-
-

Our video forgot to include this, but clicking on the Job Title shows the LinkedIn page.
-
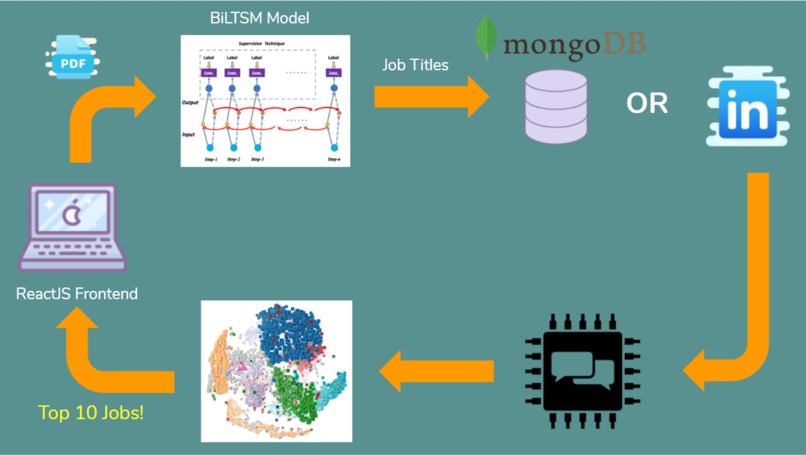
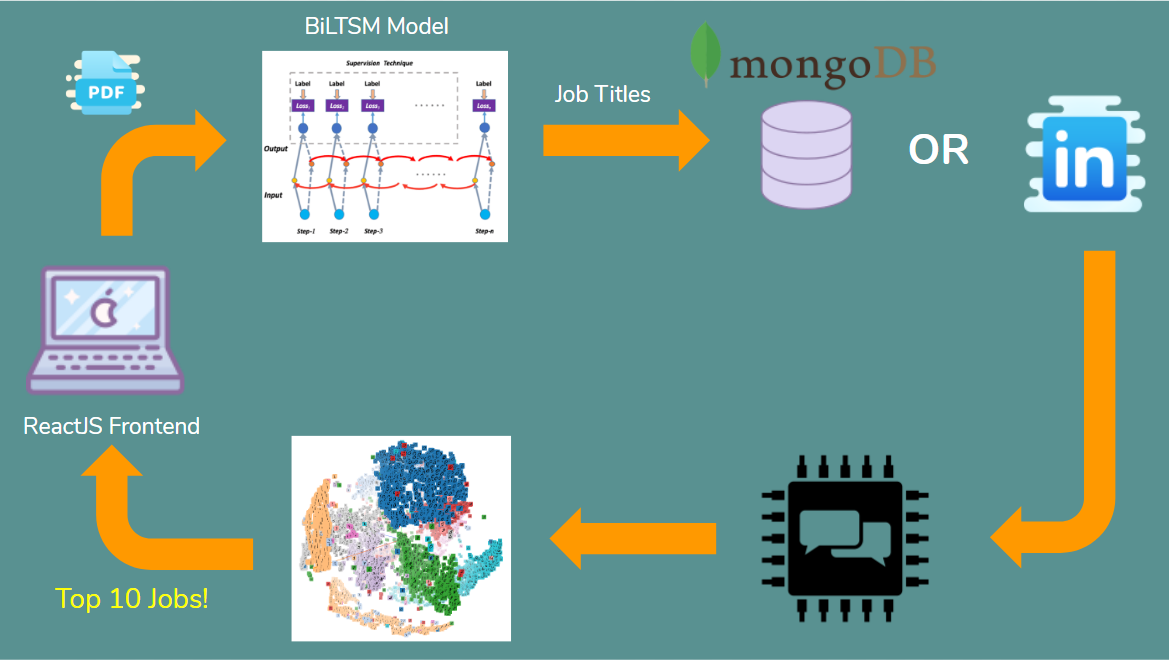
This is the architecture of our project.
-

Another logo design. They're all so beautiful!
-

And another one!
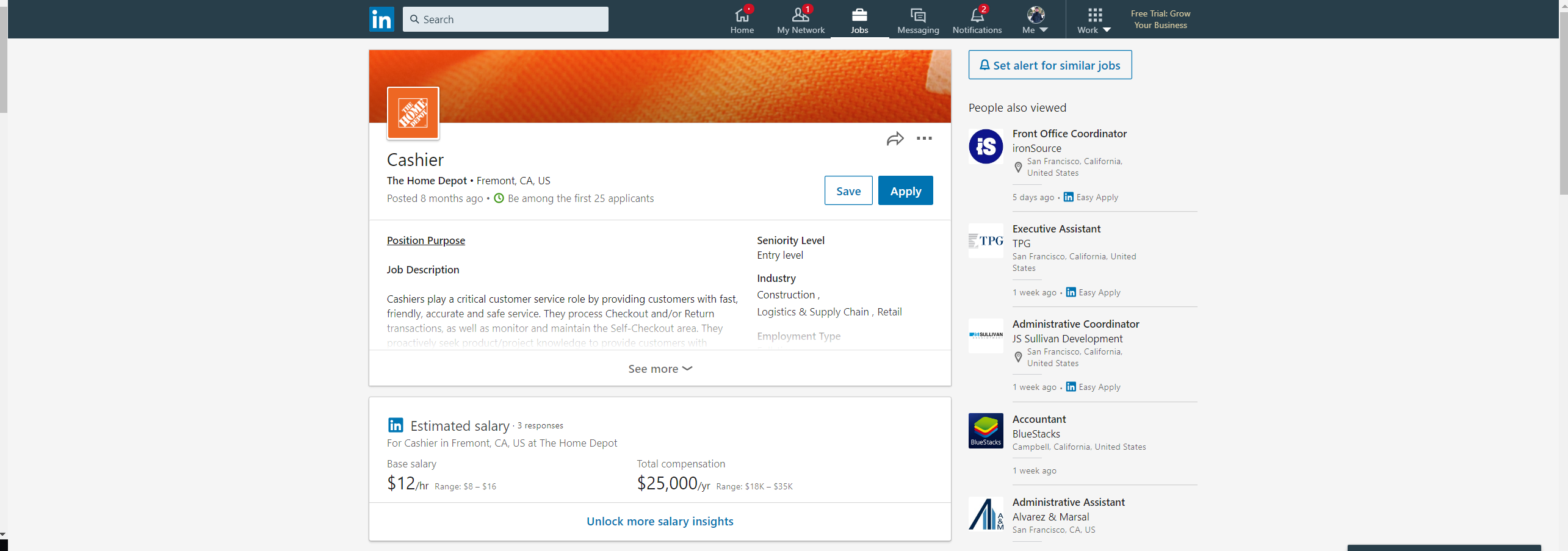


(Note: Please look at the first image we've uploaded alongside the video for a feature we missed in the demo.
Inspiration
Although the new cases of COVID-19 are terrible, our team noticed that the swathes of unemployed persons in the United States affected by quarantine parallels the Great Depression of the 1920s and might take years to fix.
The people affected by job loss aren't usually white-collar workers: fast food employees, cashiers, and mall workers are being put out of their jobs by the millions.
However, the one shining beacon is that these workers are highly adaptable and can fit many job descriptions! We realized that the best way to find new, compatible jobs for these workers is by analyzing soft skills in their resume that they've gained through experience.
What it does
Our application allows users to simply drag-n-drop their .pdf resume onto our site. From there, our NLP model will tag its soft skills, search for jobs that use those skills in a massive dataset of jobs and Google Jobs, and then recommend those jobs to those employees.
How we built it
The following summarizes the steps taken to provide smart job recommendations to applicants based on their uploaded resume:
- When the resume is uploaded onto our website as a PDF, we extract relevant information from the resume, such as the applicant’s skills and experience and parse them as text.
- We trained a Bidirectional Long Short Term Memory Network (BiLSTM) from scratch to categorize job descriptions into job titles like “business analyst” and “accountant”. With this model, we then predict the top 5 job titles that the skills and experiences listed in the resume is likely to fall under. This helps reduce the number of requests we have to make to the LinkedIn API, while still broadening the options of the applicant and not restricting them to a single job title.
- We query our MongoDB to see if we have stored the job listings for each of the 5 job titles in our database. If not, we make a request to the LinkedIn API to get job postings that are relevant to the top 5 job titles found.
- With the job postings, we use a state-of-the-art Natural Language Processing model, the Universal Sentence Encoder, to encode the job descriptions into high dimensional vectors and capture the nuances behind each word in the description.
- We also encode the resume information into high dimensional vectors and use cosine similarity to measure the similarity of the applicant’s resume with the job description.
- We return the top 10 most similar job postings that match the applicant’s skill sets.
Impact of our Project
We hope our project can help ease people back into jobs following the COVID-19 pandemic by providing them with more avenues to look for jobs. We hope this will simplify the job seeking process for them and open them up to more opportunities, both in terms of finding new suitable job titles and also finding more relevant job postings that are suited to their individual experiences and soft skills through the power of machine learning.
Challenges we ran into
- Finding a suitable dataset -- datasets containing job postings and resumes are difficult to find as they are not commonly used in machine learning. Furthermore, the dataset we found was noisy so we had to do data preprocessing to clean it.
Accomplishments that we're proud of
What we lacked on the frontend, we made up heavily on the backend with not one but two machine learning models! We were surprised to see that our BiLSTM model worked really well despite the limited training data, achieving over 90% accuracy on the test set.
What we learned
Our team had to do a lot of research on the structure of .pdf files in order to extract _ relevant _ information from it.
What's next for ResuMatch
Our website is live at https://resumatch.online/! We plan to collect more data to improve the classification of the job titles and increase the range of job titles available.









Log in or sign up for Devpost to join the conversation.