-
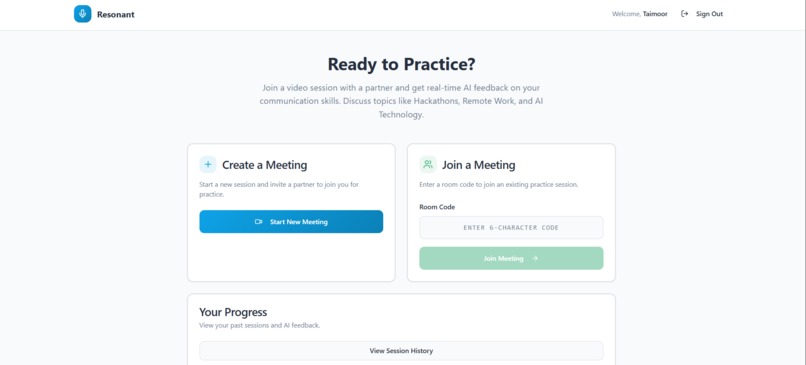
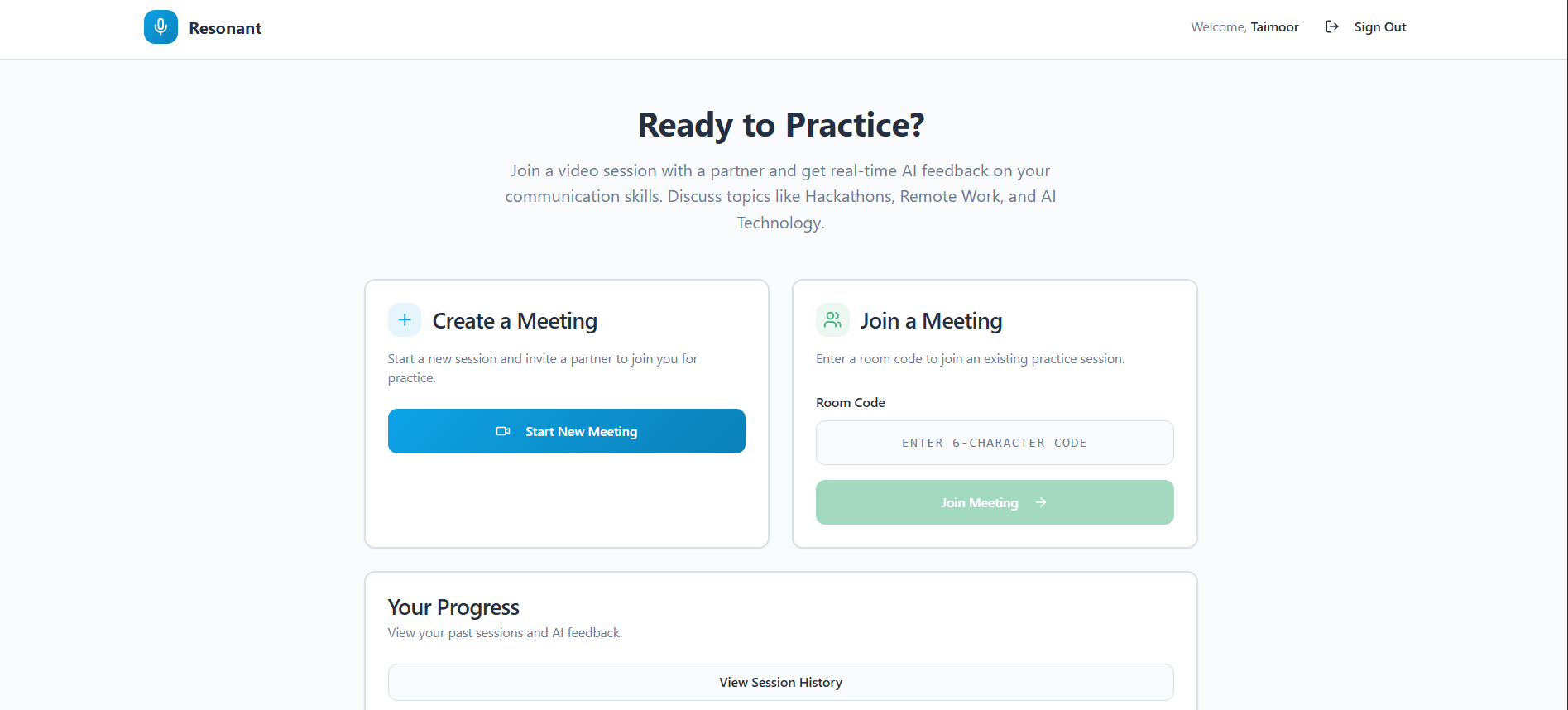
Home Page
-
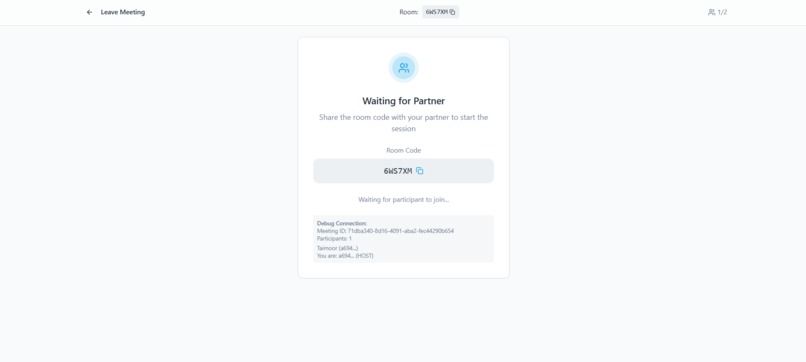
Waiting Lobby
-
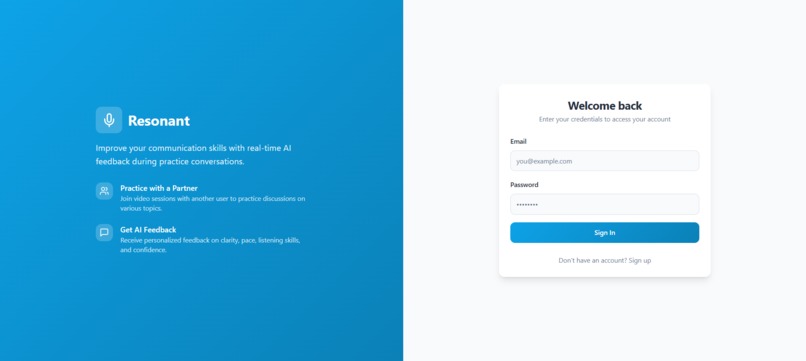
Sign In Page
Resonant: Speech Therapy & Real-Time Feedback Platform
A research-backed, high‑precision platform designed to make speech training, peer conversation, and therapeutic feedback more accessible for individuals with speech impediments.
This project integrates real human interaction with AI-driven analysis to support confidence, fluency, and long-term communication outcomes.
The Problem
Current digital speech tools fall into disconnected categories:
- Speech Therapy Apps – Provide structured practice but lack real human interaction.
- Language Exchange Platforms – Offer conversation but no therapeutic guidance or impediment-focused feedback.
- AI Conversation Tools – Miss the empathy, authenticity, and social‑confidence support users need.
This leaves a major gap: users often practice in isolation and struggle to build real conversational confidence.
Our Solution: Bridging the Gap
We introduce the first hybrid platform that combines:
- Real human conversation (peer-to-peer)
- AI-powered speech & facial analysis
- Therapeutic structure designed for social anxiety and impediments
- Clinical-grade metrics and progress tracking
This unified approach helps users build confidence, improve fluency, and receive meaningful feedback in real time.
Technical Architecture
The platform uses a robust, event-driven pipeline:
Core Pipeline
- GCS Trigger → Storage Adapter
- FFmpeg Audio Extraction
- MediaPipe Facial Analysis
- MongoDB structured data sink
- Dashboard visualization layer
Facial Tracking
- Uses MediaPipe Face Landmarker
- Tracks 478 3D facial landmarks
- Runs at 60+ FPS with <4% NME error
- Enables high‑fidelity extraction of:
- Emotion timelines
- Fluency patterns
- Articulation metrics
- Emotion timelines
Mission
To empower individuals with speech impediments through a combination of:
- Human empathy
- Real-time AI insights
- Clinically validated methodology
- Accessible, continuous feedback
This platform helps users build confidence, measure progress, and ultimately find their voice in real social settings.
Built With
- elevenlabs
- gemini
- mongodb
- python
- react
- typescript


Log in or sign up for Devpost to join the conversation.