-

Initial Page
-
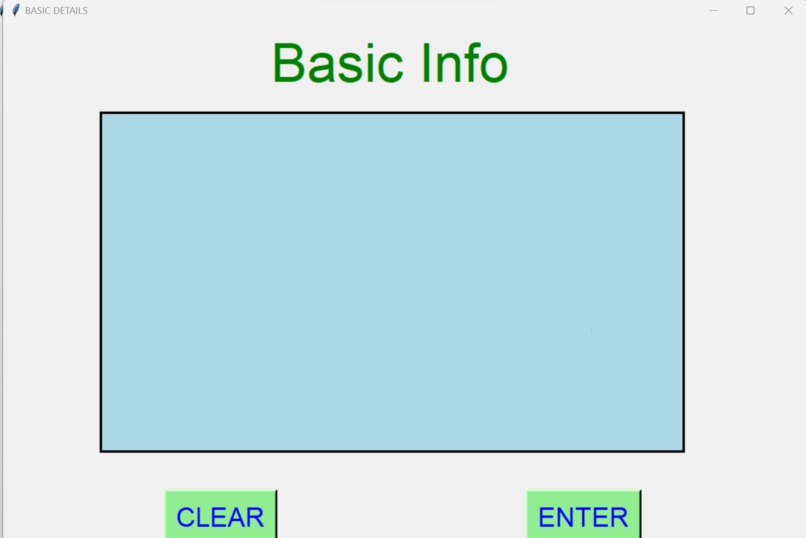
Inputing Data
-

Resume generated


Inspiration
The inspiration for this project stemmed from the need to create a more intelligent way to generate resumes that could be useful for AI-based resume detection in companies. The idea was to leverage Natural Language Processing (NLP) to parse and understand the content of resumes and then generate a structured document based on the identified entities.
What it does
The project uses a spaCy NER model to identify and classify entities within the input data. These entities include crucial resume components like Education, Experience, Achievements, and more. The model identifies how many entities are present and selects a corresponding resume type.
The resume template used in the project has a predefined color scheme, ensuring that the generated resumes maintain a consistent and professional appearance. The final product organizes the data dynamically according to the number of titles in the resume, offering a user-friendly interface built with Tkinter.
Challenges we ran into
During the development process, I faced significant challenges, particularly with the dataset. I obtained a resume dataset from Kaggle, formatted for a Named Entity Recognition (NER) model. However, the dataset was not perfect, and the format issues made it difficult to work with directly. The key challenge was extracting relevant keywords and properly annotating them in a .json file. This required manual effort to ensure that each word was correctly associated with its respective class, such as Education, Experience, or Achievements.
What's next for Resume Generator
The model does need more fine-tuning for accurate results. While the project is still a work in progress and hasn't yet achieved the level of AI-driven resume generation I initially aimed for, it serves as a valuable step towards that goal.
Built With
- natural-language-processing
- ner
- python
- tkinter


Log in or sign up for Devpost to join the conversation.