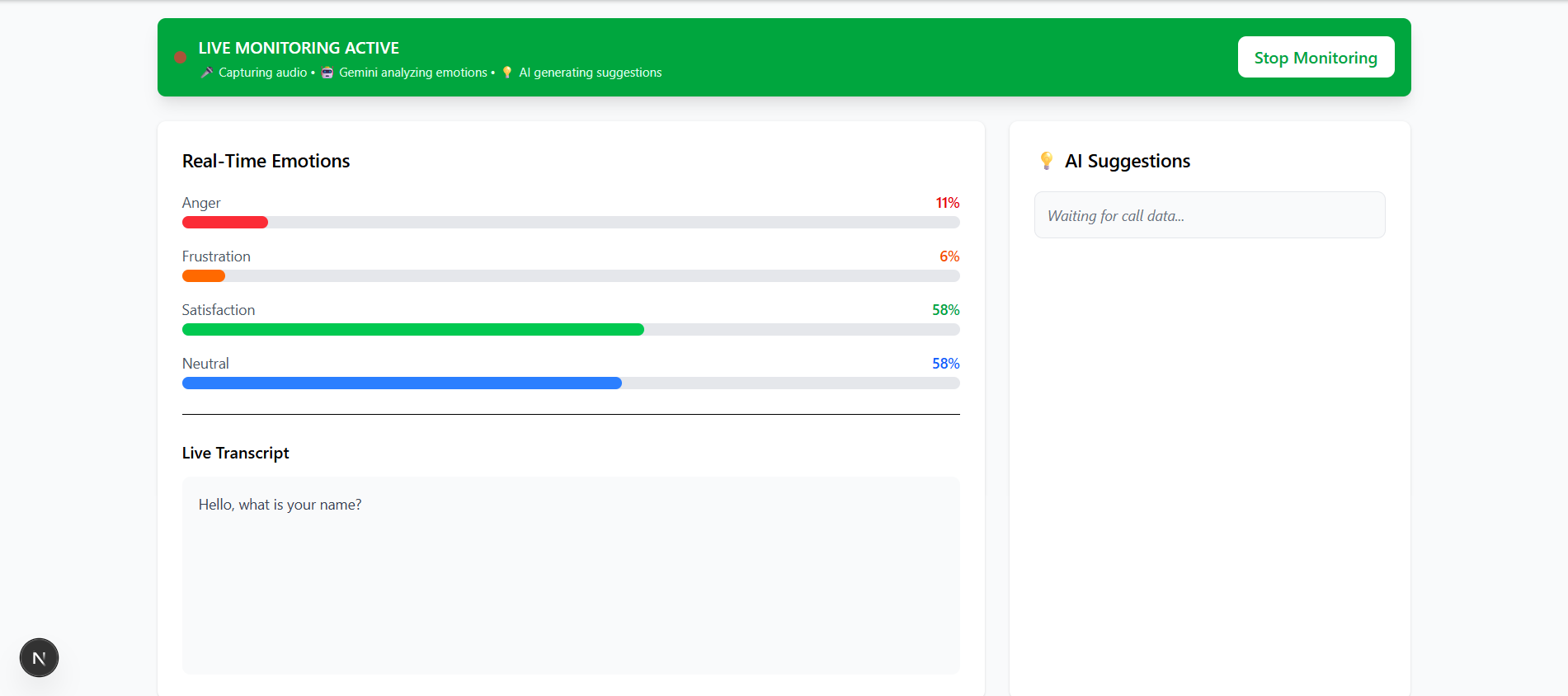
Inspiration
In the modern business landscape, customer conversations are the single richest source of truth. Every day, thousands of hours of audio are recorded—containing critical signals about product gaps, agent performance, and customer satisfaction. However, this data remains "dark data." It is locked inside raw audio files that no human has the bandwidth to re-listen to, meaning 99% of customer feedback evaporates the moment the call ends.
We were inspired to build Resonance AI to bridge the gap between unstructured audio and structured business intelligence. We wanted to democratize access to "Voice of the Customer" data, turning ephemeral phone calls into a permanent, queryable database that can drive product decisions and coaching strategies without manual intervention.
What it does
Resonance AI is an automated pipeline that transforms raw customer call recordings into actionable, structured data points.
- Ingests & Transcribes: It accepts audio files in common formats and performs local, privacy-preserving transcription using DeepGram and Hume AI to extract emotions. This converts speech into timestamped, speaker-attributed text.
- Analyzes with AI: The system feeds the transcript into a Large Language Model (Gemini or Ollama) with a specialized prompt designed to extract rigid data rather than conversational summaries.
- Extracts Structured Intelligence: Instead of vague notes, it outputs specific metrics:
- CSAT Score (1-5): An objective satisfaction rating based on sentiment.
- Resolution Status: Did the agent solve the problem? (Resolved/Partial/Unresolved).
- Missed Opportunities: Identifies questions that "fell through the cracks."
Topic Classification: automatically tags the call (e.g., Billing, Technical Issue, Refund).
Enables BI: All extracted data is stored in a SQL database and exposed via a REST API, ready to power dashboards, trend analysis tools, and agent performance reports.
How we built it
We built Resonance AI as a modular designed for flexibility and ease of deployment.
- Core Framework: We used C# for high-performance, asynchronous handling of requests.
- Transcription Engine: We integrated DeepGram and Hume AI to ensure we could handle audio processing without relying on expensive third-party transcription APIs or sending raw audio off-premise unnecessarily.
- Intelligence Layer: We implemented a dual-provider strategy. The system defaults to Google Gemini for high-speed, high-context analysis but includes full support for Ollama, allowing for completely offline, local inference.
- Data Persistence: We utilized SQLAlchemy with SQLite for instant local development, with a seamless switch to Supabase/PostgreSQL for production environments.
- Environment: The project is containerized with a virtual environment and uses
uvicornfor serving, with auto-migration logic that sets up the database schema upon the first launch.
Challenges we ran into
- Hallucination Control: Getting an LLM to output strict, consistent JSON for database insertion was difficult. We spent significant time refining system prompts to ensure the model didn't "chat" back but instead acted as a rigorous data extractor.
- Audio Dependency Hell: Managing local dependencies for audio processing (ffmpeg, torch, whisper) across different operating systems proved challenging, requiring us to create a robust environment setup guide.
- Latency vs. Accuracy: Balancing the speed of transcription with the accuracy of the output. We had to optimize how we chunk audio data to prevent timeouts during the analysis of particularly long customer support calls.
Accomplishments that we're proud of
- True "Upload-to-Insight" Automation: We successfully built a pipeline where audio is processed live, and seconds later, a database row is populated with complex analysis—no human loop required.
- Dual-Engine Architecture: We are proud of the flexibility to switch between Cloud AI (Gemini) and Local AI (Ollama) by simply changing an environment variable. This makes the tool viable for both resource-constrained startups and privacy-focused enterprises.
- Zero-Config Deployment: We engineered the backend to automatically detect the absence of tables and self-heal by running migrations on startup, significantly lowering the barrier to entry for new developers.
What we learned
- The Power of Structured Output: We learned that the real value of LLMs in business isn't just generating text, but categorizing reality. Forcing the model to commit to a "Resolution Status" is far more valuable for analytics than asking it to "summarize the call."
- Local AI is Viable: We discovered that for specialized tasks like transcription and extraction, local models are becoming incredibly competitive with cloud APIs, offering a path to zero-marginal-cost analytics.
- Audio Data is Messy: Real-world audio contains interruptions, over-talk, and noise. We learned the importance of preprocessing and robust error handling when the transcription layer isn't perfect.
What's next for Resonance
- Real-Time Streaming: Moving from batch file uploads to processing live audio streams via WebSocket for real-time agent assistance.
- RAG (Retrieval-Augmented Generation): Implementing vector search across the database of transcripts, allowing managers to ask questions like, "Show me how our agents handled 'refund' objections last month."
- Visual Dashboard: Building a React frontend to visualize the API data, providing out-of-the-box charts for CSAT trends and agent performance heatmaps.
- CRM Integration: Building webhooks to push the extracted summaries and scores directly into Salesforce or HubSpot.
Log in or sign up for Devpost to join the conversation.