-
-
architecture_diagram
-

tools_pipeline
-
workflow_diagram
-

validation_results
-
safety_gates



Inspiration
The OECD published a 98-page working paper in March 2025 estimating that diagnostic errors cost the United States $870 billion per year — 17.5% of total healthcare expenditure. One of the most documented and preventable causes isn't misreading a scan. It's the follow-up that never happened.
- 35.5% of pulmonary nodule patients receive no follow-up imaging (AHRQ / Brigham & Women's Hospital, 2025)
- 26% of BI-RADS 3 breast findings — 386 out of 1,511 patients — have no documented closure (AHRQ Lacson Report, 2025)
- 1 in 7 radiology recommendations never achieve documented follow-up (JAMA Network Open, 2022)
- 44% of diagnostic errors involve a failure to follow up on a lab or imaging result (Schiff et al., cited BMJ Open Quality 2023)
- The follow-up and coordination phase is a cause or contributor in 46% of severe and fatal diagnostic adverse events (PMC, March 2025)
The problem isn't that clinicians don't care. It's that no system is watching the loop.
Consider this scenario: a BI-RADS 4 mammogram is filed. The radiologist moves on. The referring clinician never gets a callback. The patient never hears back. Sixty-three days pass. A suspicious breast finding remains unresolved, and the window for earlier diagnosis narrows. Nobody lied, nobody was negligent — the loop simply was never watched.
Commercial platforms like Rad AI Continuity ($40M+ funded), Inflo Health, and Vital Guard are racing to solve this for large health systems — but none of them work inside an AI agent platform via MCP. ResultLoop is an MCP-native implementation of closed-loop abnormal result follow-up auditing, built to run inside an AI agent platform rather than as a standalone enterprise workflow system.
This is distinct from HEDIS quality measure gap programs, which track whether preventive screenings were ordered. ResultLoop audits the step after a critical finding has already been returned — whether the abnormal result has documented follow-up or is silently sitting open in the chart.
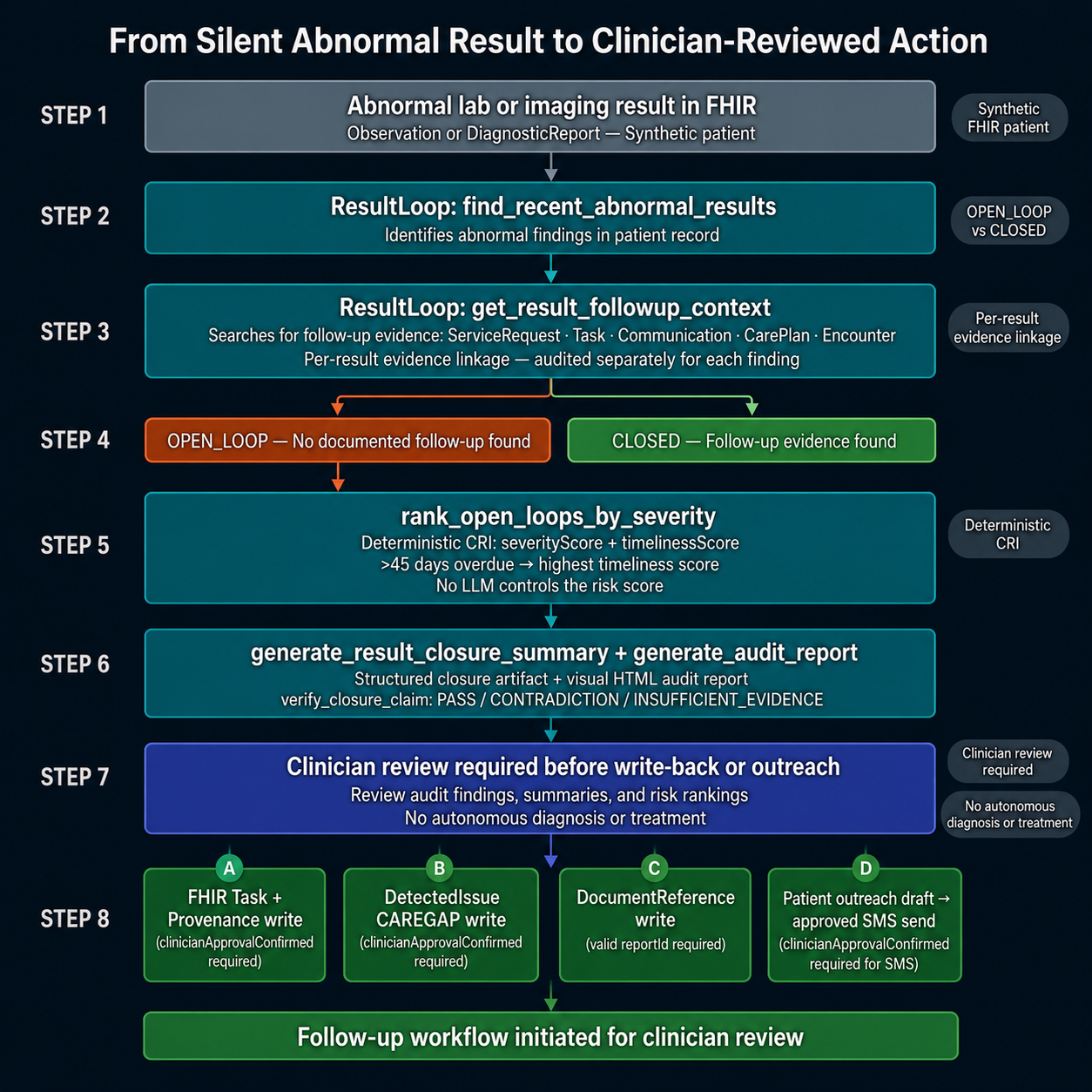
What it does
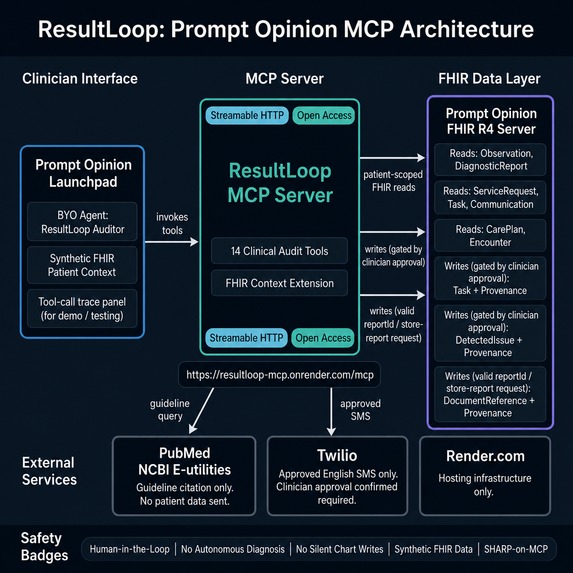
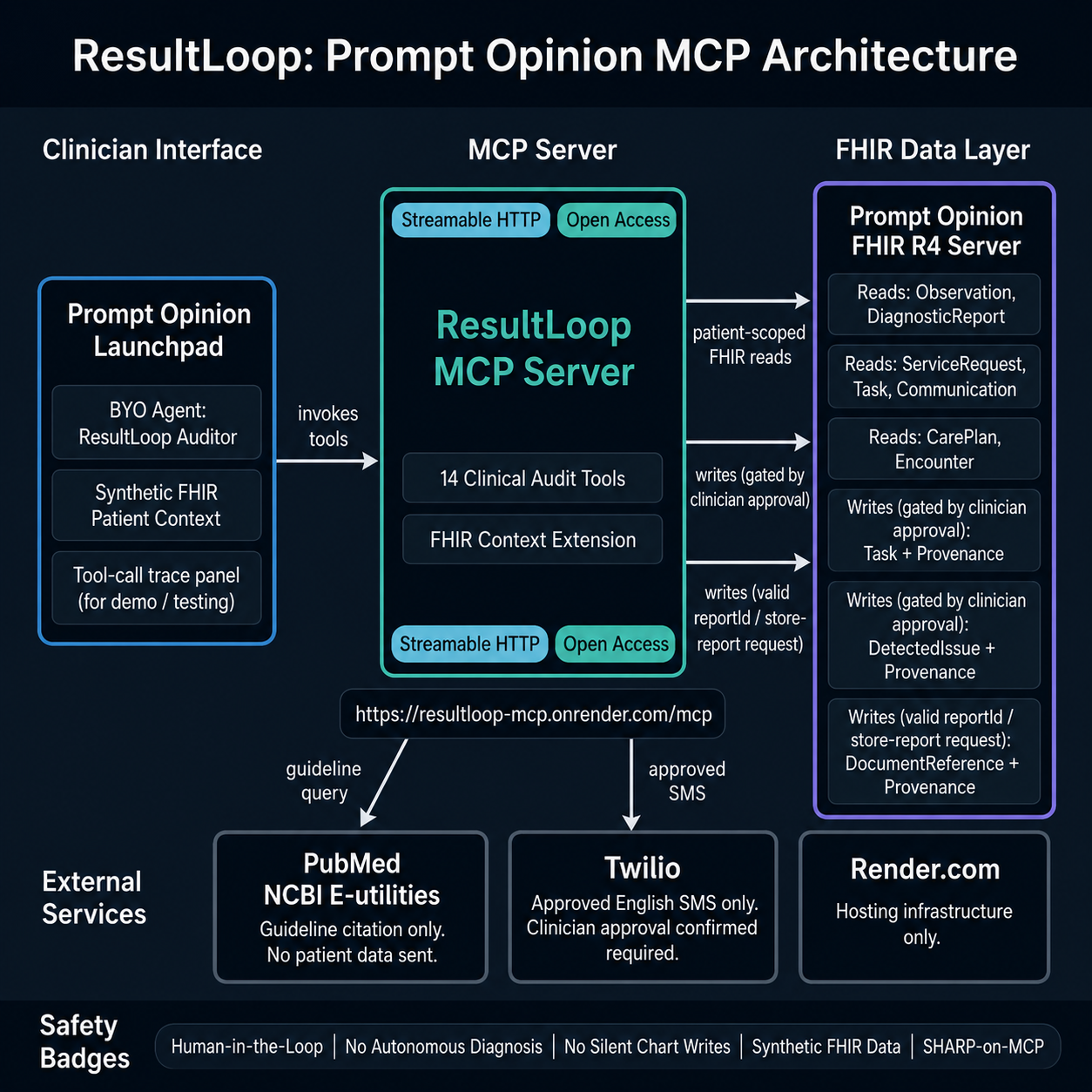
ResultLoop is a SHARP-on-MCP clinical safety server that audits patient FHIR records for abnormal lab and imaging results lacking documented follow-up closure. It works inside Prompt Opinion: any agent can invoke it against a patient's live FHIR record to discover open loops, rank them by risk, and draft closure actions for clinician review.
14 tools across 4 workflow stages:
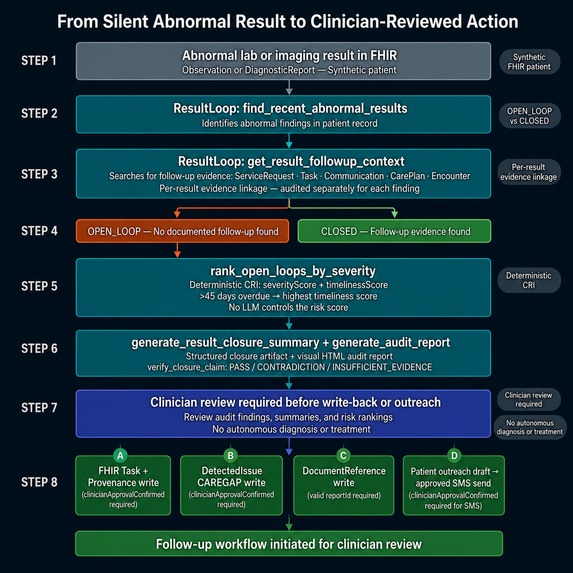
DISCOVER
find_recent_abnormal_results— scans Observations and DiagnosticReports for abnormal/critical/panic-value flagsget_result_followup_context— searches ServiceRequest, Task, Communication, CarePlan, Encounter for closure evidence; returnsOPEN_LOOPorCLOSEDget_patient_loop_history— detects longitudinal closure-failure patterns across 24 months (repeat misses)
EVIDENCE
get_clinical_guideline— searches PubMed E-utilities (esearch → esummary) for real PMID-cited clinical guidelines by finding type (BI-RADS, Lung-RADS, CA-125, etc.); returns journal metadata and direct PubMed URLs; no patient data sent to NCBI
ANALYZE
rank_open_loops_by_severity— deterministic Closure Risk Index (CRI) using BI-RADS, Lung-RADS, HbA1c, eGFR, TSH, potassium, FIT, hemoglobin thresholds — no LLM touches the scoregenerate_result_closure_summary— structured clinical safety artifact with evidence matrix and per-result risk assessmentverify_closure_claim— hallucination guardrail; returnsPASS/CONTRADICTION/INSUFFICIENT_EVIDENCE
ACT
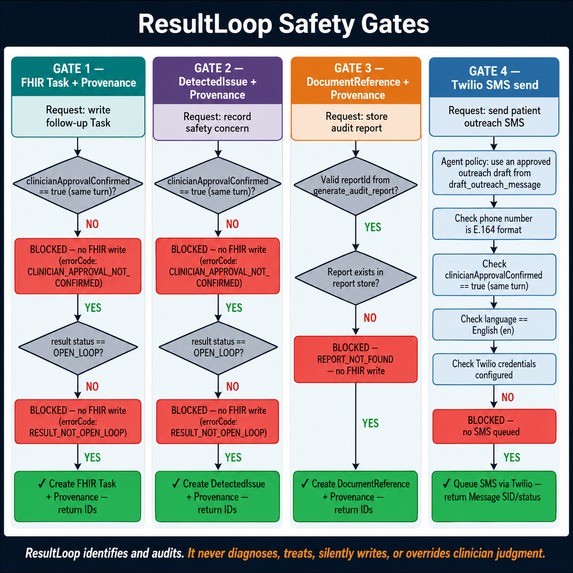
draft_followup_task_resource— draft-only FHIR R4 Task + AuditEvent with SHA-256 hash; never writes to the chartwrite_followup_task— writes FHIR Task + Provenance to the chart; requires explicitclinicianApprovalConfirmed: truein the same conversation turn — blocked by parameter-level validation, not just promptdraft_outreach_message— multilingual patient outreach (English / Spanish / Hindi) with 21st Century Cures Act framinggenerate_audit_report— self-contained HTML clinical safety report — donut chart, severity cards, evidence matrixwrite_audit_report_document_reference— writes the HTML audit report as a permanent FHIRDocumentReference(LOINC11503-0, base64 embedded, linked Provenance) — survives session expiry, readable by any downstream EHRwrite_detected_issue— writes a FHIRDetectedIssue(CAREGAP / care gap) for each open-loop result; severity mapped from CRI score; gated by explicit clinician approvalsend_sms_outreach— sends clinician-approved patient outreach SMS via Twilio Programmable Messaging; gated by explicitclinicianApprovalConfirmed: truein the same conversation turn; E.164 phone validation; English (en) only on current Twilio trial account; never sends autonomously
Safety by design: Action-oriented writes such as Task, DetectedIssue, and SMS outreach require explicit clinician approval in the same conversation turn. Audit report persistence requires a valid generated reportId and writes a DocumentReference + Provenance record. ResultLoop identifies and audits — it never diagnoses, never treats, never overrides clinical judgment.
How we built it
- Runtime: TypeScript + Node.js on Express
- MCP transport: Streamable HTTP (SHARP-on-MCP,
ai.promptopinion/fhir-contextextension declared in capabilities) - FHIR R4: reads Observation, DiagnosticReport, ServiceRequest, Task, Communication, CarePlan, Encounter; writes
Task+Provenance+DocumentReference(LOINC11503-0, base64 HTML audit report) +DetectedIssue(CAREGAP, severity=high/moderate/low). Task and DetectedIssue writes require explicit clinician approval; DocumentReference persistence requires a valid generated reportId and linked Provenance. - PubMed: NCBI E-utilities two-step pipeline (esearch → esummary); real PMIDs verified against live PubMed; no patient data transmitted to NCBI
- Deterministic scoring: Closure Risk Index (CRI) —
totalPriorityScore = severityScore + timelinessScore; severity classified from BI-RADS / Lung-RADS / lab thresholds (CRITICAL→90, HIGH→60, MODERATE→30, LOW→10); timeliness step-scored by days since result (≥45d→30, ≥30d→20, ≥14d→10); no LLM touches the score - Integrity: SHA-256 closure artifact hash on every audit; Provenance chain on every FHIR write
- Patients: 5 synthetic FHIR transaction bundles (Maria Lopez, James Chen, Sarah Williams, Robert Johnson, Priya Patel) across oncology, nephrology, endocrinology, cardiology, pulmonology
- Deployment: Render — live at
https://resultloop-mcp.onrender.com/mcp - Twilio SMS: native
fetch-based Twilio Programmable Messaging integration (no SDK); HTTP Basic auth; E.164 phone validation; 155-char GSM-7 hard cap (single segment on Twilio trial); same-turn clinician approval gate enforced at parameter level; English-only SMS delivery (ES/HI drafts generated but blocked at send-time on trial account) - Validation: 17 labeled test scenarios across 5 synthetic patients — 50 assertions, zero false closures, all safety gates verified
Challenges we ran into
- Per-result closure isolation: A follow-up ServiceRequest for one condition must not count as closure evidence for a different abnormal result. Built a custom result-linkage resolver (
result-linkage.ts) that deep-walks allreferencevalues in a FHIR resource JSON and matches by result ID, combined with code-term matching on LOINC display names — so a Task linked to a mammogram DiagnosticReport does not count as closure for an unrelated CA-125 Observation. This is one of the hardest engineering problems in the domain — and a major reason funded commercial platforms invest heavily in closed-loop follow-up infrastructure. - Deterministic vs. LLM ranking: Initial severity ranking used LLM judgment, which varied run-to-run. Replaced with the deterministic CRI formula so ranking is reproducible, citable, and audit-safe.
- Approval gate integrity:
write_followup_taskmust never fire without explicit approval — enforced at both the system-prompt level and parameter level (clinicianApprovalConfirmed: boolean). Tested with an adversarial "write it anyway" prompt — correctly blocked. - Visual audit report: Generated a self-contained HTML report with live donut chart and severity cards from pure MCP tool output, served directly from the Express server — no frontend build step.
Accomplishments that we're proud of
- 50 assertions pass across 17 labeled test scenarios — open-loop detection, false-close resistance, FHIR write, multilingual outreach, safety gates, PubMed evidence retrieval, Twilio SMS delivery
- Deterministic Closure Risk Index — a citable, auditable severity formula grounded in AHRQ published findings, equivalent to how Naranjo scoring works in pharmacovigilance
- 4 FHIR resource types written —
Task,Provenance,DocumentReference(LOINC11503-0, base64 HTML),DetectedIssue(CAREGAP) — action-oriented writes require explicit clinician approval, and persistence writes include linked Provenance - Permanent EHR-native audit record — the HTML audit report is embedded as base64 in a
DocumentReference, survives server restarts, readable by any FHIR R4-compliant system - Tri-state verification —
verify_closure_claimreturnsPASS / CONTRADICTION / INSUFFICIENT_EVIDENCE— a hallucination guardrail unique to our pipeline; a hallucinated closure is more dangerous than no answer - Multilingual outreach — drafts in English / Spanish / Hindi with 21st Century Cures Act framing; current Twilio trial delivery is English-only, with same-turn clinician approval gate enforced at the parameter level
- Longitudinal failure detection — 24-month repeat-miss pattern surfaces patients who have fallen through the cracks before, not just the current open result
- Concrete output example: for Maria Lopez,
rank_open_loops_by_severityreturnstotalPriorityScore: 90for the BI-RADS 4 mammogram (HIGH severity score 60 + ≥45 days timeliness score 30), ranked above the CA-125 elevation — deterministic, identical across every run
Benchmark
Eval corpus: 5 synthetic patients × 17 labeled scenarios × 50 assertions. Pipeline is fully deterministic — results are identical across runs.
| Benchmark | Score |
|---|---|
| Open-loop detection (True Positive Rate) | 100% — 11/11 |
| False closure rate | 0% — 0/11 |
Hallucination guardrail (verify_closure_claim) |
100% — 3/3 verdicts correct |
| CRI severity ranking correctness | 100% — 3/3 rank orders correct |
| FHIR write gate integrity | 100% — blocked without approval, writes with approval |
| Multilingual outreach (EN / ES / HI) | 100% — 3/3 languages correct |
| PubMed evidence retrieval | 100% — real PMIDs verified; graceful no-results handling |
| Twilio SMS delivery + approval gate | 100% — English SMS delivered to verified number (SMce30...); blocked without same-turn approval |
| Total | 50/50 assertions pass |
What we learned
- The most dangerous moment in clinical AI is a confident wrong answer. The tri-state verification (
PASS / CONTRADICTION / INSUFFICIENT_EVIDENCE) exists specifically because a hallucinated closure is more dangerous than no answer at all. - FHIR result linkage is the hardest part. Most commercial follow-up platforms cost millions because this is genuinely hard — determining which follow-up belongs to which result requires
reasonReference,basedOn,focus, and temporal proximity, not just date matching. - Deterministic scoring beats LLM scoring for clinical triage. The CRI formula produces the same ranking every run. Judges, clinicians, and auditors can verify it. That reproducibility is what makes it trustworthy.
- The $870B problem is real. OECD, AHRQ, and five funded startups all independently converged on the same problem. MCP is the missing interoperability layer that lets this capability work inside any agent workflow.
What's next for ResultLoop
rank_patients_by_loop_risk— multi-patient ward view; a charge nurse selects a department and sees every patient ranked by CRI in one call, not patient-by-patient- A2A agent layer — ResultLoop Auditor as a standalone A2A agent exposing
verify_closure_claimas a public safety primitive; any agent on the Prompt Opinion platform can call it without owning the full audit pipeline — a cross-agent hallucination guardrail - False-positive analysis — expanded eval corpus with precision/recall breakdown per result type (BI-RADS, Lung-RADS, lab panels); current corpus is 100% TP / 0% FP but needs wider coverage before production deployment
- EHR read-back — query the written
DetectedIssueandTaskresources post-session to confirm FHIR persistence and close the audit loop end-to-end
Judge verification
The uploaded judge setup package includes synthetic FHIR patient bundles, Prompt Opinion agent setup instructions, and testing output for the 17 validation scenarios.
Built With
- express.js
- fhir-r4
- gemini-flash
- mcp-sdk
- node.js
- render
- sha-256
- streamable-http
- twilio
- typescript
- zod
Log in or sign up for Devpost to join the conversation.