-
-
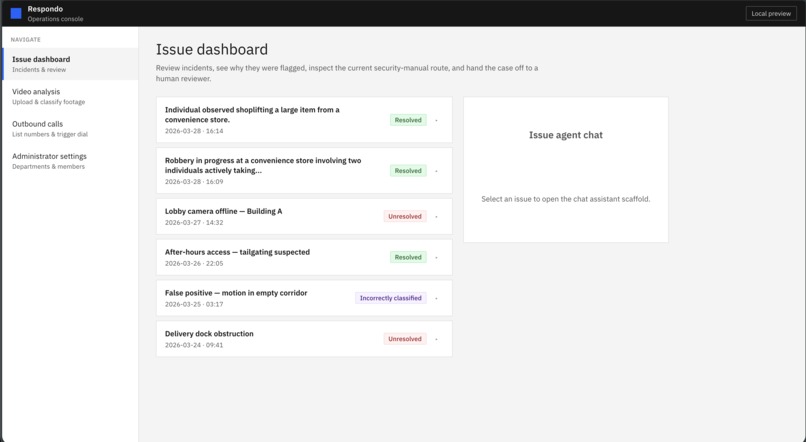
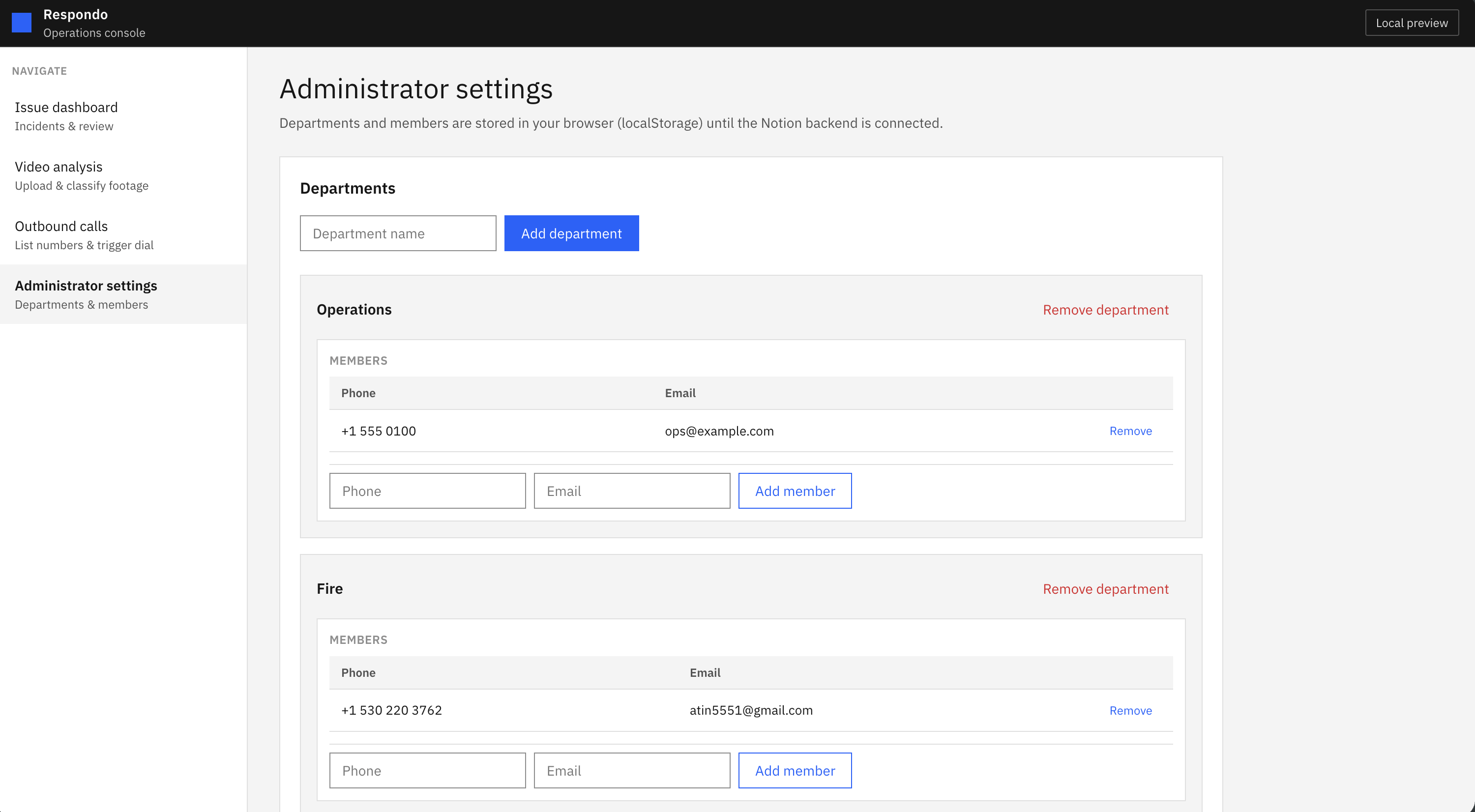
A page storing all the issues caught by Respondo
-
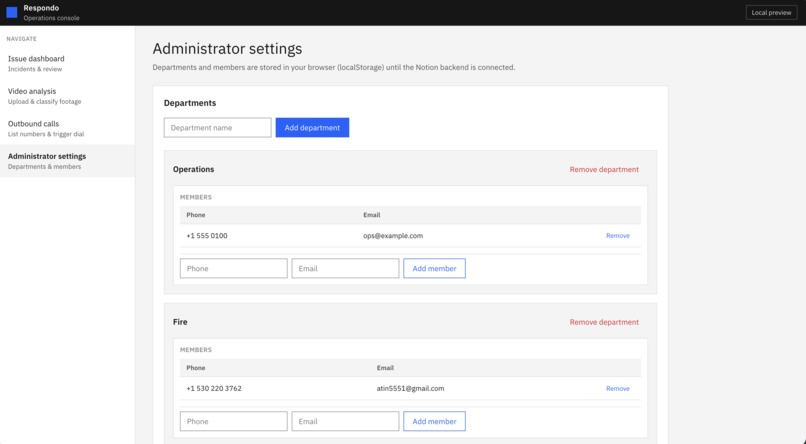
Configuring departments and contact infos within each department
-
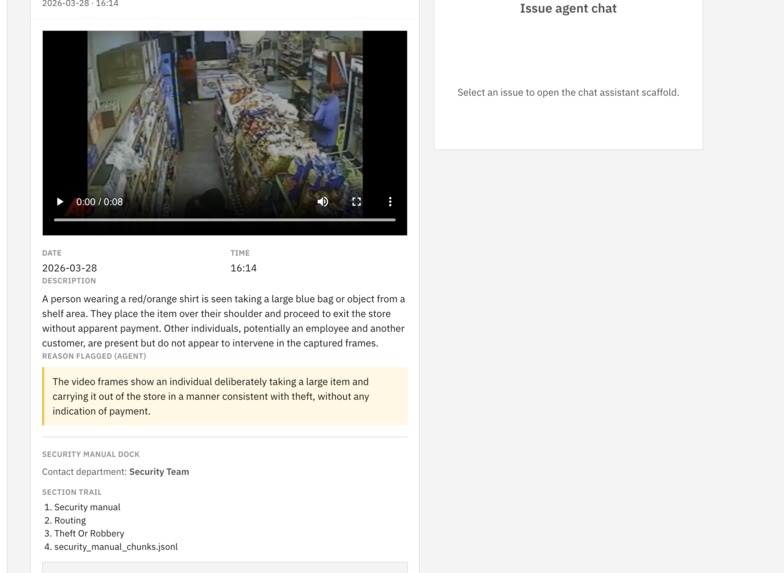
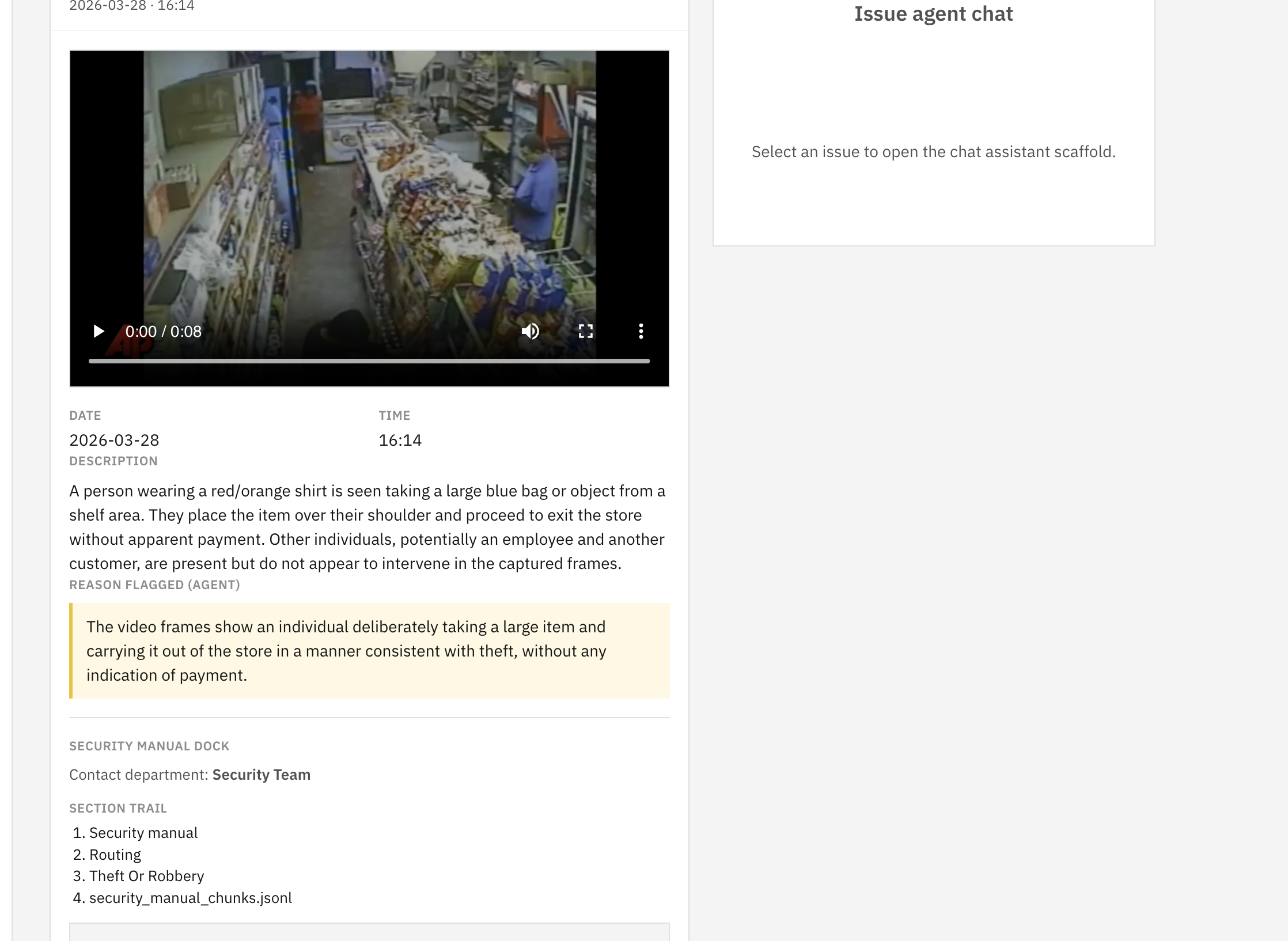
Expanded view with more detailed info of an issue detected by Respondo
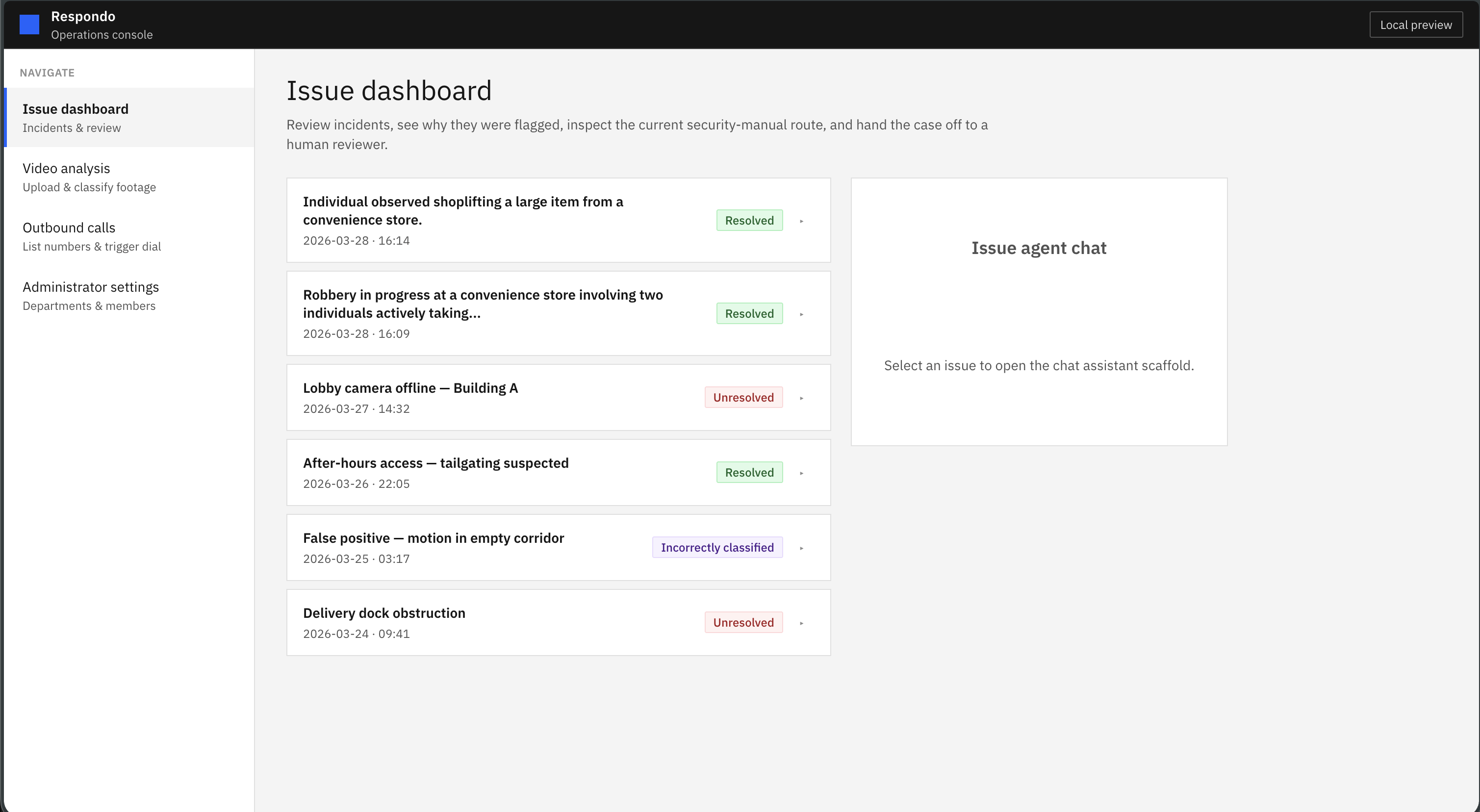
Respondo's Project Story
Inspiration
Security operations centers process hundreds of camera feeds simultaneously. Human operators are expected to catch every anomaly, a theft in aisle 7, someone who just collapsed, an unauthorized door breach, all at once, all in real time. That's an impossible ask.
We were inspired by a simple question: what if the camera already knew what it was seeing, and knew exactly who to call? Not just a dumb motion-alert, but a system that could classify an incident, reason about its severity, cross-reference an organization's own response playbooks, and hand a structured brief to the right team, all in seconds.
Respondo is that system.
What We Built
Respondo is a full-stack incident-intelligence platform with two components working in concert:
Backend (FastAPI + Gemini + Chroma)
- A video clip is uploaded to
POST /api/analyze-video. - OpenCV samples ( N ) frames evenly across the clip at timestamps
$$t_i = \frac{i}{N-1} \cdot T_{\text{total}}, \quad i = 0, 1, \ldots, N-1$$
- Those frames are sent as a multimodal prompt to Gemini 2.5 Flash via the Vertex AI express API.
- Gemini returns a structured JSON classification: incident type (one of
FIRE,THEFT_OR_ROBBERY,VIOLENCE_OR_ASSAULT,MEDICAL_EMERGENCY,SUSPICIOUS_BEHAVIOR,PROPERTY_DAMAGE,UNAUTHORIZED_ACCESS), severity, a human-readable summary, reasoning, and a confidence score ( \hat{p} \in [0, 1] ). - If the clip is flagged, the system queries a Chroma vector store over the organization's own security manuals, routing rules, department playbooks, and visual indicator guides, using Railtracks for chunking and retrieval. This vector store is deployed on Railway, which hosts both the Chroma persistence layer and our backend agents.
- The full analysis and matched manual excerpts are returned and persisted as a session trace under
.railtracks/data/sessions/.
Frontend (React + Vite + TypeScript)
- An issue dashboard showing live incidents classified from footage.
- A video analysis page where operators can drop footage and get an instant structured brief.
- A per-issue agent chat and final report generation interface, powered by Assistant UI, the open-source chat component framework that handles the full conversational agent experience including structured report output directly through the chat function.
Self-Improving with DigitalOcean
One of the features we're most excited about is the self-improvement loop, made scalable by DigitalOcean. Every session trace written to disk is not just a log: it is a candidate training signal.
When Respondo makes a false positive, flagging a clip that turned out to be a non-incident, that sample is stored. The next time a similar clip comes in, the system performs a top-( k ) retrieval over the historical session database to surface the most semantically similar past detections, including the ones that were later corrected. Those retrieved examples are injected as few-shot demonstrations into the Gemini prompt, showing the model exactly where it went wrong before and steering it away from repeating the same mistake. The architecture is:
- New clip arrives and is classified.
- A top-( k ) query runs over DigitalOcean-hosted session history using embedding similarity.
- The ( k ) most relevant past sessions, especially confirmed false positives, are prepended to the prompt as few-shot context.
- Gemini classifies with grounded awareness of its own past errors.
The system gets measurably smarter with every incident it processes.
Challenges We Faced
Retrieval grounding without hallucination. Getting the model to anchor its routing decisions to the actual manual corpus, not just its parametric knowledge, required careful prompt engineering and a retrieval step that runs after classification, not before. The right search query had to be synthesized from the Gemini output itself.
Frame sampling vs. context window. Gemini's context window is generous but not infinite. We had to find a sampling rate that captured enough of the event's temporal arc without bloating the prompt. Six frames proved a reliable default for clips under ~30 seconds.
Streaming multipart video over a REST API. FastAPI's UploadFile combined with Python's tempfile pipeline had subtle bugs around empty file detection and cleanup, especially when two optional field names (video and file) needed to be supported for different client conventions.
Making RAG actually useful for ops. Generic semantic search over manuals returned noisy results. We structured the manual corpus into typed chunks, routing, playbook, vision_mapping, so retrieval surfaces exactly the right kind of information depending on what the operator needs next. Railway made it trivial to keep this vector store persistent and accessible across deploys.
What We Learned
- Multimodal LLMs can genuinely reason about scenes. On our robbery test clip, Gemini returned a 0.95 confidence classification, identified the correct department routing (Security Team to Local Police), and generated four actionable response steps, all from six sampled frames.
- Structure beats free text in agentic pipelines. Pydantic output models with strict enum fields made downstream logic deterministic and composable.
- Vector stores are only as good as their corpus design. Spending time on manual chunking strategy paid off more than tuning embedding hyperparameters.
- Few-shot grounding is a multiplier. Injecting top-k historical false positives as examples into the live prompt dramatically reduced repeated misclassifications without any fine-tuning.
- Assistant UI removes the hardest frontend problem. Wiring up a full agentic chat interface, with structured report generation, streaming responses, and multi-turn context, would have taken days. Assistant UI made it an afternoon.
- Augment Code made all of this possible at hackathon speed. The entire codebase was vibe-coded with Augment Code. It handled boilerplate, caught integration bugs across FastAPI and React, and kept the architecture coherent as scope expanded mid-build.
Tech Stack
| Layer | Technology |
|---|---|
| Video understanding | Gemini 2.5 Flash (Vertex AI express) |
| Frame extraction | OpenCV (headless) |
| RAG / vector store | Chroma + Railtracks, hosted on Railway |
| Agent hosting | Railway |
| Self-improvement history | DigitalOcean (session store + top-k retrieval) |
| API | FastAPI + Uvicorn |
| Frontend | React 19 + Vite + TypeScript |
| Agent chat and report generation | Assistant UI |
| Tracing | Railtracks session JSON |
| Built with | Augment Code |
Built With
- .jsonl)
- .md
- bland.ai-outbound-voice-api
- browser-localstorage
- chromadb
- chromavectorstore
- cors
- css
- embedded/local-chroma-vector-database-(filesystem-persistence)
- eslint-9
- eslint-plugin-react-hooks
- eslint-plugin-react-refresh
- fastapi
- fetch-api
- fixedtokenchunker
- gemini-api
- google-cloud-(vertex-ai-/-project-&-region-env)
- google-gen-ai-sdk-(google-genai)
- google-vertex-ai
- hatchling
- html
- httpx
- javascript
- json
- json-over-http
- macos/linux
- markdown
- mediaparser
- multipart-file-uploads
- node.js
- npm
- opencv-(opencv-python-headless)
- pdfplumber
- pydantic-v2
- python
- python-3.11+
- python-dotenv
- python-multipart
- railtracks
- railtracks-session-trace-json-files
- react-19
- react-dom
- rest
- security-manual-corpus-(.txt
- starlette
- typescript
- typescript-5.9
- typescript-eslint
- uvicorn
- vapi-outbound-voice-api-&-webhooks
- vercel-ai-sdk-(ai-package)
- vite-8

Log in or sign up for Devpost to join the conversation.