-
-
home
-
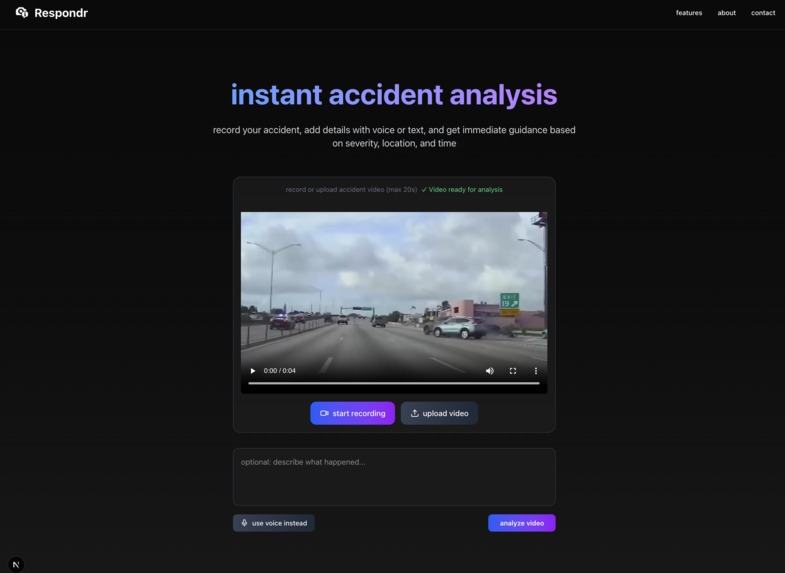
uploaded vid
-
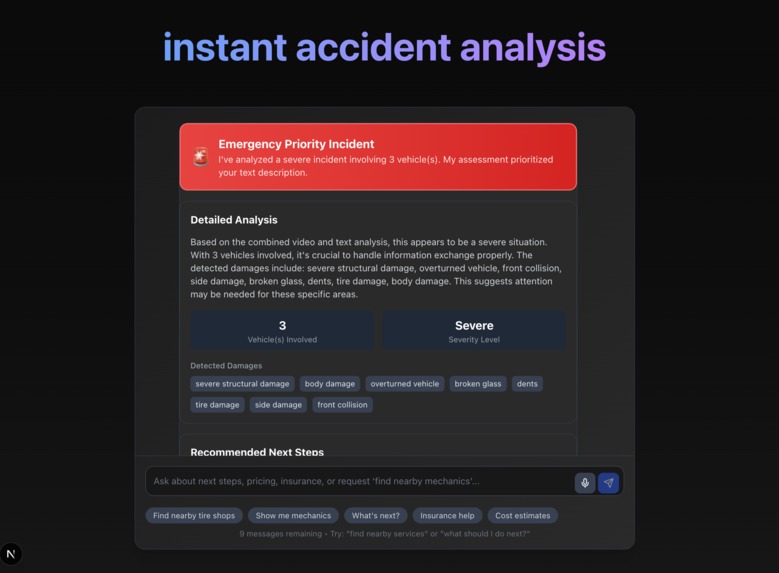
initial report
-
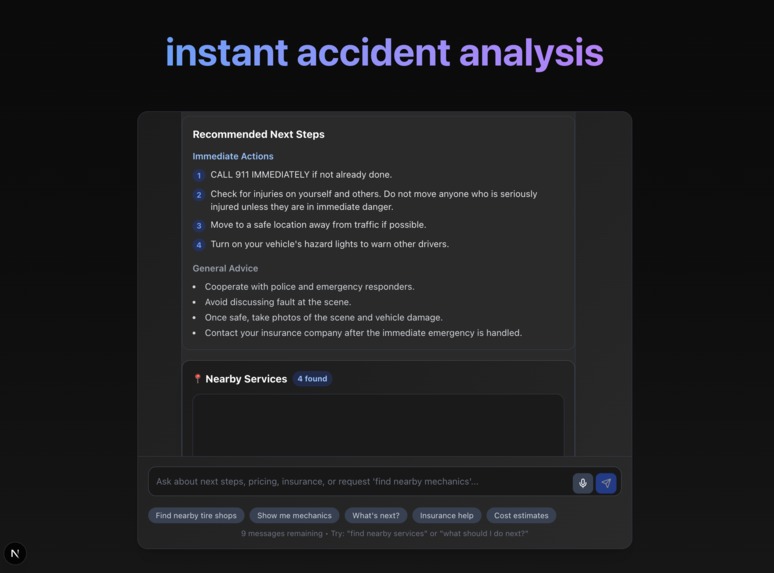
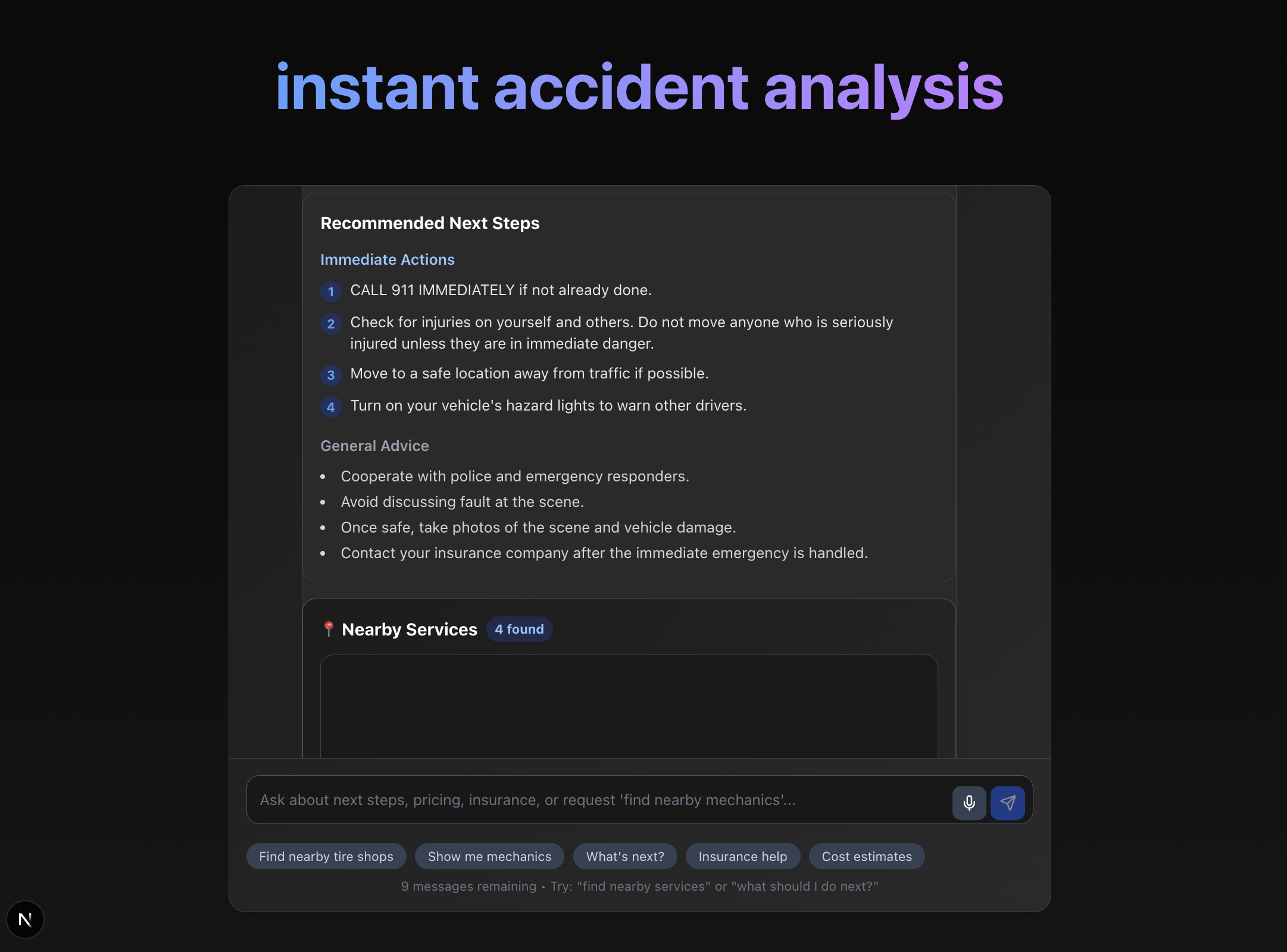
recommended actions
-
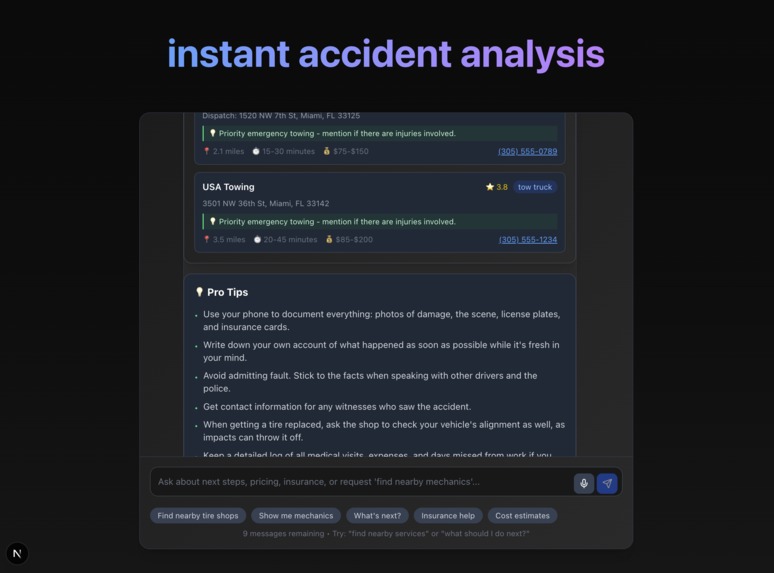
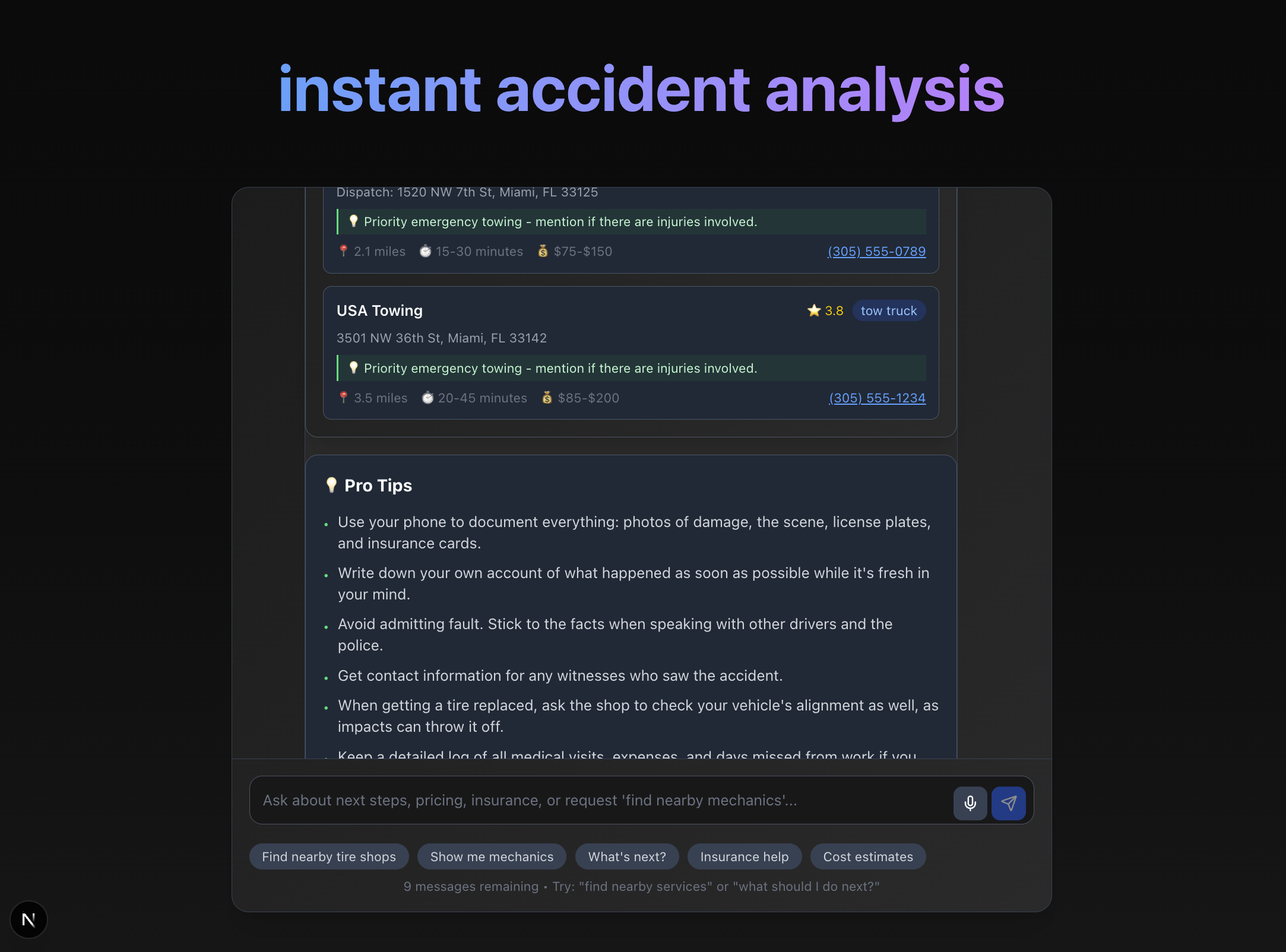
locations near by that could be useful
-
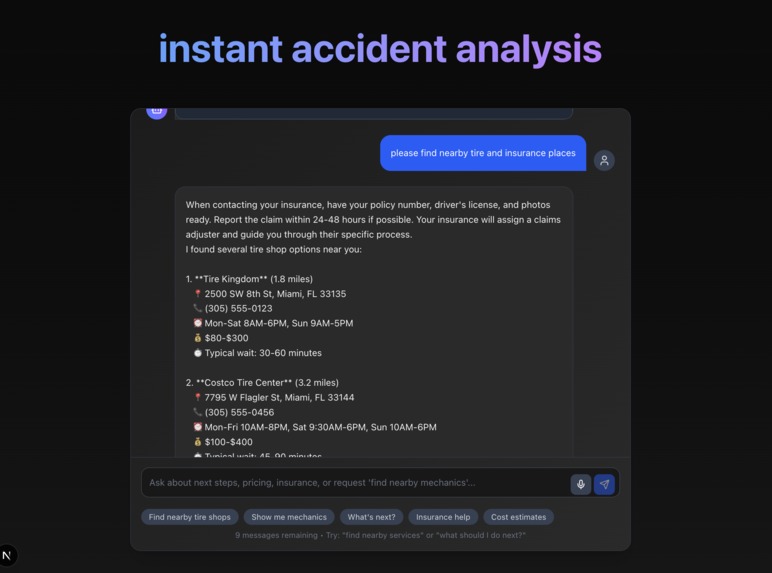
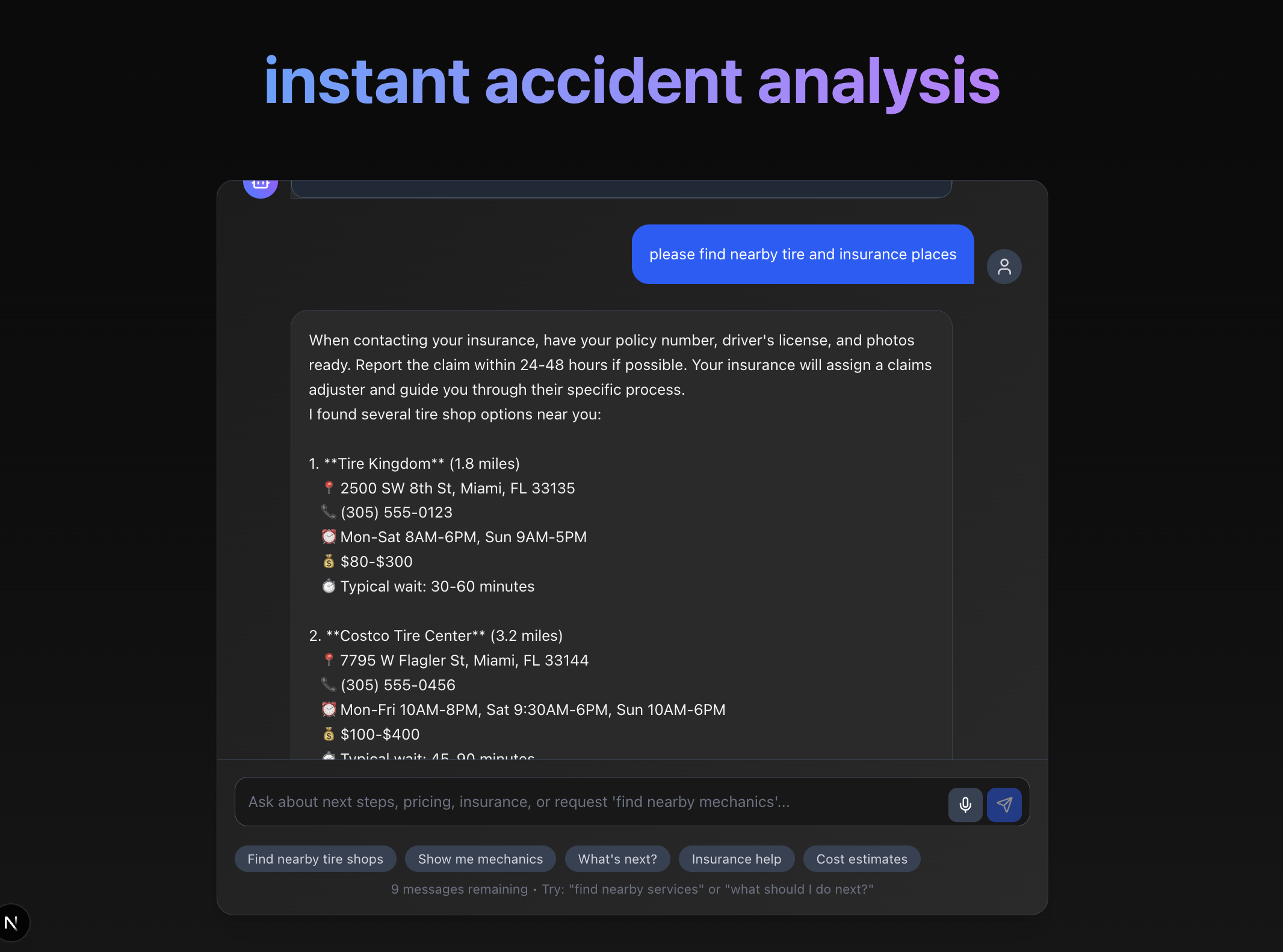
interacting
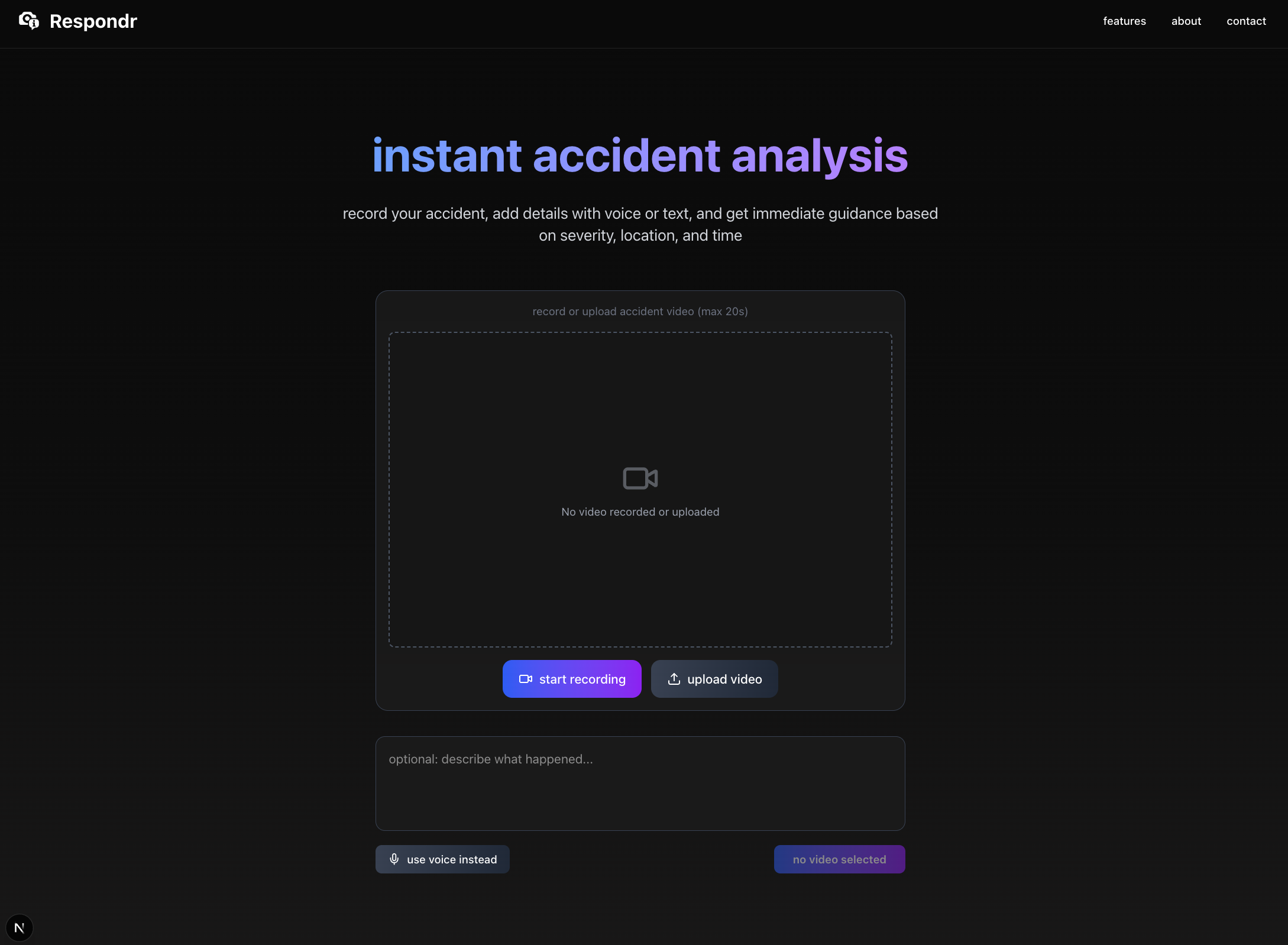
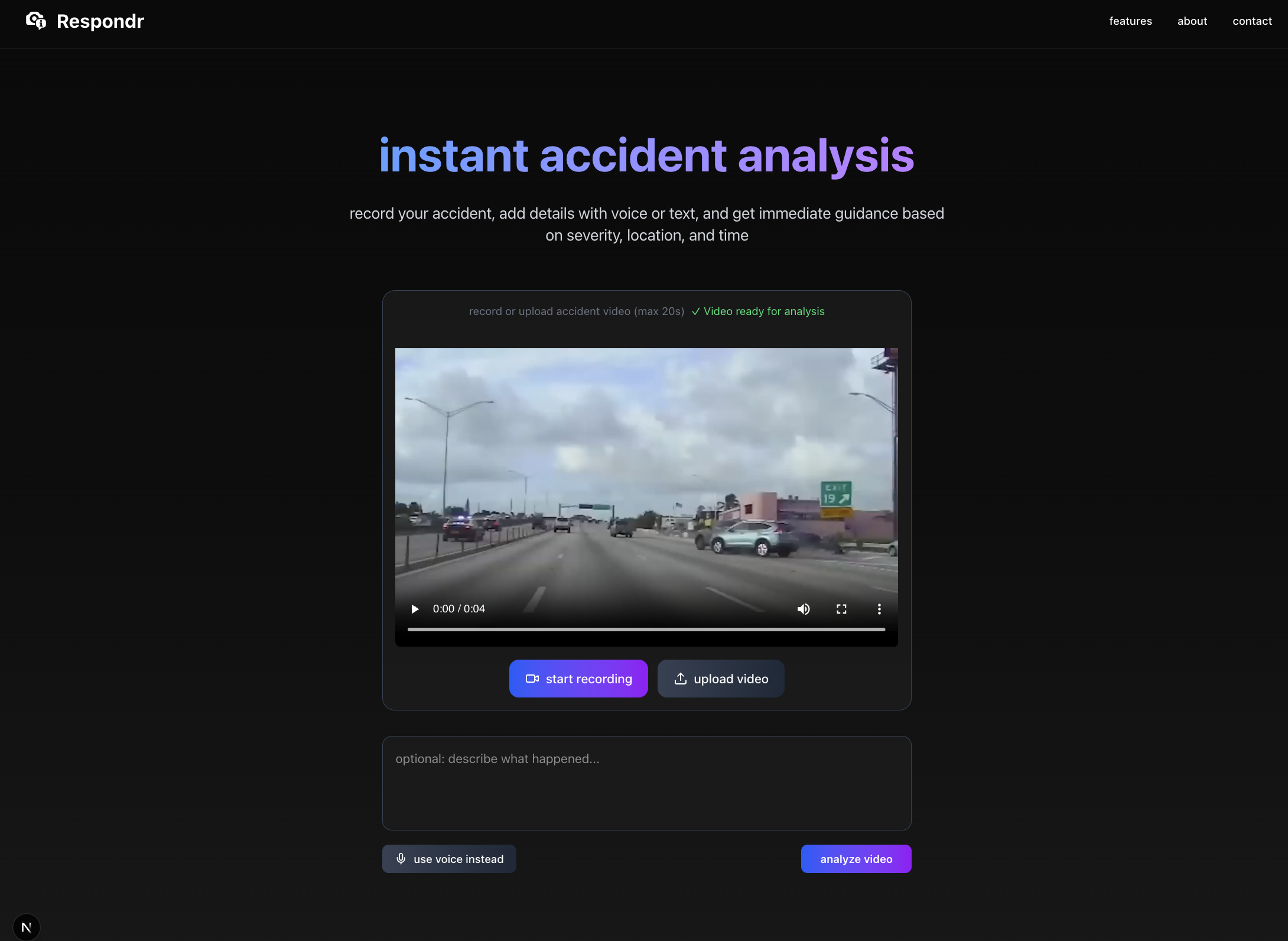

Inspiration
The story of what inspired me is I was drowsy driving while driving for 2 days awake back from California from an internship, so when I crashed into a tree at night while trying to get to a hotel to sleep, I didn't know what to do and I was very confused and unsure what to do, the area, where to go, how bad actually was the damages of my car, so this app is to help that and give guidance based on the live situation
What it does
Respondr helps accident victims by:
- Recording a live video of the accident directly from the web app.
- Using Gemini and Cloud Vision API to analyze the video for damage, vehicles involved, and severity.
- Transcribing optional voice notes via Google’s Speech-to-Text API.
- Combining visual + audio/text inputs with location data from Google Maps API.
- Providing actionable next steps:
- Minor accidents → nearby tire shops, tow trucks, or quick fixes.
- Two-person accidents → reminders to exchange insurance and document damage.
- Severe accidents → emergency survival tips, direct hospital guidance, or calling 911.
- Minor accidents → nearby tire shops, tow trucks, or quick fixes.
- Supporting an ongoing chat interface where users can ask questions like “find nearby mechanics” or “what should I do next?”
How we built it
- Frontend: Next.js + TailwindCSS for a sleek UI with dark gradients, integrated video + audio recording, and chat.
- Backend: FastAPI with endpoints for video analysis, transcription, and chat sessions.
- AI Agents:
agent_analyze_video→ uses Gemini API to detect severity, damages, and accident type.agent_transcribe_audio→ converts audio notes to text via Gemini / Google Speech-to-Text.agent_location_search→ queries Google Maps API to recommend nearby services.agent_decision_maker→ combines video + text analysis into final recommendations.
- APIs/Services:
- Gemini 1.5 Flash (video + text analysis)
- Google Maps API (service recommendations & map rendering)
- Cloud Vision API (damage classification)
- Speech-to-Text API (voice input transcription)
- Gemini 1.5 Flash (video + text analysis)
Challenges we ran into
- Extracting structured JSON results from Gemini was tricky, sometimes the model returned extra text, so we had to implement careful parsing and fallbacks.
- Building a live preview recorder in the frontend with auto-stop at 20s was harder than expected due to browser media API quirks.
- Integrating multiple APIs (Gemini, Maps, Speech-to-Text) and ensuring they worked smoothly together in a short hackathon timeframe.
Accomplishments that we're proud of
We got a basic MVP up!
What we learned
I learned more about using multiple AI agents to work together to achieve something
What's next for Respondr
Making the AI responses better, more controlled, and more valuable and relevant in the information they return
Built With
- fastapi
- gemini
- google-cloud
- maps-api
- nextjs
- speech-to-text
- tailwindcss
- vision-api



Log in or sign up for Devpost to join the conversation.