Inspiration
Many people want to compose music but face real barriers: limited mobility, the cost of instruments and lessons, or conditions that make traditional composition difficult. We wanted to build a tool where your taste and a few words could produce a song that feels like yours, whether you lack the physical ability, the training, or simply the time. That's Resonance: music creation that meets people where they are.
What it does
Resonance is a web app that generates original music shaped by your taste and your words.
Paste a playlist. Share a YouTube playlist of songs you love. We feed each track through Meta's MusicGen-Melody-Large transformer model, register PyTorch forward hooks on the model's internal transformer layers, and collect the hidden-state activations produced while the model processes melody-conditioned token sequences. Each track is converted to mono WAV at 32 kHz, sliced into overlapping 10-second chunks with an 8-second hop, and run through the model under a neutral prompt. The per-chunk activation vectors are averaged per track, then per layer, and finally reduced to a single direction vector representing the identity of your playlist: up to 20 tracks and hundreds of chunks distilled into one reusable tensor. For users who prefer speed over depth, we offer a faster path using Gemini's audio-to-text capabilities to capture the playlist's general character.
Describe what you want. Write a natural-language prompt ("lofi piano for studying," "upbeat pop with happy vibes") to further steer the generation.
Generate and refine. The backend combines your playlist vector and prompt to produce a new track via MusicGen or Google's Lyria Realtime. During generation, injection hooks add the steering vector directly to the model's hidden states at every transformer layer on each forward pass, shifting the output distribution toward your playlist's sonic fingerprint without any fine-tuning. The dashboard displays the result with an animated canvas waveform, playback controls, full track metadata (model, backend, request ID, sample rate), and panels for refinement through chat or seven steering sliders covering energy, tempo, bass resonance, harmonic complexity, instrument density, vocal presence, and emotional tension.
How we built it
Frontend. Next.js 14 and React 18 power a single-page flow: Landing, Playlist Upload, Prompt, Generation, Dashboard. The playlist view polls the backend's extraction job status in real time, mapping six internal states (queued, downloading, preprocessing, extracting, uploading, completed) to a progress bar and human-readable labels. The dashboard features a custom canvas-based waveform visualization, a playback bar, download support, and refinement controls: a chat interface for natural-language adjustments and an advanced mode with seven steering sliders that trigger live regeneration through the backend. Track metadata (model name, backend type, request ID, duration, BPM, quality tier) is pulled directly from response headers.
Backend. FastAPI on Python 3.11 serves seven REST endpoints: health check, WAV generation, concept computation (DiffMean extraction from prompt pairs), concept calibration, concept listing, YouTube cache submission, and YouTube cache polling. The YouTube pipeline uses yt-dlp to resolve playlist metadata (handling youtube.com, youtu.be, and music.youtube.com URL formats), downloads up to 20 tracks as m4a, converts each to mono WAV via ffmpeg, slices them into overlapping chunks, and runs activation extraction through MusicGen's internal transformer using PyTorch forward hooks on lm.transformer.layers. A LayerActivationCollector captures the hidden states, pools across the sequence dimension, and aggregates chunk vectors into per-layer means. Results are cached locally with optional S3 sync, keyed by stable SHA-256 hashes of the extraction configuration for deterministic cache hits. Generation combines the user's text prompt with the playlist-derived vector and optional concept sliders via injection hooks that modify hidden states in-place during the forward pass. The stack includes PyTorch, TorchAudio, soundfile, and ffmpeg.
Integration. The frontend calls the backend first for playlist analysis (returning a steering vector, an activation ID, and playlist metadata), then for generation with that vector and prompt. The resulting WAV is streamed back with custom response headers (X-Request-Id, X-Sample-Rate, X-Duration-S, X-Backend, X-Model, X-Steering), and the UI renders the waveform, metadata, and refinement controls in the dashboard.
Challenges we ran into
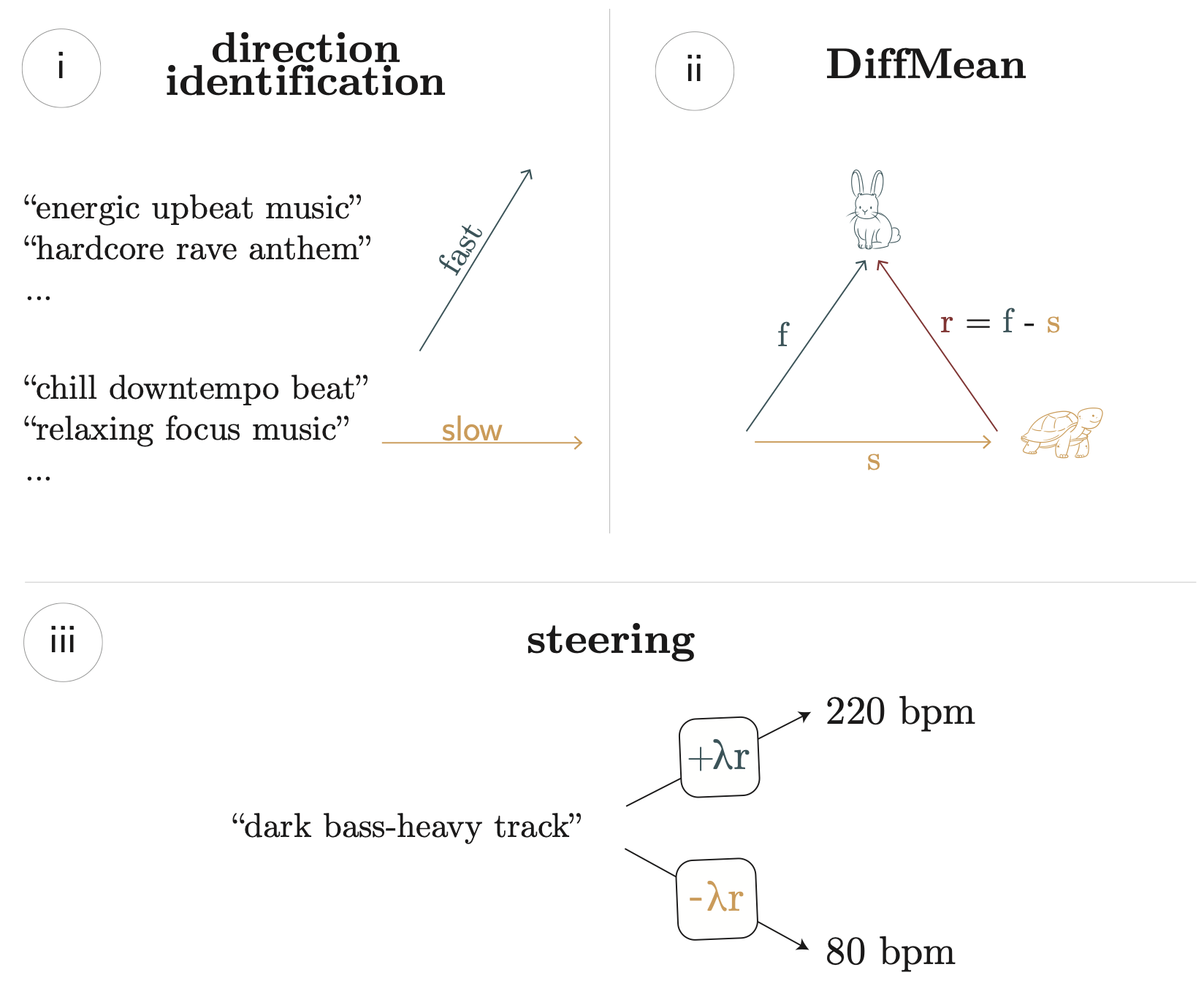
Steering is delicate. Activation vectors vary wildly in magnitude across layers, and naive injection either does nothing or destroys the output entirely. We built a calibration pipeline that generates audio at seven lambda values (0.0 through 4.0), measures signal quality via RMS, and identifies the range where RMS stays between 0.03 and 0.35, which is the zone where steering sounds musical rather than chaotic. The recommended lambda range is also computed analytically from the vector's L2 norm: upper = min(lambda_max, max(1.0, 3.2 / norm)), giving a useful default even without running calibration.
Choosing the right layer matters. Not all transformer layers respond equally to steering. We implemented a layer-scanning algorithm that evaluates the middle third of the model's layers, scoring each by its activation norm with a penalty for distance from the center layer. The best layer is selected automatically; too early and you get texture artifacts, too late and the steering has no structural effect.
GPU memory is finite. MusicGen-Melody-Large is a large model, and running activation extraction across dozens of tracks while keeping generation responsive required a threading semaphore that gates GPU access to one request at a time, LRU tensor caches (64 items each for concepts and YouTube vectors) that keep hot tensors on-device, and explicit torch.cuda.empty_cache() / torch.mps.empty_cache() calls after every generation to prevent CUDA OOM crashes
YouTube is messy. Inconsistent URL formats (youtube.com, youtu.be, music.youtube.com), playlists versus single videos, varying track lengths, and rate limiting all demanded a robust extraction pipeline. We parse URL hostnames and query parameters to distinguish playlists from single videos, enforce duration and file-size limits per track, hash each downloaded file with SHA-256 for cache integrity, and run extraction jobs in a background ThreadPoolExecutor with per-cache-key locks to prevent duplicate work. Temporary working directories are cleaned up in a finally block regardless of success or failure.
Cross-platform model loading. AudioCraft doesn't install cleanly on macOS, so we built a dual-backend system. The runtime tries AudioCraft first; if it fails, it falls back to HuggingFace Transformers with the same generation interface. The Transformers path loses melody conditioning and uses a different layer access pattern (model.decoder.layers instead of lm.transformer.layers), but steering injection works identically through the same hook mechanism.
Accomplishments that we're proud of
We built a working activation-steering pipeline from scratch. We register PyTorch forward hooks on transformer layers during generation and additively shift hidden states with a direction vector derived from real audio. The vector is computed as the L2-normalized mean of activations across hundreds of audio chunks, then injected at every layer on every forward pass. You can genuinely hear a playlist's influence in the output: the model produces something that sounds shaped by your taste, and the effect is striking.
We are equally proud of the experience itself. A YouTube URL and a sentence is all it takes. No musical knowledge, no expensive software, no physical dexterity required. Behind the curtain there are forward hooks, semaphore-gated GPU access, SHA-256-keyed caches, background thread pools, and multi-stage audio preprocessing, but the user just pastes a link and types a sentence.
What we learned
Inclusive design is intentional. Asking "who can't use traditional tools?", whether for physical, cognitive, or financial reasons, pushed us toward a simple, user-first flow.
Interpretability research has practical applications. Activation steering originates in the mechanistic interpretability community, where it is typically applied to language models. Applying it to a music generation model showed us these techniques are useful well beyond model analysis: the same DiffMean approach that researchers use to find "truth" or "refusal" directions in LLMs can find "jazz" or "lo-fi" directions in MusicGen.
Calibration matters more than capability. A powerful model is useless if steering it requires trial and error. Auto-calibration, where we generate at multiple strengths, measure RMS, and recommend a safe operating range before the user ever touches a slider, was the difference between a demo and a product.
Caching is a design decision, not an optimization. YouTube extraction can take minutes. Making it feel fast required content-addressed caching (stable hashes of model name, extraction config, and preprocessing params), background job execution with pollable status, and optional S3 sync so results survive restarts. The cache key design means the same playlist with the same config always hits the same result, and different configs correctly miss.
What's next for Resonance
Closing the refinement loop. The dashboard exposes seven steering sliders and a chat interface, and regeneration from adjusted slider parameters is wired up, but the chat interface doesn't yet parse intent into parameter changes. Letting users say "more bass, less tension" and having that map to steering adjustments is the clear next step.
Melody conditioning in the UI. The backend already supports melody-conditioned generation via generate_with_chroma, accepting audio as a URL or base64 payload. We want to surface this in the UI so users can hum or upload a reference melody alongside their playlist and prompt.
Per-layer steering. The infrastructure already supports per-layer vectors (per_layer_vector: dict[int, torch.Tensor]), but right now we reduce everything to a single one_to_all vector applied uniformly. For power users, we would like to expose controls that adjust the "texture" of a track at one layer while leaving the "structure" at another untouched.
Attention-weighted mixing. The YouTube mix schema supports three modes (mean, time_select, and attention_weighted), but only mean aggregation is fully implemented. Attention-weighted mixing would let certain chunks, say the chorus of your favorite song, contribute more to the steering vector than others.
Next, we plan to expand Resonance to support additional streaming platforms like Spotify and Apple Music, allowing users to generate music inspired by a wider range of playlists and listening habits.
We also want to make Resonance more social and collaborative. In the future, users will be able to share their generated tracks with friends, collaborate on refinements, and save their creations to a personal library for easy access and iteration.

Log in or sign up for Devpost to join the conversation.