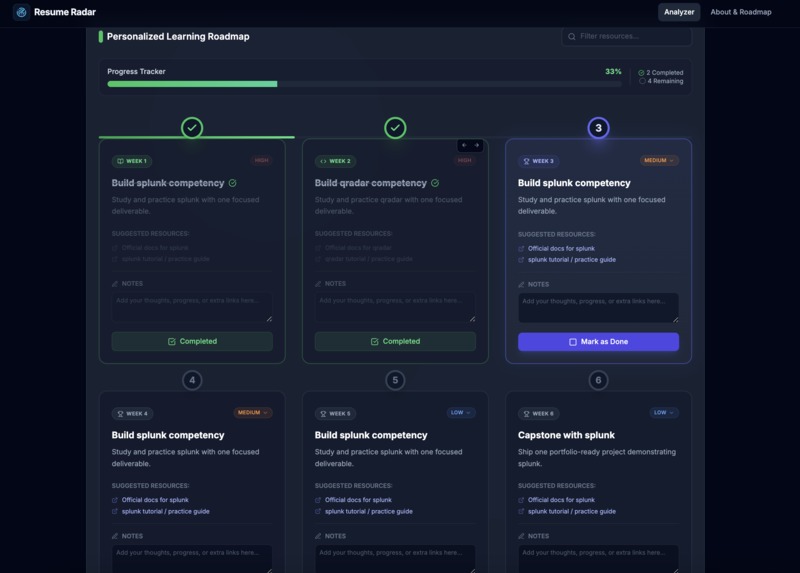
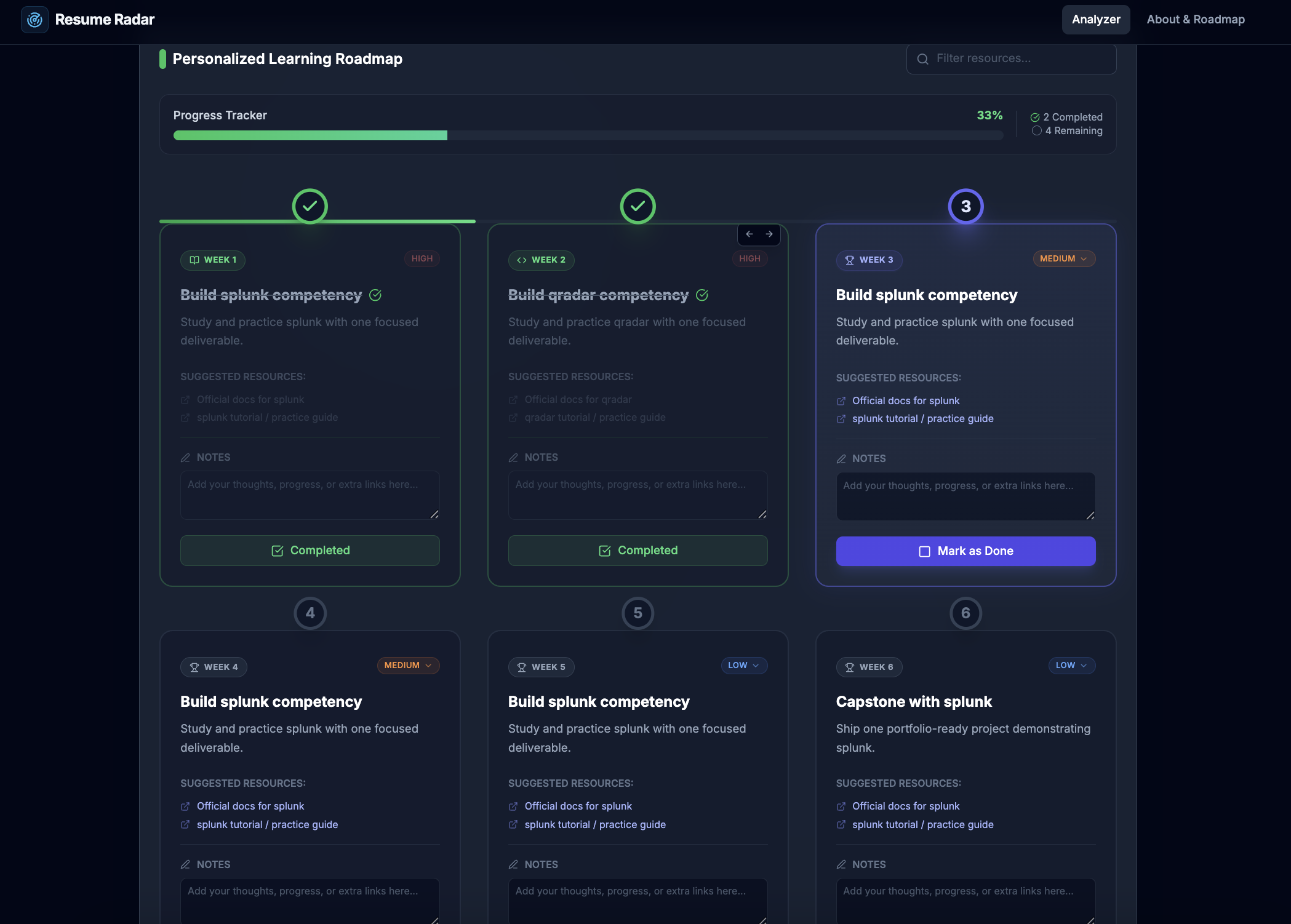
- Personalized 6-week improvement roadmap
It transforms resume optimization into a data-driven dashboard experience.
Instead of guessing, users see exactly:
What they’re missing.
How much it matters.
What to do next.
How we built it
- Frontend dashboard in React + Vite (with lazy-loaded chart components)
- Backend analysis API (
POST /api/analyze) with health endpoint (GET /health) - Server-side Gemini extraction for resume/JD parsing (no frontend API key usage)
- Rule-based parsing fallback for resume and JD when LLM extraction is missing/weak
- Deterministic weighted match scoring algorithm (transparent subscores)
- Skill normalization via canonical dictionary + synonym mapping (rule-based)
- Static sample market dataset for demand trends / salary estimate / uplift (explicitly labeled in UI)
- Interactive analytics dashboard with gap table, radar chart, market trends chart, and 6-week roadmap
The system combines NLP extraction, scoring logic, and visual intelligence.
Challenges we ran into
- Handling inconsistent resume formats
- Supporting scanned/image-only PDFs (OCR fallback not fully integrated yet)
- Normalizing synonymous skills (e.g., React vs React.js)
- Preventing LLM hallucination in skill extraction
- Designing transparent scoring logic while preserving useful UX
- Making the app resilient when backend API or LLM extraction is unavailable
We mitigated these using schema validation, canonical skill dictionaries, deterministic scoring, rule-based extraction fallback, and backend health checks surfaced in the UI.
Accomplishments that we're proud of
- Built a working end-to-end resume-to-dashboard pipeline with a backend API
- Moved Gemini usage server-side and kept the frontend secret-free
- Implemented explainable deterministic match scoring + confidence score
- Added rule-based fallback parsing so analysis still works when LLM extraction fails
- Designed an intuitive gap table + chart-based visualization system
- Delivered structured 6-week improvement roadmaps with interactive tracking
What we learned
Career readiness is not binary — it is measurable.
Transparency in scoring increases user trust.
Hybrid systems (LLM extraction + deterministic scoring + fallback rules) are far more reliable than LLM-only flows.
Visualization dramatically improves comprehension of complex gap analysis.
What's next for Resume Radar
- Real OCR integration for scanned/image-only resumes
- Replace static market dataset with refreshable public data sources
- Add gap evidence traceability (resume/JD snippets per skill)
- Analysis history + score delta comparisons over time
- Multi-job comparison dashboard
- GitHub portfolio scoring
- Interview question prediction
- Recruiter-facing analytics mode
Resume Radar can evolve into a full career intelligence platform.

Log in or sign up for Devpost to join the conversation.